Windows下搭建TensorFlow-gpu2.3环境,训练测试keras-retinanet
Windows下搭建TensorFlow-gpu2.3环境,训练测试keras-retinanet
- 1. 安装GPU环境——cuda、cudnn
-
- 1.1 安装显卡驱动
- 1.2 安装cuda
- 1.3 安装cudnn
- 1.4 验证是否安装成功
- 2. 安装Python环境
-
- 2.1 安装conda虚拟环境
- 2.2 安装TensorFlow及keras
- 2.3 安装其他依赖项
- 2.4 进行keras-retinanet所需的编译
- 3. 训练测试keras-retinanet遇到的问题
-
- 3.1 训练时在第一个epoch停止
- 3.2 训练时GPU显存不够
- 3.3 测试时GPU显存不够
主要难点在于cuda、cudnn版本的选择及安装,TensorFlow-gpu与keras之间版本配合安装
各版本如下:
cuda_10.1.105_418.96_win10
cudnn-10.1-windows10-x64-v7.6.5.32
Keras 2.4.3
tensorflow-gpu 2.3.0
1. 安装GPU环境——cuda、cudnn
1.1 安装显卡驱动
Windows下的显卡驱动安装比较简单随意了,可以去NVIDIA网站下载驱动安装,也可以使用驱动软件直接检测安装。
安装完之后,打开控制台,输入
nvidia-smi
我笔记本是一张1060的显卡,会得到如下内容,即表示安装成功
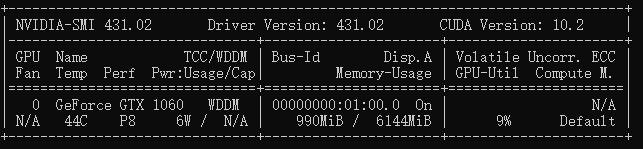
1.2 安装cuda
在选择cuda和cudnn版本时要慎重一下,因为最近新版的cudnn没有win64版本的,没深究为什么,这里我选择的是cuda10.1和cudnn7.6.5
cuda下载地址:https://developer.nvidia.com/cuda-toolkit-archive
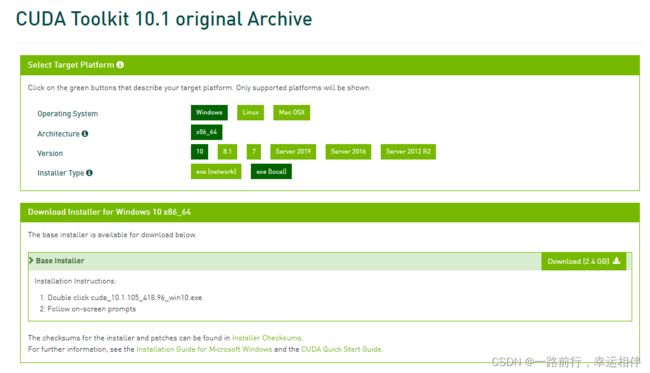
下载完有2个多G,之后一路默认安装即可,path环境也会自动配置好
1.3 安装cudnn
cudnn下载地址:https://developer.nvidia.com/rdp/cudnn-archive
要登录账户,没有的话就注册一个就好

下载完是一个安装包,解压后将对应文件复制到cuda相应的文件夹下
有三个文件:cudnn64_7.dll、cudnn.h、cudnn.lib
cuda如果是默认安装的话,路径为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
将上述三个文件放到对应的目录下即可:

1.4 验证是否安装成功
-
打开控制台,输入
nvcc -V

- 通过NVIDIA提供的 deviceQuery.exe 和 bandwidthTest.exe 来查看GPU的状态,两者均在安装目录的 extras\demo_suite文件夹中
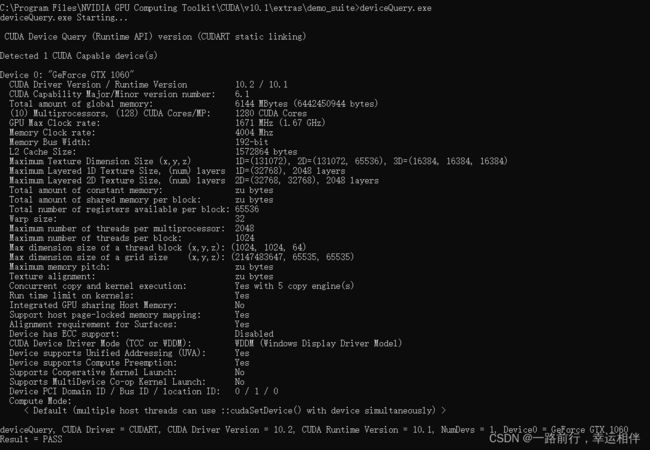
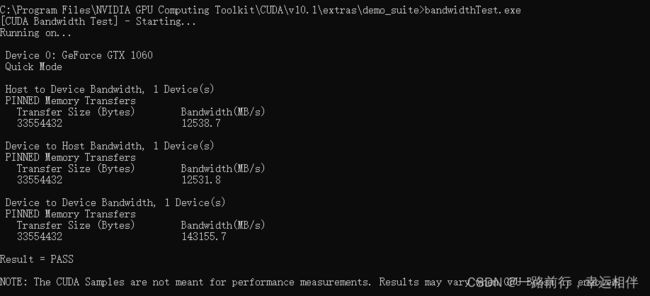
2. 安装Python环境
2.1 安装conda虚拟环境
详细内容可参考这篇文章:Windows下搭建TensorFlow2环境
- 创建虚拟环境
conda create -n TensorFlow-gpu python=3.7
- 进入虚拟环境
conda activate TensorFlow-gpu
2.2 安装TensorFlow及keras
TensorFlow与keras之间的版本对应关系还是比较重要的,不匹配会造成各种问题
这里选择的版本是Keras2.4.3与tensorflow-gpu2.3.0
-
安装tensorflow-gpu2.3.0
pip install tensorflow-gpu==2.3.0 -i https://mirrors.aliyun.com/pypi/simple/ -
安装Keras2.4.3
pip install keras==2.4.3 -i https://mirrors.aliyun.com/pypi/simple/
2.3 安装其他依赖项
keras-retinanet的地址如下:https://github.com/fizyr/keras-retinanet
其中requirements.txt文件中包含了所需依赖:
cython keras-resnet==0.2.0 git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI h5py keras matplotlib numpy>=1.14 opencv-python>=3.3.0 pillow progressbar2 tensorflow>=2.3.0由于我们已经安装好指定版本的TensorFlow和keras,所以将其在requirements.txt中删除
cython keras-resnet==0.2.0 git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI h5py matplotlib numpy>=1.14 opencv-python>=3.3.0 pillow progressbar2然后直接在该目录下执行
pip install . --user或者也可以单独pip安装
2.4 进行keras-retinanet所需的编译
在keras-retinanet目录下执行
python setup.py build_ext --inplace
是因为源码中有cpx文件,需要根据当前环境进行编译
3. 训练测试keras-retinanet遇到的问题
我在安装环境时遇到了很多问题,但大多都是与版本相关,所以这里不做记录,按照上边的环境进行安装后,应该不会出现问题。
3.1 训练时在第一个epoch停止
log中显示如下:
WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches (in this case, 500000 batches). You may need to use the repeat() function when building your dataset.
参考如下:
【记录】训练keras-retinanet提前结束
Training stops at epoch 1 #1462
是因为–steps这个参数必须完全等于训练图像的总数/batch_size,或者设置为默认值None,让tensorflow自动找出它
解决方法:在train.py文件中找到–steps,把原来的10000改为None
3.2 训练时GPU显存不够
TensorFlow2版本加入如下代码
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
tf.compat.v1.keras.backend.set_session(tf.compat.v1.Session(config=config))
3.3 测试时GPU显存不够
- 禁用GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
- 在预测时指定CPU
with tf.device('/cpu:0'):