面试笔记(02)
1、 流量很大,请求很多,秒杀怎么处理这些大量的请求?
使用MQ消息机制,达到同步转异步的效果。
使用MQ消息队列实现异步的步骤为:点击秒杀,返回请稍后查看结果,请求去MQ队列中排队,等排队执行完成后返回给用户信息。这样就可以大大减少服务器的压力,提升用户体验度。
2、FastDFS
(1)开源的分布式文件系统,主要对文件进行存储、同步、上传、下载,有自己的容灾备份、负载均衡、线性扩容机制。
(2)FastDFS架构主要包含Tracker server和Storage server。客户端请求Tracker server进行文件上传、下载的时候,通过Tracker server调度最终由Storage server完成文件上传和下载。
Tracker server:跟踪器或者调度器,主要起负载均衡和调度作用。通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务。
Storage server:存储服务器,作用主要是文件存储,完成文件管理的所有功能。客户端上传的文件主要保存在Storage server上,Storage server没有实现自己的文件系统而是利用操作系统的文件系统去管理文件。
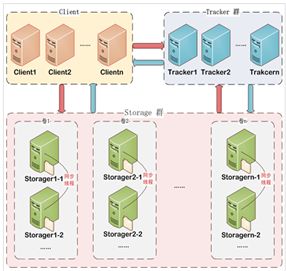
【扩展】:存储服务器采用了分组/分卷的组织方式。
整个系统由一个组或者多个组组成;
组与组之间的文件是相互独立的;
所有组的文件容量累加就是整个存储系统的文件容量;
一个组可以由多台存储服务器组成,一个组下的存储服务器中的文件都是相同的,组中的多台存储服务器起到了冗余备份和负载均衡的作用;
在组内增加服务器时,如果需要同步数据,则由系统本身完成,同步完成之后,系统自动将新增的服务器切换到线上提供使用;
当存储空间不足或者耗尽时,可以动态的添加组。只需要增加一台服务器,并为他们配置一个新的组,即扩大了存储系统的容量。
3、fastDFS资源链接如何防止被盗用?
(1)FastDFS扩展模块内置了通过token来实现防盗链的功能。开启防盗链后,访问文件是需要在url中加两个参数:token和ts。ts为时间戳,token为系统根据时间戳和密码生成的信物。
http.conf中防盗链相关的几个参数如下:
http.anti_steal.check_token:是否做token检查,缺省值为false。
http.anti_steal.token_ttl:token TTL,即生成token的有效时长
http.anti_steal.secret_key:生成token的密钥,尽量设置得长一些,千万不要泄露出去
http.anti_steal.token_check_fail:token检查失败,返回的文件内容,需指定本地文件名
(2)用nginx 用nginx去做负载,访问nginx地址,然后 nginx和 域名做绑定。
4、docker常用命令
镜像操作
1)检索
docker search 关键字。
docker search redis
2)拉取
docker pull 镜像名:tag(tag是可选的,tag表示标签,多为软件的版本,默认是latest)
docker pull mysql:5.7
3)列表(查看本地所有镜像)
docker images
4)删除(删除指定的本地镜像)
docker rmi image-id
容器操作
1)启动容器
docker start 容器的id
2)查看运行中的容器
docker ps
3)查看所有的容器
docker ps -a
4)停止运行中的容器
docker stop 容器的id
5)删除一个容器
docker rm 容器id
6)查看容器的日志
docker logs container-name/container-id
7)启动一个带端口映射的tomcat
docker run -d -p 8888:8080 tomcat
注:
-d 后台运行
-p 将主机的端口映射到容器的一个端口
主机端口:容器内部的端口
8)正确启动mysql的命令
docker run --name mysql01 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
做端口映射的启动命令
docker run -p 3306:3306 --name mysql02 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
5、如何从主机进入docker容器
(1)使用docker attach进入Docker容器
Docker提供了attach命令来进入Docker容器。
接下来我们创建一个守护态的Docker容器,然后使用docker attach命令进入该容器。
$ sudo docker run -itd ubuntu:14.04 /bin/bash
使用docker ps查看到该容器信息,接下来使用docker attach进入该容器。
$ sudo docker attach 44fc0f0582d9
使用该命令有一个问题。当多个窗口同时使用该命令进入该容器时,所有的窗口都会同步显示。如果有一个窗口阻塞了,那么其他窗口也无法再进行操作。
因为这个原因,所以docker attach命令不太适合于生产环境,平时自己开发应用时可以使用该命令。
(2)使用SSH进入Docker容器
