python与深度学习(九):CNN和cifar10
目录
- 1. 说明
- 2. cifar10实战
-
- 2.1 导入相关库
- 2.2 加载数据
- 2.3 数据预处理
- 2.4 数据处理
- 2.5 构建网络模型
- 2.6 模型编译
- 2.7 模型训练
- 2.8 模型保存
- 2.9 模型评价
- 2.10 模型测试
- 2.11 模型训练结果的可视化
- 3. cifar10的CNN模型可视化结果图
- 4. 完整代码
- 5. 改进后的代码和结果
1. 说明
本篇文章是CNN的另外一个例子,cifar10,是彩色的十分类数据集。
可以搭建卷积神经网络来训练模型。
2. cifar10实战
2.1 导入相关库
以下第三方库是python专门用于深度学习的库
# 导入tensorflow
import tensorflow as tf
# 导入keras
from tensorflow import keras
from keras.datasets import cifar10
# 引入绘制acc和loss曲线的库
import matplotlib.pyplot as plt
# 引入ANN的必要的类
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten
from keras.models import Sequential
from keras import optimizers, losses
from keras.preprocessing.image import ImageDataGenerator
2.2 加载数据
把cifar10数据集进行加载
x_train是fashion_mnist训练集图片,大小的32323的,y_train是对应的标签是数字。
x_test是fashion_mnist测试集图片,大小的32323的,y_test是对应的标签是数字。
因为y的形状是(None,1)的,如果直接进行独热编码会变成(None,1,10),会和神经网络的输出形状(None,10)不匹配,因此需要对独热编码之前的y的形状进行降维处理变成(None,)。
"1.加载数据"
"""
x_train是fashion_mnist训练集图片,大小的32*32*3的,y_train是对应的标签是数字
x_test是fashion_mnist测试集图片,大小的32*32*3的,y_test是对应的标签是数字
"""
(x_train, y_train), (x_test, y_test) = cifar10.load_data() # 加载cifar10数据集
print('mnist_data:', x_train.shape, y_train.shape, x_test.shape, y_test.shape) # 打印训练数据和测试数据的形状
"""
因为y的形状是(None,1)的,如果直接进行独热编码会变成(None,1,10),会和神经网络的输出形状(None,10)不匹配,
因此需要对独热编码之前的y的形状进行降维处理变成(None,)
"""
y_train = tf.squeeze(y_train, axis=1)
y_test = tf.squeeze(y_test, axis=1)
2.3 数据预处理
(1) 将输入的图片进行归一化,从0-255变换到0-1;
(2) 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数, 计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算 独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0。
def preprocess(x, y): # 数据预处理函数
x = tf.cast(x, dtype=tf.float32) / 255. # 将输入的图片进行归一化,从0-255变换到0-1
y = tf.cast(y, dtype=tf.int32) # 将输入图片的标签转换为int32类型
y = tf.one_hot(y, depth=10)
"""
# 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数,
计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算
独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0
"""
return x, y
2.4 数据处理
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
batchsz = 128 # 每次输入给神经网络的图片数
"""
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
"""
db = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建训练集对象
db = db.map(preprocess).shuffle(60000).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集对象
ds_val = ds_val.map(preprocess).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
2.5 构建网络模型
构建了两层卷积层,两层池化层,然后是展平层(将二维特征图拉直输入给全连接层),然后是三层全连接层。
"3.构建网络模型"
model = Sequential([Conv2D(filters=6, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Conv2D(filters=16, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Flatten(),
Dense(120, activation='relu'),
Dense(84, activation='relu'),
Dense(10,activation='softmax')])
