《Kubernetes监控篇:Kubernetes单节点之微服务JVM内存监控》
文章目录
- 一、背景信息
- 二、监控方案
- 三、环境信息
- 四、部署操作
-
-
- 4.1、资源下载
- 4.2、修改Dockerfile
- 4.3、修改mpmt-adapter.yaml文件
- 4.4、部署prometheus
- 4.5、导入dashborard模板
-
- 总结:整理不易,如果对你有帮助,可否点赞关注一下?
一、背景信息
复杂和高并发下的服务,必须保证每次gc不会出现性能下降,各种性能指标不会出现波动,gc回收规律而且干净,所以必须找到合适的jvm设置。而要找到合适的jvm设置,必须要了解当前java服务的jvm使用情况。所以我觉得非常有必要对java服务的jvm使用情况实时监控。
业务系统涉及到的java服务分为:tomcat类型、jar包类型、k8s微服务类型。
二、监控方案
方案一:业务系统java服务采用的是SpringBoot框架,SpringBoot自带监控功能Actuator,可以帮助实现对程序内部运行情况监控,比如监控状况、Bean加载情况、环境变量、日志信息、线程信息、健康检查、审计、统计和HTTP追踪等。Actuator同时还可以与外部应用监控系统整合,比如Prometheus,可以选择使用HTTP端点或JMX来管理和监视应用程序。
方案二:通过JMX Exporter来暴露 Java 应用的JVM监控指标,JMX Exporter有两种用法。
# 方法一:启动独立进程
JVM启动时指定参数,暴露JMX的RMI接口,JMX-Exporter调用RMI获取JVM运行时状态数据,
转换为Prometheus metrics格式,并暴露端口让Prometheus采集。
# 方法二:JVM进程内启动(in-process)
JVM启动时指定参数,通过javaagent 的形式运行JMX-Exporter 的jar包,
进程内读取JVM运行时状态数据,转换为Prometheus metrics格式,并暴露端口让Prometheus采集。
说明:官方不推荐使用第一种方式,一方面配置复杂,另一方面因为它需要一个单独的进程,而这个进程本身的监控又成了新的问题,所以本文重点围绕第二种用法讲如何在K8S 环境下使用JMX Exporter暴露JVM监控指标。
三、环境信息
1、监控系统架构图

2、环境说明
业务系统涉及到的java 服务,有些是tomcat类型,有些是微服务,微服务采用的是k8s来部署的。由于公司涉及到的系统有多个,并不是所有的的业务系统都有使用k8s,所以起初为了统一管理监控平台,专门申请了一台ECS服务器来部署prometheus和grafana,也就是说所有涉及到的监控数据都通过这台ECS服务器来存储和展示,针对不同监控类型数据部署了多个prometheus。
四、部署操作
4.1、资源下载
jmx_prometheus_javaagent-0.16.1.jar和prometheus-jmx-config.yaml

