【读点论文】EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks网络结构要像身材一样匀称且体量和处理能力匹配
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Abstract
- 卷积神经网络(ConvNets)通常是在固定的资源预算下开发的,然后在有更多资源的情况下扩大规模以获得更好的准确性。
- 在本文中,系统地研究了模型的缩放,发现仔细平衡网络深度、宽度和分辨率可以带来更好的性能。基于这一观察,本文提出了一种新的缩放方法,使用一个简单而高效的复合系数统一缩放深度/宽度/分辨率的所有维度。本文在扩大MobileNets和ResNet的规模上证明了这种方法的有效性。
- 为了更进一步,本文使用神经结构搜索来设计一个新的基线网络,并将其扩大到获得一个模型系列,称为EfficientNets,它比以前的ConvNets实现了更好的准确性和效率。
- 特别是,本文的EfficientNet-B7在ImageNet上达到了当时最先进的84.3%的最高准确率,同时比现有最好的ConvNet小8.4倍,推理速度快6.1倍。本文的EfficientNets在CIFAR-100(91.7%)、Flowers(98.8%)和其他3个迁移学习数据集上也有很好的迁移效果,并取得了最先进的准确性,而参数却少了一个数量级。
- 源代码是在:tpu/models/official/efficientnet at master · tensorflow/tpu (github.com)
- 论文:[1905.11946] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (arxiv.org)
- EfficientNet是Google Research 发表在ICML 2019的工作。EfficientNet根据网络从小到大,分为了B0到B7共8个网络,其中EfficientNet-B0尺寸最小,速度最快,精度相对最低;EfficientNet是Google在2019年5月提出的网络,在当时表现SOTA,超级强,该论文提出了一种多维度混合的模型放缩方法。
- 先用NAS搜一个较小的拓扑结构(基础网络),然后用一定的方法增大网络尺寸。这样,当基础网络表现超越其他同等尺寸网络时,增大网络尺寸后的表现也应该能够超越其他同等尺寸的网络。这样就得到了EfficientNet从B0到B7的backbone家族。
Introduction
-
扩大ConvNets的规模被广泛用于实现更好的准确性。例如,ResNet(He等人,2016)通过使用更多的层可以从ResNet-18扩展到ResNet-200;最近,GPipe(Huang等人,2018)通过将一个基线模型扩展到四倍大,实现了84.3%的ImageNet top-1精度。
-
然而,扩大ConvNets的过程一直没有得到很好的理解,目前有很多方法可以做到这一点。最常见的方法是通过深度(He等人,2016)或宽度(Zagoruyko和Komodakis,2016)扩大ConvNets的规模。
-
另一种不太常见,但越来越流行的方法是通过图像分辨率来放大模型(Huang等人,2018)。在以前的工作中,通常只对三个维度中的一个进行缩放–深度、宽度和图像大小。虽然可以任意缩放两个或三个维度,但任意缩放需要繁琐的手工调整,而且仍然经常产生次优的精度和效率。
-
在本文中,想研究并重新思考扩大ConvNets规模的过程。特别是,本文研究了一个核心问题:是否有一种原则性的方法来扩大ConvNets的规模,以达到更好的准确性和效率?本文的实证研究表明, 平 衡 网 络 的 宽 度 / 深 度 / 分 辨 率 等 所 有 维 度 是 至 关 重 要 的 \textcolor{blue}{平衡网络的宽度/深度/分辨率等所有维度是至关重要的} 平衡网络的宽度/深度/分辨率等所有维度是至关重要的,而令人惊讶的是,这种平衡可以通过简单地 以 恒 定 的 比 例 扩 展 它 们 来 实 现 \textcolor{red}{以恒定的比例扩展它们来实现} 以恒定的比例扩展它们来实现。基于这一观察,提出了一种简单而有效的复合缩放方法。
-
这篇论文主要是用NAS(Neural Architecture Search)技术来搜索网络的图像输入分辨率r ,网络的深度depth以及channel的宽度width三个参数的合理化配置。
-
与传统的做法不同,本文的方法是用一组固定的缩放系数来统一缩放网络的宽度、深度和分辨率。例如,如果想使用 2 N 2^N 2N倍的计算资源,那么本文可以简单地将网络深度增加 α N α^N αN,宽度增加 β N β^N βN,图像大小增加 γ N γ^N γN,其中α、β、γ是由原始小模型上的小网络搜索确定的常数系数。下图说明了本文的缩放方法与传统方法之间的区别。
-
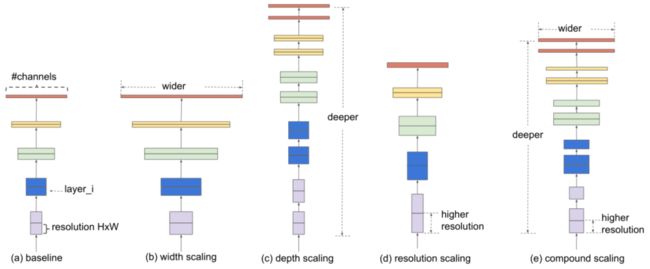
-
Model Scaling.
