应用层协议——http

文章目录
- 1. HTTP协议
-
- 1.1 认识URL
- 1.2 urlencode和urldecode
- 1.3 HTTP协议格式
-
- 1.3.1 HTTP请求
- 1.3.2 HTTP响应
- 1.3.3 外网测试
- 1.3.4 添加html文件
- 1.3.5 HTTP常见Header
- 1.3.6 GET和POST
- 1.4 HTTP的状态码
-
- 1.4.1 301和302
- 1.4.2 代码实现
- 1.5 Cookie
-
- 1.5.1 代码验证
- 1.5.2 Cookie+session
- 1.6 Connection
1. HTTP协议
虽然我们说,应用层协议是我们自己定的,但实际上,已经有一些现成的,又非常好用的应用层协议,供我们直接参考使用。HTTP(超文本传输协议)就是其中之一。
1.1 认识URL
平时我们俗称的 “网址” 其实就是说的 URL:

这里的登录信息现在已经隐藏起来,改成例如手机登录、微信登录等方式。
这里服务器地址也叫做域名会被转换成IP,并且访问网络服务,服务端必须具有端口号。因为网络通信的本质:IP+prot。但是使用确定协议的时候,一般会缺省端口号。所以,浏览器访问指定的URL的时候,浏览器必须给我们自动添加prot。
那么浏览器是如何得知,URL匹配的prot是哪个呢?
特定的众所周知服务,端口号是确定的。http对应的是80,https对应的是443,sshd对应的是22。
那么http是做什么的呢?
像我们查看图片,观看视频,其实都是以网页的形式呈现的,也就是.html文件,既然是文件,那么客户端想要观看视频时就是发送请求到服务器,然后服务器就会打开文件再给客户端发送过来。
那么http就是向特定的服务器申请特定的"资源",获取到本地,进行展示或使用。
那么资源文件在LInux服务器上,我们要打开,读取,发送给客户端,前提是要找到这个文件,找一个文件靠的就是路径,所以在URL中包含了路径。/就是Linux下的路径分隔符。
1.2 urlencode和urldecode
像 / ? : 等这样的字符,已经被url当做特殊意义理解了,因此这些字符不能随意出现。比如:某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
比如:

这里"+" 被转义成了 “%2B”。
1.3 HTTP协议格式
1.3.1 HTTP请求

请求行里对应的是:请求方法 资源路径 http的版本
请求报头对应的是:key:空格value
读到空行就代表前面的请求行和请求报头都读取完了。
1.3.2 HTTP响应

响应和请求一样是4个结构。
1.3.3 外网测试
如果我们想让浏览器去访问我们的云服务器,我们要先开放我们的端口,这里每个服务器开放我们的端口不一样,大家需要自己去上网搜索一下。
首先,这里只有服务器的编译,没有客户端。

这里服务器也是简单的多进程版本,我们让孙子进程去执行这个服务。

执行的服务是先把对方的请求信息打印出来,然后再做出响应。

当我们在浏览器链接这个IP时,可以看到浏览器上打印出我们的有效载荷。然后服务器也收到了对应的请求信息。

下面我们继续测试:

先让服务器起来。

这里我们安装了telnet命令,它是远程按照某种协议去登录。只要显示’^]'就代表我们登录成功了,然后Ctrl+]:

然后再回车一下,就可以发送我们的请求。

1.3.4 添加html文件
我们创建一个wwwroot文件夹来保存我们网页的信息。
这里就保存我们网页的首页信息。那么我们如何把这个文件读取出来,并添加相应的报头信息呢?
那么第一个问题就是:文件在哪里?
在前面的演示中,我们知道在请求的请求行中,第二个字段就是你要访问的文件路径。

但是这里的第一个/不是根目录,它是web根目录,但是可以设置成根目录。
那么如果我们不想把/a设置成根目录,我们可以在前面加上前缀:
path = "/a/b/index.html";
recource = "./wwwroot"; // 我们的web根目录
recource += path; // ./wwwroot/a/b/index.html
下面我们就写一个获取请求行文件路径的方法:
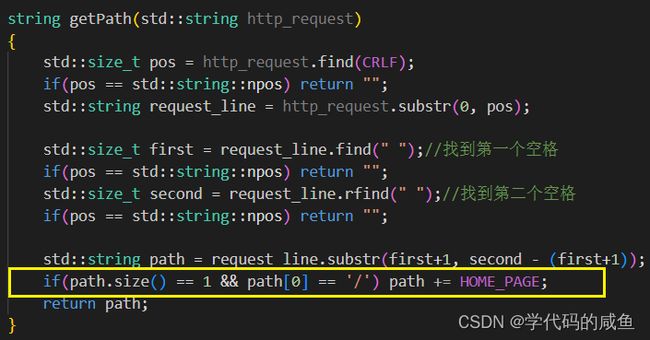
如果请求的只有一个/,说明访问的就是web根目录,难道需要把web根目录下的所有文件都返回,这是不可能的,所以我们把首页信息返回。

