Mysql进阶
一、Mysql进阶
1.1Mysql基础
DBMS:数据库管理系统
Mysql数据库的数据类型:
1.数字类型:int bigint tinyint double decimal(⻓度,⼩数点的位数)
2.字符串类型:char varchar text
3.⽇期类型:date datetime
Mysql约束条件:为字段添加约束条件
1.主键约束
2.外键约束
3.⾮空约束
4.唯⼀约束
5.⾃增约束6.默认约束
SQL:结构化查询语⾔,操作数据库
SQL分类:
1.DDL:数据定义 create drop alter
2.DML:数据操作 insert update delete
3.DQL:数据查询 select
4.TPL(TCL):事务处理 commit rollback
5.DCL:数据控制语⾔ grant
6.CCL:指针控制语⾔ cursor
7⼤语句:
**1.创建表:CREATE table 表名 (字段 数据类型 约束条件,……) **
**2.修改表:ALTER TABLE 表名 ADD 字段名 数据类型 约束条件 **
**3.删除表:DROP TABLE 表名 **
**4.新增数据:INSERT INTO 表名(字段名,……) values(值,……) **
**5.修改数据:UPDATE 表名 set 字段=值,…… [where 条件] **
**6.删除数据:DELETE FROM 表名 [where 条件] **
*7.查询数据:SELECT 字段| FROM 表名 [where 条件] **
查询条件:and or in like between and not is null order by limit group by having
聚合函数:avg max min count sum
复杂查询:⼦查询、笛卡尔积查询(⾃然查询)、内连接、左外连接、右外连接、全连接(Mysql不⽀
持)
需要刷题:https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=268
数据删除:drop(把表都删除)、delete(删除表中数据)、truncate(删除表中的数据,并删除⾃增
器)
单位:分 bigint 好处:避免四舍五⼊ 缺陷:⻚⾯需要处理
单位:元 decimal 好处:单位元,不需要额外处理 缺陷:四舍五⼊
1.2 视图
视图:对查询语句(临时表)的封装,简化操作,操作视图跟操作表⼀样
创建视图:
create view 视图名 as 查询语句;
删除视图:
drop view 视图名;
使⽤视图:
操作视图就跟表⼀样;
#视图:View 封装查询语句
select p.title ptitle,p.img,a.* from t_pc p inner join t_pcall a on p.id=a.pid
#创建视图 字段名不能一致
create view pcview as select p.title ptitle,p.img,a.* from t_pc p inner join t_pcall a on p.id=a.pid
#查看视图 只有group by后面可以跟聚合函数 where不可以
select * from pcview where title like'%1%'
#删除视图
drop view pcview
1.3触发器
触发器:满⾜⼀定的条件,就会⾃动执⾏SQL语句。 ** trigger 触发器**
触发器的分类:1.表级触发器,监听表的变化 2.⾏级触发器,监听表中数据的变化
触发器的操作类型:insert(配合after) update delete(配合before)
触发器的时间:after before
语法格式:
新建触发器:
delimiter $
create trigger 触发器名称 before|after insert|update|delete on 表名 for each row
begin
⾃动执⾏的SQL语句
end$;
删除触发器:drop trigger 触发器名称;
测试触发器:满⾜条件
-- 触发器:满足指定的条件(1.时间 before after 2.操作⽅式 新增、修改、删除)
-- 触发器创建 监听t_pcall表的新增,如果新增了,就自动在t_pc 新增数据
-- NEW相当于添加时得一个对象
-- 1.创建触发器
delimiter $
create TRIGGER t_pcall_trigger before insert on t_pcall for each row
BEGIN
insert into t_pc(id,img,auto,title)
values(NEW.imgs,NEW.pid,'kz','自动填充');