- (a)是一个基线网络例子;
- (b)-(d)是传统的缩放方法,只增加网络宽度、深度或分辨率的一个维度。
- (e)是本文提出的复合缩放方法,以一个固定的比例统一缩放所有三个维度。
-
-
直观地说,复合缩放法是有意义的,因为如果输入的图像更大,那么网络就需要更多的层来增加感受野和更多的通道来捕捉更大图像上更精细的图案。事实上,之前的理论(Raghu等人,2017;Lu等人,2018)和实证结果(Zagoruyko & Komodakis,2016)都表明,网络宽度和深度之间存在一定的关系,但据本文所知,本文是第一个对网络宽度、深度和分辨率这三个维度之间的关系进行实证量化的。
-
本文证明了本文的复合扩展方法在现有的MobileNets(Howard等人,2017;Sandler等人,2018)和ResNet(He等人,2016)上运行良好。
-
值得注意的是,模型扩展的有效性在很大程度上取决于基线网络;为了更进一步,本文使用神经架构搜索(Zoph & Le, 2017; Tan et al., 2019)来开发一个新的基线网络,并将其扩展以获得一个模型系列,称为EfficientNets。下图总结了ImageNet的性能,其中本文的EfficientNets明显优于其他ConvNets。
-

-
Model Size vs. ImageNet Accuracy.
-
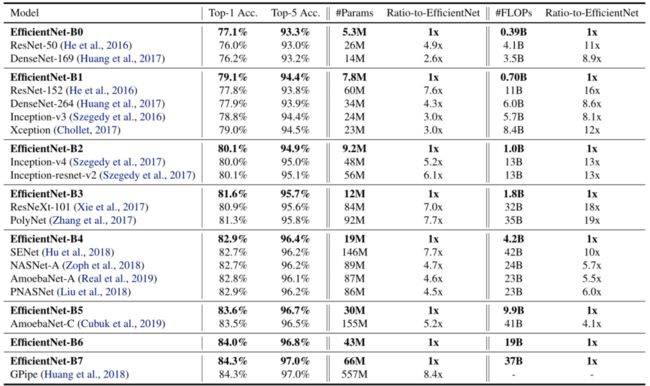
所有数字均为single-crop, single-model。本文的EfficientNets的表现明显优于其他ConvNets。特别是,EfficientNet-B7达到了最先进的84.3%的最高准确率,而且比GPipe小8.4倍,快6.1倍。EfficientNet-B1比ResNet-152小7.6倍,快5.7倍。
-
-
特别是,本文的EfficientNet-B7超过了现有最好的GPipe精度(Huang等人,2018),但使用的参数少了8.4倍,推理时运行速度快了6.1倍。与广泛使用的ResNet-50(He等人,2016)相比,本文的EfficientNet-B4在相似的FLOPS下将top-1的准确率从76.3%提高到83.0%(+6.7%)。
-
除了ImageNet,EfficientNets也能很好地迁移泛化效果,并在8个广泛使用的数据集中的5个上达到最先进的精度,同时比现有的ConvNets减少了21倍的参数。
-
卷积神经网络(cnn)通常是以固定的资源成本开发,然后在更多资源加入进来时扩大规模,以达到更高精度。例如,ResNet可以通过增加层数将 ResNet-18扩展到 ResNet-200,GPipe通过将 CNN baseline扩展4倍,在 ImageNet上实现了84.3% 的准确率。
-
传统的模型缩放实践是任意增加 CNN 的深度或宽度,或使用更大的输入图像分辨率进行训练和评估。 虽然这些方法确实提高了准确性,但它们通常需要长时间的手动调优,并且仍然会经常产生次优的性能。 ICML的一篇文章提出了一个更有原则性的方法来扩大 CNN 的规模,从而可以获得更好的准确性和效率。
Related Work
ConvNet Accuracy
- 自从AlexNet(Krizhevsky等人,2012)赢得2012年ImageNet竞赛以来,ConvNets通过变大而变得越来越准确:2014年ImageNet冠军GoogleNet(Szegedy等人,2015)用大约6.8M的参数实现了74.8%的top-1准确率,而2017年ImageNet冠军SENet(Hu等人,2018)用145M参数实现了82.7%的top-1准确率。
- GPipe(Huang等人,2018)使用557M的参数将最先进的ImageNet top-1验证准确率进一步推高到84.3%:它是如此之大,以至于只能通过分割网络并将每个部分分散到不同的加速器中,用专门的流水线并行库来训练。
- 虽然这些模型主要是为ImageNet设计的,但研究表明,更好的ImageNet模型在各种迁移学习数据集(Kornblith等人,2019),以及其他计算机视觉任务(如物体检测)中也表现得更好(He等人,2016;Tan等人,2019)。
- 虽然更高的精度对许多应用来说至关重要,但已经遇到了硬件内存的限制,因此进一步提高精度需要更好的效率。
ConvNet Efficiency
- 深度ConvNets经常被过度参数化。模型压缩(Han等人,2016;He等人,2018;Yang等人,2018)是一种常见的方法,通过用准确性换取效率来减少模型的大小。
- 随着手机变得无处不在,手工设计高效的移动尺寸ConvNets也很常见,例如SqueezeNets(Iandola等人,2016;Gholami等人,2018)、MobileNets(Howard等人,2017;Sandler等人,2018)和ShuffleNets(Zhang et al., 2018; Ma et al., 2018)。
- 后来,神经结构搜索在设计高效的移动尺寸ConvNets方面变得越来越流行(Tan等人,2019;Cai等人,2019),通过广泛地调整网络宽度、深度、卷积核类型和尺寸,达到比手工制作的移动ConvNets更好的效率。
- 然而,此前的工作还不清楚如何将这些技术应用于具有更大设计空间和更昂贵调谐成本的大型模型。在本文中,本文的目标是研究超过最先进精度的超大型卷积网络的模型效率。为了实现这一目标,本文采用了模型的缩放。
Model Scaling
- 针对不同的资源限制,有很多方法来扩展ConvNet。ResNet(He等人,2016)可以通过调整网络深度(#层的数量)来缩小(如ResNet-18)或增加(如ResNet-200),而WideResNet(Zagoruyko和Komodakis,2016)和MobileNets(Howard等人,2017)可以通过网络宽度(#通道)来扩展。