model.build(input_shape=(None, 32, 32, 3)) # 模型的输入大小
model.summary() # 打印网络结构
2.6 模型编译
模型的优化器是Adam,另外一种优化方法,学习率是0.01,
损失函数是losses.CategoricalCrossentropy,多分类交叉熵,
性能指标是正确率accuracy。
"4.模型编译"
model.compile(optimizer='Adam',
loss=losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
"""
模型的优化器是Adam
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"""
2.7 模型训练
模型训练的次数是20,每1次循环进行测试
"5.模型训练"
history = model.fit(db, epochs=20, validation_data=ds_val, validation_freq=1)
"""
模型训练的次数是20,每1次循环进行测试
"""
2.8 模型保存
以.h5文件格式保存模型
"6.模型保存"
model.save('cnn_cifar10.h5') # 以.h5文件格式保存模型
2.9 模型评价
得到测试集的正确率
"7.模型评价"
model.evaluate(ds_val) # 得到测试集的正确率
2.10 模型测试
对模型进行测试
"8.模型测试"
sample = next(iter(ds_val)) # 取一个batchsz的测试集数据
x = sample[0] # 测试集数据
y = sample[1] # 测试集的标签
pred = model.predict(x) # 将一个batchsz的测试集数据输入神经网络的结果
pred = tf.argmax(pred, axis=1) # 每个预测的结果的概率最大值的下标,也就是预测的数字
y = tf.argmax(y, axis=1) # 每个标签的最大值对应的下标,也就是标签对应的数字
print(pred) # 打印预测结果
print(y) # 打印标签类别
2.11 模型训练结果的可视化
对模型的训练结果进行可视化
"9.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy'] # 获取模型训练中的accuracy
val_acc = history.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = history.history['loss'] # 获取模型训练中的loss
val_loss = history.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show() # 将结果显示出来
3. cifar10的CNN模型可视化结果图
Epoch 1/20
391/391 [==============================] - 20s 44ms/step - loss: 1.7699 - accuracy: 0.3471 - val_loss: 1.5087 - val_accuracy: 0.4547
Epoch 2/20
391/391 [==============================] - 20s 49ms/step - loss: 1.4580 - accuracy: 0.4737 - val_loss: 1.4031 - val_accuracy: 0.4884
Epoch 3/20
391/391 [==============================] - 21s 51ms/step - loss: 1.3519 - accuracy: 0.5168 - val_loss: 1.3040 - val_accuracy: 0.5345
Epoch 4/20
391/391 [==============================] - 21s 51ms/step - loss: 1.2646 - accuracy: 0.5506 - val_loss: 1.2333 - val_accuracy: 0.5646
Epoch 5/20
391/391 [==============================] - 19s 47ms/step - loss: 1.2030 - accuracy: 0.5753 - val_loss: 1.2309 - val_accuracy: 0.5673
Epoch 6/20
391/391 [==============================] - 19s 46ms/step - loss: 1.1519 - accuracy: 0.5941 - val_loss: 1.1947 - val_accuracy: 0.5716
Epoch 7/20
391/391 [==============================] - 18s 44ms/step - loss: 1.1104 - accuracy: 0.6088 - val_loss: 1.1496 - val_accuracy: 0.5987
Epoch 8/20
391/391 [==============================] - 19s 46ms/step - loss: 1.0726 - accuracy: 0.6235 - val_loss: 1.1330 - val_accuracy: 0.6031
Epoch 9/20
391/391 [==============================] - 19s 47ms/step - loss: 1.0393 - accuracy: 0.6327 - val_loss: 1.1079 - val_accuracy: 0.6119
Epoch 10/20
391/391 [==============================] - 21s 51ms/step - loss: 1.0149 - accuracy: 0.6440 - val_loss: 1.1023 - val_accuracy: 0.6160
Epoch 11/20
