【HTTP 协议1】图文详解 HTTP 请求和应答报文
文章目录
- 前言
- 一、认识 HTTP 协议
-
- 1, 什么是 HTTP 协议
- 2, HTTP 协议的报文格式
- 二、HTTP 请求报文
-
- 1, 认识方法
-
- 1.1, GET 和 POST 辨析(重点)
- 1.2, 其他方法
- 2, 认识 URL
- 3, 认识 Header
-
- 3.1, Host
- 3.2, Content-Length
- 3.3 Content-Type
- 3.4, User-Agent
- 3.5, Referer
- 3.6, Cookie(重点)
- 三、HTTP 响应报文
-
- 1, 认识状态码
- 总结
前言
各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你:
JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等
Java数据结构: 顺序表, 链表, 堆, 二叉树, 二叉搜索树, 哈希表等
JavaEE初阶: 多线程, 网络编程, TCP/IP协议, HTTP协议, Tomcat, Servlet, Linux, JVM等(正在持续更新)
前几篇文章介绍了传输层的 TCP 协议的几大重要机制, 认识了传输层协议之后, 本片开始陆续介绍应用层的 HTTP 协议的相关知识
本篇主要介绍 HTTP 请求报文和应答报文中需要掌握和认识的知识点
提示:是正在努力进步的小菜鸟一只,如有大佬发现文章欠佳之处欢迎批评指点~ 废话不多说,直接上干货!
一、认识 HTTP 协议
1, 什么是 HTTP 协议
HTTP (“超文本传输协议”) 是一种应用非常广泛的 应用层协议, 我们平时打开一个网站, 就是通过 HTTP 协议来传输数据的
HTTP 往往是基于传输层的 TCP 协议实现的, (HTTP1.0, HTTP1.1(最主流), HTTP2.0 均为TCP, HTTP3 基于 UDP 实现)
当我们在浏览器中输入一个 CSDN 的"网址" (URL) 时, 浏览器就给 CSDN 的服务器发送了一个 HTTP 请求, CSDN 的服务器返回了一个 HTTP 响应
这个响应结果被浏览器解析之后, 就展示成我们看到的页面内容, (这个过程中浏览器可能会给服务器发送多个 HTTP 请求, 服务器会对应返回多个响应, 这些响应里就包含了页面 HTML, CSS, JavaScript, 图片, 字体等信息).
HTTP 协议是一问一答式的, 一个请求对应一个响应
2, HTTP 协议的报文格式
我们使用 fiddler 抓包工具, 打开 CSDN 网站时就可以看到各种各样的包
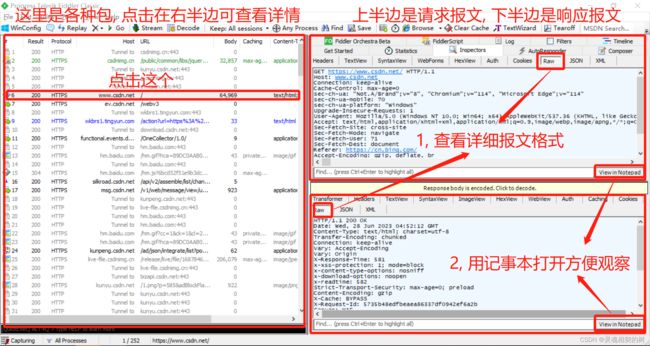
先初步观察请求/响应报文的格式, 然后再详细介绍
HTTP 请求报文的格式 :

首行:[方法] + [url] + [版本号]Header: 请求的属性, 冒号+空格分割的键值对, 每组属性之间使用\n分隔, 遇到空行表示 Header 部分结束Body: 空行后面的内容都是 Body . Body 允许为空字符串
HTTP 响应报文的格式 :

