Linux内存管理(九): 页面回收
kernel: 5.10
Arch: aarch64
页面回收
系统在运行一段时间后,内存逐渐的被分配过去, 空闲内存会越来越少,为了保证之后的程序有足够的内存可用, linux 内核会通过“page reclaim”机制 回收一部分页面。
页面回收主要需要搞清楚三个问题:
- 什么样的页面会被回收?
- 什么时候进行页面回收?
- 怎样进行页面回收?
什么样的页面会被回收?
属于内核的大部分页框是不能回收的,包括内核栈,内核的代码段,内核数据段等,kernel主要对进程使用的内存页进行回收。

如上图所示,进程的使用的内存主要包括:
- 进程堆、栈、数据段使用的匿名页: 存放到swap分区中
- 进程代码段映射的可执行文件的文件页: 直接释放
- 打开文件进行读写使用的文件页: 如果页中数据与文件数据不一致,则进行回写到磁盘对应文件中,如果一致,则直接释放
- 进行文件映射mmap共享内存时使用的页: 如果页中数据与文件数据不一致,则进行回写到磁盘对应文件中,如果一致,则直接释放
- 进行匿名mmap共享内存时使用的页: 存放到swap分区中
- 进行shmem共享内存时使用的页:存放到swap分区中
可以看出, 内存回收的时候,会筛选出一些不经常使用的文件页或匿名页,针对上述不同的内存页,有两种处理方式:
- 直接释放。 如进程代码段的页, 这些页是只读的;干净的文件页(文件页中保存的内容与磁盘中文件对应内容一致)
- 将页回写后再释放。匿名页直接将它们写入到swap分区中;脏页(文件页保存的数据与磁盘中文件对应的数据不一致)需要先将此文件页回写到磁盘中对应数据所在位置上
由此可见,如果系统没有配置swap分区,那么只有文件页能被回收.
什么时候进行页面回收?
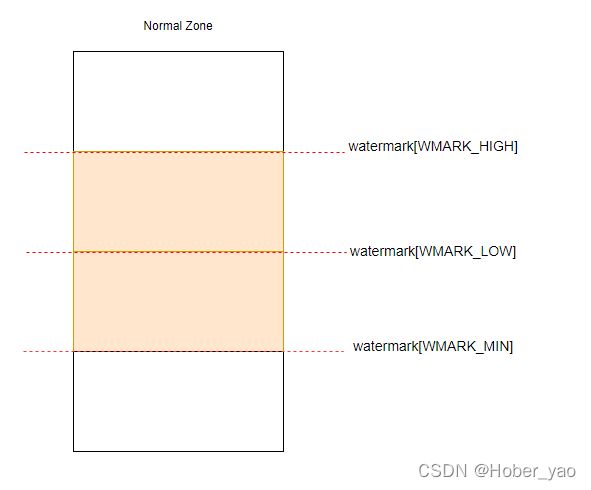
watermark水位
页面回收是以zone为单位进行的,系统根据watermark来判断一个zone需不需要进行内存回收。当分配内存时发现水位不满足要求时就会触发内存回收。
每个zone有三条水位线
[include/linux/mmzone.h]
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
再看下内存分配的流程,在之前的文章【Linux内存管理(六): 分配物理内存alloc_pages】中曾经提到过,内核分配内存页有两条路径:快速路径和慢速路径; get_page_from_freelist()函数是快速分配路径的入口, __alloc_pages_slowpath()函数是慢速分配路径的入口。
两个路径都会触发内存的回收。
流程图如下:

- 快速路径: 通过
zone_watermark_fast函数比较内存和zone的high/low/min 水位,判断内存是否不足。如果内存不足,则会触发内存回收node_reclaim() - 慢速路径: 快速路径分配失败后,则进入慢速路径。
- 内存节点中的内存空闲页面低于low watermark时,kswapd内核线程被唤醒,进行
异步回收; - 在内存分配的时候,遇到内存不足,空闲页面低于min watermark时,
直接进行回收;
- 内存节点中的内存空闲页面低于low watermark时,kswapd内核线程被唤醒,进行
接下来着重对内存分配流程中出现的node_reclaim(), 直接内存回收__alloc_pages_direct_reclaim(), 异步回收kswapd以及内存回收流程真正的主角shrink_node()展开分析。
怎样进行页面回收?
