Python的内存管理(浅拷贝与深拷贝)
欢迎来到智能优化算法的世界
博客主页:卿云阁欢迎关注点赞收藏⭐️留言
本文由卿云阁原创!
本阶段属于筑基阶段之一,希望各位仙友顺利完成突破
首发时间:2021年12月17日
✉️希望可以和大家一起完成进阶之路!
作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
0️⃣整数和短小的字符
1️⃣判断对象和对象的关系
2️⃣字符串驻留机制
3️⃣可变对象与不可变对象
4️⃣浅拷贝与深拷贝

Python 内存管理
Python的内存管理机制可以从三个方面来讲
(1)垃圾回收
(2)引用计数
(3)内存池机制
变量和常量的目的是为了让计算机认识客观世界的万事万物。
变量的定义:
a=1 a=2变量是放到内存中,cpu只和内存交互。如果我们不用python解释器,a=1只是一个普通的字符,存储在内存里,只有保存之后,可以进入硬盘。用python解释后才用了变量的概念。那么python解释在解释a=1时会做什么事情。此时内存会开辟一个空间,空间的名字叫做a。a是变量名,1才是值。a=2 内存会开辟一个空间,空间的名字叫做a,现在a的值是2,那1呢?实际上还是放在原位置。此时python的垃圾回收机制会把1的内存自动释放。当一个变量值引用计数为0的时候,就会启动垃圾回收机制。在python解释器启动的那一刻,python会自动给-5到256分配内存空间(这个也称之为小整数池。
一、垃圾回收:
python不像C++,Java等语言一样,他们可以不用事先声明变量类型而直接对变量进行赋值。对Python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称Python语言为动态类型的原因(这里我们把动态类型可以简单的归结为对变量内存地址的分配是在运行时自动判断变量类型并对变量进行赋值)。
二、引用计数:
Python
C
#include#include int main() { int a=1; int b; b=1;//两种方式表示的含义相同 //b=a; printf("a的地址是:%d\n",&a); printf("b的地址是:%d\n",&b); return 0; }
通过以上结果我们发现,python和C在执行b=a,这条语句的时候解释是不一样的,C中相当于把a的值赋值给b,在python中b=a,相当于b和a同时绑定一个相同的值。
总结:
对于C语言来讲,我们创建一个变量A时就会为为该变量申请一个内存空间,并将变量值 放入该空间中,当将该变量赋给另一变量B时会为B申请一个新的内存空间,并将变量值放入到B的内存空间中 。
而Python的情况却不一样,当变量被绑定在一个对象上的时候,该变量的引用计数就是1,(还有另外一些情况也会导致变量引用计数的增加),系统会自动维护这些标签,并定时扫描,当某标签的引用计数变为0的时候,该对就会被回收。
0️⃣✨✨✨整数和短小的字符✨✨✨
1、python内存管理机制是什么?
1). 由于 python 中万物皆对象,内存管理机制就是对象的存储问题, Python 会分配一块内存空间去存储对象。
2) 对于整数和短小的字符等, python 会执行缓存机制,即将这些对象进行缓存,不会为相同的对象分配多个内存空间
3). 容器对象,如列表、元组、字典等,存储的其他对象,仅仅是其他对象的引用,即地址,并不是这些对象本身Python 对小整数的定义是 [-5,257),注意左闭右开, 这些整数对象是提前建立好的,不会被垃圾回收。在一个Python的程序中, 所有位于这个范围内的整数使用的都是同一个对象.
a=100 b=100 c=a print(id(a)) print(id(b)) print(id(c)) 结果: 1551333536 1551333536 1551333536
1️⃣✨✨✨判断对象和对象的关系✨✨✨
判断对象和对象的关系:
PYTHON 提供了对象判断符 is 和内容判断符==
A is B:判断对象 A 和对象 B 是否同一个内存地址,即是否同一个对象
A == B:判断 A 中的内容是否和 B 中的内容一致
isinstance(a, A)判断对象是否属于某一种类型
2️⃣✨✨✨字符串驻留机制✨✨✨
创建新的字符串对象时,Python 先比较常量池中是否有相同的对象( interned ),有的话则将指针指向已有对象,并减少新对象的指针,新对象由于没有引用计数,就会被垃圾回收机制回收掉,释放出内存。
a='a b' b='a b' print(id(a)) print(id(b)) 结果 1868537789216 1868537789216
3️⃣✨✨✨可变对象与不可变对象✨✨✨
不可变对象
a=('a','b') b=('a','b') print(id(a)) print(id(b)) 结果 1868533654920 1868537105608
可变对象
x=y=[1,2,3] print(id(x)) print(id(y)) x.append(4) print(id(x)) print(id(y)) z=[1,2,3] print(id(z)) w=[1,2,3,4] print(id(w)) 结果 1868533747080 1868533747080 1868533747080 1868533747080 1868537966792 1868537916744
4️⃣✨✨✨浅拷贝与深拷贝✨✨✨
如果程序中多个不同的地方都要使用同一个对象怎么办?一共有三种解决方式:
1.对象的引用赋值
2.对象的浅拷贝
3.对象的深拷贝
1.首先对象的引用赋值是指:(只适用于可变的数据类型)
将对象的内存地址同时赋值给多个变量,多个变量指向的是同一个内存地址,
如果通过一个变量修改了对象内容,那么其他变量指向的对象内容也会同步发生改变,
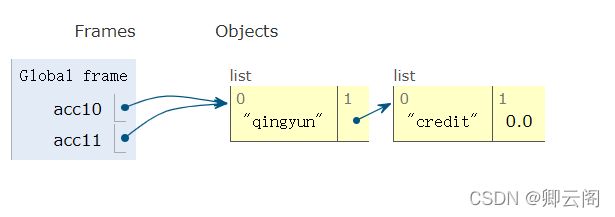
多个变量指向的地址相同.acc10=['qingyun',['credit',0.0]] acc11=acc10 print(id(acc10)) print(id(acc11)) 结果 139708482577544 139708482577544
2.对象的浅拷贝:
切片操作:acc1[:]对象实例化:list[acc1]
copy模块的copy()函数:copy.copy(acc1)
(1)切片操作:acc1[:]
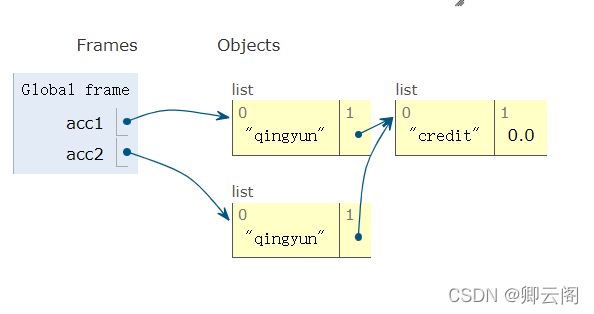
acc1=['qingyun',['credit',0.0]] acc2=acc1[:] print(id(acc1)) print(id(acc2)) 结果 139869809464520 139869795569928
(2) 对象实例化:list[acc1]
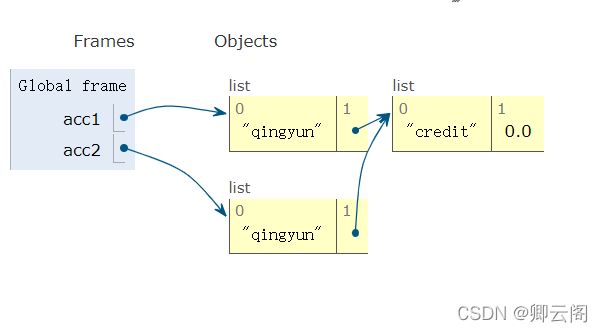
acc1=['qingyun',['credit',0.0]] acc2=list(acc1) print(id(acc1)) print(id(acc2)) 结果 139945907213448 139946096918024
(3) copy模块的copy()函数:copy.copy(acc1)
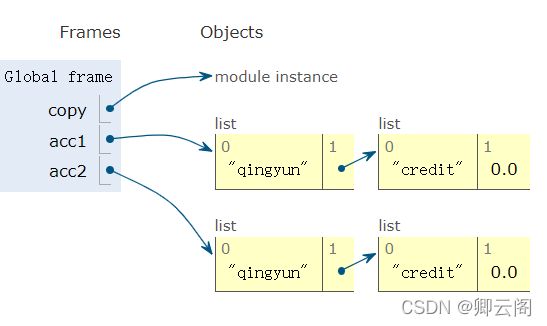
import copy acc1=['qingyun',['credit',0.0]] acc2=copy.copy(acc1) print(id(acc1)) print(id(acc2)) 结果 139688309432648 139688333061640
2.对象的深拷贝
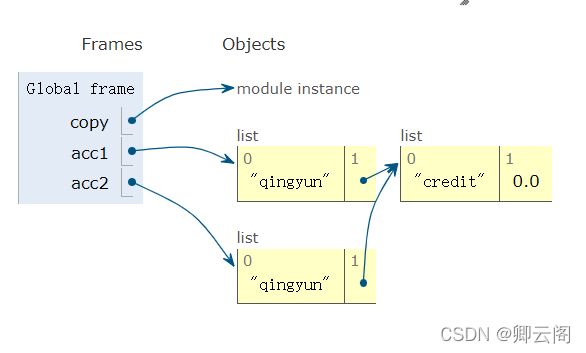
import copy acc1=['qingyun',['credit',0.0]] acc2=copy.deepcopy(acc1) print(id(acc1)) print(id(acc2)) 结果 140635593728264 140635617357320
循环引用之内存泄漏
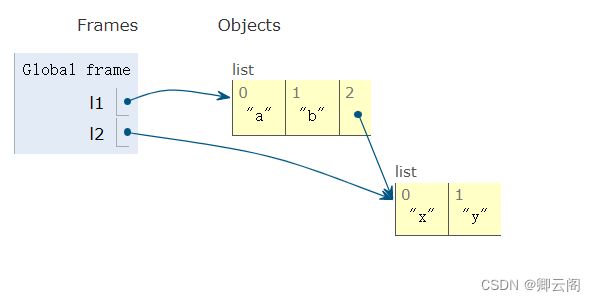
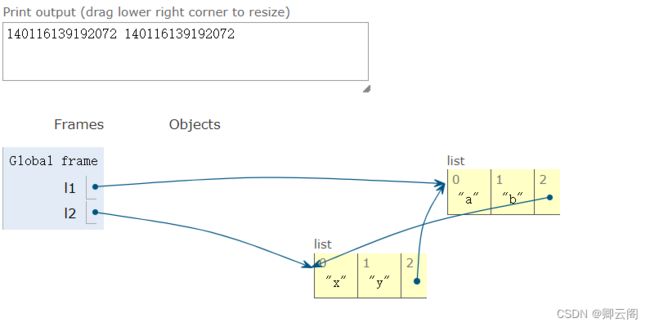
l1=['a','b'] l2=['x','y'] l1.append(l2) print(id(l2),id(l1[2])) l2.append(l1) print(id(l1),id(l2[2]))
此时,l1=['a','b',['x','y']],l2=['x','y']
l1=['a','b',['x','y']],l2=['x','y',['a','b',['x','y']]]
del l1#解决绑定关系 del l2此时这两个列表就变成了两个垃圾永远占着内存空间,这就做内存泄漏。
标记清除机制
实际上变量名和变量值都是存储在内存里的,其在内存里也是对应着两块空间的。
name="张大仙"
当堆区的内存地址引用为0 被清除时候,栈区的变量名也会被清除。
标记清除机制存会在内存空间不够用的时候,将整个的程序停止,然后扫描栈区,把所有可以通过栈区引用到的值全部标记成存活状态,一旦发现有通过栈区引用不到的值都标记成死亡状态,死亡状态的值会直接被清理掉
分代回收机制
的基于引用计数的垃圾回收机制,每次回收内存都要把所有的引用计数在遍历一遍,但是当我们的变量很多的时候,这样做的效率是很低的,所以我们可以设置一定的分类条件,这里仅作为了解。
直接引用和间接引用
name="张大仙"#直接引用 l=['a','b',name] print(l[2])#间接引用