首行: [版本号] + [状态码] + [状态码解释]Header: 请求的属性, 冒号分割的键值对, 每组属性之间使用\n分隔, 遇到空行表示 Header 部分结束Body: 空行后面的内容都是 Body . Body 允许为空字符串
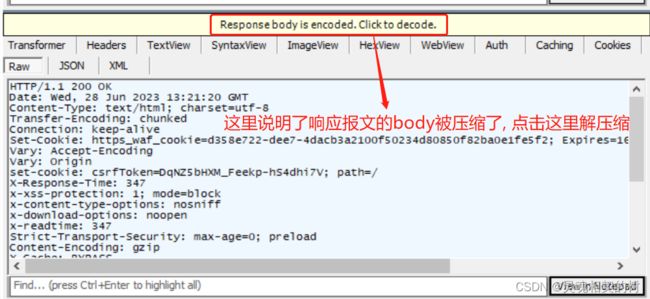
这里看到正文部分是乱码, 是因为, 为了减少网络传输的数据量, 节省带宽, 正文部分往往是被压缩的, 点击这里可以看到解压缩的正文,
然后再用记事本打开
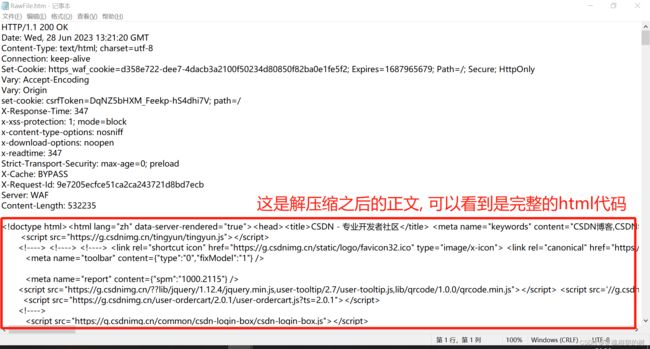
所以, 当浏览器打开一个网站时, 实际上就是给该网站的服务器发送了一个请求, 然后返回了一个响应, 这个响应就携带了这个网站的页面, 当然还有其他的响应, 可能包括 CSS, JavaScript, 音视频等资源
二、HTTP 请求报文
1, 认识方法
HTTP 请求报文中的首行的第一个属性就标识了: 这个请求使用的方法, 方法描述了这个请求打算干嘛
例如刚刚我们访问 CSDN 页面的请求的方法就是 GET

HTTP 协议常用的方法如图所示 :
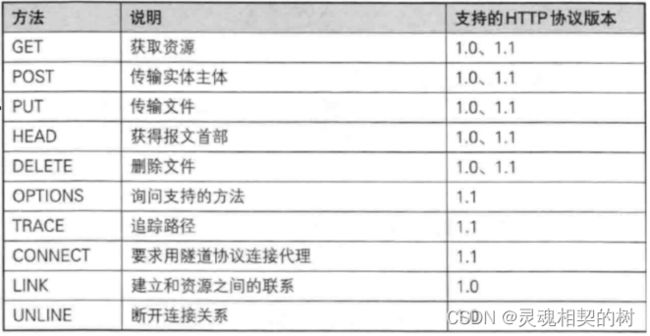
绝大多数场景使用的都是 GET 和 POST ! ! ! 只需要重点认识这两个方法即可, GET 方法表示: 从服务器里获取, POST 方法表示: 往服务器里提交
1.1, GET 和 POST 辨析(重点)
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源, 在浏览器中访问网站, 此时浏览器就会发送出一个 GET 请求, 另外, HTML 中的 link, img, script 等标签也会触发 GET 请求, 或者使用 JavaScript 中的 ajax 也能构造 GET 请求
POST 多用于提交用户输入的数据给服务器(例如登陆页面), 或者长传文件. 通过 HTML 中的 form 标签可以构造 POST 请求, 或者使用 JavaScript 的 ajax 也可以构造 POST 请求
我们看一下登录 CSDN 时, 使用 fiddler 抓到的包
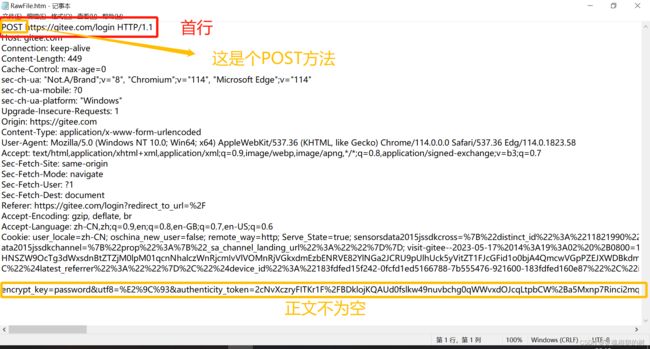
可以看到, POST 和 GET 不同, POST 请求的报文是有正文的, 因为登陆时需要提交相关材料(比如密码, 此处是被加密过的)
- 提问 : GET 和 POST 有什么区别呢?
本质上没有区别 :
1, 不同的方法只是代表不同的语义, 但不一定严格遵守
2, 使用 GET 的场景一般都可以使用 POST 代替, 这二者一般是可以相互代替的
3, GET 也可以有正文, POST 也可以没有正文, 并非绝对
使用习惯上有区别 :
1, GET 习惯用来表示"获取数据", POST 习惯表示"提交数据"
2, GET 一般没有正文, 需要携带的数据可以写在 UR L的 query string 中, POST 一般有正文
3, GET 一般被设计成"幂等"的, POST 无要求
4, GET 可以被缓存(前提是幂等), POST 不可以
这里的"幂等"是指 : 多次请求得到的响应一致, 这也是可以被缓存的原因
虽然官方标准建议 GET 设计成幂等, 但并不绝对, 比如现在很多网站都有"猜你喜欢"功能, 就是根据用户历史访问记录实时做出更新的