直接内存回收
-
_perform_reclaim
__alloc_pages_direct_reclaim()函数调用_perform_reclaim()来对页面进行回收处理。
static unsigned long
__perform_reclaim(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac)
{
unsigned int noreclaim_flag;
unsigned long pflags, progress;
cond_resched();
/* We now go into synchronous reclaim */
cpuset_memory_pressure_bump();
psi_memstall_enter(&pflags);
fs_reclaim_acquire(gfp_mask);
noreclaim_flag = memalloc_noreclaim_save();
progress = try_to_free_pages(ac->zonelist, order, gfp_mask,
ac->nodemask);
memalloc_noreclaim_restore(noreclaim_flag);
fs_reclaim_release(gfp_mask);
psi_memstall_leave(&pflags);
cond_resched();
return progress;
}
cpuset_memory_pressure_bump()函数表示如果设置了cpuset_memory_pressure_enabled,则先更新当前任务的cpuset频率表fmeter;psi_memstall_enter()和psi_memstall_leave()函数配对使用, 用于记录memory stall 的信息。fs_reclaim_acquire()和fs_reclaim_release()函数配对使用 ,是保护页面回收的所操作。memalloc_noreclaim_save()将当前任务的标志置上PF_MEMALLOC, 该标志位表示允许该函数使用系统的预留内存,不需要使用考虑zone水位问题;memalloc_noreclaim_restore()再删除该标志位
-
try_to_free_pages
try_to_free_pages()函数主要有3个操作。
(1)初始化页面回收主要的数据结构: struct scan_control
struct scan_control {
unsigned long nr_to_reclaim; // 要回收的页面数量
nodemask_t *nodemask; // 内存节点掩码
unsigned int may_writepage:1; // 是否允许把修改过文件页写回存储设备;
unsigned int may_unmap:1; // 是否允许取消页面的映射并进行回收处理;
unsigned int may_swap:1; // 是否允许写入swap分区来回收页面
s8 order; // 页面分配的数量
s8 priority; // 页面扫描粒度
s8 reclaim_idx; // 最高允许页面回收的zone
gfp_t gfp_mask; // 内存分配掩码
unsigned long nr_scanned; // 扫描不活跃页面的数量
unsigned long nr_reclaimed; // 已经回收页面的数量
struct {
unsigned int dirty; // 统计脏页数量
unsigned int unqueued_dirty; // 统计没有在块设备I/O上排队等待回写的页面数量
unsigned int congested; // 表示这个页面正在块设备I/O上进行数据回写。 这是一个可能导致阻塞的源。
unsigned int writeback; // 统计正在回写的页面数量
unsigned int immediate; // 让改页面等待一段时间
unsigned int file_taken; // 分离的文件页面数量
unsigned int taken; // 分离的页面数量
} nr;
。。。
};
(2) 调用throttle_direct_reclaim函数进行判断,该函数会对用户任务的直接回收请求进行限制;
(3) 调用do_try_to_free_pages 进行回收处理;
kswapd内核线程
kswapd_init() -> kswapd_run()
int kswapd_run(int nid)
{
pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);
...
}
系统的每个NUMA节点都会创建一个 “kswapd%d” 的内核线程。该线程在当空闲页面低于low watermark时会被唤醒,进行页面回收处理。
注重讲下kswapd() -> blance_pgdat() 函数。
static int balance_pgdat(pg_data_t *pgdat, int order, int highest_zoneidx)
{
。。。
restart:
sc.priority = DEF_PRIORITY; ---------- (1)
do {
。。。
balanced = pgdat_balanced(pgdat, sc.order, highest_zoneidx); ------- (2)
if (!balanced && nr_boost_reclaim) {
nr_boost_reclaim = 0;
goto restart;
}
if (!nr_boost_reclaim && balanced) ----------- (3)
goto out;
age_active_anon(pgdat, &sc); ------------ (4)
if (kswapd_shrink_node(pgdat, &sc)) --------- (5)
raise_priority = false;
if (raise_priority || !nr_reclaimed)
sc.priority--; ------------ (6)
} while (sc.priority >= 1);
out:
/* If reclaim was boosted, account for the reclaim done in this pass */
if (boosted) {
wakeup_kcompactd(pgdat, pageblock_order, highest_zoneidx); ----(7)
}
return sc.order;
}
对该函数进行概略分析。
(1)sc.priority用于表示页面扫描粒度或者优先级。
(2)通过pgdat_balanced() 检查内存节点是否平衡 (即该节点中存在zone的水位要高于high watermark并且可以分配出2的sc.order次幂个连续的物理页面)。
(3)如果有符合要求的zone, 那么就不会去进行内存回收,直接跳转到out lable; 如果没有符合要求的zone并且需要boost_reclaim, 那么会重新跳转到restart标签, 并且关闭boost_reclaim(boost reclaim从linux 5.0引入, 主要用于内存外碎片化的优化)
水位;
(4) age_active_anon() 扫描匿名页的活跃LRU链表。
每一个NUMA node都会维护一个lrvvec结构, 该结构用于存放5种不同类型的LRU链表,在内存进行回收时,在LRU链表中检索最少使用的页面进行处理。
/* 5种不同类型的LRU链表 */
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE, // 不活跃匿名页面链表
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE, // 活跃匿名页面链表
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE, // 不活跃文件映射页面链表
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE, // 活跃文件映射页面链表
LRU_UNEVICTABLE, // 不可回收页面链表
NR_LRU_LISTS
};
(5)kswapd_shrink_node() 函数是kswapd页面回收的核心函数, 最终调用到shrink_node()进行页面回收
(6) 加大扫描粒度。priority表示我们会扫描LRU链表所有页面中的(LRU页面数量 >> priotity)个页面, priority越小,扫面页面的数量越大。
(7) 如果设置了boost_reclaim, 则唤醒kcompactd线程。
shrink_node
static void shrink_node(pg_data_t *pgdat, struct scan_control *sc)
{
...
