基于深度学习图像分割的墙体裂缝识别检测
直接上效果演示图:
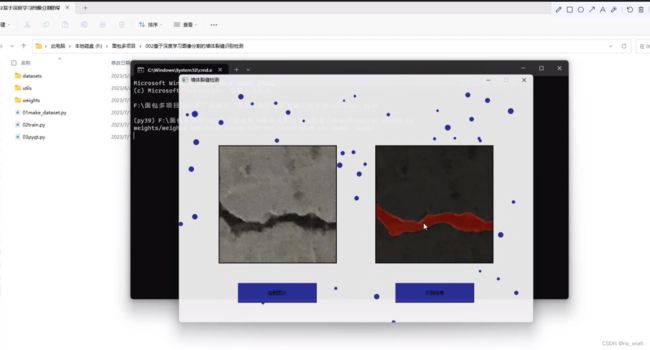
demo的演示视频和代码仓库看b站视频002期:
到此一游7758258的个人空间_哔哩哔哩_bilibili
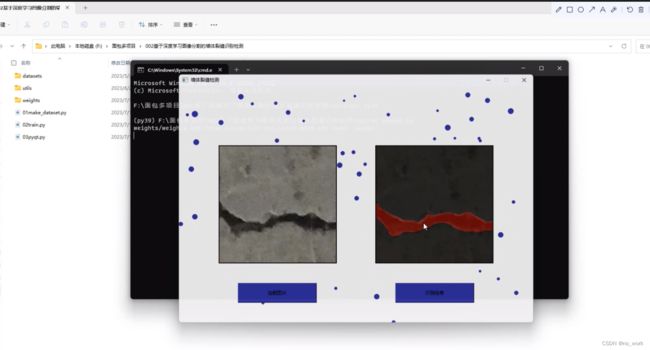
代码展示界面
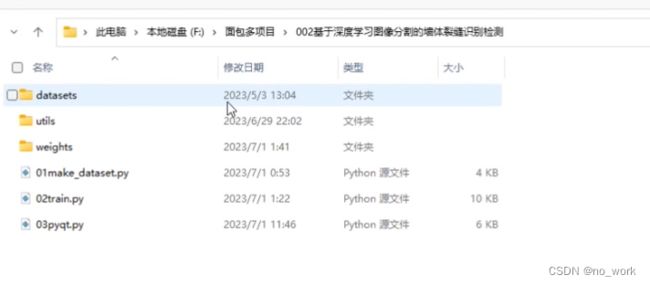
主要是01、02、03.py文件
运行01make_dataset.py文件能将图片数据转化成特定的格式。


自制数据集需要使用labelme工具对图片中裂缝部分进行打标,最好安装labelme==3.16.7环境
pip install labelme==3.16.7
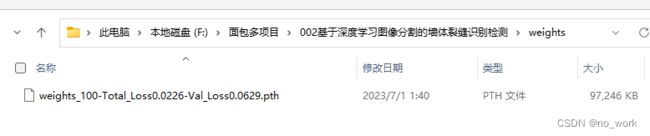
运行02train.py训练这些的图片数据集,训练好的模型保存在weights文件下。
运行03pyqt.py可以有一个可视化的交互界面,界面有两个按钮有两个显示图片框,背景有动态图,颜色每次加载都会显示不一样。
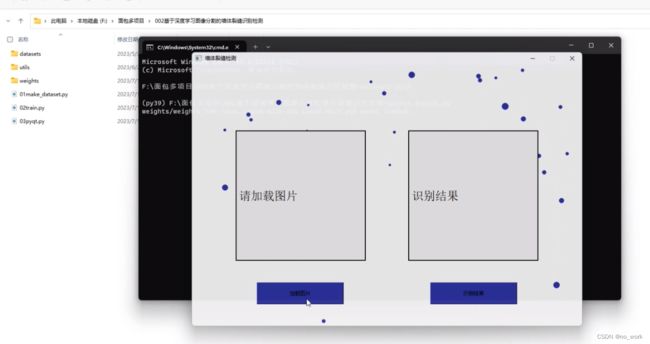
左侧图片点击加载感兴趣的图片,点击右侧按钮即可识别结果。
科普图像分割算法:
一般深度学习的图像分割算法包括:
Unet、mask-rcnn、PSPnet、yolov5-segment等等
Unet是一种常用于图像分割任务的卷积神经网络(Convolutional Neural Network,CNN)架构。它由Olaf Ronneberger、Philipp Fischer和Thomas Brox于2015年提出,并在医学图像分割领域取得了广泛应用。
Unet的名字来源于它的网络结构,它具有"U"字型的特征提取和上采样路径。该网络结构包含了一个对称的编码器(Encoder)和解码器(Decoder),中间通过跳跃连接(Skip Connections)进行特征融合。这种设计使得Unet在处理图像分割任务时能够同时具备全局信息和局部细节。
Unet的编码器部分由连续的卷积层和池化层组成,用于逐步提取图像的特征并降低空间维度。解码器部分则通过上采样操作和对应的卷积层来恢复图像的空间分辨率,并逐步重建分割结果。在解码器的每一层,通过跳跃连接将对应的编码器层的特征图与解码器层的特征图进行合并,从而保留了多尺度的特征信息。这有助于解决语义分割任务中的信息丢失和边界模糊等问题。
Unet的网络结构相对简单,而且适用于较小的数据集,因此在许多图像分割任务中都取得了良好的性能。它被广泛用于医学图像分割,如肺部分割、细胞分割等领域,也可以应用于其他领域的图像分割任务。随着深度学习的发展,基于Unet的改进和变种也不断涌现,进一步提升了图像分割的性能和效果。
