ONE-PEACE论文解读
文章目录
- 1. 摘要
- 2. 引言
- 3. 算法
-
- 3.1 结构
- 模态自适应器
- 3.2 模态融合编码器
- 3.3 任务
- 4. 实验
-
- 4.1 视觉任务
- 4.2 音频任务
- 4.3 视觉语言任务
- 4.4 消融实验
- 4.5 zero-shot检索
- 5. 结论
论文: 《ONE-PEACE: EXPLORING ONE GENERAL REPRESENTATION MODEL TOWARD UNLIMITED MODALITIES》
github: https://github.com/OFA-Sys/ONE-PEACE
1. 摘要
ONE-PEACE,一个40亿参数可扩展模型,对齐并集成视觉、音频、文字模态表征,其包括:模态自适应层、自监督层、模态前馈网络。通过增加自适应层级前馈网络使得模型易扩展到新模态,self-attention层进行多模态融合。为了预训练ONE-PEACE,作者发展两个模态未知预训练任务:跨模态对齐对比损失、模态内去噪对比学习。ONE-PEACE在多个任务达到前沿水平,分类、分割、音频文本检索、音频分类、音频问答、图文检索、visual grounding等任务。
2. 引言
作者探索一种可扩展方式构建泛化保证模型适应于任意模态。泛化表征模型条件:
1、模型结构灵活适应于各种模态,支持多模态交互;
2、预训练任务不仅可以提取信息,还需跨模态对齐;
3、预训练任务具有泛化性,可应用于不同模态。
作者提出的ONE-PEACE包括多个模态自适应器、模态融合编码器。自适应器用于将原始输入转换称特征序列,模态融合编码器中Transformer block包括共享的self-attention层及多模态特征前馈网络,
训练ONE-PEACE,作者设计两个模态无关预训练任务。跨模态对抗学习、模态内去噪对抗学习。
3. 算法
3.1 结构
ONE-PEACE包括三个模态自适应器以及一个模态融合编码器。结构如图1所示。
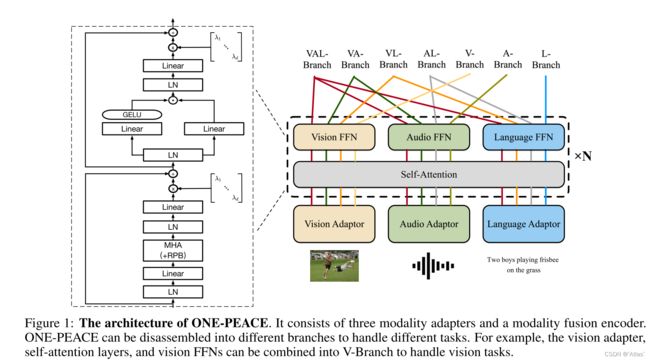
模态自适应器
模态自适应器用于将不同原始信号转换为统一特征。
Vision Adapter:使用层级MLP,逐渐增加patch大小至16*16,将输入图像patch化,然后将patch序列化,加入分类embedding,添加绝对位置embedding至image embedding,得到 E V = e c l s V , e 1 V , e 2 V , . . . , e M V E^V = e^V_{cls}, e^V_1 , e^V_2, ..., e^V_M EV=eclsV,e1V,e2V,...,eMV
Audio Adapter:使用16kHz采样音频,并进行归一化,通过卷积提取特征得到音频embedding,使用卷积层提取相对位置信息并添加到音频embedding。引入音频分类embedding得到音频表征 E A = e c l s A , e 1 A , e 2 A , . . . , e N A E^A = e^A_{cls}, e^A_1, e^A_2, ..., e^A_N EA=eclsA,e1A,e2A,...,eNA