391/391 [==============================] - 19s 47ms/step - loss: 0.9798 - accuracy: 0.6550 - val_loss: 1.0828 - val_accuracy: 0.6265
Epoch 12/20
391/391 [==============================] - 19s 47ms/step - loss: 0.9594 - accuracy: 0.6621 - val_loss: 1.0978 - val_accuracy: 0.6191
Epoch 13/20
391/391 [==============================] - 18s 44ms/step - loss: 0.9325 - accuracy: 0.6709 - val_loss: 1.0803 - val_accuracy: 0.6264
Epoch 14/20
391/391 [==============================] - 20s 49ms/step - loss: 0.9106 - accuracy: 0.6801 - val_loss: 1.0792 - val_accuracy: 0.6212
Epoch 15/20
391/391 [==============================] - 23s 54ms/step - loss: 0.8928 - accuracy: 0.6873 - val_loss: 1.0586 - val_accuracy: 0.6382
Epoch 16/20
391/391 [==============================] - 20s 50ms/step - loss: 0.8695 - accuracy: 0.6931 - val_loss: 1.0825 - val_accuracy: 0.6303
Epoch 17/20
391/391 [==============================] - 22s 54ms/step - loss: 0.8524 - accuracy: 0.6993 - val_loss: 1.0917 - val_accuracy: 0.6296
Epoch 18/20
391/391 [==============================] - 19s 46ms/step - loss: 0.8314 - accuracy: 0.7074 - val_loss: 1.0753 - val_accuracy: 0.6341
Epoch 19/20
391/391 [==============================] - 19s 48ms/step - loss: 0.8117 - accuracy: 0.7136 - val_loss: 1.0701 - val_accuracy: 0.6376
Epoch 20/20
391/391 [==============================] - 20s 50ms/step - loss: 0.7967 - accuracy: 0.7200 - val_loss: 1.0715 - val_accuracy: 0.6376
79/79 [==============================] - 1s 17ms/step - loss: 1.0715 - accuracy: 0.6376
4/4 [==============================] - 0s 6ms/step

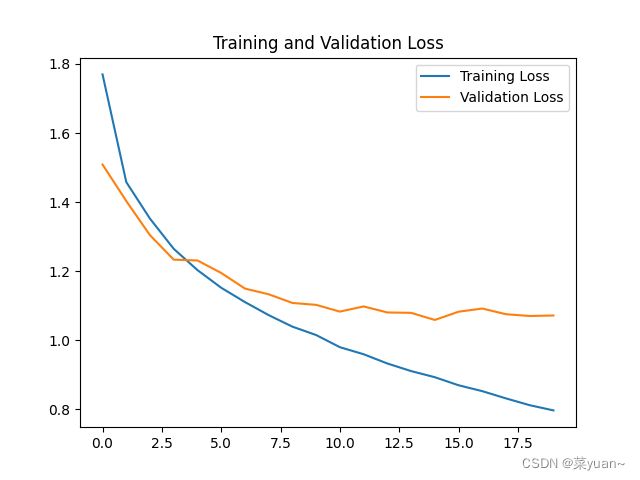
从以上结果可知,模型的准确率达到了63%,太低了,原因是网络结构有点简单,因此进行改变网络结构,同时为了降低过拟合的影响,加入数据增强部分。
4. 完整代码
# 导入tensorflow
import tensorflow as tf
# 导入keras
from tensorflow import keras
from keras.datasets import cifar10
# 引入绘制acc和loss曲线的库
import matplotlib.pyplot as plt
# 引入ANN的必要的类
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten
from keras.models import Sequential
from keras import optimizers, losses
from keras.preprocessing.image import ImageDataGenerator
"1.加载数据"
"""
x_train是fashion_mnist训练集图片,大小的32*32*3的,y_train是对应的标签是数字
x_test是fashion_mnist测试集图片,大小的32*32*3的,y_test是对应的标签是数字
"""
(x_train, y_train), (x_test, y_test) = cifar10.load_data() # 加载cifar10数据集
print('mnist_data:', x_train.shape, y_train.shape, x_test.shape, y_test.shape) # 打印训练数据和测试数据的形状
"""
因为y的形状是(None,1)的,如果直接进行独热编码会变成(None,1,10),会和神经网络的输出形状(None,10)不匹配,
因此需要对独热编码之前的y的形状进行降维处理变成(None,)
"""
y_train = tf.squeeze(y_train, axis=1)
y_test = tf.squeeze(y_test, axis=1)
"2.数据预处理"
def preprocess(x, y): # 数据预处理函数
x = tf.cast(x, dtype=tf.float32) / 255. # 将输入的图片进行归一化,从0-255变换到0-1
y = tf.cast(y, dtype=tf.int32) # 将输入图片的标签转换为int32类型
y = tf.one_hot(y, depth=10)
"""
# 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数,
计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算