在生产环境中排除了使用docker attach命令进入容器之后,还可以使用ssh。在镜像(或容器)中安装SSH Server,这样就能保证多人进入容器且相互之间不受干扰了,相信大家在当前的生产环境中(没有使用Docker的情况)也是这样做的。但是使用了Docker容器之后不建议使用ssh进入到Docker容器内。
(3)使用nsenter进入Docker容器
在上面两种方式都不适合的情况下,还有一种比较方便的方法,即使用nsenter进入Docker容器。
nsenter可以访问另一个进程的名称空间。所以为了连接到某个容器我们还需要获取该容器的第一个进程的PID。可以使用docker inspect命令来拿到该PID。
docker inspect命令使用如下:$ sudo docker inspect --help
inspect命令可以分层级显示一个镜像或容器的信息。比如我们当前有一个正在运行的容器。可以使用docker inspect来查看该容器的详细信息。
$ sudo docker inspect 容器id
如果要显示该容器第一个进行的PID可以使用如下方式
$ sudo docker inspect -f {{.State.Pid}} 容器id
在拿到该进程PID之后我们就可以使用nsenter命令访问该容器了。
$ sudo nsenter --target 3326 --mount --uts --ipc --net --pid
其中的3326即刚才拿到的进程的PID
(4)使用docker exec进入Docker容器
除了上面几种做法之外,docker在1.3.X版本之后还提供了一个新的命令exec用于进入容器,这种方式相对更简单一些,下面我们来看一下该命令的使用:
$ sudo docker exec --help
接下来使用该命令进入一个已经在运行的容器
$ sudo docker ps
$ sudo docker exec -it 775c7c9ee1e1 /bin/bash
6、docker与物理机如何做映射
(1)通过设置容器级别的hostPort,将容器应用的端口号映射到物理机上。
建立Pod的yaml为:pod-hostport.yaml。需要注意,在yaml中不要使用tab,同时缩进会影响yaml中的数据结构,注意检查缩进。
备注: 当指定hostPort之后,同一台宿主机将无法启动该容器的第2份副本。
(2) 设置Pod级别的hostNetwork=true。
该Pod中所有容器的端口号都将直接被映射到物理机上。如果容器的ports定义部分如果不指定hostPort,则默认hostPort等于containerPort。否则,指定的hostPort必须等于containerPort的值。
7、Git
SVN与Git的最主要的区别?
SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以首先要从中央服务器哪里得到最新的版本,然后干活,干完后,需要把自己做完的活推送到中央服务器。集中式版本控制系统是必须联网才能工作,如果在局域网还可以,带宽够大,速度够快,如果在互联网下,如果网速慢的话,就没办法了。
Git是分布式版本控制系统,那么它就没有中央服务器的,每个人的电脑就是一个完整的版本库,这样,工作的时候就不需要联网了,因为版本都是在自己的电脑上。既然每个人的电脑都有一个完整的版本库,那多个人如何协作呢?比如说自己在电脑上改了文件A,其他人也在电脑上改了文件A,这时,你们两之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
Git下载代码
第一步:创建一个本地的版本库(即新建一个文件夹)
第二步:右键Git bash here进入控制面板,输入命令git init 初始化化文件夹,把这个文件夹变成Git可管理的仓库。
第三步:把gitee(码云)上的项目地址复过来,git clone “仓库地址”,点击回车。
基于远程的分支创建一个本地分支
(1)查看远程分支
使用如下git命令查看所有远程分支:
git branch -r
查看远程和本地所有分支:
git branch -a
查看本地分支:
git branch
在输出结果中,前面带* 的是当前分支。
(2)拉取远程分支并创建本地分支
方法一:
使用如下命令:
git checkout -b 本地分支名XXX origin/远程分支名XXX
使用该方式会在本地新建分支XXX,并自动切换到该本地分支XXX。
采用此种方法建立的本地分支会和远程分支建立映射关系。
方式二:
使用如下命令:
git fetch origin 远程分支名x:本地分支名x
使用该方式会在本地新建分支x,但是不会自动切换到该本地分支x,需要手动checkout。
采用此种方法建立的本地分支不会和远程分支建立映射关系。
(3)本地分支和远程分支建立映射关系的作用
建立本地分支与远程分支的映射关系(或者为跟踪关系track)。
这样使用git pull或者git push时就不必每次都要指定从远程的哪个分支拉取合并和推送到远程的哪个分支了。
git branch -vv
本地分支和远程分支都有映射关系,如果没有,就需要手动建立:
git branch -u origin/分支名,
或者
git branch --set-upstream-to origin/分支名
origin 为git地址的标志,可以建立当前分支与远程分支的映射关系。
撤销本地分支与远程分支的映射关系
git branch --unset-upstream
之后可以再次用git branch -vv 查看本地分支和远程分支映射关系
问题思考:本地分支只能跟踪远程的同名分支吗?
