论文解读:Contrastive Learning Reduces Hallucination in Conversations
论文解读:Contrastive Learning Reduces Hallucination in Conversations

Github:https://github.com/sunnweiwei/MixCL
一、动机
- 大量的知识(例如常识、事实等)对于开放领域的对话系统至关重要,为了注入知识,通常会涉及到检索环节。现如今大语言语言模型的提出可以充当一个高质量的对话机器人,实现生成更多有价值信息的回复;
- 然而大模型通常都有幻觉问题,即生成出貌似合理但实际上与上下文不相关或错误的信息;
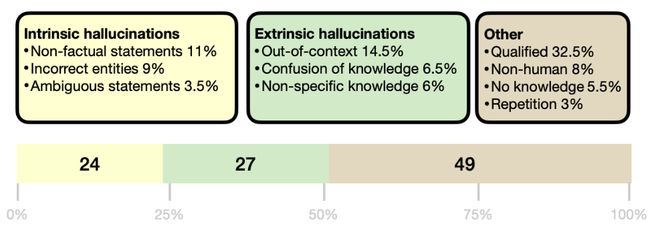
- 通过对Wizard-of-Wikipedia随机采样200个样本,并让BART生成对应的回复,根据得到的200个回复,邀请3个专家从内部幻觉和外部幻觉两个角度进行标注。结果表明,有超过50%的回复是存在幻觉的。
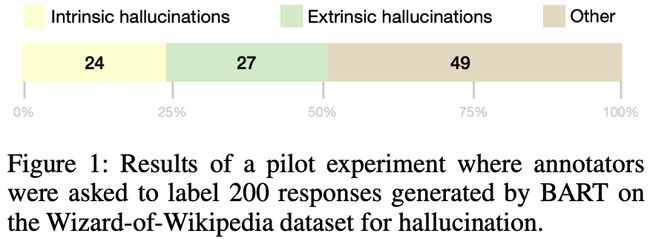
具体的占比如下图:
- 产生这种幻觉问题有很多种,例如训练阶段和测试阶段的目标不一致。训练时时最大化似然估计,这导致推理时也是按照这种模式来生成。
- 先前工作解决幻觉通常是注入外部知识库的方式,例如检索(retrieve)和后处理(post-editing)。
二、方法
问题定义
给定一个问题或上下文 x x x,一个对应检索的知识 K \mathcal{K} K,目标是根据上下文和知识来生成回复 y y y。
目前对话有两种模式,如下图:
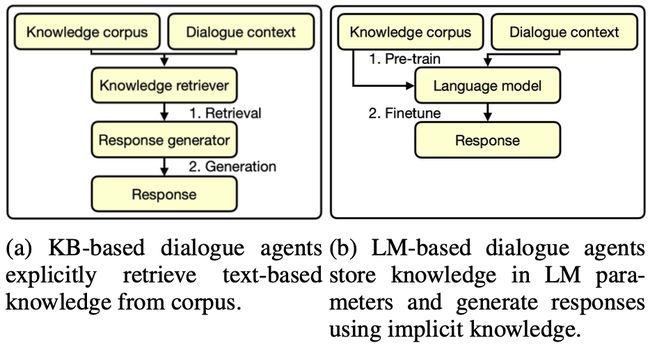
- KB模式:根据对话上下文检索知识库,获得检索到的文档后结合上下文生成回复;
- LM模式:现如今的语言模型范式,即让语言模型先在知识库上预训练,然后再直接回答;
本文则关注LM模式
(1)Pre-training:采用BART作为语言模型:

(2)SFT(Fine-tuning):采用MLE目标在对话数据集上进行自回归式训练:

然而MLE损失鼓励模型盲目模仿训练数据并导致模型幻觉,其过度依赖于前面的token,容易导致误差传播。
研究发现,使用标准 MLE 训练的模型可能会过度依赖之前预测的标记,从而加剧错误传播(Wang 和 Sennrich 2020)。 结果,在推理阶段,随着生成序列的增长,错误沿着序列累积,模型往往会放大错误并产生幻觉内容。
Studies have found that models trained with standard MLE may over-rely on previously predicted tokens, exacerbating error propagation (Wang and Sennrich 2020). As a result, during the inference stage, as the generated sequence grows, the errors accumulate along the sequence, and the model tends to amplify errors and generate hallucinating contents.
MixCL
本文提出MixCL,一种基于混合对比学习的训练策略来降低模型幻觉。
方法如下图所示:
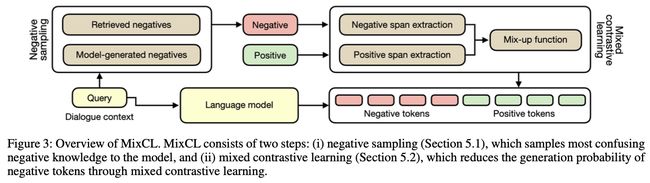
主要包括两个核心步骤:Negative Sampling和Mixed Contrastive Learning
Negative Sampling
z + z^{+} z+表示正确的知识或文本片段,代表positive,其通过一个函数 Q P o s ( x ) Q_{Pos}(x) QPos(x)来实现positive的获取。该函数输入的是原始的文本 x x x,输出正确的知识片段,可以是人工标注,也可以是启发式规则。
z − z^- z−表示negative,即non-factual或与输入 x x x存在不相关的知识(irrelevant knowledge)片段。本文设计两种获得 z − z^- z−的方法:
(1)检索式:采用TF-IDF retriever,给定输入文本 x x x和一个知识库 K \mathcal{K} K,输出一组 z − z^- z−。由于采用TF-IDF,采样得到的片段与输入文本存在一定的confusion,但依然是negative;
![]()
(2)模型生成式:提出一种bootstrapping策略,在模型生成时获得negative
![]()
使用NLI工具约束模型生成的片段不包含正确的知识。
基于上述两个方法,最终构建得到负采样函数:
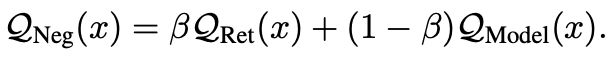
Mixed Contrastive Learning
首先对比学习的loss设计如下所示:
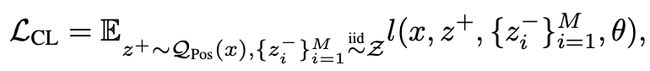
l l l表示cross-entropy loss, M M M为负样本的数量。
在BERT或GPT模式的训练中,通常 l l l要么是基于token的loss,要么是基于sentence的loss。然而模型产生的幻觉通常是一个文本区间(span),因此本文提出基于span的对比学习。
(1)抽取区间
首先要从positive和negative文本中分别抽取区间。
考虑到幻觉有内部幻觉和外部幻觉,因此设计两种span抽取策略。
- 内部幻觉:通常是实体层面上出现混淆,因此可使用NER抽取person、time等类型的实体;
- 外部幻觉:文本中出现了不相关的文本,因此采用constituency parsing抽取句子成分,例如noun、particle等。
(2)构建Mixing example
参考Mix-up等工作,将一个正样本和负样本进行mix-up: z ~ = M i x ( z + , z − ) \tilde{z}=Mix(z^+, z^-) z~=Mix(z+,z−)。
具体操作如下所示:
- 给定一个正样本 z + z^+ z+和负样本 z − z^- z−;
- 从正样本中随机采样一个之前抽取出来的区间;
- 再从负样本中随机采样一个之前抽取出来的区间;
- 将负样本中的区间替换到正样本的区间,得到 z ~ \tilde{z} z~;
- 定义一个 ϕ \phi ϕ序列,其长度与 z ~ \tilde{z} z~一样,该序列的每个元素为0或1,其中0表示对应 z ~ \tilde{z} z~位置的token来自 z − z^- z−,1表示对应的 z ~ \tilde{z} z~位置的token来自 z + z^+ z+。
其实,0/1表示的是混合后的序列 z ~ \tilde{z} z~对应的token是负样本/正样本。
(3)Contrastive Loss
对于整个数据集,给定一个输入 x x x,先获得对应的一个正样本 z + z^+ z+,然后采样获得 M M M个负样本 z i − z_i^- zi−。
所有输入 x x x对应的总的loss定义如下:

对于某一个正样本 z + z^+ z+和负样本 z i − z_i^- zi−的pair,其loss定义如下所示:
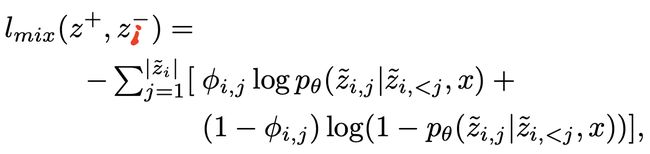
其中 z ~ i = M i x ( z + , z i − ) \tilde{z}_i=Mix(z^+, z_i^-) z~i=Mix(z+,zi−), ∣ z ~ i ∣ |\tilde{z}_i| ∣z~i∣表示这个序列的token数量, ϕ i j \phi_{ij} ϕij表示 z ~ i \tilde{z}_i z~i的第 j j j个token是否是positive。
可知该loss依然是站在基于token的Causal Languege Modeling目标,但是不同的是,对应的token有的是来自positive,有的是negative,negative token可以认为是训练过程中模拟的幻觉部分。
- 在训练过程中,如果 ϕ i j = 1 \phi_{ij}=1 ϕij=1,说明当前的token是positive的,则只需要最大化该token被预测的概率即可;
- 如果 ϕ i j = 0 \phi_{ij}=0 ϕij=0,说明当前的token是negative的,则需要最小化这个token被预测的概率。
最终总的训练loss为:

