强化学习(EfficientZero)(应用于图像和声音)
目录
摘要
1.背景介绍
2.MCTS(蒙特卡洛树搜索)(推理类模型,棋类效果应用好,控制好像也不错)
3.MUZERO
4.EfficientZero(基于MUZERO)
展望
参考文献
摘要
在文中,基于传统强化学习在数据训练方面的局限性,引入了EfficientZero,并和常用的强化学习算法在Atari游戏中,进行性能的对比,证明EfficientZero的效果,之后简单介绍了EfficientZero算法所集合的基础算法,MCTS(蒙特卡洛树搜索),MUZERO,最后介绍了MUZERO的不足,并说明EfficientZero想对应的解决方案,以及一些展望。
1.背景介绍
应用领域局限性:强化学习主要被应用于游戏中,像推荐系统,自动驾驶,交易系统和现实交互较多的领域没有被应用。

局限性原因:本质还是因为数据的问题,比方说阿尔法GO,训练数据等于在真实世界一个人用将近2w年,完成66Million局的游戏,才足以训练,而在模拟世界仅需要两组服务器,几天的时间,这种数据在推荐系统,自动驾驶,交易系统中是无法实现的。替代的方法是模拟这几种应用场景的环境,在模拟环境中训练模型,最后将模型应用在真实环境中,再根据真实世界数据,微调。

进一步理解局限原因:上面已经论述,模拟器可以解决数据问题,但为什么上述领域依然没用强化学习,问题在于,有些环境的模拟器很难被构建,像蛋白质结构,有些模拟器运行速度并不比现实世界快太多,主要是高仿真的环境。像下面想复现一个炒菜过程,就十分复杂。
为了解决这个问题,EfficientZero应运而生:目的就是解决强化学习需要太多实例的问题,提高数据效率,在高维输入图像,音频,有很好的效果。
EfficientZero怎么解决数据量的问题:首先我们看一下EfficientZero需要的数据量,在传统强化学习中Atari一般需要1000小时的数据量,大概是200 million frames,但这种小游戏,一般来说,人类花费2个小时,就能很熟练了,作为一个交互算法,我们希望也只用两个小时的训练量,来达到一个好的效果,所以只取原数据量1000小时200 million frames的1/500的,也就是2小时的400kframes。
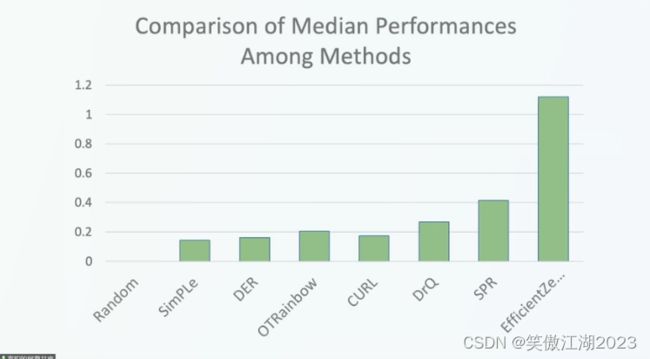
进一步看一下,下图右的结果:首先EfficientZero两个小时的训练量结果明显高于人类,更厉害的是她高于DQN用1000小时训练的结果。大大增加了强化学习在其他应用场景下落地的可能。