答案是否定的,本地分支可以与远程不同名的分支建立映射关系
操作和之前的一样,只是可以指定和本地分支名不同的远程分支名,然后使用git branch -vv 查看映射关系,可以发现建立映射成功。
8、Spring支持的隔离级别
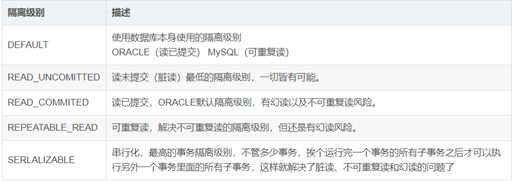
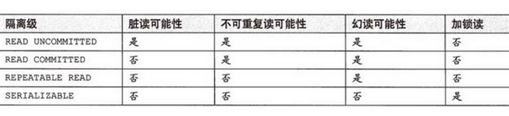
Spring建议使用DEFAULT,就是数据库本身的隔离级别,配置好数据库本身的隔离级别,无论在哪个框架中读写数据都不用担心了。
9、SpringBean的作用域
(1)singleton:单例模式(多线程下不安全)
单例模式。Spring IOC 容器中只会存在一个共享的Bean实例,无论有多少个Bean引用它,都指向同一个对象。该模式在多线程下是不安全的。Singleton作用域是spring中的缺省作用域,也可以显示的将Bean定义为单例模式,配置为
<bean id="userDao" class = "com.ioc.UserDaoImpl" scope="singleton" />
(2)prototype :原型模式每次使用时创建
原型模式,每次通过Spring容器获取prototype定义的bean时,容器都能创建一个新的Bean实例,每个Bean实例都有自己的属性和状态,而singleton对象全局只有一个对象。根据经验,对有状态的bean使用prototype作用域,而对无状态的bean使用singleton作用域。
(3)Request:一次request一个实例
request:在一次http请求中,容器会返回该Bean的同一实例。而对不同的Http请求则会产生新的Bean,而且该bean仅在当前的Http Request内有效,当前Http请求结束,该bean的实例也将会被销毁。
<bean id="loginAction" class="com.cnblogs.Login" scope="request" />
(4)session
session:在一次Http Session 中,容器会返回该Bean的同一实例。而对不同的Session请求则会创建新的实例,改bean实例仅在当前Session内有效。同Http 请求相同,每一次session请求创建新的实例,而不同的实例之间不共享属性,且实例仅在自己的session请求内有效,请求结束,则实例将被销毁。
<bean id="userPreference" class="com.ioc.UserPreference" scope="session"/>
(5)global Session
在一个全局的Http Session中,容器会返回该Bean的同一个实例,仅在使用portlet context 时有效。

SpringBean生命周期
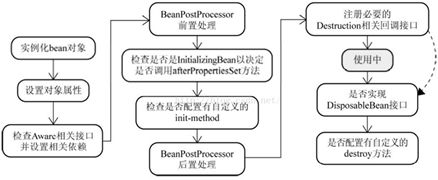
Bean实例生命周期的执行过程如下:
(1)Spring对bean进行实例化,默认bean是单例;
(2)Spring对bean进行依赖注入;
(3)如果bean实现了BeanNameAware接口,spring将bean的id传给setBeanName()方法;
(4)如果bean实现了BeanFactoryAware接口,spring将调用setBeanFactory方法,将BeanFactory实例传进来;
(5)如果bean实现了ApplicationContextAware接口,它的setApplicationContext()方法将被调用,将应用上下文的引用传入到bean中;
(6)如果bean实现了BeanPostProcessor接口,它的postProcessBeforeInitialization方法将被调用;
(7)如果bean实现了InitializingBean接口,spring将调用它的afterPropertiesSet接口方法,类似的如果bean使用了init-method属性声明了初始化方法,该方法也会被调用;
(8)如果bean实现了BeanPostProcessor接口,它的postProcessAfterInitialization接口方法将被调用;
(9)此时bean已经准备就绪,可以被应用程序使用了,他们将一直驻留在应用上下文中,直到该应用上下文被销毁;
(10)若bean实现了DisposableBean接口,spring将调用它的distroy()接口方法。同样的,如果bean使用了destroy-method属性声明了销毁方法,则该方法被调用;
10、shutdown关不了,查进程的命令,杀进程?