- 人们也清楚地认识到,更大的输入图像尺寸将有助于准确度,并有更多FLOPs的开销。尽管之前的研究(Raghu等人,2017;Lin & Jegelka,2018;Sharir & Shashua,2018;Lu等人,2018)表明,网络深度和宽度对ConvNets的表达能力都很重要,但如何有效地扩展ConvNet以实现更好的效率和准确性仍然是一个开放的问题。
- 本文的工作系统地、实证地研究了ConvNet在网络宽度、深度和分辨率三个维度上的扩展。
Compound Model Scaling
- 本文将定义了缩放问题,研究不同的方法,并提出本文新的缩放方法。
Problem Formulation
-
一个ConvNet层 i 可以被定义为一个函数。 Y i = F i ( X i ) Y_i = \mathcal{F}_i(X_i) Yi=Fi(Xi),其中 F i \mathcal{F}_i Fi是算子,Yi是输出张量,Xi是输入张量,张量形状为 < H i , W i , C i >
-
在实践中,ConvNet层通常被划分为多个阶段,每个阶段的所有层都有相同的架构:例如,ResNet(He等人,2016)有五个阶段,每个阶段的所有层都有相同的卷积类型,除了第一层执行下采样。因此,本文可以将ConvNet定义为:
-
N = ⊙ i = 1... s F i L i ( X < H I , W i , C i > ) , ( 1 ) \mathcal{N}=\odot_{i=1...s}\mathcal{F}_i^{L_i}(X_{
-
其中 F i L i \mathcal{F}^{Li}_i FiLi表示层Fi在第i阶段重复Li次, < H i , W i , C i >
-
-
与常规的ConvNet设计不同的是,它主要集中在寻找最佳的层结构 F i \mathcal{F}_i Fi,模型缩放试图扩大网络的长度(Li)、宽度(Ci)和/或分辨率(Hi,Wi)而不改变基线网络中预定的Fi。通过固定 F i \mathcal{F}_i Fi,模型缩放简化了新的资源约束的设计问题,但它仍然是一个很大的设计空间,以探索每一层不同的Li、Ci、Hi、Wi。为了进一步减少设计空间,本文限制所有层必须以恒定的比例统一缩放。
-
本文的目标是在任何给定的资源约束下使模型精度最大化,这可以被表述为一个优化问题:
-
max d , w , r A c c u r a c y ( N d , w , r ) s . t . N ( d , w , r ) = ⊙ i = 1... s F ^ i d ⋅ L ^ i ( X < r ⋅ H ^ I , r ⋅ W ^ i , w ⋅ C ^ i > ) M e m o r y ( N ) ≤ t a r g e t _ m e m o r y F L O P s ( N ) ≤ t a r g e t _ F L O P s , ( 2 ) \max\limits_{d,w,r}~Accuracy(\mathcal{N}_{d,w,r})\\ s.t.~~\mathcal{N}_{(d,w,r)}=\odot_{i=1...s}\hat{\mathcal{F}}_i^{d·\hat{L}_i}(X_{
-
其中w、d、r是缩放网络宽度、深度和分辨率的系数;ˆFi、ˆLi、ˆHi、ˆWi、ˆCi是基线网络中预定的参数,见下表。
-
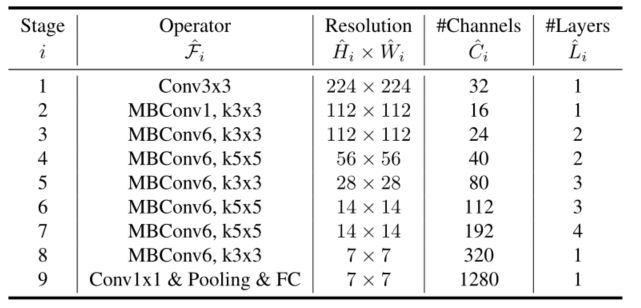
-
EfficientNet-B0基线网络–每一行描述一个具有 L ^ i \hat{L}_i L^i层的阶段i,其输入分辨率h为$ <\hat{H}_i,\hat{W}_i> , 输 出 通 道 为 ,输出通道为 ,输出通道为\hat{C}_i$。
-
EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage,
- 第一个Stage就是一个卷积核大小为3x3步距为2的普通卷积层(包含BN和激活函数Swish),
- Stage2~Stage8都是在重复堆叠MBConv结构(最后一列的Layers表示该Stage重复MBConv结构多少次),
- 而Stage9由一个普通的1x1的卷积层(包含BN和激活函数Swish)一个平均池化层和一个全连接层组成。
-
表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。
-
-
Scaling Dimensions
- 问题2的主要困难是,最佳的d、w、r相互依赖,而且在不同的资源约束下,其数值会发生变化。由于这个困难,传统的方法大多在其中一个维度上对ConvNets进行扩展。
Depth (d):
- 缩放网络深度是许多ConvNets最常用的方式(He等人,2016;Huang等人,2017;Szegedy等人,2015;2016)。其直觉是,更深的ConvNet可以捕获更丰富、更复杂的特征,并在新任务上有很好的概括性。
- 然而,由于梯度消失问题,更深的网络也更难训练(Zagoruyko & Komodakis, 2016)。尽管一些技术,如残差连接(He等人,2016)和批量规一化(Ioffe & Szegedy,2015),缓解了训练问题,但非常深的网络的精度增益会减少:例如,ResNet-1000的精度与ResNet-101类似,尽管它有更多的层。下图(中间)显示了本文对不同深度系数d的基线模型的扩展的经验研究,进一步表明非常深的ConvNets的准确率回报递减。
-

-
Scaling Up a Baseline Model with Different Network Width (w), Depth (d), and Resolution ® Coefficients.