再进一步和其他算法性能对比:1代表的是正常人类的水平,可以看出EfficientZero明显高于人类水平,而其他算法远低于人类水平,再思考一下为什么深度学习能在视觉,文本等领域活动广泛应用,因为他们的准确率,或者说场景应用效果已经远高于正常人类的水平,所以可以期待EfficientZero能给强化学习领域带来的变革。
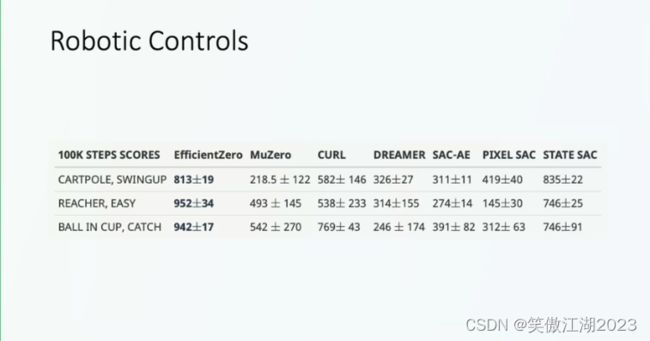
在机器人控制方面:目前EfficientZero主要用于离散空间,还没专门解决连续空间的问题(正在做)。对于机器人的连续动作,进行离散化进行了测试,即使着这样也超过同类算法很多。
2.MCTS(蒙特卡洛树搜索)(推理类模型,棋类效果应用好,控制好像也不错)
首先介绍一下MCTS,因为EfficientZero用了MCTS。
基本:阿尔法狗下棋的时候,做决策的不是策略网络和价值网络,而是蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。训练好的策略网络和价值网络均能单独地直接做决策。MCTS不需要训练,也可以单独地直接做决策。在阿尔法狗中,训练策略网络和价值网络的目的是辅助MCTS,降低MCTS的深度和宽度。在机巧围棋中,除阿尔法狗之外,还分别集成了策略网络、价值网络和蒙特卡洛落子策略,可以任意更改黑白双方的落子策略,查看不同落子策略之间的效果。
思想:人类玩家下围棋时,通常会往前看几步,越是高手,看的越远。与此同时,人类玩家不会分析棋盘上所有不违反规则的走法,而只会针对性地分析几个貌似可能的走法。假如现在该我放置棋子了,我会这样思考:现在貌似有几个可行的走法,如果我的动作是 t = 234,对手会怎么走呢?假如对手接下来将棋子放在a = 30 的位置上,那我下一步动作a 1 应该是什么呢?
人类玩家在做决策之前,会在大脑里面进行推演,确保几步以后很可能会占优势。同样的道理,AI下棋时候,也应该枚举未来可能发生的情况,从而判断当前执行什么动作的胜算更大。这样做远好于使用策略网络直接算出一个动作。
MCTS的基本原理就是向前看,模拟未来可能发生的情况,从而找出当前最优的动作。这种向前看不是遍历所有可能的情况,而是与人类玩家类似,只遍历几种貌似可能的走法,而哪些动作是貌似可行的动作以及几步之后的局面优劣情况是由神经网络所决定的。阿尔法狗每走一步棋,都要用MCTS做成千上万次模拟,从而判断出哪个动作的胜算更大,并执行胜算最大的动作。
3.MUZERO
基本:Muzero建立在alphaZero算法的搜索能力以及基于搜索的策略迭代算法之上,同时联合了一个学习model在训练的过程中,极大的扩展了该学习算法的应用场景。
它主要是将mentor Calor Tree Search算法、hidden state value equivalence思想,以及Deep Neural Network 相结合,创造一个更加general的算法来进行强化学习的训练,一句话总结就 是 Muzero算法是一个不需要environment dynamic先验,更加general的model-based的强化学习算法。
hidden state value equivalence思想:强化学习一直以来存在的一个大问题就是如何处理training space与 application space的状态的offset问题,之前就有很多人提出利用transfer learning 或者 Domain Adaptation来解决两个space之间的offset,但是hidden state value equivalence的思想是从state本身出发,在训练整个网络的时候并不是直接用训练场景的原始state作为输入,而是把原始的state通过一个神经网络进行转换,变换成hidden state(把环境状态用神经网络表示)。举个例子,人在实验室里面或者一个工厂里面走路(planning)的时候能够保证自己不碰撞到任何障碍物,而实验室的场景和工厂大不相同,也就是说真正决定人不会碰撞到障碍物不是一个具体场景,更像场景中一个抽象的结构信息,这里的hidden state就可以类比成这个抽象的结构信息。这样做的好处显而易见,就是能够提高网络的泛化能力以及网络的收敛性。只要hidden state对应的value和真实场景中对应的value是一致的,那么我们就能说hidden state可以在该任务中替代真实 state。
问题:MUZERO需要很大的数据量200M frames,41天数据量。而且不能处理复杂环境的问题,像自动驾驶,机器人控制。