Mask R-CNN(Mask Region-based Convolutional Neural Network)是一种用于图像实例分割任务的深度学习模型,是对Faster R-CNN模型的扩展。它由Kaiming He、Georgia Gkioxari、Piotr Dollár和Ross Girshick于2017年提出。
Mask R-CNN的设计目标是同时进行目标检测(Object Detection)和实例级别的语义分割(Instance Segmentation)。与传统的目标检测方法相比,Mask R-CNN能够为每个检测到的目标生成高质量的分割掩码,实现对目标的像素级别的精确分割。
Mask R-CNN的基本结构包含两个主要部分:区域建议网络(Region Proposal Network,RPN)和实例分割网络。RPN负责生成候选的目标区域,而实例分割网络则对这些候选区域进行分类、边界框回归和像素级分割。
具体而言,RPN通过在输入图像上滑动一个小的窗口来生成候选区域,并为每个窗口预测目标的边界框和目标性得分。这些候选区域经过筛选和非极大值抑制后,作为后续分割网络的输入。
实例分割网络采用了全卷积网络(Fully Convolutional Network)的结构,通过对候选区域进行RoI池化(Region of Interest Pooling)操作来提取固定尺寸的特征图。然后,该特征图被馈送到一系列卷积层和上采样层,同时进行目标分类、边界框回归和像素级分割掩码的预测。
通过联合训练目标检测和语义分割任务,Mask R-CNN能够在像素级别准确地识别和分割图像中的不同目标。这使得它在许多计算机视觉任务中都取得了显著的性能提升,如实例分割、物体识别、人体姿态估计等。
PSPNet(Pyramid Scene Parsing Network)是一种用于语义分割任务的深度学习模型,由Hengshuang Zhao、Jianping Shi、Xiaogang Wang和Xiaowei Zhou于2017年提出。
PSPNet的设计目标是实现对图像场景的像素级别语义分割。它通过利用金字塔池化(Pyramid Pooling)机制来获取多尺度的上下文信息,以便更好地理解图像中不同目标的语义信息和上下文关系。
PSPNet的基本结构包含两个关键组件:特征提取器和金字塔池化模块。
特征提取器通常是一个预训练的深度卷积神经网络(如ResNet、VGG等),它用于从输入图像中提取高级语义特征。
金字塔池化模块位于特征提取器之后,负责捕获多尺度的上下文信息。它通过将特征图分为多个不同尺度的区域,并在每个区域上进行池化操作来获取局部和全局的语义信息。不同尺度的池化特征被级联起来,并经过一系列卷积层进行特征融合和细化,最后生成与输入图像尺寸相同的语义分割结果。
通过利用金字塔池化模块,PSPNet能够有效地整合多尺度的上下文信息,使得在语义分割任务中更好地捕捉目标的语义信息和上下文关系。它在许多图像语义分割的挑战中取得了良好的性能,并且在准确性和效率上都具有竞争力。
需要注意的是,PSPNet是一种经典的语义分割模型,而随着深度学习的发展,还有其他的改进和变种模型涌现,可以进一步提升语义分割任务的性能和效果。