【NLP经典论文精读】Improving Language Understanding by Generative Pre-Training
Improving Language Understanding by Generative Pre-Training
- 前言
- Abstract
- 1. Introduction
- 2. Related Work
-
- Semi-supervised learning for NLP
- Unsupervised pre-training
- Auxiliary training objectives
- 3. Framework
-
- 3.1 Unsupervised pre-training
- 3.2 Supervised fine-tuning
- 3.3 Task-specific input transformations
-
- Textual entailment
- Similarity
- Question Answering and Commonsense Reasoning
- 4. Experiments
-
- 4.1 Setup
-
- Unsupervised pre-training
- Model specifications
- Fine-tuning details
- 4.2 Supervised fine-tuning
-
- Natural Language Inference
- Question answering and commonsense reasoning
- Semantic Similarity
- Classification
- 5. Analysis
-
- Impact of number of layers transferred
- Ablation studies
- 6. Conclusion
- 阅读总结
前言
chatGPT的初代工作,可以说没有GPT,就没有现在的大模型百家争鸣,本篇文章回顾这篇经典论文,思考作者是如何根据前者的工作在思想上进行创新,从而得到通用的模型架构。
Paper: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
Code: https://github.com/huggingface/transformersGPT
Abstract
自然语言理解任务繁多,虽然数据丰富,但是缺少标注数据,如何利用未标注数据是亟待解决的问题。作者通过在各种未标注的语料库上对语言模型进行生成式预训练,然后根据特定任务进行微调,可以得到很好的效果。与之前的模型相比,对架构进行了最小的修改。实验部分,GPT在12个任务中的9个达到了SOTA。
1. Introduction
大多数深度学习方法需要大量的手动标记数据,但是获取标注数据耗时耗力,如何利用大量未标注数据的有用信息是一个有价值的替代方案。
但是利用未标记文本数据具有挑战性:
- 不清楚什么样的预训练有利于文本的迁移学习。
- 如何将学习到的表示转移到下游任务。
现有的方法基于特定任务,或者使用复杂的学习方案,以及添加一些辅助学习的目标组合, 这些方法具有不确定性,难以有效利用无监督数据,
本文结合无监督预训练和监督微调,探索了一种用于语言理解任务的半监督方法,目标是学习通用的表示,可以迁移到任何任务。方法采用两阶段任务,先在无监督数据上进行预训练,再在特定任务的监督数据商家进行微调。
本文模型采用Transformer的解码器,迁移过程采用特定于任务的自回归方法,该方法将结构化文本处理为连续的token序列,在不改变模型架构的情况下进行微调。
作者在自然语言推理、问题问答、语义相似性和文本分类四个任务上进行评估,在12个任务中的9个达到了SOTA。
2. Related Work
Semi-supervised learning for NLP
半监督学习范式最早的方法是利用未标记的数据计算单词级或短语级统计数据,将其用作监督模型的特征。过去的工作证明可以提升任务的性能,但是这些方法主要传输单词级信息。最新的方法已经研究学习短语级或句子级信息。
Unsupervised pre-training
无监督学习的目标是找到一个好的初始化点,早期的工作在图像领域进行探索,随后的工作证明预训练可以作为一种正则化方法,具有很好的泛化能力。
与本文相近的工作采用LSTM先进行预训练,再微调,但是由于模型的原因性能受到限制。相比下,本文的Transformer可以捕获长期的语言结构。此外,其它方法中预训练的参数只能作为辅助特征,而Transformer几乎不会对模型架构进行更改。
Auxiliary training objectives
添加辅助无监督训练目标可以提升模型性能,实验部分展示无监督预训练已经学习了下游任务相关的信息。
3. Framework
训练过程分为两步骤,在大规模语料库上预训练,以及在特定任务上进行微调。
3.1 Unsupervised pre-training
给定未标注的语料序列 U = { u 1 , . . . , u n } \mathcal{U}=\{u_1,...,u_n \} U={u1,...,un},采用标准的语言模型最大化下列目标:
L 1 ( U ) = ∑ l o g P ( u i ∣ u i − k , . . . , u i − 1 ; Θ ) L_1(\mathcal{U})=\sum \mathrm{log}P(u_i|u_{i-k},...,u_{i-1};\Theta) L1(U)=∑logP(ui∣ui−k,...,ui−1;Θ)
其中 k k k是文本窗口大小,条件概率采用参数为 Θ \Theta Θ的神经网络建模,这些参数通过随机梯度下降更新。
通俗来说明一下上面的式子,就是希望模型生成的句子尽量靠近当前句子。
本文的模型是多层Transformer解码器堆叠的模型,该模型对输入带有位置编码的上下文应用多头注意力机制,输出目标token的分布:

其中 U = ( u − k , . . . , u − 1 ) U = (u_{-k},...,u_{-1}) U=(u−k,...,u−1)是标记的上下文向量, n n n是层数, W e W_e We是词嵌入矩阵, W p W_p Wp是位置嵌入矩阵。
3.2 Supervised fine-tuning
微调在有标签的数据集 C \mathcal{C} C上进行,每个样本包含token序列 x 1 , . . . , x m x^1,...,x^m x1,...,xm,标签为 y y y。将序列输入到模型中,获得最后一层激活 h l m h^m_l hlm,再将其喂入线性层中预测标签:
P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x_1,...,x_m)=\mathrm{softmax}(h_l^mW_y) P(y∣x1,...,xm)=softmax(hlmWy)
需要最大化的目标为:
L 2 ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 , . . . , x m ) L_2(\mathcal{C})=\sum_{(x,y)}\mathrm{log}P(y|x^1,...,x^m) L2(C)=(x,y)∑logP(y∣x1,...,xm)
此外作者还发现,将语言建模作为微调的辅助目标有利于提升模型的泛化性并加速学习。具体如下:
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda *L_1(\mathcal{C}) L3(C)=L2(C)+λ∗L1(C)
3.3 Task-specific input transformations