(1)ps 查看当前终端下的命令
(2)ps -aux 查看所有的进程(不是动态的)
(3)top 查看所有的进程(是动态的)
(4) kill -9 PID (绝杀)
(5) kill -9 PID (慢杀)
11、设计模式
创建型模式,共五种:
工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式
结构型模式,共七种:
适配器模式、装饰者模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:
策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
其实还有两类:并发型模式和线程池模式。
12、单例模式有几种?
单例模式的定义有饿汉式、懒汉式、懒汉式同步锁、双重校验锁、静态内部类、枚举这几种定义方式,每种方式都有他们优缺点,可以根据自己的需要去选择自己的定义方式。
(1)饿汉式
饿汉式是最简单的单例模式定义方法,首先我们需要将类的构造方法定义为private,这样在外部就不能通过构造函数生成对象;其次,我们需要定义一个静态的对象并用构造方法对其赋值;最后,提供一个public方法访问我们定义的静态对象。具体代码如下:
public class SingleTonOne {
private final static SingleTonOne singleTonOne = new SingleTonOne();
private SingleTonOne() {}
public static SingleTonOne getInstance() {
return singleTonOne;
}
}
优点:简单方便。
缺点:不管程序中是否使用到了单例对象,都会生成单例对象,并且由于静态对象是在类加载时就需要生成,会降低应用的启动速度。
适用:类对象功能简单,占用内存较小,使用频繁。
不适用:类对象功能复杂,占用内存大,使用概率较低。
(2)懒汉式
懒汉式相比于饿汉式,最大的区别在于静态对象的生成是在使用到单例实例的时候才去生成的,而不是在应用启动的时候构造,如果应用中没有使用到单例对象,是不会构造单例对象的。具体代码如下:
public class SingleTonTwo {
private static SingleTonTwo singleTonTwo = null;
private SingleTonTwo() {}
public static SingleTonTwo getInstance() {
if (singleTonTwo == null) { // 首次生成单例对象时,如果多个线程同时调用getInstance方法,这个条件针对多个线程同时成立,那么就会生成多个单例对象
singleTonTwo = new SingleTonTwo();
}
return singleTonTwo;
}
}
这种单例模式的定义使用的是懒加载的方式,即需要的时候才去构造单例对象,针对于单线程模式,这样定义是没有问题的,但是如果是多线程模式,就有可能构造多个单例对象,如果多个线程同时首次调用getInstance去获得单例对象,在判断单例对象是否为空时可能都会成立,那样就会构造多个单例对象,懒汉式的定义方式最大的问题就是它是线程不安全的。
优点:单例对象的生成是在应用需要使用单例对象时才去构造,可以提高应用的启动速度。
缺点:不是线程安全的,如果多个线程同时调用getInstance方法,那么可能会生成多个单例对象。
适用:单例对象功能复杂,占用内存大,对应用的启动速度有要求。
不适用:多线程同时使用。
(3)懒汉式同步锁
懒汉式单例模式的问题在于它是线程不安全的,那么如果我们加上线程保护机制,问题不就解决了吗?懒汉式同步锁就是在懒汉式上加上线程同步锁,已确保线程安全。具体代码如下:
public class SingleTonThree {
private static SingleTonThree singleTonThree = null;
private SingleTonThree() {
}
public static SingleTonThree getInstance() {
synchronized(SingleTonThree.class) { // 加上线程同步锁,确保每次只有一个线程进入
if (singleTonThree == null) {
singleTonThree = new SingleTonThree();
}
}
return singleTonThree;
}
}
(4)双重校验锁
用懒汉式同步锁可以解决线程安全问题,但是我们在获得单例对象时有必要每次都判断线程同步锁吗?如果单例对象已经不为空了,我们直接返回单例对象就行了,就不需要判断线程同步锁和构造单例对象了,双重校验锁是在懒汉式同步锁的基础上再加上一层单例对象是否为空的判断,以减少判断线程同步锁的次数,从而提高效率,代码如下:
public class SingleTonFour {
private volatile static SingleTonFour singleTonFour = null; // 加上volatile关键字,线程每次使用到被volatile关键字修饰的变量时,都会去堆里拿最新的数据
private SingleTonFour() {
}
public static SingleTonFour getInstance() {
if (singleTonFour == null) { // 在懒汉式同步锁的基础上加上了一个判断,如果单例对象不为空,就不需要执行获得对象同步锁的代码,从而提高效率
synchronized (SingleTonFour.class) { // 只有当单例对象为空时才会执行
if (singleTonFour == null) {
singleTonFour = new SingleTonFour();
}
}
}
return singleTonFour;
}
}
优点:懒加载、线程安全、效率高。
缺点:代码比较复杂。
(5)利用静态内部类
java的静态内部类的加载是在使用到该静态内部类的时候才去加载的,并且加载静态内部类是线程安全的,我们可以利用这一特性来定义单例模式,具体代码如下:
public class SingleTonFive {
/**
* 私有静态内部类,程序只有当使用到静态内部类是才会去加载静态内部类,然后生成单例对象
*/
private static class SingleTonFiveHolder {
public static SingleTonFive singleTonFive = new SingleTonFive();
}
private SingleTonFive() {
}
/**
* 只用调用了getInstance方法,程序中使用到了静态内部类SingleTonFiveHolder,才会去加载SingleTonFiveHolder,生成单例对象
* @return
*/
public SingleTonFive getInstance() {
return SingleTonFiveHolder.singleTonFive;
}
}
优点:实现简单,懒加载,线程安全。
缺点:增加了一个静态内部类,apk文件增大。
(6)枚举
package com.liunian.androidbasic.designpattern.singleton;
/**
* Created by dell on 2018/4/19.
* 枚举单例模式
* 优点:线程安全,不用担心序列化和反射问题
* 缺点:枚举占用的内存会多一点
*/
public enum SingleTonSix {
INSTANCE;
private String field;
public String getField() {
return field;
}
public void setField(String field) {
this.field = field;
}
}
优点:线程安全,不用担心序列化和反射问题。
缺点:枚举占用的内存会多一点。
13、JMM(Java的内存模型)
Java的内存模型
Java的内存模型简称JMM(Java Memory Model),是Java虚拟机所定义的一种抽象规范用来屏蔽不同硬件和操作系统的内存访问差异。让Java程序在各种平台下都能达到一致的内存访问效果。

主内存(Main Memory)
主内存可以简单理解为计算机当中的内存,但又不完全等同。
主内存被所有线程共享,对于一个共享变量(比如静态变量,或是堆内存中的实例)来说,主内存当中存储了它的"本尊"。
工作内存(Working Memory)
工作内存可以理解为计算机当中的CPU高速缓存,但又不完全等同。
每一个线程拥有自己的工作内存,对于一个共享变量来说,工作内存当中存储了它的"副本"。
线程对共享变量的所有操作都必须在工作内存中进行,不能直接读写主内存中的变量。
不同线程之间也无法访问彼此的工作内存,变量值的传递只能通过主内存来进行。
直接操作主内存太慢,所以JVM才不得不利用性能较高的工作内存。
这里类比一下:CPU、高速缓存、内存 之间的关系
工作内存所更新的变量并不会立即同步到主内存。
volatile关键字
具有许多特性,其中最重要的特性就是保证了用volatile修饰的变量对所有线程的可见性。
可见性是什么?
当一个线程修改了变量的值,新的值会立刻同步到主内存当中。
而其他线程读取这个变量的时候,也会从主内存中拉取最新的变量值。
为什么volatile关键字可以有这样的特性?
