SQL项目实战:银行客户分析
大家好,本文将与大家分享一个SQL项目,即根据从数据集收集到的信息分析银行客户流失的可能性。这些洞察来自个人信息,如年龄、性别、收入和人口统计信息、银行卡类型、产品、客户信用评分以及客户在银行的服务时间长短等。对于银行而言,了解如何留住客户比寻找其他客户更有利。
客户流失是指客户或顾客的流失。公司通常将其作为关键业务指标之一,因为恢复的长期客户对公司的价值远远高于新招募的客户。客户流失有两种类型:自愿流失和非自愿流失。自愿流失是由于客户决定转向其他公司或服务提供商,而非自愿流失则是由于客户搬迁到长期护理机构、死亡或搬迁到较远的地方等情况造成的。
本文将集中讨论自愿流失,因为它可能是由于公司与客户关系中公司可以控制的因素造成的,例如如何处理账单互动或如何提供售后帮助。
数据集

本文使用的是customer_churn_records表,该表包含多列,customerid是表的主键。
-
RowNumber:对应记录(行)编号
-
CustomerId:客户的ID编号
-
Surname:客户的姓氏
-
CreditScore:客户信用行为预测值
-
Geography:客户所在地
-
Gender:客户的性别信息
-
Age:客户的年龄信息
-
Tenure:客户在银行的使用年限
-
Balance:客户账户中的余额信息
-
NumOfProducts:客户购买的产品数量
-
HasCrCard:客户是否拥有信用卡
-
IsActiveMember:客户是否处于活跃状态
-
EstimatedSalary(估计工资):客户的估计工资金额
-
Exited:客户是否离开银行
-
Complain:客户是否有投诉
-
Satisfaction Score:客户对银行的满意度评分
-
Card Type:客户持有的银行卡类型
-
Points Earned:客户使用信用卡获得的积分
# 显示表中的列 = customer_churn_records
q='''
SELECT * FROM customer_churn_records
'''
df = pd.read_sql(q,engine_postgresql)
df.head()
查询客户流失率
导入软件包:
import psycopg2 # PostgreSQL数据库适配器
import pandas as pd # 用于分析数据
from sqlalchemy import create_engine # 促进Python程序与数据库之间的通信首先,本文根据已退出的列计算有多少客户流失。
# 统计是否流失/退出的客户总数
q='''
WITH temp_churn AS(
SELECT exited,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
COUNT(exited) as Total
FROM temp_churn
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()
可以发现在10000名客户中,有近20%从银行退出或流失。尽管这个数字并不算很大,但如果现在还不能解决这个问题,它可能会增长得更多。
现在,本文将从活跃客户、性别、人口统计、年龄、临时工龄、信用分数、产品数量、满意度分数、投诉、是否有信用卡、卡类型、已获积分、预估薪资和余额等多个方面来检查客户流失状况的类型。
# 统计有多少活跃客户流失
q='''
WITH temp_isactivemember AS(
SELECT exited,
CASE
WHEN isactivemember = 1 THEN 'Active'
ELSE 'Not Active'
END AS isactivemember
from customer_churn_records
)
SELECT isactivemember,
COUNT (CASE WHEN exited = 1 THEN 1 END) AS Churn,
COUNT (CASE WHEN exited = 0 THEN 1 END) AS Not_Churn
FROM temp_isactivemember
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df
# 根据性别计算是否流失/退出的客户总数
q='''
SELECT gender,
COUNT(gender) as Total,
COUNT(case when exited = 1 then 1 end) as Churn,
COUNT(case when exited = 0 then 1 end) as Not_churn
FROM customer_churn_records
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()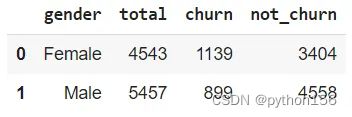
# 根据人口统计数据计算流失客户的数量
q='''
SELECT geography,
COUNT (CASE WHEN exited = 1 THEN 1 END) AS Churn,
COUNT (CASE WHEN exited = 0 THEN 1 END) AS Not_Churn
FROM customer_churn_records
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df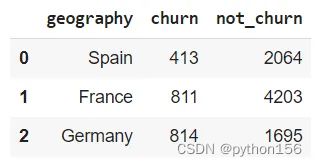
#根据年龄组计算流失客户的数量
q='''
SELECT
CASE
WHEN age <= 20 THEN 'Group <= 20'
WHEN age >= 21 AND age <= 40 THEN 'Group 21-40'
WHEN age >= 41 AND age <= 60 THEN 'Group 41-60'
ELSE 'Group > 60'
END AS age_category,
COUNT(CASE WHEN exited = 1 then 1 end) as Churn,
