CompletableFuture生产中使用问题
CompletableFuture生产中使用问题
-
- 1 背景
- 2 测试
- 3 原因
- 4. 总结
1 背景
接到一个任务,需要优化下单接口,查看完业务逻辑后发现有一些可以并行或异步查询的地方,于是采用CompletableFuture来做异步优化,提高接口响应速度,伪代码如下
//查询用户信息
CompletableFuture<JSONObject> userInfoFuture = CompletableFuture
.supplyAsync(() -> proMemberService.queryUserById(ordOrder.getId()));
//查询积分商品信息
CompletableFuture<JSONObject> integralProInfoFuture = CompletableFuture
.supplyAsync(() -> proInfoService
.getProById(ordOrderIntegral.getProId()));
//查询会员积分信息
CompletableFuture<Integer> integerFuture = CompletableFuture
.supplyAsync(() -> proMemberService
.getTotalIntegralById(ordOrder.getOpenId()));
2 测试
优化完后,测试执行速度2000ms下降到600ms,经过本地和测试环境测试后,上线生产,
生产日志打印出来的线程号,却不是从CompletableFuture的默认线程池中取出的.
生产日志
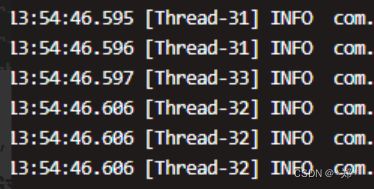
本地和测试环境打印日志
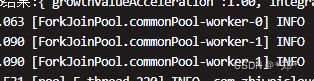
日志中发现生产环境为每个线程创建了一个全新的线程,如果并发太高,会存在线程资源被耗尽的可能性,从而导致服务器崩溃.
3 原因
翻阅CompletableFuture的源码后,终于找到了原因: 是否使用默认ForkJoinPool线程池和机器配置有关.
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) {
return asyncSupplyStage(ASYNC_POOL, supplier);
}
点击进入asynPool
//是否使用默认线程池的判断依据
private static final Executor ASYNC_POOL = USE_COMMON_POOL ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
//useCommonPool的来源
private static final boolean USE_COMMON_POOL =
(ForkJoinPool.getCommonPoolParallelism() > 1);
CompletableFuture是否使用默认线程池,是根据这个useCommonPool值来判断的,值为true使用
public static int getCommonPoolParallelism() {
return COMMON_PARALLELISM;
}
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode,
int corePoolSize,
int maximumPoolSize,
int minimumRunnable,
Predicate<? super ForkJoinPool> saturate,
long keepAliveTime,
TimeUnit unit) {
checkPermission();
int p = parallelism;
if (p <= 0 || p > MAX_CAP || p > maximumPoolSize || keepAliveTime <= 0L)
throw new IllegalArgumentException();
if (factory == null || unit == null)
throw new NullPointerException();
this.factory = factory;
this.ueh = handler;
this.saturate = saturate;
this.keepAlive = Math.max(unit.toMillis(keepAliveTime), TIMEOUT_SLOP);
int size = 1 << (33 - Integer.numberOfLeadingZeros(p - 1));
int corep = Math.min(Math.max(corePoolSize, p), MAX_CAP);
int maxSpares = Math.min(maximumPoolSize, MAX_CAP) - p;
int minAvail = Math.min(Math.max(minimumRunnable, 0), MAX_CAP);
this.bounds = ((minAvail - p) & SMASK) | (maxSpares << SWIDTH);
this.mode = p | (asyncMode ? FIFO : 0);
this.ctl = ((((long)(-corep) << TC_SHIFT) & TC_MASK) |
(((long)(-p) << RC_SHIFT) & RC_MASK));
this.registrationLock = new ReentrantLock();
this.queues = new WorkQueue[size];
String pid = Integer.toString(getAndAddPoolIds(1) + 1);
this.workerNamePrefix = "ForkJoinPool-" + pid + "-worker-";
}
4. 总结
- 使用CompletableFuture一定要自定义线程池
- CompletableFuture是否使用默认线程池和机器核心数有关,核心数减1大于1才会使用默认线程池,否则为每个任务创建一个线程.
- 即使服务器核心大于2使用默认线程池也可能会因为线程池中线程过少,导致线程大量等待,降低吞吐率,甚至拖垮服务器
- ForkJoinPool使用于CPU密集型的任务(计算).
线程池大小与处理器的利用率之比可以使用下面的公式进行估算公式:
N threads = N CPU * U CPU * (1 + W/C)
其中:
-
NCPU 是处理器的核的数目,可以通过 Runtime.getRuntime().availableProce-
ssors() 得到 -
U CPU 是期望的CPU利用率(该值应该介于0和1之间)
-
W/C是等待时间与计算时间的比率
一般的设置线程池的大小规则是:
-
如果服务是cpu密集型的,设置为电脑的核数
-
如果服务是io密集型的,设置为电脑的核数*2