-
具有较大宽度、深度或分辨率的大型网络往往能达到较高的精度,但精度的提高在达到80%后很快就饱和了,这表明了单维扩展的局限。
-
Width (w):
- 缩放网络宽度通常用于小尺寸模型(Howard等人,2017;Sandler等人,2018Tan等人,2019)2。正如(Zagoruyko & Komodakis, 2016)所讨论的,更宽的网络往往能够捕捉到更精细的特征,更容易训练。然而,极宽但浅的网络往往难以捕捉到更高层次的特征。本文在上图(左)中的经验结果显示,当网络变得更宽、w值更大时,准确率会迅速饱和。
Resolution ®:
-
有了更高的分辨率的输入图像,ConvNets有可能捕捉到更精细的模式。从早期ConvNets的224x224开始,现代ConvNets倾向于使用299x299(Szegedy等人,2016)或331x331(Zoph等人,2018)以获得更好的准确性。最近,GPipe(Huang等人,2018)用480x480的分辨率实现了最先进的ImageNet准确性。更高的分辨率,如600x600,也被广泛用于物体检测ConvNets(He等人,2017;Lin等人,2017)。上图(右)显示了缩放网络分辨率的结果,的确,更高的分辨率可以提高准确率,但对于非常高的分辨率来说,准确率的提高会减弱(r=1.0表示分辨率为224x224,r=2.5表示分辨率为560x560)。
-
上述分析使本文得出了第一个看法
- O b s e r v a t i o n 1 : 扩 大 网 络 宽 度 、 深 度 或 分 辨 率 的 任 何 维 度 都 能 提 高 精 确 度 , 但 对 于 更 大 的 模 型 来 说 , 精 确 度 的 提 高 会 减 弱 。 \textcolor{red}{Observation 1:扩大网络宽度、深度或分辨率的任何维度都能提高精确度,但对于更大的模型来说,精确度的提高会减弱。} Observation1:扩大网络宽度、深度或分辨率的任何维度都能提高精确度,但对于更大的模型来说,精确度的提高会减弱。
Compound Scaling
-
本文根据经验观察到,不同的缩放维度是不独立的。
-
直观地说,对于更高分辨率的图像,本文应该增加网络深度,这样更大的感受野可以帮助捕捉类似的特征,包括更大图像中的更多像素。相应地,当分辨率较高时,本文也应该增加网络的宽度,以便在高分辨率的图像中捕捉到更多像素的细微模式。
-
这些直觉表明,需要协调和平衡不同的缩放维度,而不是传统的单一维度的缩放。
-
为了验证本文的直觉,本文比较了不同网络深度和分辨率下的宽度缩放,如下图所示。
-
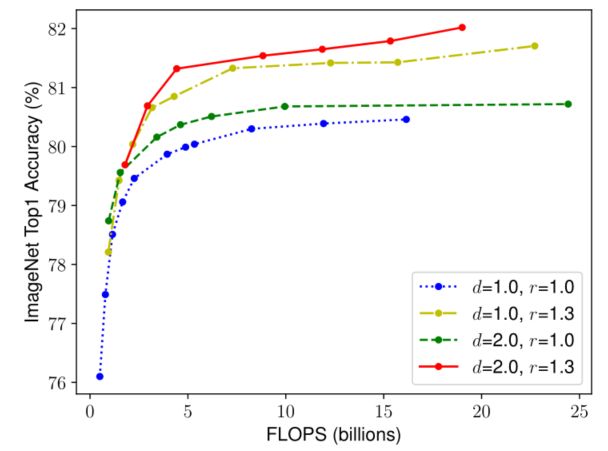
-
Scaling Network Width for Different Baseline Networks.