insert into t_pc(id,img,auto,title)
values(NEW.imgs,NEW.pid,'yy','可增加多条;隔开');
END$
-- 2.触发器 测试
INSERT into t_pcall(pid,imgs) values(1231223,"111");
-- 3.查询
select * from t_pc;
-- 4.删除触发器
drop TRIGGER t_pcall_trigger;
1.4SQL语法
变量、分⽀、循环
变量:mysql数据库中有3种变量,
第⼀种:系统变量 @@变量名不能⾃定义,只能⽤系统提供
第⼆种:⽤户变量 @变量名,可以直接 set @变量名=值
第三种:局部变量(⾃定义变量)只能定义在函数、存储过程中。DECLARE 变量名 数据类型 ;
-- 查看所有全局系统变量
show global variables;
-- 查询系统变量的值
select @@version;
-- 用户变量,@开头
set @user1 =1;
select @user1;
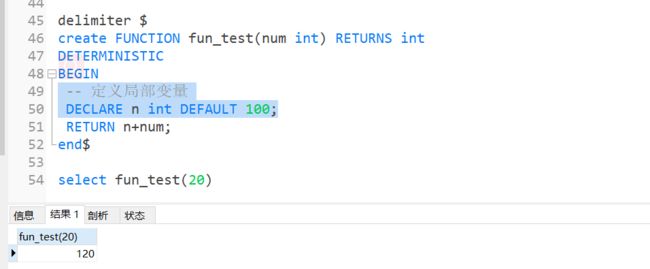
-- 函数+局部变量
delimiter $
create FUNCTION fun_test(num int) RETURNS int
DETERMINISTIC
BEGIN
-- 定义局部变量
DECLARE n int DEFAULT 100;
RETURN n+num;
end$
-- 使用函数
select fun_test(20)
1.5自定义函数
**必须有返回值 **
创建函数: function
delimiter $
create function 函数名(参数名 数据类型,……) returns 数据类型
begin
DETERMINISTIC
代码逻辑
return 返回值;
end$
删除函数:drop function 函数名;
使⽤函数:直接⽤,⽤在select
-- 函数实现特定功能的代码块
-- 创建函数
delimiter $
create FUNCTION f_add(num1 int,num2 int) RETURNS int
DETERMINISTIC
BEGIN
RETURN num1+num2;
end$
-- 使⽤函数
select f_add(1,1);
select f_add(id,100) from t_account;
-- 删除函数
drop FUNCTION f_add;
1.5存储过程
关键字:PROCEDURE procedure 程序 call 执行
存储过程:实现特定功能的SQL语句块,其实就是⼀种特殊的函数,没有返回值函数
参数类型有三种:
1.输⼊参数 -只读 in
**2.输出参数 -只写 out **
**3.输⼊输出参数 -读写 inout **
创建存储过程
create PROCEDURE 存储过程名称(参数类型 参数名 数据类型,……)
begin
实现逻辑处理
end
使⽤存储过程:call 存储过程名称(参数变量)
删除存储过程:drop PROCEDURE 存储过程名称
-- 存储过程:一种特殊的函数,没有返回值的函数,实现特定功能的SQL语句块
-- 1.创建存储过程
delimiter $
create PROCEDURE p_add(in num1 int,in num2 int,out num3 int)
BEGIN
set num3=num1+num2;
end$
-- 2.设置用户变量
set @n = 0;
-- 3.调用存储过程 输入 输入 输出
call p_add(1,1,@n);
-- 查询⽤户变量的内容
select @n;
-- 1.定义存储过程,实现指定数量的账号数据添加
delimiter $
create PROCEDURE p_accountadd(in num int)
BEGIN
DECLARE i int DEFAULT 0;
while i<num
DO
set i=i+1; -- concat合并
insert into t_pcall(pid,imgs) values(CONCAT('1851599',i),CONCAT('6666',i));
end WHILE;
end$
-- 2.执行
call p_accountadd(100);
-- 3.查看
select * from t_pcall;
-- 删除存储过程
drop PROCEDURE p_add;
1.6索引
**索引:是⼀种可以提升查询效率的结构,⽬的就是为了提⾼查询的效率。 **
如果把书⽐喻成表,那么书的⽬录就是索引。
索引可以提⾼查询效率(⽣效),会影响新增、删除、修改的效率(涉及到索引字段)