上图展示了如何将模型应用到特定问题下。核心包括两个过程,第一是对输入的token序列进行预处理,根据任务加入特殊的token构造可以处理的有序序列,第二是对输出部分构建一个线性层,将Transformer的输出映射到对应的标签或者词表上。
Textual entailment
对于蕴含任务,将前提和假设连接到一起,中间用分隔符分割。
Similarity
对于相似性任务,序列的排序没有关联,因此对两种排序都进行了独立建模,将最后一层的输出相加喂入MLP。
Question Answering and Commonsense Reasoning
对于此类任务,给定上下文内容和问题,以及一组回答,将上下文与问题和每个回答相连接,两两之间都需要特殊的分隔符,最后将所有组合的输出结果通过softmax层标准化,得到答案的分布。
4. Experiments
4.1 Setup
Unsupervised pre-training
作者采用BooksCorpus数据集训练语言模型,该数据集包含超过7000部未发表的书籍。书籍中的内容包含长段的连续文本,因此可以学习远程信息。
Model specifications
模型采用12层Transformer解码器,768维隐向量以及12个多头数。激活函数采用高斯误差线性单元(GELU),位置编码采用可学习的位置嵌入。
Fine-tuning details
略。
4.2 Supervised fine-tuning

上图概括了本文进行实验的NLP任务。
Natural Language Inference

上图展示了自然语言推理任务的结果,GPT在五个数据集中的四个上显著优于基线,但是在RTE上低于多任务biLSTM模型,可能的原因是本文的模型没进行多任务上训练。
Question answering and commonsense reasoning
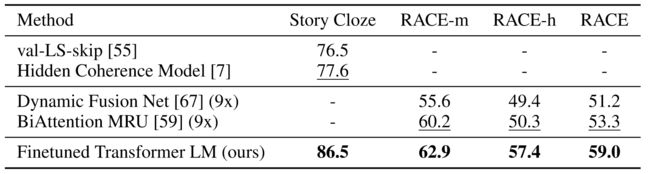
在问答和常识推理上,GPT显著高于其他模型,证明模型有效处理远程上下文的能力。
Semantic Similarity

语义相似性涉及预测两个句子在语义上是否等效。作者使用三个数据集进行评估,在其中两个上达到了最先进的结果。
Classification
最后评估了分类任务,在SST-2和CoLA上都具有竞争力的结果。
5. Analysis
Impact of number of layers transferred
作者观察了模型层数对预训练知识迁移到下游任务的影响,下图左边展示了模型层数对MultiNLI和RACE任务的性能变化。观察到每增加一层会提升9%的性能,说明预训练模型中每一层都包含用于解决目标任务的知识。
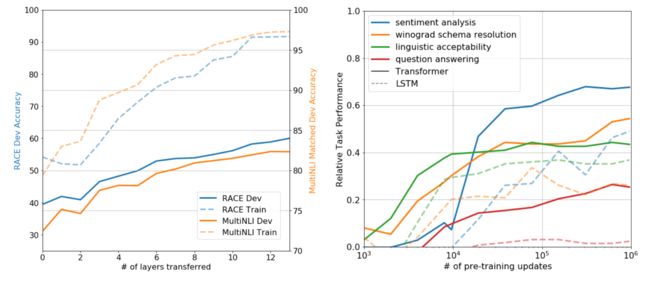
上图右边可视化了启发式解决方案在生成预训练模型过程中的有效性。作者希望更好理解为什么预训练是有效的。一个假设是,底层的生成模型通过执行多任务预训练提高了语言建模能力,并且注意力机制有利于迁移。观察到模型性能随着预训练的更新稳定增加,表明预训练支持学习各种任务相关功能。
Ablation studies

笑容实验结果见上表,观察到越大的数据集受益于辅助目标,但较小的数据集相反。其次Transformer架构优于LSTM架构,最后缺乏预训练会损害所有任务的性能。
6. Conclusion
本文设计了GPT,通过预训练和微调,实现了强大的自然语言理解能力。本文的工作证明,实现显著的性能提升是可能的。作者希望有助于对自然语言理解和其他领域的无监督学习进行新的研究,进一步提高我们对无监督学习如何以及何时发挥作用的理解。
阅读总结
NLP大模型时代的经典基石文章,正是GPT的提出,才有了bert,才有了chatGPT,才有了现在nlp大模型领域的百家争鸣。虽然GPT本质上是Transformer的解码器的堆叠,但是它创新性提出了预训练和微调的学习范式,为之后的大模型发展奠定了基础。说到GPT,就不得不提到BERT,从引用量来说,BERT远超于GPT,但是不代表BERT就优于GPT,虽然从实验结果上BERT吊锤GPT,但是细读BERT可以发现,BERT许多地方都借鉴了GPT,包括预训练和微调的范式,所以BERT虽然让预训练+微调的方法出圈了,但是真正的贡献还是来自于GPT。当然,正是因为BERT的出现,让GPT意识到自己的不足,即解码器和编码器架构本身的不同,正是架构的不同,才让二者的预训练任务不同,所需要的训练数据规模和模型规模也就不同,因此GPT的后续工作才会在更大规模的数据集上预训练,在模型层数上下功夫。