-
每条线上的点表示一个具有不同宽度系数(w)的模型。所有基线网络都来自表EfficientNet-B0 baseline network。第一个基线网络(d=1.0,r=1.0)有18个卷积层,分辨率为224x224,而最后一个基线(d=2.0,r=1.3)有36层,分辨率为299x299。
-
-
如果只缩放网络宽度w而不改变深度(d=1.0)和分辨率(r=1.0),准确性很快就会饱和。随着深度(d=2.0)和分辨率(r=2.0)的提高,在相同的FLOPS成本下,宽度的扩展可以达到更好的精度。这些结果使本文得出第二个观察结果。
- O b s e r v a t i o n 2 : 为 了 追 求 更 好 的 准 确 性 和 效 率 , 在 C o n v N e t 扩 展 过 程 中 , 平 衡 网 络 宽 度 、 深 度 和 分 辨 率 等 所 有 维 度 至 关 重 要 。 \textcolor{red}{Observation 2 :为了追求更好的准确性和效率,在ConvNet扩展过程中,平衡网络宽度、深度和分辨率等所有维度至关重要。} Observation2:为了追求更好的准确性和效率,在ConvNet扩展过程中,平衡网络宽度、深度和分辨率等所有维度至关重要。
-
事实上,之前的一些工作(Zoph等人,2018;Real等人,2019)已经试图任意平衡网络宽度和深度,但都需要繁琐的人工调整。
-
在本文中,本文提出了一种新的复合缩放方法,即使用复合系数φ以一种原则性的方式均匀地缩放网络宽度、深度和分辨率。
-
d e p t h : d = α ϕ w i d t h : w = β ϕ r e s o l u t i o n : r = γ ϕ s . t . α ⋅ β 2 ⋅ γ 2 ≈ 2 α ≥ 1 , β ≥ 1 , γ ≥ 1 , ( 3 ) depth:d=\alpha^\phi\\ width:w=\beta^\phi\\ resolution:r=\gamma^\phi\\ s.t.~~\alpha·\beta^2·\gamma^2≈2\\ \alpha\geq1,\beta\geq1,\gamma\geq1,(3) depth:d=αϕwidth:w=βϕresolution:r=γϕs.t. α⋅β2⋅γ2≈2α≥1,β≥1,γ≥1,(3)
-
其中,α、β、γ是常数,可以通过小网格搜索来确定。直观地说,φ是一个用户指定的系数,它控制了多少更多的资源可用于模型扩展,而α、β、γ分别指定了如何将这些额外的资源分配给网络宽度、深度和分辨率。
-
-
值得注意的是,常规卷积运算的FLOPS与 d 、 w 2 、 r 2 d、w^2、r^2 d、w2、r2成正比,即网络深度翻倍将使FLOPs翻倍,但网络宽度或分辨率翻倍将使FLOPs增加4倍。
-
由于卷积运算通常在ConvNets的计算成本中占主导地位,用上等式3扩展ConvNet将使总FLOPs大约增加 ( α ⋅ β 2 ⋅ γ 2 ) φ (α·β^2·γ^2)^φ (α⋅β2⋅γ2)φ。在本文中,本文约束 α ⋅ β 2 ⋅ γ 2 ≈ 2 α·β^2·γ^2≈2 α⋅β2⋅γ2≈2,这样对于任何新的φ,总FLOPS将大约增加 2 φ 2^φ 2φ。
EfficientNet Architecture
-
由于模型的缩放不会改变基线网络中的层算子ˆFi,因此拥有一个好的基线网络也是至关重要的。本文将使用现有的ConvNets来评估本文的缩放方法,但是为了更好地证明我们的缩放方法的有效性,本文还开发了一个新的适用于移动产品的基线,称为EfficientNet。
-
受(Tan等人,2019)的启发,本文通过利用多目标神经架构搜索来开发本文的基线网络,以优化准确性和FLOPS。具体来说,本文使用与(Tan等人,2019)相同的搜索空间,并使用 A C C ( m ) × [ F L O P S ( m ) T ] w ACC(m)×[\frac{FLOPS(m)}{T}]^w ACC(m)×[TFLOPS(m)]w作为优化目标,其中ACC(m)和FLOPS(m)表示模型m的精度和FLOPS,T是目标FLOPS,w=-0.07是用于控制精度和FLOPS之间权衡的超参数。
-
与(Tan等人,2019;Cai等人,2019)不同,这里本文优化的是FLOPS而不是延迟,因为本文不针对任何特定的硬件设备。本文的搜索产生了一个高效的网络,本文称之为EfficientNet-B0。
-
由于本文使用的搜索空间与(Tan et al., 2019)相同,所以架构与MnasNet类似,只是本文的EfficientNet-B0由于FLOPS目标较大(本文的FLOPS目标是400M),所以规模稍大。上表EfficientNet-B0基线网络显示了EfficientNet-B0的架构。它的主要构件是移动倒置瓶颈MBConv(Sandler等人,2018;Tan等人,2019),本文还在其中加入了挤压和激发优化(Hu等人,2018)。
-
MBConv其实就是MobileNetV3网络中的InvertedResidualBlock,但也有些许区别。一个是采用的激活函数不一样(EfficientNet的MBConv中使用的都是Swish激活函数),另一个是在每个MBConv中都加入了SE模块。