每个索引,都是⼀张表。实际上,⼀张表的索引的数量不能超过32个
索引的语法格式:
创建索引:create index 索引名 on 表名(字段名) ; (id性能最高)
查看索引是否⽣效:explain 查询语句 where 索引字段=值;
删除索引:alter table 表名 drop index 索引名;
查看表上的索引:show index from 表名;
索引的分类:
**1.主键索引 **
**2.普通索引 **
**3.唯⼀索引 **
4.联合索引(复合索引)
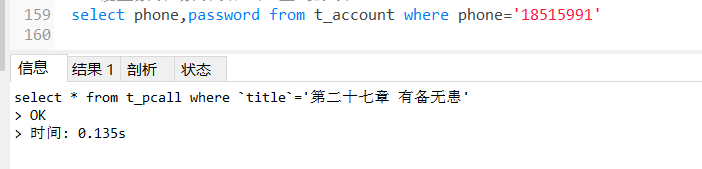
没有索引之前:
创建索引之后:
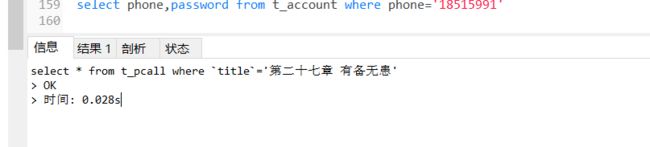
由于数据不多,所以性能提升并不明显
查看是否存在索引:

explain的结果说明:
type所显示的是查询使⽤了哪种类型,type包含的类型包括如下图所示的⼏种,从好到差依次是
**system > const > eq_ref > ref > range > index > all **
查看表上的索引:
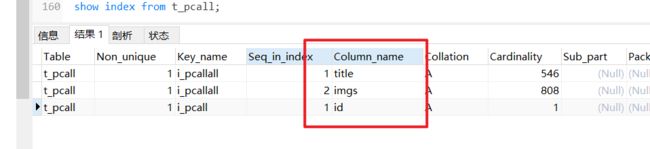 联合索引,最左侧原则:
联合索引,最左侧原则:

只有最左侧被当为索引
那么为什么还要创建联合索引呢??
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
-- 索引:提升查询效率
-- 1.将原有表中的数据再次添加
insert into t_pcall select * from t_pcall
select count(*) from t_pcall;
-- 2.没有索引的时候
select * from t_pcall where `title`='第二十七章 有备无患';
-- 3.创建索引
create index i_pcall on t_pcall(`title`);
-- 4.有索引之后
select * from t_pcall where `title`='第二十七章 有备无患';
-- 5.分析查询语句,是否存在索引
EXPLAIN select * from t_pcall where `title`='66664785';
-- 6.删除索引
alter table t_pcall drop index i_pcall;
-- 7.查看表上的索引
show index from t_pcall;
-- 8.创建联合索引
create index i_pcallall on t_pcall(title,imgs);
-- 最左前缀原则
EXPLAIN select * from t_pcall where title='第二十七章 有备无患';
EXPLAIN select * from t_pcall where imgs='https://www.um16.cn//info/1/27.html';
EXPLAIN select * from t_pcall where id=100;
-- 覆盖索引 索引表,不用查询原表
select title,imgs from t_pcall where title='第二十七章 有备无患'
explain的结果分析:
id
id相同,执⾏顺序由上⾄下
id不同,如果是⼦查询,id的序号会递增,id值越⼤优先级越⾼,越先被执⾏
id相同不同,同时存在 id相同的可以认为是⼀组,同⼀组中从上往下执⾏,所有组中id⼤的优先执⾏
type
type所显示的是查询使⽤了哪种类型,type包含的类型包括如下图所示的⼏种,从好到差依次是
system > const > eq_ref > ref > range > index > all
system 表只有⼀⾏记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
const 表示通过索引⼀次就找到了,const⽤于⽐较primary key 或者unique索引。因为只匹配⼀⾏数
据,所以很快。如将主键置于where列表中,MySQL就能将该查询转换为⼀个常量。
eq_ref 唯⼀性索引扫描,对于每个索引键,表中只有⼀条记录与之匹配。常⻅于主键或唯⼀索引扫描
ref ⾮唯⼀性索引扫描,返回匹配某个单独值的所有⾏,本质上也是⼀种索引访问,它返回所有匹配某个单
独值的⾏,然⽽,它可能会找到多个符合条件的⾏,所以他应该属于查找和扫描的混合体。
range 只检索给定范围的⾏,使⽤⼀个索引来选择⾏,key列显示使⽤了哪个索引,⼀般就是在你的where
语句中出现between、< 、>、in等的查询,这种范围扫描索引⽐全表扫描要好,因为它只需要开始于索引
