Python模块requests基本用法
简介
Python 的 requests 模块是一个流行的第三方库,用于发送HTTP请求。它提供了一组简洁且易于使用的API,使得在Python中进行网络通信变得更加简单和灵活。
目录
1. 基本概念
1.1. HTTP 协议
1.2. GET 请求
1.3. POST 请求
1.4. get 和 post 的区别
2. 发送请求
2.1. 发送 get 请求
2.2. 发送 post 请求
2.3. 发送 put 请求
2.4. 发送 delete 请求
3. 处理响应
3.1. 获取响应内容
3.2. 获取响应状态
3.3. 获取响应头部信息
3.4. 处理重定向
3.5. 获取其他响应信息
3.6. 指定内容字符集
4. 会话管理和 Cookie
4.1. 会话管理
4.2. Cookie 操作
5. 异常处理
5.1. 捕获所有异常
5.2. 捕获状态码异常
5.3. 捕获连接失败异常
5.4. 捕获请求超时异常
6. 其他方法
6.1. 文件上传
6.2. 代理设置
6.3. 快速读取多个地址信息
1. 基本概念
1.1. HTTP 协议
- HTTP协议(Hypertext Transfer Protocol)是一种用于在网络上发送和接收HTML页面或其他内容的协议,是基于客户端-服务器模型,客户端发起HTTP请求,服务器响应请求并返回相应的内容。
- HTTP协议使用URL(Uniform Resource Locator)来标识互联网上的资源,如网页、图片、视频等。客户端通过发送HTTP请求来获取特定URL对应的资源,请求包括请求方法(如GET、POST)、头部信息(如浏览器类型、请求资源类型等)和可选的请求体(如表单数据、请求参数等)。
HTTP协议是在互联网上进行数据传输和通信的基础协议,它为客户端和服务器之间提供了一种简单、开放的通信方式,使得互联网上的信息交流和资源访问变得更加便捷和高效。其主要作用是
传输数据:HTTP协议是一种用于传输数据的协议,它可以在客户端和服务器之间传输各种类型的数据,如HTML页面、图片、视频、音频等。通过HTTP,用户可以在浏览器中访问网页,下载文件,发送和接收数据等。
客户端和服务器通信:HTTP协议定义了客户端和服务器之间的通信规则。客户端发送HTTP请求到服务器,服务器解析请求并发送HTTP响应回客户端。这种通信模式使得客户端可以请求特定资源,服务器可以根据请求进行处理并返回相应的内容。
资源定位和标识:HTTP协议使用URL来定位和标识互联网上的资源。URL由协议类型、服务器地址、资源路径等组成,通过URL可以唯一确定一个资源的位置。
无状态协议:HTTP协议是无状态的,即服务器不会保留与客户端之间的任何状态信息。每个HTTP请求都是独立的,服务器只处理请求并返回相应的响应,不会对之前的请求进行记忆。这种无状态的设计使得HTTP协议具有简单、可扩展的特性。
安全性:HTTP协议本身是明文传输的,数据在传输过程中可能会被窃听或篡改。为了保障通信的安全性,可以使用HTTPS(HTTP Secure)协议,它在HTTP协议之上添加了SSL/TLS加密层,对数据进行加密和认证。
1.2. GET 请求
- GET请求是HTTP协议中的一种请求方法,用于从服务器获取资源。它是最常见和最简单的请求方法之一。
- GET请求中的请求参数会暴露在URL中,因此,不应将敏感信息通过GET请求传递。对于传输敏感信息(例如:用户、密码)或需要修改服务器上资源状态的请求,应使用POST请求或其他更安全的请求方法。
get 请求的特点
- 请求参数通过URL中的查询字符串传递,如:http://www.baidu.com/path?param1=value1¶m2=value2
- GET请求对请求参数的长度有限制,因为URL的长度是有限制的,不适合传输大量的数据。
- GET请求是幂等的,即多次重复发送同样的GET请求,不会对服务器产生副作用,也不会修改服务器上的资源状态。
- GET请求可以被缓存,如果相同的GET请求被发送多次,中间的请求可以通过缓存直接返回响应结果。
get 请求的优点
- 简单和直观:GET请求是HTTP协议中最简单的请求方法,只需要通过URL进行请求信息的传递,易于理解和实现。
- 可缓存:GET请求可以被缓存,如果相同的GET请求被重复发送,中间的请求可以通过缓存直接返回响应结果,减少了服务器的负载和网络传输时间。
- 可书签化:由于GET请求的参数附加在URL中,因此可以将带有GET请求的URL添加到书签中,方便用户保存和分享特定的资源。
- 可见性:GET请求的参数和请求信息都会暴露在URL中,可以直观地看到请求的内容,方便调试和问题排查。
get 请求的缺点
- 长度限制:GET请求的请求参数通过URL的查询字符串传递,URL的长度是有限制的,所以对于大量数据的传输不合适,存在长度限制问题。
- 安全性问题:GET请求中的请求参数暴露在URL中,可能被其他人在网络传输过程中截获或记录,存在安全风险。敏感信息(如密码)不应通过GET请求传递。
- 副作用问题:GET请求属于幂等请求,即多次发送同样的GET请求不会对服务器产生副作用。但对于涉及修改服务器资源状态或产生其他副作用的请求(如增、删、改等操作),不应该使用GET请求。
1.3. POST 请求