Language Adapter:使用字节对编码器(BPE)将输入文本转换为子序列,特别token:[CLS] 和 [EOS],插入句子的起始和结尾,embedding层将子序列转为文本embedding,引入卷对位置embedding得到文本表征 E L = e c l s L , e 1 L , e 2 L , . . . , e K L , e e o s L E^L = e^L_{cls}, e^L_1 , e^L_2, ..., e^L_K, e^L_{eos} EL=eclsL,e1L,e2L,...,eKL,eeosL。
3.2 模态融合编码器
模态融合编码器基于Transformer结构,每个Transformer block包括一个共享self-attention层及三个模态前馈网络。共享self-attention层用于不同模态之间交互,三个模态前馈网络(V-FFN, A-FFN, and L-FFN),进一步提取各自模态信息。为了稳定训练及提升模型表现,作者进行如下改进:
Sub-LayerNorm:在输入映射之前以及每个self-attention层及FFN层输出映射之前插入映射。
GeGLU激活函数:替换FFN中激活函数为GeGLU,
Relative Position Bias (RPB):对于文本及音频,引入1D相对位置偏置,对于图像引入2D偏置。训练过程self-attention层共享偏置,fine-tuning时拆分;
LayerScale:用于动态调整每个残差block的输出。具体的,对于self-attention层级FFN层输出乘以可学习对角矩阵。LayerScale有利于稳定训练,提升性能。
ONE-PEACE对不同模态解耦进不同分支处理任务。
3.3 任务
ONE-PEACE预训练任务包括跨模态对比学习以及模态内去噪对比学习。前者用于提升跨模态检索能力,后者用于在下游任务预训练时获得更高表现,如图2所示。
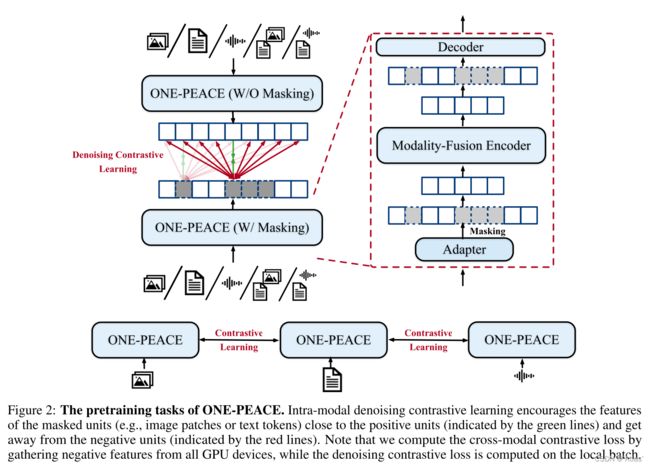
跨模态对比学习:
内核为最大化成对样本相似度,最小化非成对样本相似度;具体token的输出作为全局表征,比如vision class token or language class token,通过线性映射及归一化的点最终表征 S 1 , S 2 S^1, S^2 S1,S2,损失函数如式1所示,

其中 N N N为batch大小, i , j i,j i,j为bacth内index, σ σ σ为可学习参数。跨模态对比学习用于图像文本对以及音频文本对。
模态内去噪对比学习:
跨模态对比学习主要用于对齐不同模态特征,然而缺少模态内精细特征学习,因此引入模态内去噪对比学习。具体如下:
**对于任意模态,首先通过对应模态自适应器编码,得到embedding,然后随机mask一些单元(text tokens or image patches),同时将未mask的单元送入模态融合编码器,得到结果与可学习mask token进行concat送入轻量级Transformer decoder,生成mask区域特征,同时为mask样本输入ONE-PEACE得到目标特征。**损失函数如式2,
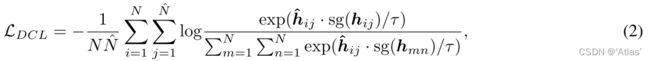
h ^ i j \hat h_{ij} h^ij为mask后得到修复特征, h i j h_{ij} hij为目标特征, s g sg sg表示停止梯度回传, N ^ \hat N N^为mask单元数量,这个损失在拉近正样本距离同时使得负样本之间远离。
模态内去噪对比学习应用于5种数据:图像、音频、文本、图文对、音频文本对。对于图像文本对,将image patch及text token concat进行编码得到目标特征。
训练:
ONE-PEACE预训练分为两部分:视觉-语言预训练、音频-语言预训练。
视觉-语言预训练过程使用图文对数据,仅更新视觉、语言相关参数,损失函数如式3;
![]()
在音频-语言预训练阶段,使用音频-文本对,损失函数如式4
![]()
4. 实验
4.1 视觉任务
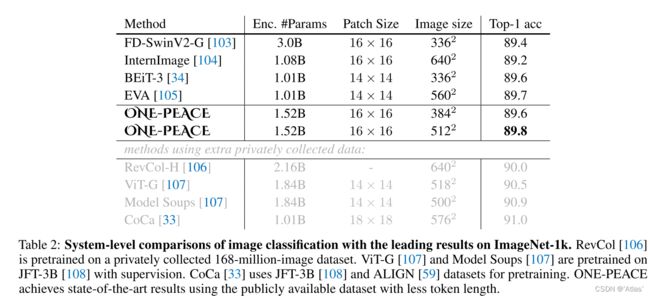
图像分类:在除class token以外图像token进行全局池化、LN、linear层结果作为输出,进一步在ImageNet-21k上进行finetune,结果如表2,在ImageNet数据集top-1 acc达到89.8;
语义分割:使用Mask2Former作为分割头在ADE20K数据集进行finetune,结果如表3,达到新SOTA,63.0。
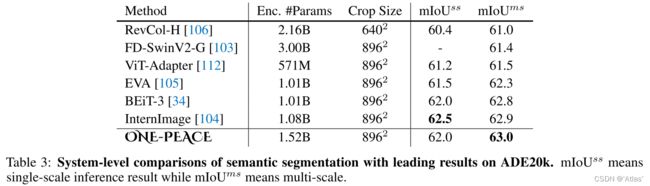
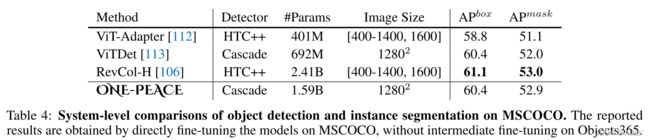
目标检测及实例分割:使用ONE-PEACE的backbone,ViTDet及Cascade Mask-RCNN结构,在COCO上进行finetune,结果如表4,达到与SOTA相当效果,与VitDet相比好像增益不大;
视频行为识别:跟随AIM,frozen 预训练模型参数,每个transformer层增加空间、时间MLP自适应器,使用I3D作为分类头,结果如表5,在Kinetics 400数据集,达到88.1 top-1 acc。

4.2 音频任务
音频文本检索:作者融合AudioCaps、Clotho、MACS三个数据集进行Finetune,与图文检索类似,使用A-Branch and L-Branch分别提取音频及文本特征,计算余弦距离,结果如表6,在AudioCaps、Clotho数据集达到SOTA。

音频分类及音频问答:zero-shot音频分类分别通过A-Branch提取音频embedding、L-Branch提取文本embedding,通过两者相似度实现分类;音频问答任务中每个样本包括一个视频、一个问题及四个候选答案,每个答案及问题联合音频通过AL-Branch提取embedding,最小化正确答案之间距离,最大化错误答案距离,结果如表7,在ESC-50数据集,ONE-PEACE达到91.8 zero-shot acc,在FSD50K数据集超越之前SOTA,AQA任务超越SOTA 2.7。

4.3 视觉语言任务
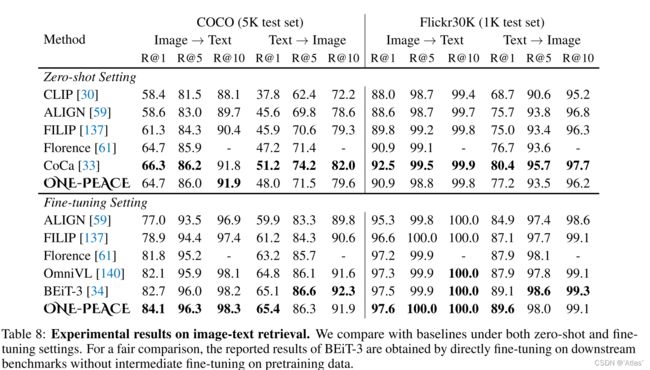
图文检索:结果如表8,看起来和BLIP2有些差距;
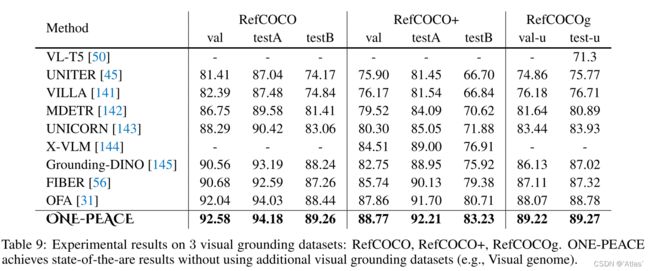
Visual Grounding:结果如表9,在三个数据集达到新SOTA;
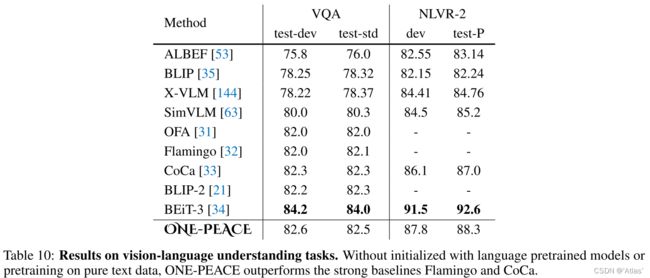
视觉语言理解:表10展示ONE-PEACE在VQA及视觉推理任务上结果,比BEiT-3表现差的原因为:BEiT-3在同域数据集训练;BEiT-3使用纯文本进行预训练,提高对文本理解;
4.4 消融实验
表11展示模型结构消融实验,共享self-attention层、FFN层分离效果最佳;由于self-attention层在对齐模态起到更重作用。

图4展示不同结构拟合能力,self-attention层共享、FFN层分离的网络拟合最快。
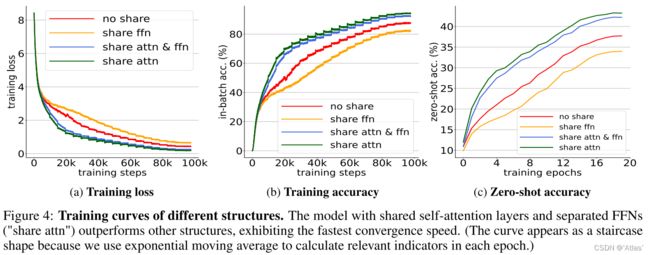
表12展示模态内去噪对比学习影响,DCL-L、DCL-V、DCL-VL均起到正向作用,提升下游任务finetune性能及zero-shot跨模态检索能力;

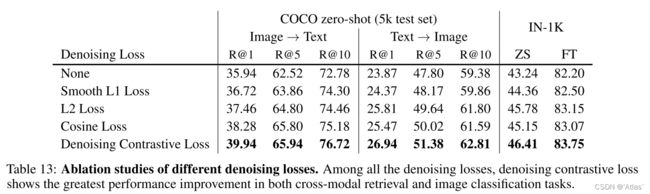
表13作者比较各种去噪损失函数,去噪对抗损失函数提升最明显;
4.5 zero-shot检索
文本作为中间态用于与对齐其他模态,比如文本作为中间态,可用于对齐图片与语音。作者评估语音到图片、语音+图片到图片、语音+文本到图片检索,如图5所示。表明不需要学习所有模态间对应关系,与之间模态保持一致即可。
5. 结论
ONE-PEACE作为一种易扩展的跨模态泛化表征模型,可对齐和集成视觉、语音、语言模态表征,实验结果表明,在多个任务达到前沿效果:图像分类、语义分割、音频-文本检索、音频问答、图文检索、visual grounding。同时具有一定zero-shot检索能力,即使训练集数据模态非成对,也能够对齐模态。
限制:
对于一些任务未达到SOTA,作者进行归因于:
- 在预训练阶段ONE-PEACE没有见过足够的图文对;
- 未使用语言预训练模型初始化,也没有引入纯语言数据。
个人思考:
- 在目标检测、实例分割任务,使用ONE-PEACE预训练增益不大;
- 检索能力相对于BLIP2,存在一定差距,当然模型大小也存在差异;
- zero-shot检索很有意思,通过各种模态对齐中间态,进而完成各个模态对齐,但是训练起来会不会有难度。