again:
shrink_node_memcgs(pgdat, sc); ------- (1)
vmpressure(sc->gfp_mask, sc->target_mem_cgroup, true,
sc->nr_scanned - nr_scanned,
sc->nr_reclaimed - nr_reclaimed); ------- (2)
if (current_is_kswapd()) { ------- (3)
if (sc->nr.writeback && sc->nr.writeback == sc->nr.taken)
set_bit(PGDAT_WRITEBACK, &pgdat->flags);
if (sc->nr.unqueued_dirty == sc->nr.file_taken)
set_bit(PGDAT_DIRTY, &pgdat->flags);
if (sc->nr.immediate)
congestion_wait(BLK_RW_ASYNC, HZ/10);
}
if ((current_is_kswapd() ||
(cgroup_reclaim(sc) && writeback_throttling_sane(sc))) &&
sc->nr.dirty && sc->nr.dirty == sc->nr.congested)
set_bit(LRUVEC_CONGESTED, &target_lruvec->flags);
if (!current_is_kswapd() && current_may_throttle() &&
!sc->hibernation_mode &&
test_bit(LRUVEC_CONGESTED, &target_lruvec->flags))
wait_iff_congested(BLK_RW_ASYNC, HZ/10);
if (should_continue_reclaim(pgdat, sc->nr_reclaimed - nr_reclaimed,
sc)) ----- (4)
goto again;
...
}
(1) shrink_node_memcgs() 会进行页面的扫描和回收。
(2) 使用vmpressure来记录页面回收的效率
(3) 如果当前页面回收者是kswapd, 则需要判断
- 如果当前系统回写的页面数量等于这一轮页面扫描的数量, 说明系统有大量的回写页面, 需要设置WRITEBACK标志位
- 如果系统当前还没有回写的脏页数量等于这一轮页面扫描的数量, 说明有大量脏页, 需要设置DIRTY标志位。
- 如果当前系统的脏页数量等于正在块设备I/0上进行回写数据的页面数量, 说明系统有大量页面堵塞在块设备的I/O操作上,需要设置CONGESTED标志位
- 如果统计有immediate个页面, 说明有大量页面在等待回写, 调用congestion_wait 函数来让页面等待100ms
(4) should_continue_reclaim 会判断是否需要继续进行页面回收。
扩展下shrink_node_memcgs
shrink_node_memcgs
+->shrink_zone-----------------------------扫描zone中所有可回收的页面
+-> shrink_lruvec-------------------------扫描LRU链表的核心函数
+->shrink_list-------------------------处理各种LRU链表
+-> shrink_active_list----------------查看哪些活跃页面可以迁移到不活跃页面链表中
+->isolate_lru_pages---------------从LRU链表中分离页面
+->shrink_inactive_list--------------扫描inactive LRU链表尝试回收页面,并且返回已经回收页面的数量。
+->shrink_page_list----------------扫描page_list链表的页面并返回已回收的页面数量
+->shrink_slab---------------------------调用内存管理系统中的shrinker接口来回收内存
shrink_lruvec函数中会调用get_scan_count()计算每个lru链表需要扫描的页框数量,保存到nr数组中。 并且会获取swap分区的活跃状态swappiness, 此值较低时,那么就更多的进行文件页的回收,此值较高时,则更多进行匿名页的回收.
shrik_list() 函数会根据传入lru链表的类型调用不同的函数来处理对应链表:
shrink_active_list() 函数扫描活跃页面,看看有哪些活跃页面可以迁移到不活跃页面链表中;shrink_inactive_list() 函数扫描不活跃页面链表并且回收页面。
小结
通过对页面回收的分析, 我们可以知道哪些页面可以被回收, 了解页面回收的触发时机,以及初步浏览页面回收的算法LRU,以及页面回收的主要操作, 即: 一.直接将一些页释放。二.将页回写保存到磁盘,然后再释放。