计算机毕设 深度学习交通车辆流量分析 - 目标检测与跟踪 - python opencv
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 DeepSORT车辆跟踪
-
- 3.1 Deep SORT多目标跟踪算法
- 3.2 算法流程
- 4 YOLOV5算法
-
- 4.1 网络架构图
- 4.2 输入端
- 4.3 基准网络
- 4.4 Neck网络
- 4.5 Head输出层
- 5 最后
0 前言
这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
**基于深度学习得交通车辆流量分析 **
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分

1 课题背景
在智能交通系统中,利用监控视频进行车流量统计是一个研究热点。交管部门通过实时、准确地采集车流量信息,可以合理分配交通资源、提高道路通行效率,有效预防和应对城市交通拥堵问题。同时随着车辆数量的增加,交通违章现象频出,例如渣土车违规上道、工程车辆违规进入城市主干道、车辆停放在消防通道等,这一系列的交通违规行为给城市安全埋下了巨大隐患。对于交通管理者而言,加强对特定车辆的识别和分类管理尤为重要。然而,在实际监控识别车辆时,相当一部分车辆图像存在图像不全或者遮挡问题,极大降低了监控识别准确率。如何准确识别车辆,是当前车辆检测的重点。
根据实际情况,本文将车辆分为家用小轿车、货车两类进行车辆追踪和速度识别。
2 实现效果
可识别图片视频中的轿车和货车数量,检测行驶速度并实时显示。
关键代码
# 目标检测
def yolo_detect(self, im):
img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.conf_thres, self.iou_thres )
pred_boxes = []
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], im.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
pred_boxes.append(
(x1, y1, x2, y2, lbl, conf))
return pred_boxes
3 DeepSORT车辆跟踪
多目标在线跟踪算法 SORT(simple online andrealtime tracking)利用卡尔曼滤波和匈牙利匹配,将跟踪结果和检测结果之间的IoU作为代价矩阵,实现了一种简单高效并且实用的跟踪范式。但是 SORT 算法的缺陷在于所使用的关联度量(association metric)只有在状态估计不确定性较低的情况下有效,因此算法执行时会出现大量身份切换现象,当目标被遮挡时跟踪失败。为了改善这个问题,Deep SORT 将目标的运动信息和外观信息相结合作为关联度量,改善目标消失后重新出现导致的跟踪失败问题。
3.1 Deep SORT多目标跟踪算法
跟踪处理和状态估计
Deep SORT 利用检测器的结果初始化跟踪器,每个跟踪器都会设置一个计数器,在卡尔曼滤波之后计数器累加,当预测结果和检测结果成功匹配时,该计数器置为0。在一段时间内跟踪器没有匹配到合适的检测结果,则删除该跟踪器。Deep SORT 为每一帧中新出现的检测结果分配跟踪器,当该跟踪器连续3帧的预测结果都能匹配检测结果,则确认是出现了新的轨迹,否则删除该跟踪器。
Deep SORT使用 8维状态空间 描述目标的状态和在图像坐标系中的运动信息。
描述目标的状态和在图像坐标系中的运动信息。 表示目标检测框的中心坐标
表示目标检测框的中心坐标 分别表示检测框的宽高比例和高度,
分别表示检测框的宽高比例和高度,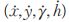 表示前面四个参数在图像坐标中的相对速度。算法使用具有恒定速度模型和线性观测模型的标准卡尔曼滤波器,将检测框参数
表示前面四个参数在图像坐标中的相对速度。算法使用具有恒定速度模型和线性观测模型的标准卡尔曼滤波器,将检测框参数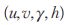 作为对象状态的直接观测值。
作为对象状态的直接观测值。
分配问题
Deep SORT 结合运动信息和外观信息,使用匈牙利算法匹配预测框和跟踪框。对于运动信息,算法使用马氏距离描述卡尔曼滤波预测结果和检测器结果的关联程度,如公式中:
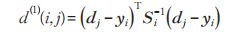
 分别表示第 j 个检测结果和第 i 个预测结果的状态向量,Si 表示检测结果和平均跟踪结果之间协方差矩阵。马氏距离通过测量检测结果距离平均跟踪结果的标准差,将状态估计的不确定性考虑在内,可以排除可能性低的关联。
分别表示第 j 个检测结果和第 i 个预测结果的状态向量,Si 表示检测结果和平均跟踪结果之间协方差矩阵。马氏距离通过测量检测结果距离平均跟踪结果的标准差,将状态估计的不确定性考虑在内,可以排除可能性低的关联。
当目标运动信息不确定性较低的时候,马氏距离是一种合适的关联因子,但是当目标遮挡或者镜头视角抖动时,仅使用马氏距离关联会导致目标身份切换。因此考虑加入外观信息,对每一个检测框 dj 计算出对应的外观特征描述符 rj ,并且设置 。对于每一个跟踪轨迹 k 设置特征仓库
。对于每一个跟踪轨迹 k 设置特征仓库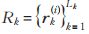 ,用来保存最近100条目标成功关联的特征描述符,
,用来保存最近100条目标成功关联的特征描述符, 。计算第 i 个跟踪框和第 j 个检测框最小余弦距离,如公式:
。计算第 i 个跟踪框和第 j 个检测框最小余弦距离,如公式:

当 小于指定的阈值,认为关联成功。
小于指定的阈值,认为关联成功。
马氏距离在短时预测情况下可以提供可靠的目标位置信息,使用外观特征的余弦相似度可以在目标遮挡又重新出现时恢复目标 ID,为了使两种度量的优势互补,使用线性加权的方式进行结合:

3.2 算法流程
Deepsort算法的工作流程如下图所示:

源码流程
主函数部分整体逻辑是比较简单的,首先是将命令行参数进行解析,解析的内容包括,MOTChanlleng序列文件所在路径、需要检测文件所在的目录等一系列参数。解析之后传递给run方法,开始运行。

进入run函数之后,首先会收集流信息,包括图片名称,检测结果以及置信度等,后续会将这些流信息传入到检测框生成函数中,生成检测框列表。然后会初始化metric对象,metric对象简单来说就是度量方式,在这个地方我们可以选择两种相似度的度量方式,第一种叫做余弦相似度度量,另一种叫做欧拉相似度度量。通过metric对象我们来初始化追踪器。

接着根据display参数开始生成对应的visuializer,如果选择将检测结果进行可视化展示,那么便会生成Visualization对象,我从这个类中可以看到,它主要是调用opencv image viewer来讲追踪的结果进行展示。如果display是false则会生成一个NoVisualization对象,它一个虚拟可视化对象,它以给定的顺序循环遍历所有帧以更新跟踪器,而无需执行任何可视化。两者主要区别其实就是是否调用opencv将图片展示出来。其实前边我们所做的一系列工作可以说都是准备的工作,实际上核心部分就是在执行这个run方法之后。此处我们可以看到,在run方法中传入了一个frame_callback函数,这个frame_callback函数可以说是整个算法的核心部分,每一帧的图片都会执行该函数。

4 YOLOV5算法
6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布不到50天。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种 one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。YOLO 一共发布了五个版本,其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
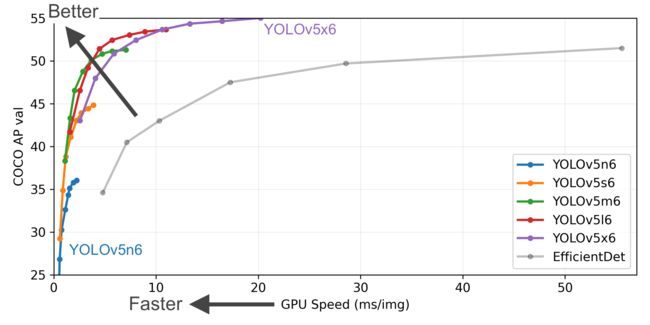
YOLOv5有4个版本性能如图所示:
4.1 网络架构图

YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
4.2 输入端
在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- Mosaic数据增强:Mosaic数据增强的作者也是来自YOLOv5团队的成员,通过随机缩放、随机裁剪、随机排布的方式进行拼接,对小目标的检测效果很不错

4.3 基准网络
融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
4.4 Neck网络
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。Yolov5中添加了FPN+PAN结构,相当于目标检测网络的颈部,也是非常关键的。


FPN+PAN的结构

这样结合操作,FPN层自顶向下传达强语义特征(High-Level特征),而特征金字塔则自底向上传达强定位特征(Low-Level特征),两两联手,从不同的主干层对不同的检测层进行特征聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
4.5 Head输出层
输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
对于Head部分,可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
①==>40×40×255
②==>20×20×255
③==>10×10×255

相关代码
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')
else:
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid