golang内存分配与管理
概述
golang的内存分配机制源自Google的tcmalloc算法,英文全称thread caching malloc,从名字可以看出,是在原有基础上,针对多核多线程的内存管理进行优化而提出来的。该算法的核心思想是内存的多级管理,进而降低锁的粒度;将内存按需划成大小不一的块,减少内存的碎片化。为每个P,也就是go协程调度模型了里面的逻辑处理器维护一个mcache结构体的独立内存池,只有当该内存池不足时,才会向全局mcentral和mheap结构体管理的内存池申请。为每一个P维持一个私有的本地内存池,从而不用加锁,加快了内存分配速度。只有在本地P的内存池被消耗完,或者申请的内存太大时,才会访问全局的内存池,大大减小了多线程下对全局内存池访问带来的竞争系统损耗。
内存架构
以64位的系统为例,1.11版本以后go程序的整个堆内存是连续,如下图 所示。结构虽然简单,但是在混合使用go和c的时候会导致程序崩溃,例如分配的内存地址发生冲突,导致初始化堆和扩容失败。

自1.11版本以后,对堆实现了分块处理,arena不再是连续的,以64位的Linux系统为例,是一个块块64MB大小的块。golang内存的三级架构如下图所示。下面将分别介绍各个层。

mspan
mspan结构体是go内存管理的基本单元,定义在runtime/mheap.go中,主要结构体成员如下:
//go:notinheap
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
nelems uintptr // number of object in the span.
allocBits *gcBits
allocCount uint16 // number of allocated objects
spanclass spanClass // size class and noscan (uint8)
elemsize uintptr // computed from sizeclass or from npages
.....
}
可以发现,这是一个双向链表。
startAddr:当前span在arena中的起始字节的地址
npages:当前span包含arena中多少页
nelems:当前span,包含多少个对象。golang又对每一个span,按照所属class的不同,切分成大小不同的块,以减少内存碎片。
allocCount:已分配的对象数目
elemsize:对象大小
spanclass:span所属的class。
根据对象的大小,golang划分了一系列的class,以应对各种场景的内存分配,较少内存碎片化。每个class都有一个固定大小的对象和固定的span大小,如下所示:
// class bytes/obj bytes/span objects waste bytes
// 1 8 8192 1024 0
// 2 16 8192 512 0
// 3 32 8192 256 0
// 4 48 8192 170 32
// 5 64 8192 128 0
// 6 80 8192 102 32
// 7 96 8192 85 32
// 8 112 8192 73 16
// 9 128 8192 64 0
// 10 144 8192 56 128
// 11 160 8192 51 32
// 12 176 8192 46 96
// 13 192 8192 42 128
// 14 208 8192 39 80
// 15 224 8192 36 128
// 16 240 8192 34 32
// 17 256 8192 32 0
// 18 288 8192 28 128
// 19 320 8192 25 192
// 20 352 8192 23 96
// 21 384 8192 21 128
// 22 416 8192 19 288
// 23 448 8192 18 128
// 24 480 8192 17 32
// 25 512 8192 16 0
// 26 576 8192 14 128
// 27 640 8192 12 512
// 28 704 8192 11 448
// 29 768 8192 10 512
// 30 896 8192 9 128
// 31 1024 8192 8 0
// 32 1152 8192 7 128
// 33 1280 8192 6 512
// 34 1408 16384 11 896
// 35 1536 8192 5 512
// 36 1792 16384 9 256
// 37 2048 8192 4 0
// 38 2304 16384 7 256
// 39 2688 8192 3 128
// 40 3072 24576 8 0
// 41 3200 16384 5 384
// 42 3456 24576 7 384
// 43 4096 8192 2 0
// 44 4864 24576 5 256
// 45 5376 16384 3 256
// 46 6144 24576 4 0
// 47 6528 32768 5 128
// 48 6784 40960 6 256
// 49 6912 49152 7 768
// 50 8192 8192 1 0
// 51 9472 57344 6 512
// 52 9728 49152 5 512
// 53 10240 40960 4 0
// 54 10880 32768 3 128
// 55 12288 24576 2 0
// 56 13568 40960 3 256
// 57 14336 57344 4 0
// 58 16384 16384 1 0
// 59 18432 73728 4 0
// 60 19072 57344 3 128
// 61 20480 40960 2 0
// 62 21760 65536 3 256
// 63 24576 24576 1 0
// 64 27264 81920 3 128
// 65 28672 57344 2 0
// 66 32768 32768 1 0
其中:
class:是class id, 对应了span结构体所属的class的种类,可以看到一共66中,实际一共67种。大于32K的内存 分配,会直接从mheap中分配,后面会介绍。
bytes/obj:每个对象占用的字节数
bytes/span:每个span的大小,也就是页数*8k(页大小)
objects:该类span所拥有的对象数,span所占字节数/对象所占字节数
waste bytes:该类span浪费的字节数,从以上分析可以看出,每一类span并不能刚好按该类对象大小,分配整数个对象,即做到每一字节物尽其用,这个值是:span所占字节数%对象所占字节数
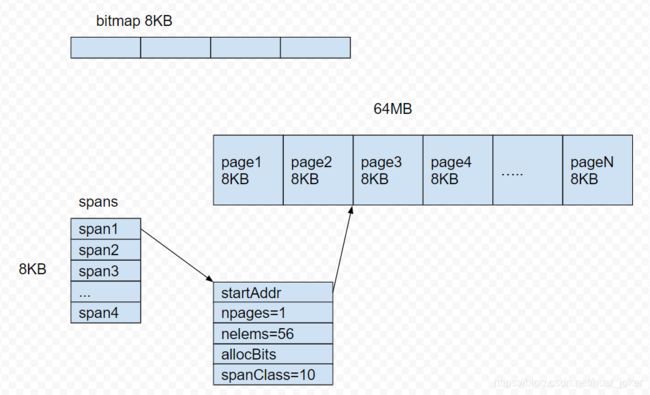
以class 10 为例,span与管理的内存如下图所示:

表示当前span类别属于class10,大小只有1页,又切分56个大小为144字节的块,其中两个已分配。
mheap
mheap管理整个go程序的堆空间,在源文件runtime/mheap.go中找到了该结构体描述,以及全局变量mheap_,结构体主要字段如下:
type mheap struct {
// lock must only be acquired on the system stack, otherwise a g
// could self-deadlock if its stack grows with the lock held.
lock mutex
pages pageAlloc // page allocation data structure
allspans []*mspan // all spans out there
// Malloc stats.
largealloc uint64 // bytes allocated for large objects
nlargealloc uint64 // number of large object allocations
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
curArena struct {
base, end uintptr
}
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
}
pages:堆的也分配
allspans:所有分配的span
largealloc:超过32k大对象的分配空间的字节数
nlargealloc:超过32k大对象分配的对象数目
central:mcentral结构单元
spanalloc:mspan分配器
cachealloc:mache分配器
curArena: 当前arena的起始地址
arenas:将虚拟地址空间以arena帧的形式一片片分割
arenas变成了一个heapArea的指针数组。
type heapArena struct {
bitmap [heapArenaBitmapBytes]byte
spans [pagesPerArena]*mspan
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
zeroedBase uintptr
}
这个结构体描绘了一个arena,查看runtime/malloc.go
heapArenaBytes = 1 << logHeapArenaBytes
// logHeapArenaBytes is log_2 of heapArenaBytes. For clarity,
// prefer using heapArenaBytes where possible (we need the
// constant to compute some other constants).
logHeapArenaBytes = (6+20)*(_64bit*(1-sys.GoosWindows)*(1-sys.GoarchWasm)) + (2+20)*(_64bit*sys.GoosWindows) + (2+20)*(1-_64bit) + (2+20)*sys.GoarchWasm
// heapArenaBitmapBytes is the size of each heap arena's bitmap.
heapArenaBitmapBytes = heapArenaBytes / (sys.PtrSize * 8 / 2)
pagesPerArena = heapArenaBytes / pageSize
在64位Linux系统上,单个arena的大小heapArenaBytes是64MB,每个arena分成8k大小的页。整个虚拟内存的第一级切分图,如下所示:

每个heapArena结构体按下图管理每个arena,
bitmap在gc的时候起作用,其中每个字节标识了arena每四个指针大小空间(也就是32字节大小)的内容情况:1位标识是否已扫描,一位标识是否有指针