独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0
"""
return x, y
batchsz = 128 # 每次输入给神经网络的图片数
"""
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
"""
db = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建训练集对象
db = db.map(preprocess).shuffle(60000).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集对象
ds_val = ds_val.map(preprocess).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
"3.构建网络模型"
model = Sequential([Conv2D(filters=6, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Conv2D(filters=16, kernel_size=(5, 5), activation='relu'),
MaxPool2D(pool_size=(2, 2), strides=2),
Flatten(),
Dense(120, activation='relu'),
Dense(84, activation='relu'),
Dense(10,activation='softmax')])
model.build(input_shape=(None, 32, 32, 3)) # 模型的输入大小
model.summary() # 打印网络结构
"4.模型编译"
model.compile(optimizer='Adam',
loss=losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
"""
模型的优化器是Adam
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"""
"5.模型训练"
history = model.fit(db, epochs=20, validation_data=ds_val, validation_freq=1)
"""
模型训练的次数是20,每1次循环进行测试
"""
"6.模型保存"
model.save('cnn_cifar10.h5') # 以.h5文件格式保存模型
"7.模型评价"
model.evaluate(ds_val) # 得到测试集的正确率
"8.模型测试"
sample = next(iter(ds_val)) # 取一个batchsz的测试集数据
x = sample[0] # 测试集数据
y = sample[1] # 测试集的标签
pred = model.predict(x) # 将一个batchsz的测试集数据输入神经网络的结果
pred = tf.argmax(pred, axis=1) # 每个预测的结果的概率最大值的下标,也就是预测的数字
y = tf.argmax(y, axis=1) # 每个标签的最大值对应的下标,也就是标签对应的数字
print(pred) # 打印预测结果
print(y) # 打印标签类别
"9.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy'] # 获取模型训练中的accuracy
val_acc = history.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = history.history['loss'] # 获取模型训练中的loss
val_loss = history.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show() # 将结果显示出来
5. 改进后的代码和结果
# 导入tensorflow
import tensorflow as tf
# 导入keras
from tensorflow import keras
from keras.datasets import cifar10
# 引入绘制acc和loss曲线的库
import matplotlib.pyplot as plt
# 引入ANN的必要的类
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten, Dropout
from keras.models import Sequential
from keras import optimizers, losses
from keras.preprocessing.image import ImageDataGenerator
"1.加载数据"
"""
x_train是fashion_mnist训练集图片,大小的32*32*3的,y_train是对应的标签是数字
x_test是fashion_mnist测试集图片,大小的32*32*3的,y_test是对应的标签是数字
"""
(x_train, y_train), (x_test, y_test) = cifar10.load_data() # 加载cifar10数据集
print('mnist_data:', x_train.shape, y_train.shape, x_test.shape, y_test.shape) # 打印训练数据和测试数据的形状
image_gen_train = ImageDataGenerator(
rescale=1. / 1., # 如为图像,分母为255时,可归至0~1
rotation_range=45, # 随机45度旋转
width_shift_range=.15, # 宽度偏移
height_shift_range=.15, # 高度偏移
horizontal_flip=False, # 水平翻转
zoom_range=0.5 # 将图像随机缩放阈量50%
)
image_gen_train.fit(x_train)
"""