的某⼀点,⽽结束于另⼀点,不⽤扫描全部索引。
index Full Index Scan,Index与All区别为index类型只遍历索引树。这通常⽐ALL快,因为索引
⽂件通常⽐数据⽂件⼩。(也就是说虽然all和Index都是读全表,但index是从索引中读取的,⽽all是
从硬盘读取的)
all Full Table Scan 将遍历全表以找到匹配的⾏
possible_keys 和 key
possible_keys 显示可能应⽤在这张表中的索引,⼀个或多个。查询涉及到的字段上若存在索引,则该索
引将被列出,但不⼀定被查询实际使⽤。
key实际使⽤的索引,如果为NULL,则没有使⽤索引。(可能原因包括没有建⽴索引或索引失效)
key_len
表示索引中使⽤的字节数,可通过该列计算查询中使⽤的索引的⻓度,在不损失精确性的情况下,⻓度越短
越好。
rows
根据表统计信息及索引选⽤情况,⼤致估算出找到所需的记录所需要读取的⾏数,也就是说,⽤的越少越好
Extra
Using filesort
说明mysql会对数据使⽤⼀个外部的索引排序,⽽不是按照表内的索引顺序进⾏读取。MySQL中⽆法利⽤索
引完成的排序操作称为“⽂件排序”。
Using temporary
使⽤了⽤临时表保存中间结果,MySQL在对查询结果排序时使⽤临时表。常⻅于排序order by和分组查询
group by。
Using index
表示相应的select操作中使⽤了覆盖索引(Covering Index),避免访问了表的数据⾏,效率不错。如
果同时出现using where,表明索引被⽤来执⾏索引键值的查找;如果没有同时出现using where,表明
索引⽤来读取数据⽽⾮执⾏查找动作。
Using join buffer
表明使⽤了连接缓存,⽐如说在查询的时候,多表join的次数⾮常多,那么将配置⽂件中的缓冲区的join
buffer调⼤⼀些
二、SQL优化
2.1 SQL执⾏顺序
Mysql中⼀个查询语句的执⾏顺序:
select distinct *或字段 from 表名 inner|left|right join 表名 on 条件 where 条件 group by 字段
having 条件 order by 字段 asc|desc limit 起始⾏索引,数量
依次出现的关键词的顺序:
**a.select **
b.distinct (去重)
**c.from **
**d.join **
possible_keys 和 key
possible_keys 显示可能应⽤在这张表中的索引,⼀个或多个。查询涉及到的字段上若存在索引,则该索
引将被列出,但不⼀定被查询实际使⽤。
key实际使⽤的索引,如果为NULL,则没有使⽤索引。(可能原因包括没有建⽴索引或索引失效)
key_len
表示索引中使⽤的字节数,可通过该列计算查询中使⽤的索引的⻓度,在不损失精确性的情况下,⻓度越短
越好。
rows
根据表统计信息及索引选⽤情况,⼤致估算出找到所需的记录所需要读取的⾏数,也就是说,⽤的越少越好
Extra
Using filesort
说明mysql会对数据使⽤⼀个外部的索引排序,⽽不是按照表内的索引顺序进⾏读取。MySQL中⽆法利⽤索
引完成的排序操作称为“⽂件排序”。
Using temporary
使⽤了⽤临时表保存中间结果,MySQL在对查询结果排序时使⽤临时表。常⻅于排序order by和分组查询
group by。
Using index
表示相应的select操作中使⽤了覆盖索引(Covering Index),避免访问了表的数据⾏,效率不错。如
果同时出现using where,表明索引被⽤来执⾏索引键值的查找;如果没有同时出现using where,表明
索引⽤来读取数据⽽⾮执⾏查找动作。
Using join buffer
表明使⽤了连接缓存,⽐如说在查询的时候,多表join的次数⾮常多,那么将配置⽂件中的缓冲区的join
buffer调⼤⼀些
**e.on **
**f.where **
**g.group by **
**h.having **
**i.order by **
**j.limit **
**Mysql中的执⾏顺序: **
1.from
笛卡尔积计算 ⽣成虚拟表v1 笛卡尔积计算()
2.on
过滤数据 再次⽣成虚拟表v2
3.join
添加外部数据 v3
4.where
条件过滤 v4
5.group by
分组
6.聚合函数
avg max min sum count
7.having
条件过滤,可以使⽤聚合函数的结果或使⽤聚合函数
8.select
查询需要的字段
9.distinct
去重重复结果
10.order by
排序
11.limit
分⻚
笛卡尔积是什么?