mcentral
从mheap的结构体中,可以看到,mheap创建了一个包含164个mcentral对象的数组。也就是mheap管理着164个mcentral。mcentral结构体类型如下所示:
type mcentral struct {
lock mutex
spanclass spanClass
nonempty mSpanList // list of spans with a free object, ie a nonempty free list
empty mSpanList // list of spans with no free objects (or cached in an mcache)
// nmalloc is the cumulative count of objects allocated from
// this mcentral, assuming all spans in mcaches are
// fully-allocated. Written atomically, read under STW.
nmalloc uint64
}
lock:互斥锁
spanclass:所属span的类型,从这里可以推断,应该是每一种类型的span,都有一个对应的mcentral结构体
nonempty:含有空对象且可分配的span列表,查看这个类型,可以发现是个知头尾的双向链表
type mSpanList struct {
first *mspan // first span in list, or nil if none
last *mspan // last span in list, or nil if none
}
empty:不含空对象且不可分配的span列表
nmalloc:已分配的累计对象数目
mcentral为所有mcache提供分配好的mspan资源。当某一个P私有的mcache没有可用的span的以后,会动态的从mcentral申请,之后就会缓存在mcache中。前面介绍到mheap会创建134个mcentral,也就是每个class类型的span会有两个对应的mcentral:span内包含指针和不包含指针的。
mcentral与mspan的对应关系如下图所示:
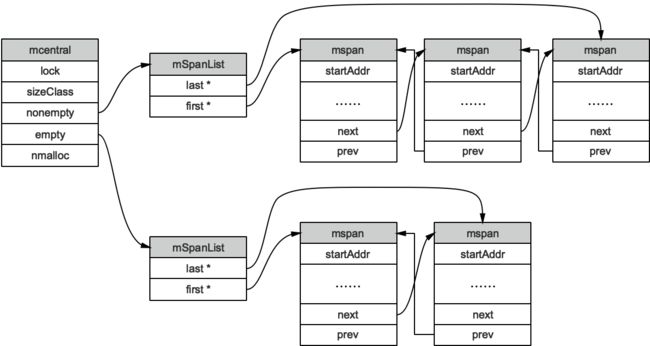
先简单总结mcache从mcentral获取和归还span:
获取:先加锁,从nonempty链表找一个可用的mspan,从该链表删除,并加入到empty链表中,然后把mspan返回给当前P中运行的协程,解锁。
归还:先加锁, 把mspan从empty链表删除,然后加入到nonempty链表,解锁。
mcache
mspan作为内存管理的基本单位,显然需要上一级单位来管理它:mcache。在runtime/mcache.go里面找到了这个结构体,只显示关键字段。这是一个指针数组,再想到mspan结构的类型,可以想到是多条链表。
type mcache struct {
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
}
查看这个numSpanClasses,发现值是67<<1,等于134。意味着是上述class分类总数的两倍,这是为何?原因是:上述的每种claas类型的span都有两组列表,其中第一组列表中的对象包含了指针,第二组列表中表示的对象不包含指针。这样做的目的是以空间换时间去提高GC扫描的性能,毕竟不用扫描不带指针的那一条列表。mcache和span的对应关系如下图所示:

mcache在初始化的时候是空的,随着程序的执行,会动态的从central中获取并缓存下来。查看源码我们发现,mcache结构体是没有锁的,是如何保证多线程安全的?每一个P(goroutine调度的GPM模型参考https://studygolang.com/articles/26795)都会有自己一个私有的mache,而每次只会有一个协程运行在同一个P上,也就是说每个P都拥有一个本地、私有化的mcache(内存池),所以不用加锁。
小结
以64位4核处理器的Linux系统为例,4个逻辑处理器的go运行环境配置为例,虚拟内存堆区、mheap、mcentral、mcache和逻辑处理器p及goroutine的关联关系如下入所示:

1、mheap创建了4M个heapArena结构体,把48位地址线管理的256T地址空间切分成一个个64MB的叫做Arena的块。同时创建了包含134个元素的mcentral数组,每一个mcentral管理着同属一类classid的span块组成的链表。而每一类classid的span块列表又分为带指针的span块和不带指针的span块,所以67类classid需要134个mcentral来管理。
2、每个mcentral中有两个span链表:带空余对象的可分配span链表和不带空余对象或在mcache中已被使用的不可分配span列表。当P向本地的mcache申请span,而得不到时,mcache会向mcentral申请。mcentral为所有P共有,所以需要加锁。
3、每一个逻辑P都有独立的mcache用于缓存该逻辑处理器已申请的span,当有G运行在P上,且要去申请内存时,会优先从与该P对应绑定的mcache中申请,因为在P上同时只会有一个G在运行,且mcache专属于P,所以不需要加锁。与mcentral类似,每个mcache针对每个span类型的class维护两条链表:带指针的span块和不带指针的span块,所以每个mcache中也有134条span块的链表。
4、根据所管理对象大小,mspan一共被划分为66类。mspan将分配得到的arena页再度按所属种类的对象大小再度切分,以 class类型24为例,占据一页空间,对象大小为480bytes,因此该span被分为17个大小为480字节的小块,一共使用8160字节,并有32字节被浪费掉。
内存分配
小于16字节的微小对象:
使用mcache的微小分配器,分配小于16B的对象。
16B~32KB的小对象:
由运行G所在P的去对应的mcache中查找对应大小的class,如果mcache分配失败,则去mcentral中查找,否则再去mheap中申请新的页用于mspan,并挂在mcentral与mcache中。
大于32K大对象:
由mheap直接申请,并分配在保存在mcentral的class0类型中。