1.2, 其他方法
PUT : 与 POST 相似,只是具有幂等特性,一般用于更新
DELETE : 删除服务器指定资源
OPTIONS : 返回服务器所支持的请求方法
HEAD : 类似于GET,只不过响应体不返回,只返回响应头
TRACE : 回显服务器端收到的请求,测试的时候会用到这个
CONNECT : 预留,暂无使用
2, 认识 URL
请求报文中的第二个属性就是 URL, 如图

URL (Uniform Resource Locator 统一资源定位符), 就是平时俗称的"网址", 互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它
上图中的URL中有很多信息被省略了, 完整的 URL 应该如下图所示 :

协议方案名: 常见的有 http 和 https, 也有其他的类型.(例如访问 mysql 时用的jdbc:mysql )登陆信息: 现在的网站进行身份认证一般不再通过 URL 进行了, 一般都会省略服务器地址: 此处是一个 “域名”, 域名会通过 DNS 系统解析成一个具体的 IP 地址端口号: 上面的 URL 中端口号被省略了, 当端口号省略的时候, 浏览器会根据协议类型自动决定使用哪个端口 (例如 http 协议默认使用 80 端口, https 协议默认使用 443 端口)带层次的文件路径: 标识要访问的服务器的哪一个资源查询字符串(query string): 具体的表示了请求的资源是什么, 本质是一个键值对结构. 键值对之间使用 & 分隔, 键和值之间使用 = 分隔.片段标识: 主要用于页面内跳转
3, 认识 Header

其中键和值之间用冒号+空格分隔, Header 中的键值对可以用 N 个, 没有限制, 大部分键值对都是由 HTTP 协议规定的, 还有一部分是允许程序员自定义的
接下来介绍一部分键值对的含义
3.1, Host
标识当前要访问的服务器的地址(和端口)
在 URL中虽然已经写入了域名, 通常情况下这两个是一致的, 但如果不是直接访问, 而是通过代理访问服务器, 这二者就不同了
3.2, Content-Length
标识 Body 的长度(单位是字节)
如果是 GET 方法获取的请求, 一般没有 Body, 所以就不显示这个键值对了
3.3 Content-Type
标识 Body 中的数据格式(和字符集)
如果是 GET 方法获取的请求, 一般没有 Body, 所以就不显示这个键值对了
如果是 POST 或其他的方法, Content-Type 一般是以下两种 :
1, application/json, 是浏览器和 HTTP 服务器交互最常见的一种格式,正文中形如 JavaScript 中的对象
2, application/x-www-from-urlencoded, 是 HTML 中的 from 表单提交数据生成的, 正文中形如 URL 中的 query string
上述两种格式一般在请求报文中使用, 如果是响应报文, 数据的格式还有上文提到过的 text/html, text/css, application/javascript, image/jpg等等
3.4, User-Agent
标识用户的客户端操作系统型号和版本, 以及使用的浏览器的版本

User-Agent 的设计是一个历史遗留问题, 如今的作用大不如前, 不过至少可以用来区分用户是使用电脑/手机/平板
3.5, Referer
标识当前页面从哪跳转过来的

(如果直接在地址栏输入 URL 或者通过收藏夹进行访问, 是没有 Referer 的)
3.6, Cookie(重点)
Cookie 是浏览器在本地存储用户自定义数据的一种关键机制
如下图所示, Cookie 里有很多键值对(数据可以由程序员自定义), 键值对之间用分号分割, 键和值之间用等号分割, 具体这些键值对表示的含义是什么, 咱不知道, 只有开发这个网站的程序员知道