-

-
MBConv结构主要由一个1x1的普通卷积(升维作用,包含BN和Swish),一个kxk的Depthwise Conv卷积(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的普通卷积(降维作用,包含BN),一个Droupout层构成。
-
第一个升维的1x1卷积层,它的卷积核个数是输入特征矩阵channel的n 倍,$ n \in \left{1, 6\right}$。
-
当n = 1时,不要第一个升维的1x1卷积层,即Stage2中的MBConv结构都没有第一个升维的1x1卷积层(这和MobileNetV3网络类似)。
-
关于
shortcut连接,仅当输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时才存在(代码中可通过stride==1 and inputc_channels==output_channels条件来判断)。 -
SE模块如下所示,由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的$ \frac{1}{4} $ ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数。
-
只有使用shortcut的时候才有Dropout层。
-
-
Stochastic Depth(随机深度网络),2016年清华的黄高在ECCV发表
- 提出背景:深度(残差)网络中并不是所有的层都是必要的,有很多层是冗余的,有些分支里权重值相对于别的层可能非常小。
- 随机深度:通过在训练过程中随机丢掉一些层,来优化深度残差网络的训练过程。网络变得简单一点了
- 用随机变量和线性衰减的生存概率原则来dropout
- 对于较深的网络它能够加快训练时间,并提升性能。
- 在训练时缩小的深度(随机在ResNet的基础上丢掉一些层),较少训练时间,提高训练性能
- 在预测时保持较深的深度,可以通过在训练期间随机丢弃整个ResBlock,并通过残差连接绕过它们的转换来实现这个目标。
-
Stochastic_Depth:训练时,加入了随机变量 b(伯努利随机变量),把 b*f,对整个ResBlock卷积部分做了随机丢弃。果b = 1,则简化为原始的ResNet结构;如果b = 0,则这个ResBlock未被激活,降为恒等函数。
-
伯努利分布(0-1分布),它的随机变量只取0或1,0频率是1−p,1的频率是p。
-
H l = R e L U ( b l f l ( H l − 1 ) + i d e n t y ( H l − 1 ) ) H_l=ReLU(b_lf_l(H_{l-1})+identy(H_{l-1})) Hl=ReLU(blfl(Hl−1)+identy(Hl−1))
-
-
-
从基线EfficientNet-B0开始,应用本文的复合扩展方法,分两步进行扩展。
-
STEP 1: 本文首先固定φ=1,假设有两倍的可用资源,并根据上文等式2和3对α、β、γ进行小网格搜索。特别是,本文发现EfficientNet-B0的最佳值是α=1.2,β=1.1,γ=1.15,在 α ⋅ β 2 ⋅ γ 2 ≈ 2 α·β^2·γ^2≈2 α⋅β2⋅γ2≈2的约束条件下。
-
第2步:然后本文将α、β、γ固定为常数,用上等式3将不同φ的基线网络放大,得到EfficientNet-B1至B7(详见下表)。
-
-
EfficientNet Performance Results on ImageNet
-
所有的EfficientNet模型都是在基线EfficientNet-B0的基础上,通过上等式3中不同的复合系数φ进行扩展。为了比较效率,本文将准确率排名前1/前5的ConvNets归为一组。
-
与现有的ConvNets相比,本文缩放后的EfficientNet模型持续减少了一个数量级的参数和FLOPS(最多可减少8.4倍的参数,最多可减少16倍FLOPS)。
-
本文省略了集合和多目标模型(Hu等人,2018),或在3.5B Instagram图像上预训练的模型(Mahajan等人,2018)。
-
-
值得注意的是,通过直接在大模型周围搜索α、β、γ,有可能获得更好的性能,但在更大的模型上,搜索成本变得过于昂贵。本文的方法解决了这个问题,只在小型基线网络上做一次搜索(第1步),然后对所有其他模型使用相同的缩放系数(第2步)。

Experiments
- 在本节中将首先在现有的ConvNets和新提出的EfficientNets上评估本文的缩放方法。
Scaling Up MobileNets and ResNets
- 作为一个概念证明,首先将本文的缩放方法应用于广泛使用的MobileNets(Howard等人,2017;Sandler等人,2018)和ResNet(He等人,2016)。下表显示了以不同方式对它们进行缩放的ImageNet结果。与其他单维缩放方法相比,本文的复合缩放方法提高了所有这些模型的准确性,表明本文提出的缩放方法对一般现有ConvNets的有效性。
-
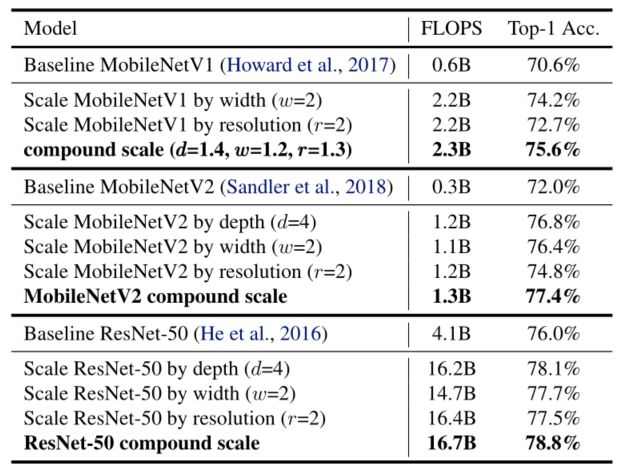
-
Scaling Up MobileNets and ResNet.