4.2、修改Dockerfile
# 修改前
FROM java:8u111-jdk
RUN cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo 'Asia/Shanghai' >/etc/timezone
ADD mpmt-cp-adapter.jar adapter.jar
EXPOSE 8083
ENTRYPOINT ["java","-Xmx2048m","-Xms512m","-XX:MaxMetaspaceSize=512m","-XX:MetaspaceSize=256m","-Djava.security.egd=file:/dev/./urandom","-jar","/adapter.jar","--spring.profiles.active=test"]
# 修改后
FROM java:8u111-jdk
RUN cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo 'Asia/Shanghai' >/etc/timezone
ADD mpmt-cp-adapter.jar adapter.jar
ADD prometheus-jmx-config.yaml /prometheus-jmx-config.yaml
ADD jmx_prometheus_javaagent-0.16.1.jar /jmx_prometheus_javaagent-0.16.1.jar
EXPOSE 8083
EXPOSE 7070
ENTRYPOINT ["java","-javaagent:/jmx_prometheus_javaagent-0.16.1.jar=7070:prometheus-jmx-config.yaml","-Xmx2048m","-Xms512m","-XX:MaxMetaspaceSize=512m","-XX:MetaspaceSize=256m","-Djava.security.egd=file:/dev/./urandom","-jar","/adapter.jar","--spring.profiles.active=test"]
4.3、修改mpmt-adapter.yaml文件
# 修改前
---
apiVersion: v1
kind: Service
metadata:
name: mpmt-adapter-svc
labels:
app: mpmt-adapter
spec:
type: NodePort
ports:
- port: 8083
targetPort: 8083
protocol: TCP
nodePort: 31087
selector:
app: mpmt-adapter
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mpmt-adapter
spec:
serviceName: "mpmt-adapter"
podManagementPolicy: Parallel
replicas: 1
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
app: mpmt-adapter
template:
metadata:
labels:
app: mpmt-adapter
spec:
containers:
- name: mpmt-adapter
image: server.harbor.com:8888/library/mpmt-adapter:202107191029
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8083
resources:
requests:
cpu: "500m"
memory: "4Gi"
limits:
cpu: "1000m"
memory: "6Gi"
# 修改后
---
apiVersion: v1
kind: Service
metadata:
name: mpmt-adapter-svc
labels:
app: mpmt-adapter
spec:
type: NodePort
ports:
- port: 8083
targetPort: 8083
protocol: TCP
nodePort: 31087
name: jdk #增加内容
- port: 7070 #增加内容
targetPort: 7070 #增加内容
protocol: TCP #增加内容
nodePort: 35001 #增加内容
name: jvm #增加内容
selector:
app: mpmt-adapter
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mpmt-adapter
spec:
serviceName: "mpmt-adapter"
podManagementPolicy: Parallel
replicas: 1
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
app: mpmt-adapter
template:
metadata:
labels:
app: mpmt-adapter
spec:
containers:
- name: mpmt-adapter
image: server.harbor.com:8888/library/mpmt-adapter:202107191029
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8083
resources:
requests:
cpu: "500m"
memory: "4Gi"
limits:
cpu: "1000m"
memory: "6Gi"
说明:这里由于prometheus部署在另外一台非k8s集群主机上,所以这里的微服务的jvm端口都采用主机端口映射方式,要注意的是如果同一个yaml文件中需要映射多个端口到宿主机上,需要对不通的映射端口添加名称以区分,这里采用的jdk和jvm的方式。
4.4、部署prometheus
mkdir -pv /data/pkgs/prometheus/jvm-exporter/etc/conf.d/rules
vim /data/pkgs/prometheus/jvm-exporter/etc/conf.d/rules/rule_jvm_alert.yml
groups:
- name: jvm-alerting
rules:
# down了超过1分钟
- alert: instance-down
expr: up == 0
for: 1m
labels:
severity: 严重
team: 运维
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
# down了超过5分钟
- alert: instance-down
expr: up == 0
for: 5m
labels:
severity: 灾难
team: 运维
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# 堆空间使用超过50%
- alert: heap-usage-too-much
expr: jvm_memory_bytes_used{job="jvm-exporter", area="heap"} / jvm_memory_bytes_max * 100 > 50
for: 1m
labels:
severity: 警告
team: 运维
annotations:
summary: "JVM Instance {{ $labels.instance }} memory usage > 50%"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been in status [heap usage > 50%] for more than 1 minutes. current usage ({{ $value }}%)"
