EalsticSearch添加字段后重建索引方法
前言
EalsticSearch作为全文搜索引擎被大家广泛应用于项目中,大部项目原始数据一般都存在关系型数据库中,如Mysql。然后通过同步或者异步方式将需要搜索的数据同步至EalsticSearch,常用方法有:代码中先写入Mysql,然后再写入EalsticSearch,异步的一般使用Canal+MQ的方式异步抽取数据写入ES。由于ES中的索引字段是不可变的,不像Mysql需要添加字段时可以随时添加,而ES索引一旦创建好了就不能再添加字段,动态添加的数据也无法创建索引,本文介绍一种简单的方式,使用ES别名+重建索引的方式在一定程度上解决ES添加字段的问题。
项目中使用别名替代索引
比如我们需要创建一个索引bucket_size_index
PUT /bucket_size_index
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"size": {
"type": "long"
},
"tenantId": {
"type": "long"
},
"time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
在项目中我们不要直接使用bucket_size_index,先创建一个别名bucket_size_alias
POST /_aliases
{
"actions": [
{
"add": {
"index": "bucket_size_index",
"alias": "bucket_size_alias"
}
}
]
}
然后在项目中使用bucket_size_alias添加数据
POST /bucket_size_alias/_doc/1
{
"id": "1",
"tenantId": 1,
"size": 1024,
"time": "2023-07-17 18:00:00"
}
创建新索引使用reindex重建索引
有一天我们需要再添加一个字段bucket_name,我们可以创建了个新的索引 bucket_size_index_2
PUT /bucket_size_index_2
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"bucket_name": {
"type": "keyword"
},
"size": {
"type": "long"
},
"tenantId": {
"type": "long"
},
"time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
使用_reindex将bucket_size_index中的数据重建到 bucket_size_index_2中
POST _reindex
{
"source": {
"index": "bucket_size_index"
},
"dest": {
"index": "bucket_size_index_2"
}
}
如果数据量非常大reindex会很慢,接口会超时,我们可以使用异步reindex
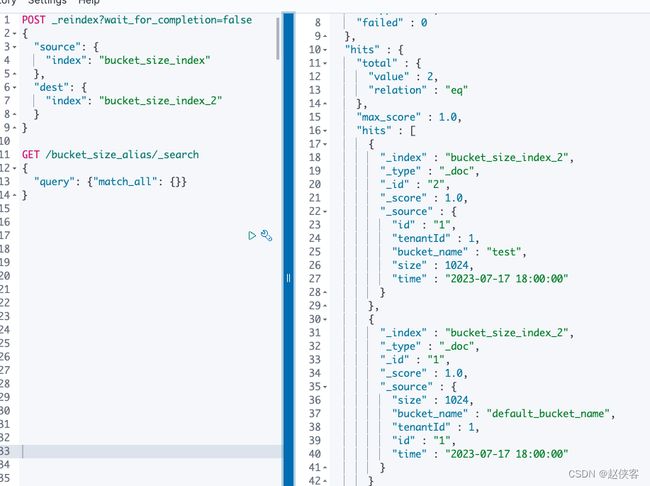
POST _reindex?wait_for_completion=false
{
"source": {
"index": "bucket_size_index"
},
"dest": {
"index": "bucket_size_index_2"
}
}
接口会返回任务ID
{
"task" : "jnj5k6NlQK-LvEopzRycxw:90463975"
}
可以查询取消任务状态
//查询所有状态
GET _tasks?detailed=true&actions=*reindex
//查询指定任务状态
GET /_tasks/jnj5k6NlQK-LvEopzRycxw:90463975
//取消任务
POST _tasks/jnj5k6NlQK-LvEopzRycxw:90463975/_cancel
删除老别名,创建新别名
因为项目中使用的别名bucket_size_alias还是指向bucket_size_index,我们需要将其删除再指向bucket_size_index_2
POST /_aliases
{
"actions" : [
{ "remove": { "index": "bucket_size_index", "alias": "bucket_size_alias" } },
{ "add": { "index": "bucket_size_index_2", "alias": "bucket_size_alias" } }
]
}
然后我可以继续添加数据了
POST /bucket_size_alias/_doc/2
{
"id": "1",
"tenantId": 1,
"bucket_name":"test",
"size": 1024,
"time": "2023-07-17 18:00:00"
}
可是我们发现新添加的数据有bucket\_mame这个字段,老数据没有bucket\_name字段,这里我们可以通过\_update\_by\_query批量给bucket\_name添加个默认值
POST /bucket_size_alias/_update_by_query
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "bucket_name"
}
}
}
},
"script":{
"inline" : "ctx._source.bucket_name= 'default_bucket_name'",
"lang" : "painless"
}
}
这样老数据也有了新的字段