-
ImageNet Results for EfficientNet
-
本文使用与(Tan等人,2019)类似的设置在ImageNet上训练我们的EfficientNet模型。RMSProp优化器的衰减为0.9,动量为0.9;批量规范动量为0.99,权重衰减1e-5;初始学习率0.256,每2.4个epochs衰减0.97。
-
本文还使用SiLU(Swish-1)激活(Ramachandran等人,2018;Elfwing等人,2018;Hendrycks & Gimpel,2016)、AutoAugment(Cubuk等人,2019)和随机深度(Huang等人,2016),生存概率为0.8。
- SiLU:按元素应用 Sigmoid 线性单元 (SiLU) 函数。SiLU 函数也称为 swish 函数。
- silu(x)=x∗σ(x),其中 σ(x) 是逻辑 sigmoid。
- SiLU:按元素应用 Sigmoid 线性单元 (SiLU) 函数。SiLU 函数也称为 swish 函数。
-
众所周知,更大的模型需要更多的正则化,因此本文将dropout(Srivastava等人,2014)从EfficientNet-B0的0.2线性增加到B7的0.5。本文从训练集中随机抽取25K图像作为最小集,并对该最小集进行提前停止;然后在原始验证集上评估提前停止的检查点,以报告最终的验证精度。
-
表EfficientNet Performance Results on ImageNet显示了从同一基线EfficientNet-B0扩展而来的所有EfficientNet模型的性能。
-
本文的EfficientNet模型与其他具有相似精度的ConvNets相比,使用的参数和FLOPS通常要少一个数量级。特别是,本文的EfficientNet-B7以66M的参数和37B的FLOPS实现了84.3%的top1准确率,比之前最好的GPipe(Huang等人,2018)更准确,但体积小了8.4倍。这些收益既来自于更好的架构、更好的扩展,也来自于为EfficientNet定制的更好的训练设置。
-
**图Model Size vs. ImageNet Accuracy.**和下图显示了代表性ConvNets的参数-精度和FLOPS-精度曲线,与其他ConvNets相比,本文的按比例排列的EfficientNet模型以更少的参数和FLOPS获得了更好的精度。
-

-
FLOPS vs. ImageNet Accuracy
-
与图Model Size vs. ImageNet Accuracy类似,只是它比较的是FLOPS而不是模型大小。
-
-
值得注意的是,本文的EfficientNet模型不仅体积小,而且计算成本更低。例如,本文的EfficientNet-B3比ResNeXt101(Xie等人,2017)使用18倍的FLOPS实现了更高的精度。
-
为了验证延迟,本文还测量了几个有代表性的CovNets在实际CPU上的推理延迟,如下表所示,本文报告了20次运行的平均延迟。
-

-
Inference Latency Comparison:延时是在英特尔至强CPU E5-2690的单核上用批处理量1测得的。
-
-
本文的EfficientNet-B1比广泛使用的ResNet-152快5.7倍,而EfficientNet-B7比GPipe(Huang等人,2018)快6.1倍,这表明本文的EfficientNets在实际硬件上确实很快速。
Transfer Learning Results for EfficientNet
-
本文还在一列常用的迁移学习数据集上评估了本文的EfficientNet,如下表所示。本文借用(Kornblith等人,2019)和(Huang等人,2018)的相同训练设置,采取ImageNet预训练的检查点,在新的数据集上进行微调:
-

-
Transfer Learning Datasets.Transfer Learning Results for EfficientNet
-
-
下表显示了迁移学习的性能:
-
(1)与公开的可用模型,如NASNet-A(Zoph等人,2018)和Inception-v4(Szegedy等人,2017)相比,本文的EfficientNet模型以平均4.7倍(最多21倍)的参数减少实现了更好的准确性。
-
(2)与先进的模型相比,包括动态合成训练数据的DAT(Ngiam等人,2018)和用专门的流水线并行训练的GPipe(Huang等人,2018),本文的EfficientNet模型在8个数据集中的5个仍然超过了它们的准确性,但使用的参数减少了9.6倍
-
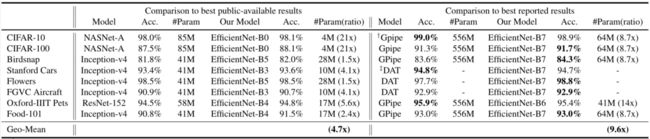
- EfficientNet Performance Results on Transfer Learning Datasets.