因为Java语言的先行发生原则(happens-before)。
Volatile对指令的重排序的影响
1)什么是指令重排序?
指令重排序是指: JVM在编译Java代码的时候,或者CPU在执行JVM字节码的时候,对现有的指令顺序进行重新排序。
2)指令重排序的目的?
目的:为了在不改变程序执行结果的前提下,优化程序的运行效率。
需要注意的是,这里所说的不改变执行结果,指的是单线程下的程序执行结果。
3)然而,指令重排序是一把双刃剑,虽然优化了程序的执行效率,但是在某些情况下,会影响到多线程的执行结果。
指令重排序解决方法?
1)什么是内存屏障?
内存屏障(Memory Barrier)是一种CPU指令。
内存屏障也称为内存栅栏或栅栏指令,是一种屏障指令,它使CPU或编译器对屏障指令之前和之后发出的内存操作执行一个排序约束。
这通常意味着在屏障之前发布的操作被保证在屏障之后发布的操作之前执行。
内存屏障共分为四种类型:
1) LoadLoad屏障:
抽象场景:Load1; LoadLoad; Load2
Load1 和 Load2 代表两条读取指令。在Load2要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
2)StoreStore屏障:
抽象场景:Store1; StoreStore; Store2
Store1 和 Store2代表两条写入指令。在Store2写入执行前,保证Store1的写入操作对其它处理器可见
3)LoadStore屏障:
抽象场景:Load1; LoadStore; Store2
在Store2被写入前,保证Load1要读取的数据被读取完毕。
4)StoreLoad屏障:
抽象场景:Store1; StoreLoad; Load2
在Load2读取操作执行前,保证Store1的写入对所有处理器可见。StoreLoad屏障的开销是四种屏障中最大的。
总结
Volatile特性一:
保证变量在多线程之间的可见性。
可见性的保证是基于CPU的内存屏障指令,被JSR-133抽象为happens-before原则。
Volatile特性二:
阻止编译时和运行时的指令重排。
编译时JVM编译器遵循内存屏障的约束。
运行时依靠CPU屏障指令来阻止重排。
14、java的hashcode如何产生的?
public int hashCode() {
int h= hash;
if (h== 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
关于为什么取31为权?
原因一:主要是因为31是一个奇质数,所以31 * I = 32 * II =(I << 5)-i,这种位移与减法结合的计算相比一般的运算快很多。
原因二:值31被选择,因为它是一个奇数的素数如果它是偶数,并且倍增溢出,则信息将会丢失,因为乘以2移位相当于使用素数的好处不太清楚,但是是传统的.31的一个很好的特性是乘法可以被一个移位和一个减法取代以获得更好的性能:31 * i ==(i << 5) - i。现代虚拟机自动进行这种优化。
15、MySQL常用函数
聚合函数
在数据库函数中,聚合函数是我们最常用的一类。所谓的聚合,就是对一组值进行组合计算,返回单个值。
(1)count
计数函数,对元组或者属性计数。
一般格式:count(属性名)。
select count() from <表名>;
是对整个表的元组进行计数
select count(属性名) from 表名 where 条件表达式;
count 支持条件计数,只计算有效值,不计算null值。
(2)max
求最大值函数,查询字段中的最大的数。
一般格式:max(属性名)
select max(属性名) from 表名 [where 条件表达式];
(3)min
求最小值函数,查询字段中的最小的数。
一般格式:min(属性名)
select min(属性名) from 表名 [where 条件表达式];
(4)avg
求平均值函数,查询字段中所有数的平均值。
一般格式:avg(属性名)
select avg(属性名) from 表名 [where 条件表达式];
(5)sum
求和函数,查询属性中所有数的和。
一般格式:sum(属性名)
select sum(属性名) from 表名 [where 条件表达式];
除了通过函数计算还能直接用运算符计算
select 属性名1*2,属性名2+属性名3 from 表名;
数学函数
(1)abs
返回X的绝对值
格式: abs(x)
select abs(-10),abs(12);
(2)round
四舍五入函数。
一般格式:round(数值类型[,精确位数]);
select round(1234.56);
不加精确位数默认精确到整数位
select round(123.456,2);
加上精确位数就保留多少位小数。
(3)MOD
mod(a,b) a除以b的余数
(4)rand
获取随机数,随机数的范围在0~1之间,生成小于1的浮点小数
生成范围在0~9之间的数据。
select rand()*10;
