java面试题收集(16)
1、SpringBean的作用域
singleton:单例模式
当spring创建applicationContext容器的时候,spring会欲初始化所有的该作用域实例,加上lazy-init就可以避免预处理。
prototype:原型模式
每次通过getBean获取该bean就会新产生一个实例,创建后spring将不再对其管理。
request:请求模式
每次请求都新产生一个实例,和prototype不同就是创建后,接下来的管理,spring依然在监听。
session:会话模式
每次会话都新产生一个实例,和prototype不同就是创建后,接下来的管理,spring依然在监听。
global session:全局模式
全局的web域,与servlet中的application类似。
2、接口和抽象类的区别
不同之处:
抽象类:
(1)抽象类中可以定义构造器。
(2)可以有抽象方法和具体方法。
(3)接口中的成员全都是public的。
(4)抽象类中可以定义成员变量。
(5)有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法。
(6)抽象类中可以包含静态方法。
(7)一个类只能继承一个抽象类。
接口:
(1)接口中不能定义构造器。
(2)方法全部默认都是抽象方法,接口中的变量默认也必须是public static final。
(3)抽象类中的成员可以是private、默认、protected、public。
(4)接口中定义的成员变量实际上都是常量。
(5)接口中不能有静态方法。
(6)一个类可以实现多个接口。
相同之处:
(1)不能够实例化。
(2)可以将抽象类和接口类型作为引用类型。
(3)一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要被声明为抽象类。
3.Rest和RPC对比
RPC最主要的缺陷就是服务提供方和调用方式之间依赖太强,我们需要为每一个微服务进行接口的定义,并通过持续继承发布,需要严格的版本控制才不会出现服务提供和调用之间因为版本不同而产生的冲突。
REST是轻量级的接口,服务的提供和调用不存在代码之间的耦合,只是通过一个约定进行规范,但也有可能出现文档和接口不一致而导致的服务集成问题,但可以通过swagger工具整合,是代码和文档一体化解决,所以REST在分布式环境下比RPC更加灵活。
4、DELETE、TRUNCATE、DROP的区别
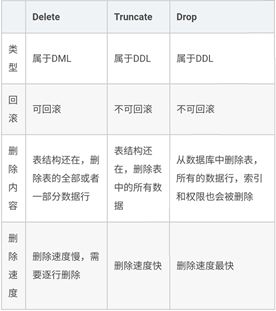
因此,在不再需要一张表的时候,用drop;在想删除部分数据行时候,用delete;在保留表而删除所有数据的时候用truncate。
5、Arraylist与Linkedlist 分析
Arraylist
底层是基于动态数组。
根据下标访问数组元素的效率高,向尾部添加元素的效率高。
删除数组中元素以及向数组中间添加数据的效率低,因为需要移动数组最坏情况是删除第一个元素,那就要把第2-第n个元素都往前移动一位。
之所以称之为动态数组,是因为Arraylist在数组容量超过上限后可以扩容(JDK1.8之后数组扩容后是之前的1.5倍)Arraylist源码中最大的数组容量是Integer.MAX_VALUE-8,对于空出的8位,目前解释是:
1)存储Headerwords。
2)避免一些机器内存溢出,减少出错几率,所以少分配。
3)最大还是能支持到Integer.MAX_VALUE(当Integer.MAX_VALUE-8依旧无法满足需求时)。
Linkedlist
Linkedlist基于链表的动态数组数据添加删除效率高,只需要改变指针指向即可,但是访问数据的平均效率低,需要对链表进行遍历。
总结
(1)对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
(2)各自效率问题:
ArrayList是线性表(数组)
get()直接读取第几个下标,复杂度O(1)。
add(E)添加元素,直接在后面添加,复杂度O(1)。
add(index,E)添加元素,在第几个元素后面插入,后面的元素需要向后移动,复杂度O(n)。