- POST请求是HTTP协议中的一种请求方法,用于向服务器提交数据,并请求服务器处理该数据。与GET请求相比,POST请求常用于发送较大量的数据、修改服务器上的资源状态以及进行敏感操作等。
- POST请求不仅可以传输表单数据,也可以传输其他类型的数据,如JSON、XML等。使用POST请求时,需要根据具体的场景和需求,将数据格式化和编码成对应的请求体数据类型。
port 请求的特点
- 数据传输较安全:相对于GET请求将数据暴露在URL中,POST请求将数据放在消息体中发送,对于敏感信息更为安全。
- 请求参数长度无限制:POST请求中的参数和数据不会受到URL长度限制,能够传输较大量的数据。
- 不可缓存:由于POST请求需要向服务器提交数据,每次请求的数据都可能不同,所以大部分情况下不能被缓存,需要实时重新请求。
- 非幂等性:POST请求可能对服务器资源产生副作用,即每次发送相同的POST请求,可能会对服务器资源状态进行修改。
port 请求的优点
- 数据安全性更高:相对于GET请求,POST请求将数据放在请求的消息体中传输,而不是直接附加在URL中,因此对于敏感信息的传输更加安全,减少了数据被恶意拦截或篡改的风险。
- 容量大小无限制:POST请求传输的数据没有URL长度限制,可以传输较大的数据量,适合上传文件或传输大量文本数据。
- 更好的请求语义:POST请求用于向服务器提交数据并请求处理,适合于对服务器资源进行修改、创建等操作,具有更好的请求语义。使用POST请求可以清晰地表达意图,使服务器能够更好地处理和响应请求。
- 支持多种数据格式:POST请求可以使用不同的Content-Type来指定数据格式,可以传输多种类型的数据,如表单数据、JSON数据、XML数据等,具有更大的灵活性。
post 请求的缺点
- 非幂等性:POST请求可能对服务器资源产生副作用,即每次发送相同的POST请求,都可能会对服务器资源状态进行修改,而不仅仅是获取资源。这意味着相同的POST请求不能重复执行,可能会导致不可预料的结果。
- 不可缓存:由于POST请求中往往包含了对服务器资源的修改,为了保证数据的一致性,POST请求通常不能被缓存,需要实时重新请求,增加了服务器的负载和网络传输时间。
- 请求复杂度相对较高:相对于GET请求,POST请求在构造和发送上相对复杂一些,需要将数据放入请求的消息体中,并设置合适的Content-Type、Content-Length等请求头部信息。
1.4. get 和 post 的区别
- GET请求适用于获取资源、查询或浏览数据等操作,传输的数据量较小且不涉及敏感信息。
- POST请求适用于向服务器提交数据、修改资源状态等操作,支持传输较大量的数据和敏感信息的安全传输。
参数位置和传输方式
- GET请求:参数通过URL的查询字符串传递,附加在URL的末尾,以
?开头,多个参数之间使用&分隔,例如:http://www.baidu.com/path?param1=value1¶m2=value2。数据可以通过URL进行传输,也可以通过请求头的字段进行传输。- POST请求:参数和数据放在请求的消息体中,通过请求头部的Content-Type字段来指定数据的类型,常见的有application/x-www-form-urlencoded、multipart/form-data、application/json等。
数据传输安全性
- GET请求:参数和数据暴露在URL中,容易被拦截、篡改或记录,不适合传输敏感信息。
- POST请求:参数和数据放在请求的消息体中传输,对于敏感信息的安全性更高。
请求语义和副作用
- GET请求:主要用于从服务器获取资源,获取数据的语义明确,是幂等的,多次请求结果相同,不会对服务器产生副作用。
- POST请求:主要用于向服务器提交数据,请求可能对服务器产生副作用,常用于修改、创建资源等操作,不具备幂等性。
URL长度限制
- GET请求:由于参数在URL中传递,URL的长度存在限制(不同浏览器和服务器对URL长度的限制不同),不适合传输大量数据。
- POST请求:没有URL长度限制,可以传输较大量的数据。
缓存
- GET请求:可以被缓存,如果相同的GET请求被重复发送,中间的请求可以通过缓存直接返回响应结果,减少了服务器的负载和网络传输时间。
- POST请求:通常不会被缓存,因为POST请求可能对服务器资源产生副作用,需要实时重新请求。
2. 发送请求
2.1. 发送 get 请求
语法
requests.get(
url #必选参数,指定URL地址
params=None #可选参数,用于指定查询参数,可以是一个字典或一个字符串。
**kwargs #可选参数,用于传递其他参数,例如请求头、超时时间等。
)
**kwargs 可以是:
headers:设置请求头信息
timeout:设置请求的超时时间(单位:秒)
发送一个简单的 get 请求
import requests
# 发送get请求
response = requests.get('https://www.baidu.com/')
# 打印状态码
print(response)
# 打印内容
print(response.text)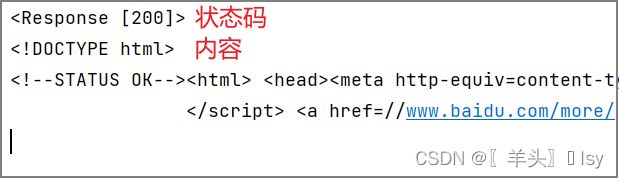
发送带查询参数的 get 请求
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://www.baidu.com/', params=params)
