【机器学习】西瓜书习题3.5Python编程实现线性判别分析,并给出西瓜数据集 3.0α上的结果
参考代码
结合自己的理解,添加注释。
代码
- 导入相关的库
import numpy as np
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
- 导入数据,进行数据处理和特征工程
得到数据集 D = { ( x i , y i ) } i = 1 m , y i ∈ { 0 , 1 } D=\{ (x_i,y_i) \}_{i=1}^m, y_i \in \{0,1\} D={(xi,yi)}i=1m,yi∈{0,1}
# 1.数据处理,特征工程
data_path = 'watermelon3_0_Ch.csv'
data = pd.read_csv(data_path).values
# 按照数据集3.0α,强制转换数据类型
X = data[:,7:9].astype(float)
y = data[:,9]
y[y=='是'] = 1
y[y=='否'] = 0
y = y.astype(int)
- 计算西瓜书60页中的 X i 、 μ i 、 Σ i X_{i}、\mu_i、\Sigma_i Xi、μi、Σi
# 将X的数据根据label值分成X0和X1
pos = y == 1
neg = y == 0
X0 = X[neg]
X1 = X[pos]
# 计算u0,u1 keepdims保持原数据维数
u0 = X0.mean(0, keepdims=True)
u1 = X1.mean(0, keepdims=True)
# 计算sigma0,sigma1
sigma0 = np.dot((X0-u0).T,X0-u0)
sigma1 = np.dot((X1-u1).T,X1-u1)
- 根据式3.33计算类内散度矩阵
S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T S_w=\Sigma_0+\Sigma_1=\sum_{x\in X_{0}}(x-\mu_0)(x-\mu_0)^T+\sum_{x\in X_{1}}(x-\mu_1)(x-\mu_1)^T Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T
根据式3.39计算 w w w
w = S w − 1 ( μ 0 − μ 1 ) w=S_w^{-1}(\mu_0-\mu_1) w=Sw−1(μ0−μ1)
# 计算类内散度矩阵 with-class scatter matrix
sw = sigma0 + sigma1
# numpy.linalg.inv() 函数来计算矩阵的逆
w = np.dot(np.linalg.inv(sw),(u0-u1).T).reshape(1,-1)
- 画出样本点和得到的直线
fig, ax = plt.subplots()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
plt.scatter(X1[:, 0], X1[:, 1], c='k', marker='o', label='good')
plt.scatter(X0[:, 0], X0[:, 1], c='r', marker='x', label='bad')
plt.xlabel('密度', labelpad=1)
plt.ylabel('含糖量')
plt.legend(loc='upper right')
x_tmp = np.linspace(-0.05, 0.15)
y_tmp = x_tmp * w[0, 1] / w[0, 0]
plt.plot(x_tmp, y_tmp, '#808080', linewidth=1)
得到下图

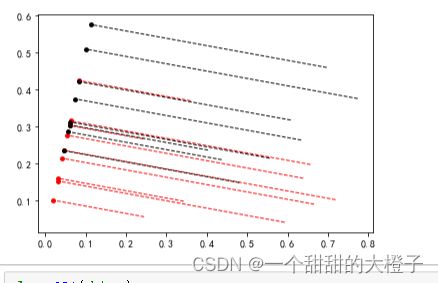
- 计算每个样本点在直线上的投影
计算的理解参考这篇文章
# 求w这个向量的 单位向量 wu
# np.linalg.norm()默认求2 范数,表示向量中各个元素平方和 的 1/2 次方,L2 范数又称 Euclidean 范数或者 Frobenius 范数。
wu = w / np.linalg.norm(w)
# 正负样本点
# 求负样本的投影点,并连线
X0_project = np.dot(X0, np.dot(wu.T, wu))
plt.scatter(X0_project[:, 0], X0_project[:, 1], c='r', s=15)
for i in range(X0.shape[0]):
plt.plot([X0[i, 0], X0_project[i, 0]], [X0[i, 1], X0_project[i, 1]], '--r', linewidth=1)
# 求正样本的投影点,并连线
X1_project = np.dot(X1, np.dot(wu.T, wu))
plt.scatter(X1_project[:, 0], X1_project[:, 1], c='k', s=15)
for i in range(X1.shape[0]):
plt.plot([X1[i, 0], X1_project[i, 0]], [X1[i, 1], X1_project[i, 1]], '--k', linewidth=1)
得到下图
将上述代码封装成类,如下:
class LDA(object):
def fit(self, X_, y_, plot_=False):
pos = y_ == 1
neg = y_ == 0
X0 = X_[neg]
X1 = X_[pos]
u0 = X0.mean(0, keepdims=True) # (1, n)
u1 = X1.mean(0, keepdims=True)
sw = np.dot((X0 - u0).T, X0 - u0) + np.dot((X1 - u1).T, X1 - u1)
w = np.dot(np.linalg.inv(sw), (u0 - u1).T).reshape(1, -1) # (1, n)
if plot_:
# 设置字体为楷体
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.rcParams['font.sans-serif'] = ['KaiTi']
fig, ax = plt.subplots()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
plt.scatter(X1[:, 0], X1[:, 1], c='k', marker='o', label='good')
plt.scatter(X0[:, 0], X0[:, 1], c='r', marker='x', label='bad')
plt.xlabel('密度', labelpad=1)
plt.ylabel('含糖量')
plt.legend(loc='upper right')
x_tmp = np.linspace(-0.05, 0.15)
y_tmp = x_tmp * w[0, 1] / w[0, 0]
plt.plot(x_tmp, y_tmp, '#808080', linewidth=1)
wu = w / np.linalg.norm(w)
# 正负样板店
X0_project = np.dot(X0, np.dot(wu.T, wu))
plt.scatter(X0_project[:, 0], X0_project[:, 1], c='r', s=15)
for i in range(X0.shape[0]):
plt.plot([X0[i, 0], X0_project[i, 0]], [X0[i, 1], X0_project[i, 1]], '--r', linewidth=1)
X1_project = np.dot(X1, np.dot(wu.T, wu))
plt.scatter(X1_project[:, 0], X1_project[:, 1], c='k', s=15)
for i in range(X1.shape[0]):
plt.plot([X1[i, 0], X1_project[i, 0]], [X1[i, 1], X1_project[i, 1]], '--k', linewidth=1)
# 中心点的投影
u0_project = np.dot(u0, np.dot(wu.T, wu))
plt.scatter(u0_project[:, 0], u0_project[:, 1], c='#FF4500', s=60)
u1_project = np.dot(u1, np.dot(wu.T, wu))
plt.scatter(u1_project[:, 0], u1_project[:, 1], c='#696969', s=60)
ax.annotate(r'u0 投影点',
xy=(u0_project[:, 0], u0_project[:, 1]),
xytext=(u0_project[:, 0] - 0.2, u0_project[:, 1] - 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
ax.annotate(r'u1 投影点',
xy=(u1_project[:, 0], u1_project[:, 1]),
xytext=(u1_project[:, 0] - 0.1, u1_project[:, 1] + 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
plt.axis("equal") # 两坐标轴的单位刻度长度保存一致
plt.show()
self.w = w
self.u0 = u0
self.u1 = u1
return self
def predict(self, X):
project = np.dot(X, self.w.T)
wu0 = np.dot(self.w, self.u0.T)
wu1 = np.dot(self.w, self.u1.T)
return (np.abs(project - wu1) < np.abs(project - wu0)).astype(int)