remove()删除元素,后面的元素需要逐个移动,复杂度O(n)。
LinkedList是链表的操作
get()获取第几个元素,依次遍历,复杂度O(n)。
add(E)添加到未尾,复杂度O(1)。
add(index,E)添加第几个元素后,需要先查找到第几个元素,直接指针指向操作,复杂度O(n)。
remove()删除元素,直接指针指向操作,复杂度O(1)。
6、集合默认容量与扩容机制分析
(1)ArrayList
默认容量:10。
扩容机制:当发现容量不足时扩容,容量为原来的1.5倍+1。
(2)LinkedList
默认容量:0。
扩容机制:无。
(3)Vector
默认容量:10。
扩容机制:当发现容量不足时,扩容到原来的两倍。
(4)HashSet
默认容量:16。
扩容机制:加载因子为0.75,当超过这个阈值时扩容,扩容到原来的两倍。它的子链表达到8时,转化成红黑树。小于6个转化成链表。
(5)HashMap
默认容量:16。
扩容机制:加载因子为0.75,当超过这个阈值时扩容,扩容到原来的两倍。它的子链表达到8时,转化成红黑树。小于6个转化成链表。
(6)Hashtable
默认容量:11。
扩容机制:加载因子为0.75,当超过这个阈值时扩容,扩容为2*原数组长度+1。
7、Hystrix隔离机制
线程池隔离
优点:
1)支持排队和超时。
2)支持异步调用。
缺点:
线程调用会产生额外的开销。
适用场景:
1)不受信客户。
2)有限扇出。
信号量隔离
优点:
1)轻量。
2)无额外开销。
缺点:
1)不支持任务排队和主动超时。
2)不支持异步调用。
适用场景:
1)受信客户。
2)高扇出(网关)。
3)高频高速调用(cache)。
8、一条select语句执行流程图

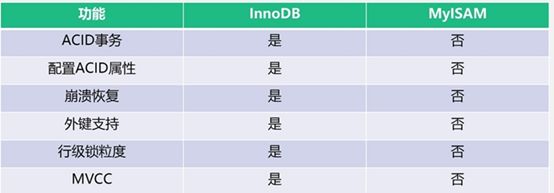
9、InnoDB与MyISAM功能对比
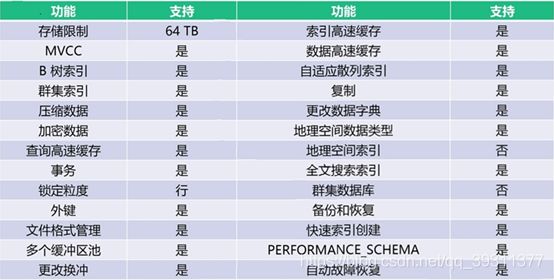
10、InnoDB特性
11、多版本并发控制原理(MVCC)
(1)InnoDB存储引擎,实现的是基于多版本的并发控制协议MVCC。
(2)MVCC最大的好处是读不加锁,读写不冲突。
(3)现阶段几乎所有的RDBMS,都支持MVCC。
(4)在MVCC并发控制中,读操作可分两类:快照读(snapshot read)与当前读(currentread)。
注意:MVCC只在READ COMMITED和REPEATABLE READ两个隔离级别下工作。
12、MySQL锁分类
表级锁
(1) 开销小,加锁快。
(2) 不会出现死锁。
(3) 粒度大,锁冲突概率最高,并发度最低。
行级锁
(1) 开销大,加锁慢。
(2) 会出现死锁。
(3) 粒度最小,锁冲突概率最低,并发度最高。
页级锁
(1) 开销和加锁时间界于表锁和行锁之间。
(2) 会出现死锁。
(3) 粒度界于表锁和行锁之间,并发度一般。
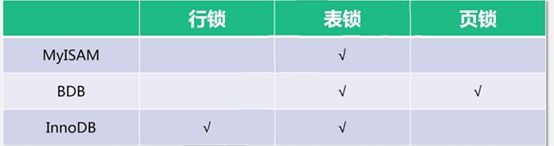
13、InnoDB锁分类/模式
行锁
(1)共享锁(s)。
(2)排他锁(x)。
表锁
(1)意向共享锁(IS)。
(2)意向排他锁(IX)。
(3)自增锁(AUTO-INC Locks)。
14、MySQL执行计划分析“三步曲”
第一步:查看SQL执行计划
(1)explain SQL。
(2)desc 表名;或者show create table表名\G。
第二步:通过Profile定位QUERY代价消耗
(1)set profiling=1。
(2)执行SQL。
(3)show profiles;获取Query_ID。
(4)show profile for query Query_ID;查看详细的profile信息。
第三步:SQL Optimizer Trace
(1)set session optimizer_trace=‘enabled=on’。
(2)执行SQL。
(3)查询information_schema.optimizer_trace表,获取SQL查询计划树。
(3)set session optimizer_trace=‘enabled=off’;开启此项影响性能,记得用后关闭。
15、MySQL复制原理