发送GET请求并加入其他参数(设置请求头和请求超时时间)
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get('https://www.baidu.com/', headers=headers, timeout=5)
2.2. 发送 post 请求
语法
requests.post(
url #必选参数,指定URL地址。
data=None #可选参数,传递表单数据。可以是一个字典、字符串或二进制数据。
json=None #可选参数,传递JSON数据。将自动将数据编码为JSON格式并设置请求头部的Content-Type为application/json。
headers=None #可选参数,指定HTTP请求的头部信息。可以通过字典形式传递。
cookies=None #可选参数,传递Cookie信息。可以是字典或CookieJar对象。
auth=None #可选参数,用于身份验证,可以是身份验证相关的对象,如HTTPBasicAuth或HTTPDigestAuth等。
timeout=None #可选参数,设置请求的超时时间(单位:秒)
allow_redirects #可选参数,用于设置是否允许重定向(默认True)。
**kwargs #可选参数,用于传递其他参数,例如proxies、verify(SSL验证)等。
)
发送一个简单的 post 请求
import requests
# 发送post请求
response = requests.post('https://www.baidu.com/')
# 打印状态码
print(response)
# 打印内容
print(response.text)
发送JSON数据的POST请求
import json
url = 'https://www.baidu.com/'
data = {'key': 'value'}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, json=json.dumps(data), headers=headers)
发送带有请求头和超时时间的POST请求
url = 'https://www.baidu.com/'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.post(url , headers=headers, timeout=5)
送带有身份验证的POST请求
from requests.auth import HTTPBasicAuth
url = 'https://www.baidu.com/'
auth = HTTPBasicAuth('username', 'password')
response = requests.post(url, auth=auth)
发送带有Cookie的POST请求
url = 'https://www.baidu.com/'
cookies = {'session_id': '123456'}
response = requests.post(url, cookies=cookies)
2.3. 发送 put 请求
语法
requests.put(
url #必选参数,指定URL地址。
data=None #可选参数,传递表单数据。可以是一个字典、字符串或二进制数据。
json=None #可选参数,传递JSON数据。将自动将数据编码为JSON格式并设置请求头部的Content-Type为application/json。
headers=None #可选参数,指定HTTP请求的头部信息。可以通过字典形式传递。
cookies=None #可选参数,传递Cookie信息。可以是字典或CookieJar对象。
auth=None #可选参数,用于身份验证,可以是身份验证相关的对象,如HTTPBasicAuth或HTTPDigestAuth等。
timeout=None #可选参数,设置请求的超时时间(单位:秒)
allow_redirects #可选参数,用于设置是否允许重定向(默认True)。
**kwargs #可选参数,用于传递其他参数,例如proxies、verify(SSL验证)等。
)
发送一个简单的 put 请求
# 发送put请求
response = requests.put('https://www.baidu.com/')
# 打印状态码
print(response)
# 打印内容
print(response.text)
2.4. 发送 delete 请求
语法
requests.delete(
url #必选参数,指定URL地址。
params=None #可选参数,传递URL查询参数。可以是一个字典或字符串。
headers=None #可选参数,指定HTTP请求的头部信息。可以通过字典形式传递。
cookies=None #可选参数,传递Cookie信息。可以是字典或CookieJar对象。
auth=None #可选参数,用于身份验证,可以是身份验证相关的对象,如HTTPBasicAuth或HTTPDigestAuth等。
timeout=None #可选参数,设置请求的超时时间(单位:秒)