获取到文件路径后,我们需要把web根目录添加上:
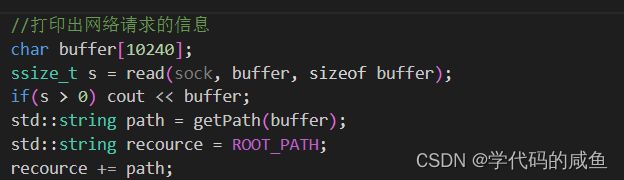
添加完成之后,我们就可以打开文件并去读取。

读取之后,返回。

顺便,我们记录一下文件的类型。

在这里我们可以添加报头:内容的类型和内容的长度。
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件。
如果文件里的后缀不是.jpg类型,我们就把Content-Type设置成text/html : HTML格式(HTML是一种纯文本格式的文件,内部只能书写文字内容,不能添加图片、音频、视频)。
如果文件里的后缀是.jpg类型,我们就把Content-Type设置成image/jpeg :jpg图片格式(“JPG是JPEG格式文件,JPEG格式是最常用的图像文件格式,后缀名为“.jpg”或“.jpeg”)。
测试结果:
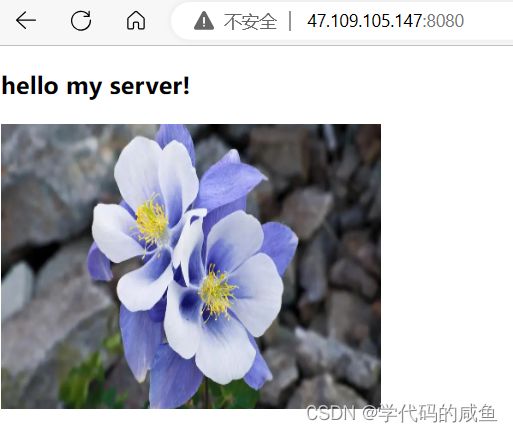
1.3.5 HTTP常见Header
Content-Type: 数据类型(text/html等)。
Content-Length: Body的长度。
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上。
User-Agent: 声明用户的操作系统和浏览器版本信息。
referer: 当前页面是从哪个页面跳转过来的。
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问。
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
1.3.6 GET和POST
网络行为无非两种:
1.把远端的资源拿到本地,采用的是GET方法。
2.把我们的属性字段提交到远端,采用的是GET方法或者POST方法。
下面我们就试着把我们的属性字段提交到远端:
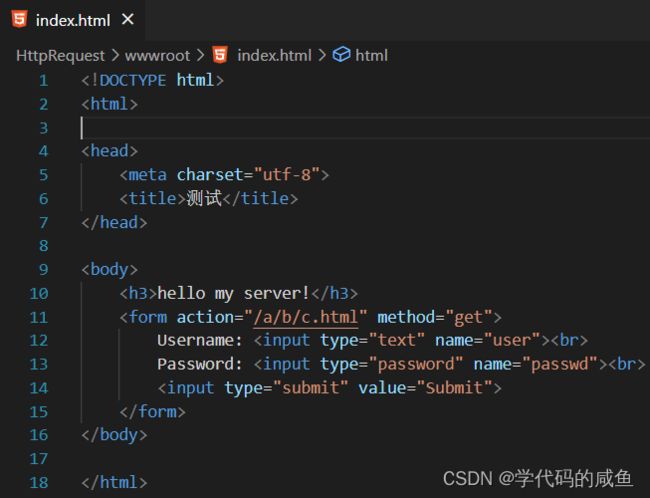
我们在这里创建了一个表单,action属性规定当提交表单时,向何处发送表单数据。 method属性是规定如何发送表单数据(表单数据发送到action属性所规定的页面)。
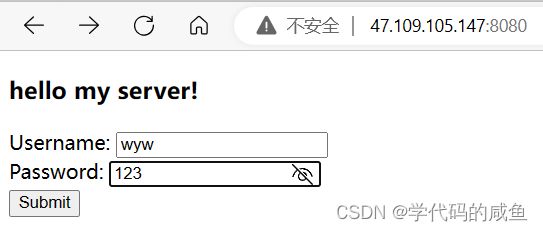
然后我们点击按钮,就会出现404,因为我们找不到/a/b/c.html,所以就报错404:

下面我们看一下它的抓包情况:

从上图可以看出:在HTTP中,GET方法会以明文方式将我们对应的参数信息拼接到URL中。
下面我们再看一下POST方法:
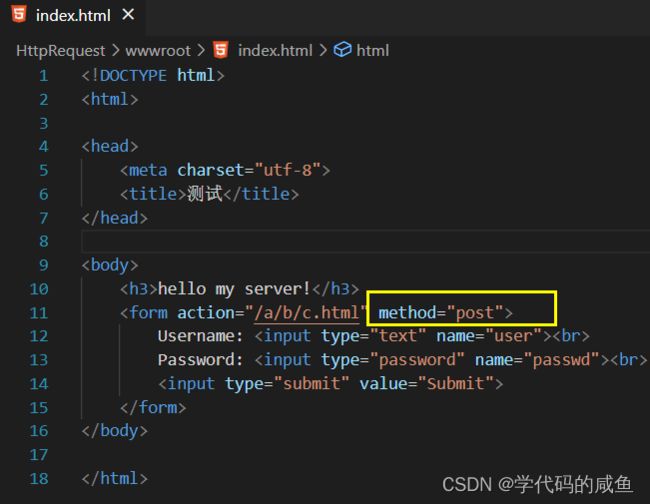
测试输入:

可以看到URL中,没有我们的参数信息。
看一下它的抓包情况:
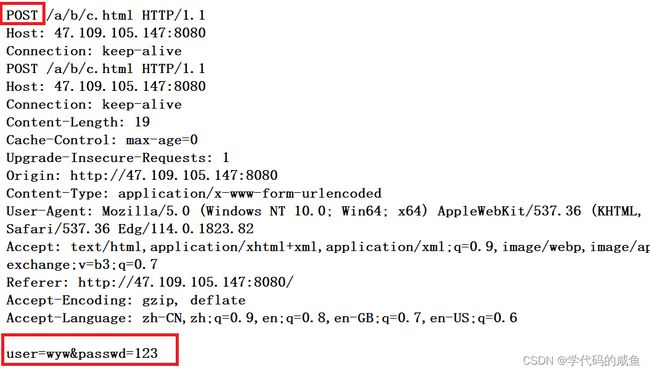
从上图可以看出:POST方法提交参数,会将参数以明文的方式拼接到HTTP正文中来进行提交。
所以,两者方法的比较,GET方法传参不私密,POST方法传参通过正文传参,相对来说私密点。并且如果我们传的资源比如视频,音乐这些比较大的不采用GET方法,否则URL会非常长。
1.4 HTTP的状态码
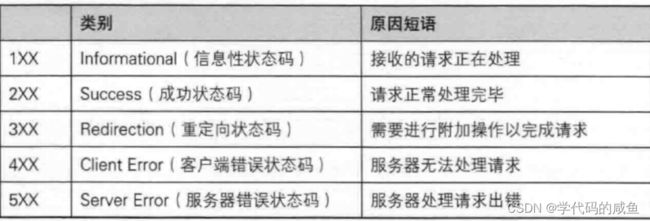
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)。
1.4.1 301和302
301叫做永久重定向,302叫做临时重定向。
这里的重定向是什么意思呢?
我们客户端向服务器进行请求,它给客户端响应,响应中的状态码如果为301或者302,那么它的响应报头里有location:一个新的网站(new url)。

那么我们的浏览器就会自动的跳转到new url这个服务端。这个过程就是重定向。
1.4.2 代码实现

我们这里读取到请求之后,服务器不做响应,让它重定向。

大家可以这样去测试一下,你会发现它会跳转到qq的网页。这里我们写Location时需要加上域名,不然只能站内跳转。
1.5 Cookie
http协议的特点之一:无状态,意思是:http不会记录你上一秒的请求。
那么肯定会有许多人有疑问?假如我们是某个网站的VIP,我们想看一部电影,我们肯定要先登录我们的VIP,如果我们不记录,那么每访问一部电影,我们就登录一次VIP吗?
答案肯定不是的,虽然http没有记录,但是我们却有保持记录的手段,所以就需要用到Cookie(会话保持)。
比如:我们登录时需要输入我们的用户名和密码,给服务端请求响应后,服务器会把我们输入的内容写到客户端的Cookie中。等下次再次请求时,会自动携带浏览器访问该网站对应的Cookie文件中的内容。
1.5.1 代码验证
我们要设置Cookie,需要使用一个响应报头:Set-Cookie。

测试如下:

我们可以看到在浏览器中就会把内容保存到Cookie中。
那么Cookie是什么呢?
是浏览器维护的文件,存在磁盘上或者内存中。
但是单单一个Cookie是不安全的,所以我们采用了Cookie+session。
1.5.2 Cookie+session
当我们输入用户名和密码后,服务器会先认证,但是不着急先返回,它先会自动创建一个session文件。然后把用户的临时私密信息,保存在这个文件中。最后,会把session_id(具有唯一性)写入到本地的Cookie中。下次再请求的时候,就会通过session_id来获取信息。
1.6 Connection
用户看到的完整的网页内容,背后可能是无数次的http请求。1.0的HTTP版本,是一种无状态,无连接的应用层协议。 HTTP1.0规定浏览器和服务器保持短暂的链接。并且http底层主流采用的是tcp协议,所以浏览器每次请求都需要与服务器建立一个TCP连接,服务器处理完成以后立即断开TCP连接(无连接),服务器不跟踪也每个客户单,也不记录过去的请求(无状态)。
所以,造成的问题:每次发送请求,都需要进行一次TCP连接,而TCP的连接释放过程又是比较费事的。这种特性会使得网络的利用率变低。
所以在http1.1版本增加Connection字段,通过设置Keep-Alive保持HTTP连接不断卡。避免每次客户端与服务器请求都要重复建立释放建立TCP连接。提高了网络的利用率。
那么我们使用http1.1版本时,在客户端和服务端之间需要进行版本协商工作。如果客户端和服务端的Connection都是Keep-Alive,说明双方同意采用长链接的方案。如果某个当中的Connection是closed,说明只能采用短链接。