COUNT(CASE WHEN exited = 0 then 1 end) as Not_Churn
FROM customer_churn_records
GROUP BY 1
ORDER BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df
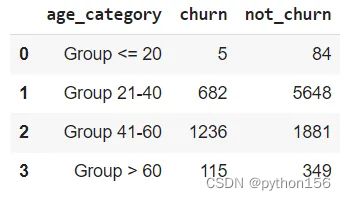
# 根据他们成为客户的时间计算是否流失/退出的客户总数
q='''
WITH temp_tenure AS(
SELECT tenure,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
AVG(tenure) as Average_tenure
FROM temp_tenure
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()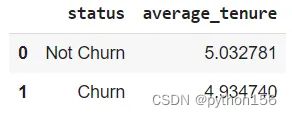
# 根据客户使用银行产品的数量,计算有多少客户流失
q='''
WITH temp_bankprod AS(
SELECT numofproducts,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
AVG(numofproducts) as avg_numofproducts
FROM temp_bankprod
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()
# 根据客户 对银行的满意度得分的平均得分,计算有多少客户流失
q='''
WITH temp_satisfaction AS(
SELECT satisfaction_score,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
AVG(satisfaction_score) as satisfaction_level
FROM temp_satisfaction
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()
# 根据客户的投诉量,统计有多少客户流失
q='''
WITH temp_complain AS(
SELECT complain,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
COUNT(complain) as complain
FROM temp_complain
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()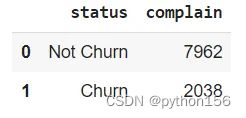
# 根据客户是否拥有信用卡计算有多少客户流失
q='''
WITH temp_hascrcard AS(
SELECT hascrcard,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
COUNT (CASE WHEN hascrcard = 1 THEN 1 END) AS has_creditcard,
COUNT (CASE WHEN hascrcard = 0 THEN 1 END) AS no_creditcard
FROM temp_hascrcard
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df
# 根据客户的预估工资计算有多少客户流失
q='''
WITH temp_salary AS(
SELECT estimatedsalary,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
AVG(estimatedsalary) as avg_salary,
MAX(estimatedsalary) as max_salary,
MIN(estimatedsalary) as min_salary
FROM temp_salary
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()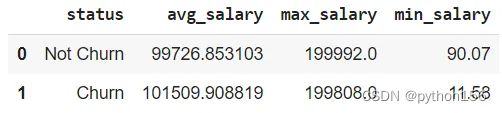
# 根据客户的银行存款余额计算有多少客户流失
#(平均、最高、最低)
q='''
WITH temp_balance AS(
SELECT balance,
CASE
WHEN exited = 1 THEN 'Churn'
ELSE 'Not Churn'
END AS STATUS
from customer_churn_records
)
SELECT STATUS,
AVG(balance) as avg_balance,
MAX(balance) as max_balance,
MIN(balance) as min_balance
FROM temp_balance
GROUP BY 1
'''
df = pd.read_sql(q,engine_postgresql)
df.head()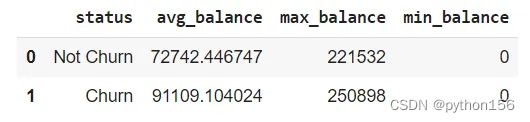
结论
根据上述问题,有一些类别可以帮助确定哪些方面会真正影响客户流失。不管客户在银行停留了多长时间,他们仍然有可能流失,或者说,客户的银行账户上有相当数量的存款,他们仍然有可能流失。
通过分析发现,41至60岁年龄段的客户比其他年龄段的客户更容易流失。为了解决这个问题,银行可以集中精力创造或提升产品和服务,以帮助吸引和维护特定年龄段的客户,比如为年龄较大的客户提供更流畅的服务和最短的排队时间。
持有信用卡的客户往往不会流失,而是会继续留在银行。银行最好通过各种促销活动说服更多的客户申请信用卡,这取决于客户细分,可根据客户的卡种(钻石卡、白金卡、金卡、银卡)、性别、年龄、支出和人口分布进行细分。
留存客户和流失客户的满意度得分有点令人担忧 [ 3.017960 / 2.997547 ],银行需要进行评估,以保持流失客户和留存客户之间的满意度得分差距,并保持活跃客户,因为活跃客户流失的可能性较低。