【Linux】-进程概念及初始fork
作者:小树苗渴望变成参天大树
作者宣言:认真写好每一篇博客
作者gitee:gitee✨
作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!

文章目录
- 前言
- 一、进程标识符
-
- 1.1认识第一个系统调用接口
- 1.2 第二个系统调用接口fork
- 二、总结
前言
上篇Linux我们讲解了什么是进程,从硬件,在到软件,再到宏观上讲解了操作系统是怎么管理我们软硬件的,大家应该已经有了一定的认识和了解,今天我们就对进程展开来讲点东西,我们的在Windows这样的操作系统是使用PCB来这个的结构体形成的结构去管理的,但在Linux上我们是task_struct结构体去管理我们的软硬件的,那我们结构体里面到底有什么,在上节课我们只是把具体的属性给大家展示了,但是并不知道什么意思,今天我们先介绍其中一点,话不多说,我们开始进入正文。
task_ struct内容分类
标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据。
I/O状态信息: 包括显示的I/O请求分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息
fork一会再说,先做一个知识铺垫。
一、进程标识符
我们上篇的最后讲解了怎么去看一个进程,我们来写一个死循环的程序,防止他很快就结束进程,不方便我们去查看他的进程
#include第一:通过proc这个文件夹去看,但是这种方法不知道对应的是哪个进程。

第二种:通过命令查看ps ajx | head -1 && ps ajx | grep proc或者ps ajx | head -1 && ps ajx | grep proc | grep -v grep

我们的进程task_struct就是一个结构体类型的结点,ps的作用实际就是在遍历这个结构,通过grep把找到的过滤出来。我们发现一个进程有这么多个属性,我们值需要了解其中两个,其余的不重要,一个是PID(进程id),一个是PPID(父进程id),后面会介绍到这两者有什么关系
1.1认识第一个系统调用接口

通过计算机层状结构图,我们知道了系统调用接口是直接对接操作系统的,系统调用接口也是一个函数,一会学习的两个接口就是来查看PID和PPID的,我们来看代码:
#include我们来写一个命令当成监视窗口:while :; do ps ajx | head -1 ; ps ajx | grep proc | grep -v grep ; sleep 1 ; done 这是每个1秒显示一个进程信息。
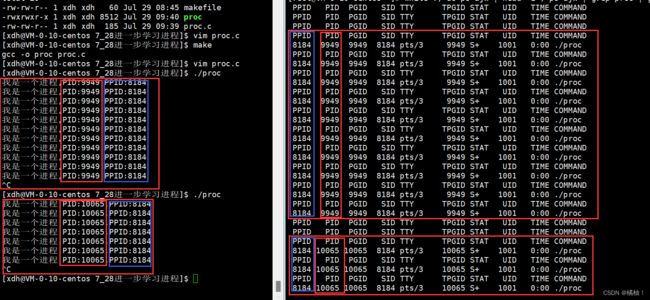
大家看到我们通过系统调用接口也把我们的id给获取到了。
大家应该会发现,我将自己写的程序运行了两次,PID两次都不同,PPID却是相同的,这是为什么呢?我们来看看这个程序PPID是什么。

这个程序的PPID是我们bash程序的PID,bash不就是我们之前说的王婆,这就是一个外壳程序,命令行解释器,是我们每次登录的时候,Linux操作系统自动就会运行这个bash程序形成了一个进程,我们写的程序就是在这个进程创建的基础下跑,当我们再次登录这个bash进程的PID又会发生变化,而我们自己写的程序每次运行的PID不一样是正常的,就好比你刚进校的学号,每个人第二次考上进去的学号都是不一样的。
通过上面的解释,操作系统是不会让你直接去在他的进程上创建子进程去运行的,是通过bash进程,我们写的程序就是他的子进程,在bash进程下创建子进程去跑的,为什么要这么做,接下来我们讲到fork就可以来解决我刚才说的问题
1.2 第二个系统调用接口fork
这个接口就可以让我们更好的认识父子进程的关系,以及上面的操作是怎么做到的,我们先来看一个例子:

大家看到我们加了fork之后,居然打印了两次,这个例子还不能说明什么,我们来看看文档
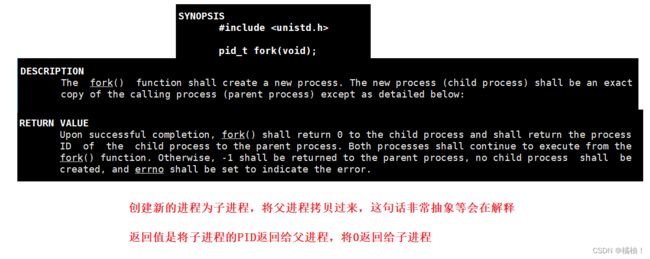
这个返回值看上去非常的抽象,是要返回两个值??太不可思议了,我们再来看一个例子:

我们看到两个死循环都走起来了,这下更不可思议了。一个程序怎么会执行两个死循环语句呢?接下来我将通过四个问题来带大家解决疑惑:
-
为什么fork需要给子进程返回0,给父进程返回子进程的PID
(1)为什么要返回不同的值,是为了区分让不同的执行流,去执行不同的代码块,就好比上面的代码。
(2)每个父进程可以有好多个子进程,子进程只有一个父进程,所以父进程需要知道子进程的PID来唯一标识要控制哪个子进程去执行。而返回0是为了标识子进程,子进程通过getppid就可以找到父进程 -
fork干了什么事情?
这下大家应该知道为什么要返回两次,是如何做到分流的吧,但是fork是一个函数,怎么做到返回两次呢??
- 一个函数是如何做到返回两次的??