因为y的形状是(None,1)的,如果直接进行独热编码会变成(None,1,10),会和神经网络的输出形状(None,10)不匹配,
因此需要对独热编码后的y的形状进行降维处理变成(None,10)
"""
y_train = tf.squeeze(y_train, axis=1)
y_test = tf.squeeze(y_test, axis=1)
"2.数据预处理"
def preprocess(x, y): # 数据预处理函数
x = tf.cast(x, dtype=tf.float32) / 255. # 将输入的图片进行归一化,从0-255变换到0-1
y = tf.cast(y, dtype=tf.int32) # 将输入图片的标签转换为int32类型
y = tf.one_hot(y, depth=10)
"""
# 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数,
计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算
独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0
"""
return x, y
batchsz = 128 # 每次输入给神经网络的图片数
"""
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
"""
db = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建训练集对象
db = db.map(preprocess).shuffle(50000).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集对象
ds_val = ds_val.map(preprocess).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
"3.构建网络模型"
model = Sequential([Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu'),
Dropout(0.25),
MaxPool2D(pool_size=(2, 2), strides=2),
Conv2D(filters=64, kernel_size=(3, 3),padding='same', activation='relu'),
Dropout(0.25),
MaxPool2D(pool_size=(2, 2), strides=2),
Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'),
Dropout(0.25),
MaxPool2D(pool_size=(2, 2), strides=2),
Flatten(),
Dense(1024, activation='relu'),
Dense(10,activation='softmax')])
model.build(input_shape=(None, 32, 32, 3)) # 模型的输入大小
model.summary() # 打印网络结构
"4.模型编译"
model.compile(optimizer='Adam',
loss=losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
"""
模型的优化器是Adam
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"""
"5.模型训练"
history = model.fit(db, epochs=20, validation_data=ds_val, validation_freq=1)
"""
模型训练的次数是10,每1次循环进行测试
"""
"6.模型保存"
model.save('cnn_cifar10_4.h5') # 以.h5文件格式保存模型
"7.模型评价"
model.evaluate(ds_val) # 得到测试集的正确率
"8.模型测试"
sample = next(iter(ds_val)) # 取一个batchsz的测试集数据
x = sample[0] # 测试集数据
y = sample[1] # 测试集的标签
pred = model.predict(x) # 将一个batchsz的测试集数据输入神经网络的结果
pred = tf.argmax(pred, axis=1) # 每个预测的结果的概率最大值的下标,也就是预测的数字
y = tf.argmax(y, axis=1) # 每个标签的最大值对应的下标,也就是标签对应的数字
print(pred) # 打印预测结果
print(y) # 打印标签类别
"9.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy'] # 获取模型训练中的accuracy
val_acc = history.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = history.history['loss'] # 获取模型训练中的loss
val_loss = history.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show() # 将结果显示出来
Epoch 1/20
391/391 [==============================] - 109s 272ms/step - loss: 1.4598 - accuracy: 0.4688 - val_loss: 1.2981 - val_accuracy: 0.5713
Epoch 2/20
391/391 [==============================] - 103s 262ms/step - loss: 1.0536 - accuracy: 0.6297 - val_loss: 1.0809 - val_accuracy: 0.6476
Epoch 3/20