浏览器作为客户端, 需要向该网站的服务器发送请求来获取资源, 显然服务器是需要存储一些数据的, 而浏览器这边也需要存储一些数据, 比如说用户的登录信息
既然客户端这边要存储数据, 能否直接存在用户的硬盘上? 一定不可以, 不能允许网页操作本机的硬盘, 文件系统, 否则如果被恶意网站植入病毒, 硬盘中的数据都可能受到威胁, 所以浏览器是禁止网页访问硬盘的
Cookie 就是解决这一问题的重要机制, 浏览器允许网页把重要的信息存储在各自网页的 Cookie 中, 同一个网站(主页和子页)共享一份 Cookie
- 1, Cookie 从哪里来?
Cookie (中存储的数据)从服务器来: 第一次登陆一个网站的时候, 服务器会返回一个响应, 在这个响应报文中, 通过 Set-Cookie 把需要存储的值返回给客户端, 客户端进行存储
比如在我的 gitee 主页上可以查看已经存储的 Cookie, 方便观察我们把这些都删除
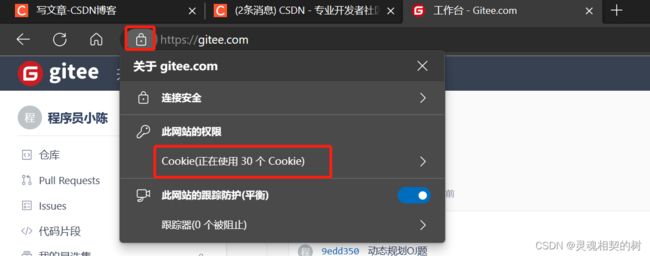
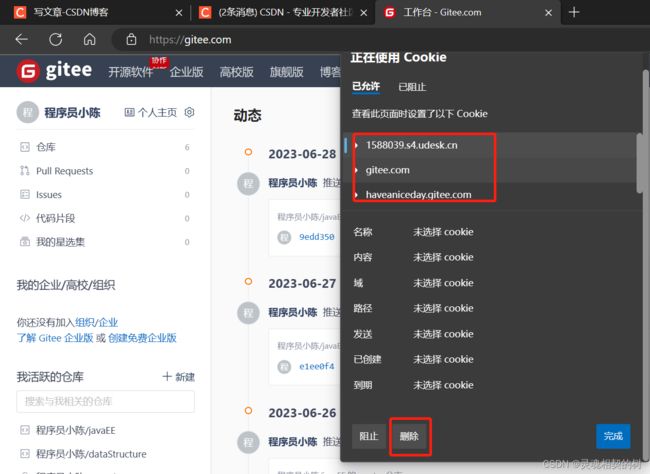
删除 Cookie 之后, 其中存储的有关用户登录的信息就没了, 有些网站可能会主动退出登录, 或者自动重新登陆, 通过 fiddler 可以抓包看到登陆时的响应报文中确实有 Set-Cookie 字段

里面包含了一个 gitee-session-n 这样的属性, 属性值是一串很长的加密之后的信息. 这个信息就是用户当前登陆的身份标识. 也称为 “令牌(token)”
- 2, Cookie 到哪里去?
Cookie 要回到服务器, 当客户端收到 Set-Cookie 中的数据后, 后续每次请求网页的时候, 给服务器发送的请求报文中都有一个 Cookie 字段, 相当于把 Cookie 里面的值再带给服务器
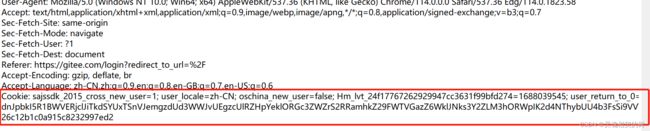
请求你中的 Cookie 字段也包含了一个 gitee-session-n 属性, 里面的值和刚才服务器返回的值相同, 后续只要访问 gitee 这个网站, 就会一直带着这个令牌, 直到令牌过期/下次重新登陆
- Cookie 有什么用?
Cookie 是一浏览器客户端在本地存储用户自定义数据的一种机制, 比如存储用户的身份信息, 让服务器通过 Cookie 来识别用户身份
三、HTTP 响应报文
1, 认识状态码