- 本文扩展的EfficientNet模型在8个数据集中的5个取得了新的最先进的准确性,参数平均减少9.6倍。
- GPipe(Huang等人,2018)用专门的流水线并行性库训练巨型模型。
- DAT表示领域自适应迁移学习(Ngiam等人,2018)。这里本文只比较基于ImageNet的迁移学习结果。
- NASNet(Zoph等人,2018)、Inception-v4(Szegedy等人,2017)、ResNet-152(He等人,2016)的传输精度和#参数来自(Kornblith等人,2019)。
-
-
下图比较了各种模型的准确性-参数曲线。一般来说,本文的EfficientNets在参数较少的情况下,始终比现有的模型,包括ResNet(He等人,2016)、DenseNet(Huang等人,2017)、Inception(Szegedy等人,2017)和NASNet(Zoph等人,2018)取得更好的准确性。
-
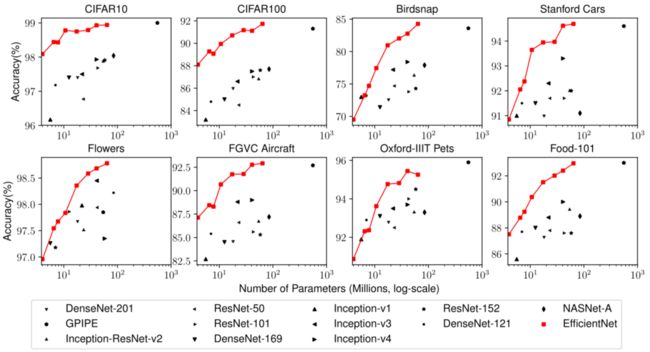
-
Model Parameters vs. Transfer Learning Accuracy
-
所有模型都在ImageNet上进行了预训练,并在新数据集上进行了微调。
-
Discussion
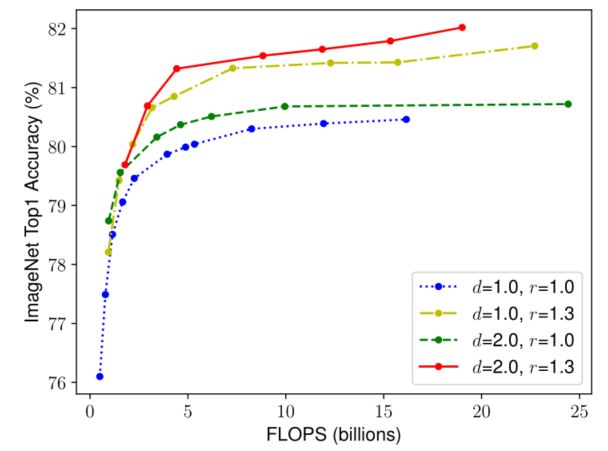
- 为了区分本文提出的缩放方法与EfficientNet架构的贡献,下图比较了不同缩放方法对同一EfficientNet-B0基线网络的ImageNet性能。
-
-
Scaling Up EfficientNet-B0 with Different Methods.
-
- 一般来说,所有的缩放方法都是以更多的FLOPS为代价来提高准确性,但是本文的复合缩放方法可以进一步提高准确性,比其他单一维度的缩放方法提高2.5%,这说明本文提出的复合缩放的重要性。
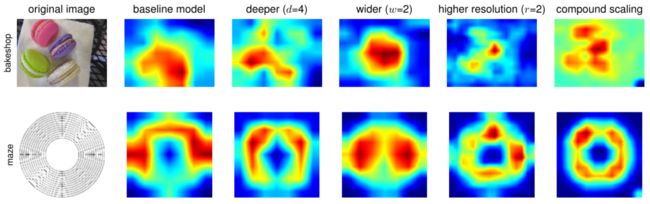
- 为了进一步了解为什么本文的复合缩放方法比其他方法更好,下图比较了几个具有代表性的模型的不同缩放方法的类激活图(Zhou等人,2016)。
-
-
不同缩放方法的模型的类激活图(CAM)(Zhou等人,2016)–本文的复合缩放方法使缩放后的模型(最后一栏)集中在更多的相关区域,有更多的物体细节。模型细节见下表。
-
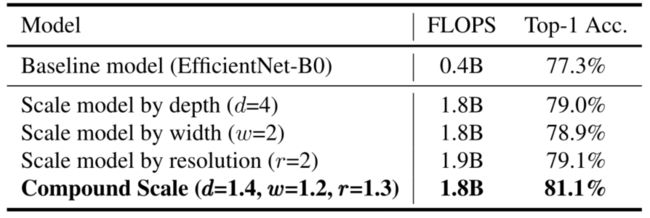
-
上图中使用的比例模型。
-
- 所有这些模型都是从同一基线上进行缩放的,它们的统计数字见上表。图像是从ImageNet验证集中随机抽取的。如图所示,复合缩放的模型倾向于关注具有更多物体细节的相关区域,而其他模型要么缺乏物体细节,要么无法捕获图像中的所有物体。
Conclusion
- 在本文中,本文系统地研究了ConvNet的扩展,发现仔细平衡网络的宽度、深度和分辨率是一个重要但缺失的部分,使模型无法获得更好的准确性和效率。
- 为了解决这个问题,本文提出了一种简单而高效的复合扩展方法,它使我们能够以一种更有准则的方式轻松地将基线ConvNet扩展到任何目标资源限制,同时保持模型的效率。
- 在这种复合扩展方法的支持下,本文证明了一个移动版的EfficientNet模型可以非常有效地扩展,在ImageNet和五个常用的迁移学习数据集上,以较少的参数和FLOPs超过了最先进的精度。
Appendix
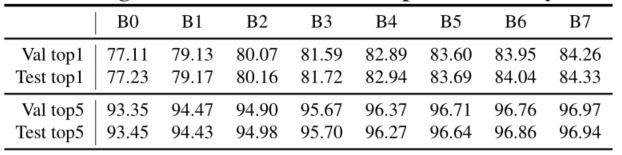
- 自2017年以来,大多数研究论文只报告和比较ImageNet的验证准确性;本文也遵循这一惯例,以便更好地进行比较。此外,还通过将本文对100k测试集图像的预测提交到http://image-net.org,验证了测试精度;结果见下表。正如预期的那样,测试精度与验证精度非常接近。
-
-
ImageNet验证与测试的Top-1/5准确率。
-