初始化时, α 1 = 0.4 \alpha_1=0.4 α1=0.4, α 2 = 0.3 \alpha_2=0.3 α2=0.3, α 3 = 0.3 \alpha_3=0.3 α3=0.3
随后这些参数进行线性变化,最终 α 1 = 0.5 \alpha_1=0.5 α1=0.5, α 2 = 0.5 \alpha_2=0.5 α2=0.5, α 3 = 0 \alpha_3=0 α3=0。
之所以一开始 α 3 > 0 \alpha_3>0 α3>0,目的是为了防止模型灾难性遗忘。
三、实验
数据集
Wizard-of-Wikipedia(WoW)
评价指标
F1、ROUGE-L、BLEU(2/4)、MT、Knowledge-F1、Entity-F1、Acc。
F1 (Dinan et al. 2019) calculates the unigram F1 between the generated text and the ground-truth text. For ROUGE (Lin 2004) we use ROUGE-L (RL for short) following previous work. BLEU (Papineni et al. 2002) we use BLEU-2 and BLEU-4 (or B2 and B4 for short) and use the implementation in the NLTK Toolkit. MT (Meteor) (Denkowski and Lavie 2014) is based on the harmonic mean of unigram precision and recall. Knowledge-F1 (Dinan et al. 2019) (or KF1 for short) calculates the F1 between the generated response and the ground-truth knowledge sentence, which indicates the informativeness of a response. Acc measures the knowledge selection accuracy. As we skip the knowledge selection step, we select knowledge by matching the generated response with each knowledge candidate in WoW using the F1 score. Entity-F1 (or EF1 for short) identifies entities in text using Spacy, deletes the non-entity words, and calculates the F1 score between the modified generated text and the ground- truth response. EF1 eliminates the impact of the stop-word and focuses on the accuracy of entities.
这些评价指标的实现参考:https://github.com/sunnweiwei/MixCL/blob/main/utils/evaluation.py
另外邀请新的三个标注人员对测试样本中的100个样本进行标注,从四个方面进行打分。
Informativeness(0、1、2分), which measures whether the response is knowledge-inclusive; Relevancy(0、1、2分), which measures whether the response’s content is relevant to the dialogue; Factuality(0或1分), which measures whether the information in the response is factually correct; and Humanlikeness(0、1、2分), which measures whether the response is human-like in its fluency and naturalness.
实验细节
backbone选择BART-Large(400M),知识库则为Wikipedia
实验结果
(1)自动评估

可知在各种指标上效果都是提升比较明显的。
(2)人工评估

克制提出的MixCL在人工打分上也是最高的,部分指标也逼近人类回复的打分。
(3)消融实验
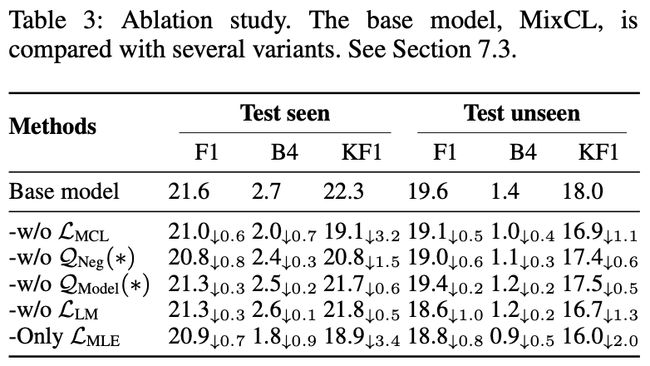
模型训练使用了三个loss和两个采样函数。发现如果缺少使用一个部分呢,效果都会下降。但是指标上下降也并不明显
(4)有效性验证
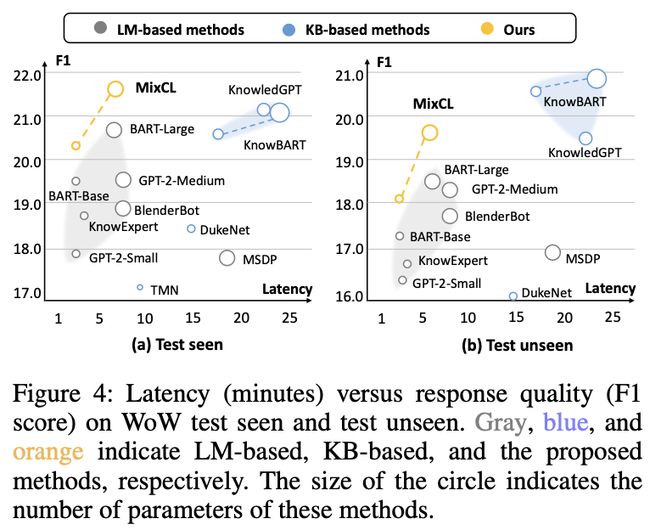
横轴表示模型生成结果的等待时间,纵轴为F1值。
可知我们的方法用最少的latency(等待时间)获得了最佳的F1值,说明整体性能是很优的。
(5)Case Study