# 堆空间使用超过80%
- alert: heap-usage-too-much
expr: jvm_memory_bytes_used{job="jvm-exporter", area="heap"} / jvm_memory_bytes_max * 100 > 80
for: 1m
labels:
severity: 严重
team: 运维
annotations:
summary: "JVM Instance {{ $labels.instance }} memory usage > 80%"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been in status [heap usage > 80%] for more than 1 minutes. current usage ({{ $value }}%)"
# 堆空间使用超过90%
- alert: heap-usage-too-much
expr: jvm_memory_bytes_used{job="jvm-exporter", area="heap"} / jvm_memory_bytes_max * 100 > 90
for: 1m
labels:
severity: 灾难
team: 运维
annotations:
summary: "JVM Instance {{ $labels.instance }} memory usage > 90%"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been in status [heap usage > 90%] for more than 1 minutes. current usage ({{ $value }}%)"
# 在5分钟里,Old GC花费时间超过30%
- alert: old-gc-time-too-much
expr: increase(jvm_gc_collection_seconds_sum{gc="PS MarkSweep"}[5m]) > 5 * 60 * 0.3
for: 5m
labels:
severity: 警告
team: 运维
annotations:
summary: "JVM Instance {{ $labels.instance }} Old GC time > 30% running time"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been in status [Old GC time > 30% running time] for more than 5 minutes. current seconds ({{ $value }}%)"
# 在5分钟里,Old GC花费时间超过50%
- alert: old-gc-time-too-much
expr: increase(jvm_gc_collection_seconds_sum{gc="PS MarkSweep"}[5m]) > 5 * 60 * 0.5
for: 5m
labels:
severity: 严重
team: 运维
annotations:
summary: "JVM Instance {{ $labels.instance }} Old GC time > 50% running time"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been in status [Old GC time > 50% running time] for more than 5 minutes. current seconds ({{ $value }}%)"
# 在5分钟里,Old GC花费时间超过80%
- alert: old-gc-time-too-much
expr: increase(jvm_gc_collection_seconds_sum{gc="PS MarkSweep"}[5m]) > 5 * 60 * 0.8
for: 5m
labels:
severity: 灾难
team: 运维
annotations:
summary: "JVM Instance {{ $labels.instance }} Old GC time > 80% running time"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been in status [Old GC time > 80% running time] for more than 5 minutes. current seconds ({{ $value }}%)"
# 4、准备lflk-test.json
vim /data/pkgs/yibot_lflk_tools_v4.0/prometheus/jvm-exporter/etc/conf.d/lflk-test.json
[
{
"targets": [
"172.181.111.110:35001"
],
"labels": {
"tag": "lflk",
"system": "大地分局调度系统",
"env": "测试环境",
"owner": "大地分局",
"cloud": "华为云",
"ip": "10.96.30.87",
"java": "mpmt-adapter"
},
{
"targets": [
"172.181.111.110:35002"
],
"labels": {
"tag": "lflk",
"system": "大地分局调度系统",
"env": "测试环境",
"owner": "大地分局",
"cloud": "华为云",
"ip": "10.96.30.87",
"java": "mpmt-watcher"
}
]
# 4、启动容器
docker run -d --name prometheus-jvm-exporter -p 9101:9090 -v /etc/localtime:/etc/localtime \
-v /data/pkgs/yibot_lflk_tools_v4.0/prometheus/jvm-exporter/etc/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /data/pkgs/yibot_lflk_tools_v4.0/prometheus/jvm-exporter/etc/conf.d:/etc/prometheus/conf.d \
prom/prometheus --web.enable-lifecycle --config.file=/etc/prometheus/prometheus.yml
# 5、测试
# 查看mpmt-adapter服务jvm数据
http://172.181.111.110:35001
# 查看Prometheus是否获取微服务jvm数据
http://172.181.111.107:9101
如下图所示,则表示Prometheus数据


4.5、导入dashborard模板
说明:默认是grafana已经安装,至于如何导入模板及添加数据源就不做介绍了。
# 官方模板
https://grafana.com/grafana/dashboards/12856/revisions
# 个人修改模板
https://download.csdn.net/download/m0_37814112/20374260
JVM监控效果图如下:
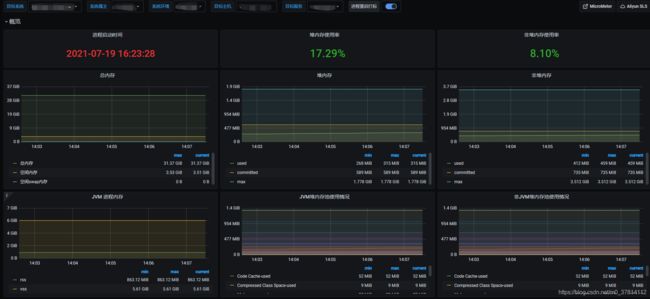

钉钉告警效果图如下:

总结:整理不易,如果对你有帮助,可否点赞关注一下?
更多详细内容请参考:企业级K8s集群运维实战