状态码表示访问一个页面的结果 (是访问成功, 还是失败, 还是其他的一些情况…), 接下来简单介绍一些常见的状态码
| 序号 | 分类 | 描述 |
|---|---|---|
| 1xx | 信息性 | 服务器收到请求, 正在处理 |
| 2xx | 成功 | 请求接收成功, 处理完毕 |
| 3xx | 重定向 | 需要进一步操作以完成请求 |
| 4xx | 客户端错误 | 请求包含语法错误或无法完成请求 |
| 5xx | 服务器错误 | 服务器处理请求出错 |
-
200 OK
这是一个最常见的状态码, 表示访问成功, 一般用于GET与POST请求 -
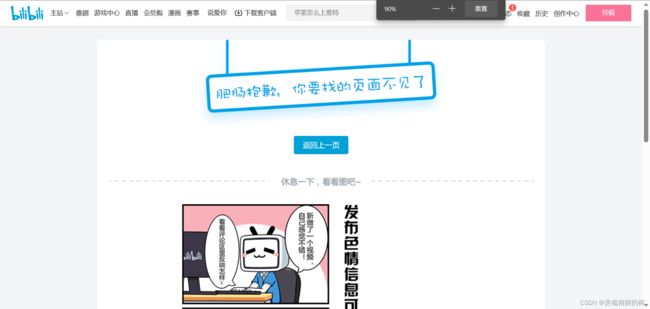
404 Not Found
找不到资源, 服务器无法根据客户端的请求找到资源(网页), 通过此代码, 网站设计人员可设置"您所请求的资源无法找到"的个性页面
(浏览器输入一个 URL, 目的就是为了访问对方服务器上的一个资源. 如果这个 URL 标识的资源不存在, 那么就会出现 404)
-
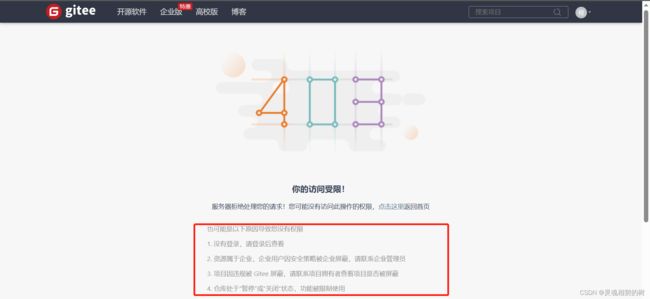
403 Forbidden
拒绝访问, 有的页面通常需要用户具有一定的权限才能访问(比如登陆后才能访问), 如果用户没有登陆直接访问, 就容易见到 403.
-
405 Method Not Allowed
方法不支持, 前面介绍了 HTTP 中所支持的方法( GET, POST, PUT, DELETE 等), 但是对方的服务器不一定都支持所有的方法(或者不允许用户使用一些其他的方法) -
500 Internal Server Error
服务器内部出错, 可能是服务器端的代码出 bug 了或者异常崩溃了, 一般在访问主流网站时很少见到这个状态码, 但后端程序员在写代码的时候可能比较常见 -
504 Gateway Timeout
访问超时, 服务器访问量大, 无法及时处理请求并返回响应 -
301 Moved Permanently
永久重定向, 请求的资源已被永久的移动到新的 URI, 返回信息会包括新的 URI, 浏览器会自动定向到新 URI, 今后任何新的请求都应使用新的 URI 代替
重定向就是值访问旧的资源地址时, 自动被引导到新的资源地址, 俗称页面跳转
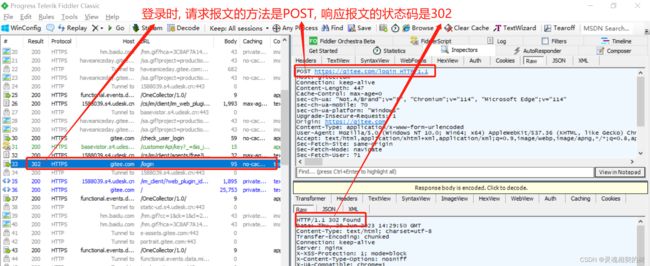
- 302 Found
临时重定向, 资源只是临时被移动, 下一次请求时是否被移动, 不一定, 所以客户端应继续使用原有 URI
在登陆页面中经常会见到 302, 用于实现登陆成功后自动跳转到主页.
响应报文的 header 部分会包含一个 Location 字段, 表示要跳转到哪个页面
总结
以上就是本篇的全部内容, 主要介绍了如何 HTTP 协议的请求和响应报文的格式, 重点介绍了 HTTP 方法中的 GET 和 POST 的辨析, 以及 Header 中有关 Cookie 的相关知识
如果本篇对你有帮助,请点赞收藏支持一下,小手一抖就是对作者莫大的鼓励啦~
上山总比下山辛苦
下篇文章见