allow_redirects #可选参数,用于设置是否允许重定向(默认True)。
**kwargs #可选参数,用于传递其他参数,例如proxies、verify(SSL验证)等。
)
发送一个简单的 delete 请求
# 发送delete请求
response = requests.delete('https://www.baidu.com/')
# 打印状态码
print(response)
# 打印内容
print(response.text)
3. 处理响应
3.1. 获取响应内容
语法
response.text #以字符串形式返回响应内容。
response.content #以字节形式返回响应内容。
response.json() #以JSON解析并返回响应内容。如果响应内容不是有效的JSON格式,则会抛出JSONDecodeError异常。以 "字符串" 形式返回响应内容
response = requests.get('https://www.baidu.com/')
print(response.text)
以 "字节" 形式返回响应内容
response = requests.get('https://www.baidu.com/')
print(response.content)
以 "JSON" 形式返回响应内容(如果响应内容不是有效的JSON格式,则会抛出JSONDecodeError异常。)
response = requests.get('https://www.baidu.com/')
print(response.json())
3.2. 获取响应状态
语法
response.status_code #返回响应的状态码。
response.ok #返回布尔值,表示请求是否成功(2xx响应码)。
response.raise_for_status() #如果响应状态码表明请求不成功,则抛出HTTPError异常。获取响应的 "状态码"
response = requests.get('https://www.baidu.com/')
print(response.status_code)
获取响应的 "状态码的布尔值"
response = requests.get('https://www.baidu.com/')
print(response.ok)
"状态码"异常则抛出 "ConnectionError" 异常。
response = requests.get('https://www.baidu.com/')
print(response.raise_for_status())
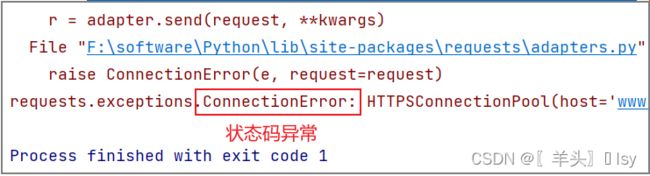
3.3. 获取响应头部信息
语法
response.headers #返回响应头部的字典形式。
response.headers['header_name'] #返回指定头部字段的值。以 "字典形式" 返回响应头部的全部信息
response = requests.get('https://www.baidu.com/')
print(response.headers)
返回指定头部 "字段的值"
response = requests.get('https://www.baidu.com/')
print(response.headers['Date'])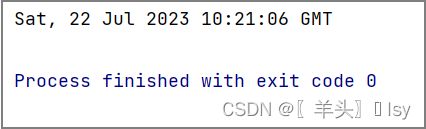
3.4. 处理重定向
语法
response.history #返回一个包含重定向历史的列表,每个元素是一个Response对象。
response.url #返回最终响应的URL。返回一个包含 "重定向历史" 的列表
response = requests.get('https://www.baidu.com/')
print(response.history)
返回最终响应的 "URL"
response = requests.get('https://www.baidu.com/')
print(response.url)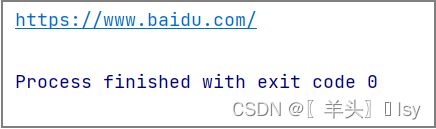
3.5. 获取其他响应信息
语法
response.encoding #返回响应使用的字符编码。
response.cookies #返回响应的Cookies信息,可以进行进一步操作。返回响应的 "字符编码"
response = requests.get('https://www.baidu.com/')
print(response.encoding)
返回响应的 "cookies信息"
response = requests.get('https://www.baidu.com/')
print(response.cookies)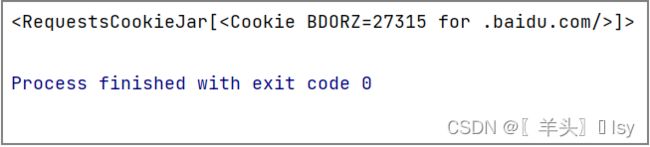
3.6. 指定内容字符集
# 获取结果
response = requests.get('https://www.baidu.com/')
# 按内容展示
html = response.text
# 指定内容的字符集
html = response.content.decode('utf-8')
# 输出结果
print(html)
4. 会话管理和 Cookie
4.1. 会话管理