4.EfficientZero(基于MUZERO)
MUZERO不足1:转移函数(transformation function)学习不充分,或者说转移函数学习时所受到的监督不够,因为转移函数学习是在价值函数(value function)和策略函数(policy function)监督下学习的,但这个两个函数只是一个22维的向量,属于弱监督,达不到最好的监督效果。
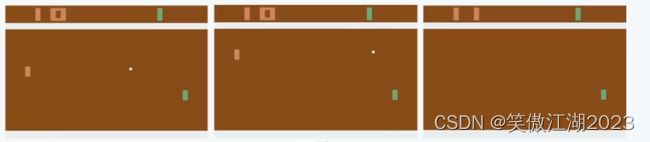
MUZERO不足2:model aliasing problem,以下图为例解释,如下图所示,一个白板和一个绿板在打一个白球,模型需要去学习,白球所有可能出界的具体位置,而在现实世界人类并不会关心,这个球具体是从那个位置出去的,人类只会关心,它有没有出去,从这个角度看,MUZERO在这一块构造的过于复杂。
MUZERO不足3:off-policy error when limite data,可以这样理解,在有限的数据中,价值函数计算有很大的off-policy error,理想情况下当前的目标值是由policy function求得,但在数据很少时会重复利用数据,这时得到的目标值,可能来源于老的数据。
解决1:不足1采用自监督解决。 使用一个consistency来学习环境如何变化的信息,或者说学习transformation function。从下图左(可放大界面查看)流程图去理解,在训练时输入一个Ot,通过representation(表征网络)得到st(状态),at(动作)再输入next-state网络得到预测的st+1,也就是下一个环境状态(因为想学习的是环境转移函数,或者说最好的环境转移率),同时在真实环境中输入Ot+1得到真实的st+1最后通过,对比网络,不断拉近预测和真实的差值,这样的好出在于,因为从时序出发,我们一次可以进行上千次时序的输入,而MUZERO仅22维,达到了一个强监督的效果。
从下图右直观理解一下consistency带来的效果:
第一行第一列表示输入,第二列到第六列表示第一步到第五步的预测效果。第一行每一步是最理想的效果。
第二行没有用consistency,可以看出第一步就糊了。
第三行用来consistency,可以看出,第五步依然有不错的效果,最起码保留了基本结构。


解决2:对于上面打球游戏,可以理解为MUZERO想得到每一步最好的结果,但对于人类而言,我们只想知道最终谁赢谁输,所以MUZERO把问题复杂化了,而EfficientZero考虑从最终得分叠加去得到结果即可,所以基于LTSM(长短期记忆网络)去解决这个问题。
长短期记忆网络 LSTM(long short-term memory):是 RNN 的一种变体,其核心概念在于细胞状态以及“门”结构。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去。你可以将其看作网络的“记忆”。理论上讲,细胞状态能够将序列处理过程中的相关信息一直传递下去。因此,即使是较早时间步长的信息也能携带到较后时间步长的细胞中来,这克服了短时记忆的影响。信息的添加和移除我们通过“门”结构来实现,“门”结构在训练过程中会去学习该保存或遗忘哪些信息。
进一步对比MUZERO(单步预测)和EfficientZero(多步预测)的效果:从下图可以看出在训练集上单步预测好于多步预测,但在验证集的泛化效果,多步预测好于单步预测。我的理解是,世事变化无常,不可能每一步预测的都一定能实现,反而多步预测得到总的结果,会有更好的效果,这里用resnet可以对比理解,resnet解决的就是,多层网络某一层效果不好,直接舍弃,但我保证最后的结果不差。

解决3:MUZERO用的是第一个V,但数据量骤减之后第一个V已不在适用,EfficientZero使用第二个V构造价值。将原V中的k-1中的k用第二个V中l-1的自适应量l表示。

展望
1.环境不确定性目前未处理,是一个方向。
2.作者提出一个观点,训练应该在真实环境下,但真实环境下需要训练上万次成本就很高,所以作者认为一个厉害的强化学习算法可以训练几十次就达到好的效果,比方说EfficientZero。
参考文献
1.青源 LIVE 第 29 期 |使用有限的数据掌握Atari游戏_哔哩哔哩_bilibili
2.蒙特卡洛树搜索(MCTS)_RuizhiHe的博客-CSDN博客
3.如何理解deepMind 团队的Muzero算法_OsgoodWu的博客-CSDN博客
4.LSTM 简介_Lemon_Yam的博客-CSDN博客
5(详细).清华高阳:EfficientZero,一种采样高效的强化学习算法|报告详解 - 知乎