391/391 [==============================] - 104s 264ms/step - loss: 0.8955 - accuracy: 0.6840 - val_loss: 0.9347 - val_accuracy: 0.7052
Epoch 4/20
391/391 [==============================] - 103s 262ms/step - loss: 0.7785 - accuracy: 0.7258 - val_loss: 0.9195 - val_accuracy: 0.6880
Epoch 5/20
391/391 [==============================] - 104s 264ms/step - loss: 0.6896 - accuracy: 0.7575 - val_loss: 0.8039 - val_accuracy: 0.7330
Epoch 6/20
391/391 [==============================] - 103s 262ms/step - loss: 0.6085 - accuracy: 0.7864 - val_loss: 0.8141 - val_accuracy: 0.7296
Epoch 7/20
391/391 [==============================] - 102s 261ms/step - loss: 0.5378 - accuracy: 0.8102 - val_loss: 0.7418 - val_accuracy: 0.7463
Epoch 8/20
391/391 [==============================] - 102s 259ms/step - loss: 0.4698 - accuracy: 0.8335 - val_loss: 0.6867 - val_accuracy: 0.7693
Epoch 9/20
391/391 [==============================] - 102s 259ms/step - loss: 0.4042 - accuracy: 0.8563 - val_loss: 0.6729 - val_accuracy: 0.7734
Epoch 10/20
391/391 [==============================] - 103s 261ms/step - loss: 0.3474 - accuracy: 0.8763 - val_loss: 0.6690 - val_accuracy: 0.7696
Epoch 11/20
391/391 [==============================] - 102s 261ms/step - loss: 0.2969 - accuracy: 0.8958 - val_loss: 0.6920 - val_accuracy: 0.7660
Epoch 12/20
391/391 [==============================] - 102s 260ms/step - loss: 0.2597 - accuracy: 0.9072 - val_loss: 0.7243 - val_accuracy: 0.7558
Epoch 13/20
391/391 [==============================] - 102s 259ms/step - loss: 0.2146 - accuracy: 0.9235 - val_loss: 0.7107 - val_accuracy: 0.7599
Epoch 14/20
391/391 [==============================] - 106s 269ms/step - loss: 0.1904 - accuracy: 0.9318 - val_loss: 0.6790 - val_accuracy: 0.7760
Epoch 15/20
391/391 [==============================] - 103s 262ms/step - loss: 0.1703 - accuracy: 0.9404 - val_loss: 0.7177 - val_accuracy: 0.7706
Epoch 16/20
391/391 [==============================] - 103s 262ms/step - loss: 0.1526 - accuracy: 0.9463 - val_loss: 0.7038 - val_accuracy: 0.7781
Epoch 17/20
391/391 [==============================] - 103s 262ms/step - loss: 0.1333 - accuracy: 0.9520 - val_loss: 0.7267 - val_accuracy: 0.7770
Epoch 18/20
391/391 [==============================] - 103s 263ms/step - loss: 0.1253 - accuracy: 0.9576 - val_loss: 0.7518 - val_accuracy: 0.7728
Epoch 19/20
391/391 [==============================] - 103s 263ms/step - loss: 0.1210 - accuracy: 0.9570 - val_loss: 0.7855 - val_accuracy: 0.7670
Epoch 20/20
391/391 [==============================] - 104s 265ms/step - loss: 0.1105 - accuracy: 0.9607 - val_loss: 0.8065 - val_accuracy: 0.7721
79/79 [==============================] - 4s 48ms/step - loss: 0.8065 - accuracy: 0.7721
4/4 [==============================] - 0s 15ms/step

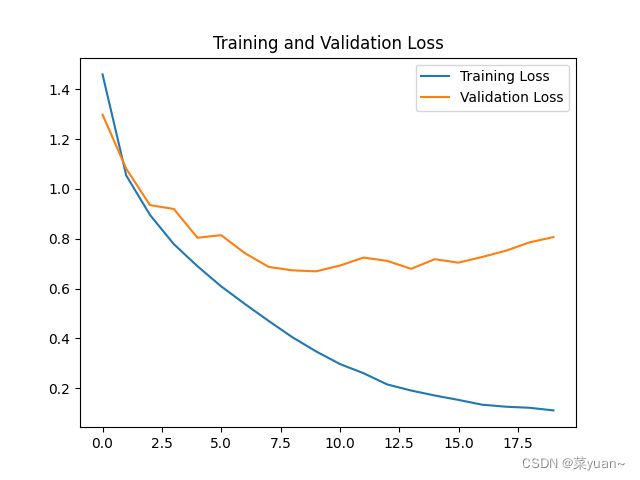
结果有所改善,但是过拟合仍然存在。