笛卡尔积乘积指在数学上,两个集合X和Y的笛卡尔积 (Cartesian product),又称直积,表示 X x Y,第一个对象是 X 的成员而第二个对象是 Y 的所有可能有序对的其中一个成员。
eg1:
假设集合A = {a,b},集合B = {0,1,2},则两个集合的笛卡尔积为:
{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}
eg2:
设A,B为集合,用A中元素为第一元素,B中元素为第二元素构成有序对,
所有这样的有序对组成的集合叫做A与B的笛卡尔积,记作AxB.
笛卡尔积的符号化为:
A×B={(x,y)|x∈A ∧ y∈B}
例如,A = {a,b}, B = {0,1,2},则
A×B = {(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
B×A = {(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}
转载: http://t.csdn.cn/38tIL
SQL优化三部曲:定位、分析、解决开发中遇到问题解决三部曲:
定位(⽇志、debug)
分析(根据异常,和定位的点,去分析代码)
解决(根据分析结果,因果而异)
2.2 SQL优化之定位
定位:找到执⾏慢的sql语句
⽅式,任选其⼀:
**1.Mysql的慢查询⽇志 **
在mysql的配置⽂件中:windows:my.ini linux:my.cnf

每次只需要,查看slow.log⽇志⽂件,记录就是执⾏超过2秒的sql语句
**2.Spring AOP实现查询语句的记录 **
aop的环绕通知,去记录查询的sql语句的执⾏时间,如果执⾏超过2秒,就记录sql语句
**3.Druid的SQL监控 **
配置Druid的SQL监控,获取执⾏慢的SQL语句
2.3 SQL优化之分析
分析:根据执⾏慢的SQL语句,进⾏分析,找到慢的原因
汇总⼀些常⻅:
**1.SQL语句有业务逻辑,影响性能 **
**2.SQL语句,联合查询的多表关系不是最短路径 **
**3.SQL语句索引失效 **
**4.SQL语句查询条件的顺序不对 **
**5.Mysql并发量过⼤ **
**6.SQL语句对应的表的数据量太⼤ **
**7.SQL语句太⻓ **
8.SQL语句查询条件函数计算
2.4 SQL优化之解决
解决:对号⼊座,尝试处理
**1.SQL语句有业务逻辑,影响性能 **
拆分业务逻辑,可以把逻辑放到Java代码中解决,改SQL语句
**2.SQL语句,联合查询的多表关系不是最短路径 **
分析涉及到的多表关系,查看能不能找到最短路径,⼲掉没⽤的表连接
**3.SQL语句索引失效 **
想办法让索引⽣效,⽐如合理设计索引,采⽤联合索引,使⽤最左前缀原则,索引的数量、索引的字
段
**4.SQL语句查询条件的顺序不对 **
on先执⾏,再执⾏where,最后执⾏having
所以可以把有些查询条件放到on那⾥进⾏筛选
**5.Mysql并发量过⼤ **
2种⽅案:1.舍弃连接,数据库连接池,设置最⼤连接
2.搭建Mysql的集群(多主多从)-中间件解决 (Mycat、Sharding-Jdbc)
**6.SQL语句对应的表的数据量太⼤ **
实现数据分⽚,采⽤第三⽅技术:Sharding-Jdbc
**7.SQL语句太⻓ **
拆分为多个sql语句,在Java代码中整合数据
**8.SQL语句查询条件函数计算 **
避免在sql的查询条件中使⽤函数进⾏计算处理,可以考虑Java代码中实现数据处理
结合项⽬模块
2.5 常⽤的SQL优化⽅案
1、你必须选择记录条数最少的表作为基础表
from 是从前往后检索的,所以要最少记录的表放在最前⾯。
2、采⽤⾃下⽽上的顺序解析WHERE⼦句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些
可以过滤掉最⼤数量记录的条件必须写在WHERE⼦句的末尾。同时在链接的表中能过滤的就应该先进⾏过
滤。
where是从后往前检索,所以能过滤最多数据的条件应放到最后。
3、SELECT⼦句中避免使⽤ '*'
4、尽量多使⽤COMMIT
5、计算记录条数时候,第⼀快:count(索引列),第⼆快:count(*)
6、⽤WHERE⼦句替换HAVING⼦句
7、通过内部函数代替⾃定义函数提⾼SQL效率
8、使⽤表的别名(Alias)
9、⽤EXISTS替代IN
10、⽤NOT EXISTS替代NOT IN
11、⽤表连接替换EXISTS
12、⽤索引提⾼效率
13、尽量避免在索引列上使⽤计算,
包括在SELECT后⾯ WHERE后⾯等任何地⽅,因为在索引列上计算会导致索引失效。
14、避免在索引列上使⽤NOT
在索引列使⽤not会导致索引失效。
15、⽤>=替代>
16、⽤UNION替换OR (适⽤于索引列)
17、⽤IN来替换OR
18、避免在索引列上使⽤IS NULL和IS NOT NULL
19、总是使⽤索引的第⼀个列
20、尽量⽤UNION-ALL 替换UNION ( 如果有可能的话)
21、ORDER BY ⼦句只在两种严格的条件下使⽤索引.