- 发送多个相关请求时,使用会话(Session)对象来管理这些请求,以便在多个请求之间共享状态、Cookie和身份验证等信息。
举例
import requests
# 创建会话对象
session = requests.Session()
# 设置会话级别的头部信息(可选)
session.headers.update({'User-Agent': 'Mozilla/5.0'})
# 第一个请求(使用post请求登录)
response1 = session.post('http://xxx.com/login', data=login_data)
# 第二个请求(登录以后的其他操作1)
response2 = session.get('http://xxx.com/xxx1')
# 第三个请求(登录以后的其他操作2)
response3 = session.get('http://xxx.com/xxx2')
# 关闭会话
session.close()- 创建一个会话对象后,身份信息和cookie都可以共享,适用于多个相关联的请求。
使用会话对象的优点
自动管理Cookie:会话对象会自动在请求中发送和更新Cookie信息,无需手动处理。
共享会话级别信息:会话对象可用于共享头部信息、身份验证等。这避免了在每个请求中单独设置这些信息的麻烦。
连接重用:会话对象会自动重用连接,提高请求性能。
4.2. Cookie 操作
1、添加 cookie
import requests
url = 'http://xxx.com'
cookies = {'name': 'value'}
# 请求中添加cookie值
response = requests.get(url, cookies=cookies)
2、获取 cookie 值
import requests
response = requests.get('https://www.baidu.com/')
# 直接打印cookie全部信息
print(response.cookies)
# 通过name和value获取名称和值
for cookie in response.cookies:
print(cookie.name, cookie.value)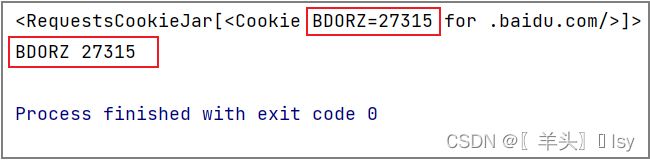
3、删除 cookie
import requests
response = requests.get('https://www.baidu.com/')
# 删除名称为'BDORZ'的 Cookie
response.cookies.pop('BDORZ')
# 删除所有Cookie
response.cookies.clear()
4、添加 cookie 到会话
import requests
# 创建一个会话
session = requests.Session()
# 添加Cookie到会话
cookies = {'name': 'value'}
session.cookies.update(cookies)
# 使用包含Cookie的会话发送请求
response = session.get(url)
# 清除所有Cookie
session.cookies.clear()
5. 异常处理
5.1. 捕获所有异常
- RequestException 是所有异常的基类,可以用于捕获所有的异常情况。当发生网络请求错误时,例如连接超时、DNS解析失败等,可以使用该异常来捕获并处理。
requests.exceptions.RequestException示例
import requests
from requests.exceptions import RequestException
try:
response = requests.get(url)
print('响应正常,执行下一步')
except RequestException as e:
print("请求发生异常:", str(e))
5.2. 捕获状态码异常
- HTTPError 表示HTTP错误状态码(4xx或5xx)的响应。可以使用响应对象的
.raise_for_status()方法来引发该异常。
requests.exceptions.HTTPError示例
import requests
from requests.exceptions import HTTPError
try:
response = requests.get(url)
response.raise_for_status()
print('响应正常,执行下一步')
except HTTPError as e:
print("HTTP错误:", str(e))
5.3. 捕获连接失败异常
- ConnectionError 用于捕获请求连接失败的异常,例如:无法连接到目标服务器,或者网络连接中断。
requests.exceptions.ConnectionError示例
import requests
from requests.exceptions import ConnectionError
try:
response = requests.get(url)
print('响应正常,执行下一步')
except ConnectionError as e:
print("连接错误:", str(e))
5.4. 捕获请求超时异常