写时拷贝:
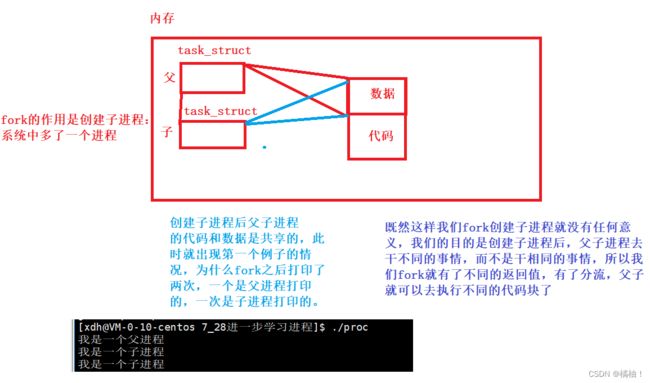
**大家应该知道我们在Windows上,我们启动了许多个软件,但其中一个软件挂掉了会不会影响其他软件,答案是不会的,所以在任何平台上,进程在运行的时候,是具有独立性的**,那我们刚才说到fork他也是创建一个子进程,在上面我们说到,父子进程的代码和数据是共享的,那么就会导致如果子进程修改了数据,那么可能会影响到我父进程的运行,此时就不符合进程具有独立性的思想,想问一下大家,代码共享而数据不共享是不是具有独立性:答案是具有,因为你的代码最终操控都是数据,只要操作的数据不是一样的就不会影响到其他进程的运行,所以防止这种事情的发生,我们父子进程的代码时共享,数据不共享,如下图:
将父进程的数据拷贝到新的空间个给子进程自己玩,就算子进程修改了数据也是他那一块空间的数据,不会影响到父进程对应的数据,就实现了进程之间的独立性。
此时又面临一个问题:当内存空间严重不足时,我们父进程还是把所有的数据都拷贝到子进程的数据空间里吗?如果子进程没有使用这些数据,那么不就造成资源浪费了吗??内存要想办法给自己节省空间,所以此时就引入了写时拷贝这个概念,我们的父子进程一开始还是指向同一块数据的,如果子进程想要修改数据,内存在给其分配空间,将要修改的数据先拷贝到新空间,然后你在修改,这样就做到了用多少拷多少。
这就好比C++说的深浅拷贝,你要想看看数据,指向同一块空间也无所谓,但你要想修改内容,我给你在开辟一块空间,你修改了不能影响到我原来的数据。


有了上面的写时拷贝,我们再来谈谈fork函数返回值的问题,上面只是说到怎么返回两次的,父子进程分别去调用return就可以了,那怎么做到返回不同的值,原因就是return语句是写入,写入就要修改数据,此时内存就会将返回的数据拷贝到子进程的新数据区中,然后让子进程进行修改在返回,所以我们会返回两个同的值。
通过上面的例子,我们发现bash进程也应该是操作系统fork出来的子进程,那我们的操作系统为什么要这么做,因为我们的操作系统也是一款软件,在内存中也有自己的进程,他不相信任何用户,所以他需要创建子进程,用户想要修改数据,修改的是子进程指向的数据空间,修改了不会影响我操作系统进程指向的数据空间,这样就保证了操作系统的安全性
相信此时大家对fork的理解又加深了,并且了解父子进程的关系了吧。
- 一个变量是如何接收两个不同的值
这个需要使用到我们进程地址空间的知识,但是此时已经不影响我们对fork以及父子进程的理解了,而且也知道fork的作用以及目的。
如果父子进程被创建好,fork()往后,哪个进程先运行呢?
谁先运行是由调度器去决定,调度器有自己的调度算法,这个在后面的博客会介绍到,他是怎么去调度的,目前我们上面这个问题是不知道答案的,不确定谁先被执行。
通过上面四个问题的解释,我来给fork做一个小总结:
- fork有两个返回值
- 父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
- fork 之后通常要用 if 进行分流
二、总结
通过这节的学习,我们知道了fork这个系统接口的用法,以及作用,可以说这个接口对我们的学习是又很大的帮助,可以使我们分别去做不同的事,也让我们知道函数还有又这样的功能,是我们的认知又提高了一个档次,接下来的一篇我还是介绍task_struct里面的属性-进程状态。一起来期待吧
