2. Datax将数据导入到hive中
2.1 注意事项:
- 将idea中的CRLF改成LF,因为在windows中的转行符号为 \r\n 而在linux中的换行符是 \n,如果不转的话会报错
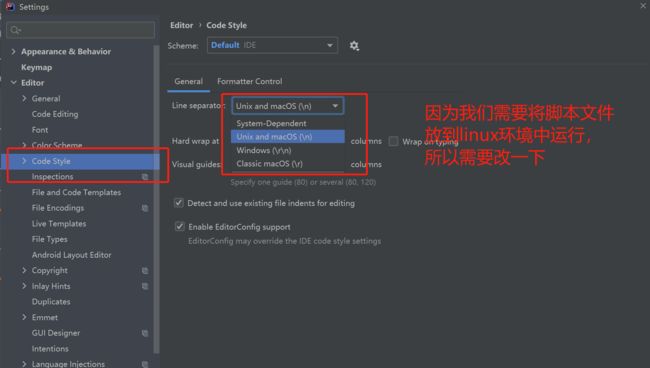
- 我们在配置datax 的 . json文件时需要注意
从GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。中取read和write时
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://xxx:port",
"fileType": "orc", -- 换成text
"path": "/user/hive/warehouse/writerorc.db/orcfull", -- 需要加上一个日期变量(${ds})
"fileName": "xxxx",
"column": [
{
"name": "col1",
"type": "TINYINT"
},
{
"name": "col2",
"type": "SMALLINT"
},
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress":"NONE" -- 这一行需要删掉
}
}
}
]
}
}- 小技巧,我们可以将字段截取到VScode中可以方便快捷的取到自己想要的格式。为了防止犯小错误,我们可以将上述脚本复制粘贴到VSCOd中,看的更加清晰
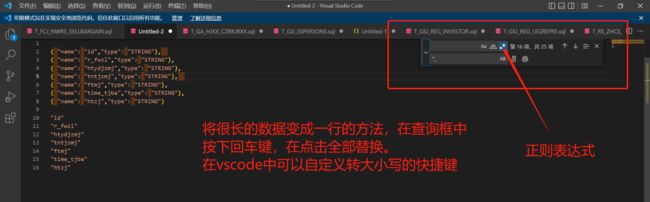
-
重点:
当数据量比较少时,采用全量采如,我们需要指定在hdfs中每一天建立一个分区,但是我们不能写死,所以我们在脚本文件汇总需要定义一个变量,然后再从外部传入到脚本文件中,如下:
# $1:获取脚本的第一个变量
ds=$1
# 1.删除输出目录
hadoop fs -rmr /daas/motl/ods/ods_t_fcj_nwrs_sellbargain/ds=$ds
# 2.创建一个空的输出目录
hadoop fs -mkdir -p /daas/motl/ods/ods_t_fcj_nwrs_sellbargain/ds=$ds
# 3. 使用datax导入数据
# -p: 給json脚本传参数
datax.py -p "-Dds=$ds" ../datax/ods_t_fcj_nwrs_sellbargain.json
# 4. 给剑豪的表动态的添加一个分区
hive -e "alter table ods.ods_t_fcj_nwrs_sellbargain add IF NOT EXISTS partition (ds='$ds')"
# 然后我们在命令行键入的时候需要指定 ds
sh xxx.sh 第一个变量(20220803)