Timeout 用于捕获请求超时的异常
requests.exceptions.Timeout示例
import requests
from requests.exceptions import Timeout
try:
response = requests.get(url, timeout=5)
print('响应正常,执行下一步')
except Timeout as e:
print("请求超时:", str(e))
6. 其他方法
6.1. 文件上传
语法
requests.post(
url #必选参数,指定URL地址
files #可选参数,指定文件名
)1、发送单个文件
import requests
url = 'http://xxx.com/'
file_path = './file.txt'
# 读取文件
with open(file_path, 'rb') as file:
# 将读取的二进制信息赋值为字典
files = {'file': file}
# 通过字典发送post请求
response = requests.post(url, files=files)
# 获取响应信息
print(response.text)
2、发送多个文件(方法同上,多个文件使用遍历方式)
import requests
url = 'http://xxx.com/'
file_paths = {
'file1': './file1.txt',
'file2': './file2.txt'
}
uploaded_files = {}
# 通过循环方式读取多个文件
for field_name, file_path in file_paths.items():
with open(file_path, 'rb') as file:
files = {field_name: file}
response = requests.post(url, files=files)
uploaded_files[field_name] = response.text
print(uploaded_files)
6.2. 代理设置
- 在计算机网络中,代理(Proxy)是一种充当中间人的服务器,它在客户端和目标服务器之间起到转发和代理的作用。当客户端发送请求时,代理服务器接收请求并将其转发给目标服务器。然后,代理服务器接收来自目标服务器的响应,并将其转发回客户端。
- 在使用 requests 库发送 HTTP 请求时,代理(Proxy)可以用于访问被限制或无法直接访问的网站、隐藏真实的 IP 地址、实现访问控制等功能。通过配置代理,请求将通过代理服务器,而不是直接与目标服务器通信。这样,目标服务器会认为请求来自代理服务器,而不是真实的客户端。
1、通过proxies参数设置全局代理
import requests
# 设置服务器地址和端口
proxies = {
'http': 'http://xxx.com:8080',
'https': 'https://xxx.com:8080'
}
# 通过proxies发送
response = requests.get(url, proxies=proxies)
2、使用环境变量设置代理
import requests
import os
# 通过os获取本地变量去设置代理
os.environ['HTTP_PROXY'] = 'http://xxx.com:8080'
os.environ['HTTPS_PROXY'] = 'https://xxx.com:8080'
# 发送请求时,自动在环境变量中读取代理设置
response = requests.get(url)
3、环境变量中读取代理设置
import requests
# 定义代理的地址和端口
proxy = 'http://xxx.com:8080'
# 创建一个会话
session = requests.Session()
# 设置代理
session.proxies = {'http': proxy, 'https': proxy}
# 发送请求
response = session.get(url)
4、代理中设置用户、密码
import requests
proxies = {
# 设置用户 : 密码 @ 地址 : 端口
'http': 'http://username:[email protected]:8080',
'https': 'https://username:[email protected]:8080'
}
# 通过设置的代理,发送请求
response = requests.get(url, proxies=proxies)
6.3. 快速读取多个地址信息
示例(简单读取某地址信息)
import requests
def get_html(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
def main():
urls = [
'https://www.xxx1.com/',
'https://www.xxx2.com/',
'https://www.xxx3.com/'
]
for url in urls:
html = get_html(url)
print(html)
if __name__ == '__main__':
main()