22、避免改变索引列的类型
23、需要当⼼的WHERE⼦句
24、避免使⽤耗费资源的操作(如DISTINCT,UNION,MINUS,INTERSECT,ORDER BY等)
三、Mysql集群
在⾼并发下、海量数据下,在所难免就要实现Mysql的集群搭建
Mysql本身可以实现主从复制,我们需要完成配置,就可以实现数据从主库⾃动到从库。
1. Sharding-JDBC实现Mysql集群
Sharding-JDBC 是当当⽹开源的适⽤于微服务的分布式数据访问基础类库,完整的实现了分库分表,读
写分离和分布式主键功能,并初步实现了柔性事务。从 2016 年开源⾄今,在经历了整体架构的数次精
炼以及稳定性打磨后,如今它已积累了⾜够的底蕴。
ShardingSphere是⼀套开源的分布式数据库中间件解决⽅案组成的⽣态圈,它由Sharding-JDBC、
Sharding-Proxy 和 Sharding-Sidecar这3款相互独⽴的产品组成。
https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick
start/
1.maven配置
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.0</version>
</dependency>
2.application.yml
spring:
shardingsphere:
mode: #1.配置模式 单机或集群
type: Standalone
datasource:
names: ds #2.配置数据源 根据实际情况
ds:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://rm-bp1fi52ghqu598b39lo.mysql.rds.aliyuncs.com/db_login?serverTimezone=Asia/Shanghai
username: self
password: Tws123456
type: com.alibaba.druid.pool.DruidDataSource
jackson:
date-format: yyyy-MM-ss HH:mm:ss
rules: #3.配置分片规则
sharding: #设置分片信息:水平分片:一库多表,垂直分片:多库
tables:
t_user:
actual-data-nodes: ds.t_user$->{0..2}
table-strategy:
standard:
sharding-column: id
sharding-algorithm-name: t-user-inline
key-generate-strategy:
column: id
key-generator-name: snowflake
binding-tables[0]: t_user
sharding-algorithms:
t-user-inline:
type: INLINE
props:
algorithm-expression: t_user$->{id % 3}
key-generators:
snowflake:
type: SNOWFLAKE
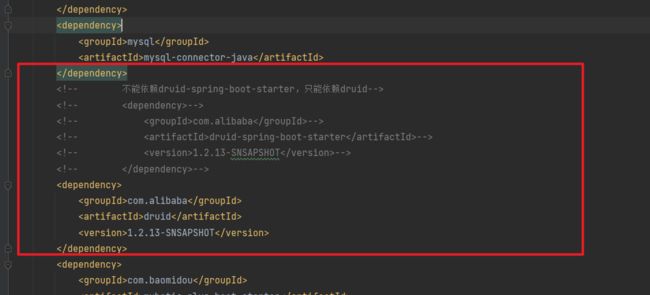
**这⾥遇到⼀个bug: **
**Sharding-jdbc使⽤Drud不能依赖druid-spring-boot-starter **
**只能依赖:druid,否则就会遇到⼀个坑,报 Property ‘sqlSessionFactory’ or ‘sqlSessionTemplate’ **
**are requi **
**后来查阅⽂档,官⽅⽂档,发现原来Sharding-jdbc4.0之后。就不能依赖这个包,会引起冲突。因为我 **
们使⽤的Sharding-jdbc5.0以后的版本