格式: rand()
三角函数
三角函数中的 正弦 函数
sin30度shi 2/1
格式: sin(radin)
注意: radin 是弧度制,而不是角度
弧度转角度公式
#PI == 180
radin=PI/180*angle;
除此之外还有其他的三角函数
cos(radin) 余弦
tan(radin) 正切
ctan(radin) 余切
(1)PI
数据库提供了直接获取 PI 值的函数
PI() 求圆周率
(2)power
求次方函数
一般格式:power(底数,指数);
select power(2,3); # 求2的3次方的值
可以用pow函数代替power函数
select pow(2,3);
求次方根(开方)
pow(9,1/2); pow(4,0.5) #只需要把指数改一下
日期时间函数
直接从系统获取日期和时间,不需要通过表格获取。
(1)now
求当前的日期和时间。
一般格式:now()。
select now();
返回一个 datetime 类型的数据。
(2)date
求出日期的格式的函数
一般格式:date(日期时间类型的属性名)。
select date(birthday) from student;
(3)time
求时间函数的格式的函数。
一般格式:time(日期时间类型的属性名)
select time(birthday) from student;
(4)date_format
时间日期类型转字符串类型函数。
一般格式: date_format(日期时间类型,格式字符串)
/*
%Y 年 %y 年(保留后2位)
%M 月份英文单词 %m 数字月份
%d 日期 #D 数字th
%H 时(24小时制) %h 12时制
%i 分
%s 秒
*/
select date_format(now(),'%Y%m%d:%H%i%s');
注意:大小写格式会有不一样的输出
字符处理函数
(1)upper
小写字母转大写字母函数。
一般格式:upper(字符型属性名);
select upper('abc');
也可用 ucase() 函数代替 select ucase(‘abc’);
(2)lower
大写字母转小写字母函数。
一般格式:lower(字符型属性名);
select upper('ABC');
也可用 lcase 函数代替,如: select lcase(‘ABC’);
(3)substring
提取字串函数,以给定的参数求字符串中的一个子串。
mysql 中,字符串数据下标从1开始
格式: substring(字符串,start,length);
## 要被提取的字符串
## start 开始提取的位置
## end 提取的数量
subsring("string",start,end);
从字符串中第start个字符开始取出长度为length的字符串。
select substring('abc123@#$',4,3);# 结果为123
也可以用mid函数代替,如: select mid(‘abc123@#$’,4,3);
(4)concat
字符串拼接函数
格式: concat(字符串,字符串…)
char_length() 求字符串长度
(5)insert
字符串 string2 替换 string1 的 x 位置开始长度为 len 的字符串
/*
string1 准备替换的字符串
x 开始位置
len 替换的长度 如果是0,就是从该位置进行插入
string2 替换的字符串
*/
insert(string1,x,len,string2)
(6)locate
从字符串 s 中获取 s1 的开始位置
locate(substr,str) :返回子串 substr 在字符串 str 第一个出现的位置,如果 substr 不是在 str`里面,返回0。
locate(s1,s)
(7)length
length(string) :返回字符串 string 的长度。
(8)ASCII
ASCII( str )
返回字符串 str 字符中的ASCII代码值。如果 str 是空字符串,返回0。
如果 str 是NULL,返回NULL。
select ASCII('a');
注意:只能显示一个字符的 ASCII 码值.
高级函数
(1)md5
不可逆的加密验证函数。
(2)bin
bin(x) 返回二进制编码。
(3)binary
binary(s) 将字符串 s 转换为二进制字符串。
(4)database
返回当前数据库名
分组查询
对查询结果进行分组。
分组关键字:group by
一般格式:
select 属性名1,属性名2,…,属性名n
from 表名 group by 属性名(1~n) [having 条件表达式];
注意:分组过后不能用where进行条件筛选,需要用having
where:从数据源去掉不符合搜索条件的数据。
having:在分好的组中去掉每组不符合条件的数据。
其他函数
FIND_IN_SET(str,strlist)
返回str在字符串集strlist中的序号(任何参数是NULL则返回NULL,如果str没找到返回0,参数1包含","时工作异常)。