cuda c权威编程指南_GPU加速03:多流和共享内存—让你的CUDA程序如虎添翼的优化技术!
我和滴滴云有一些合作,没有GPU的朋友可以前往滴滴云上购买GPU/vGPU/机器学习产品,记得输入AI大师码:1936,可享受9折优惠。GPU产品分时计费,比自己购买硬件更划算,请前往滴滴云官网 http://www. didiyun.com 购买。
本文为英伟达GPU计算加速系列的第三篇,前两篇文章为:
- AI时代人人都应该了解的GPU知识:主要介绍了CPU与GPU的区别、GPU架构、CUDA软件栈简介。
- 超详细Python Cuda零基础入门教程:主要介绍了CUDA核函数,Thread、Block和Grid概念,内存分配,并使用Python Numba进行简单的并行计算。
阅读完前两篇文章后,相信读者应该能够将一些简单的CPU代码修改成GPU并行代码,但是对计算密集型任务,仅仅使用前文的方法还是远远不够的,GPU的并行计算能力未能充分利用。本文将主要介绍一些常用性能优化的进阶技术,这部分对编程技能和硬件知识都有更高的要求,建议读者先阅读本系列的前两篇文章,甚至阅读英伟达官方的编程手册,熟悉CUDA编程的底层知识。当然,将这些优化技巧应用之后,程序将获得更大的加速比,这对于需要跑数小时甚至数天的程序来说,收益非常之大。
本文仍然使用Python版的Numba库调用CUDA,有更复杂需求的朋友可以直接使用C/C++调用CUDA,并阅读英伟达的官方文档。C/C++对数据的控制更细致,是英伟达官方推荐的编程语言,所能提供的编程接口更全面。
CUDA C Programming Guide :https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
下一篇文章将提供实战案例,包括金融领域期权定价的GPU实现。

CUDA优化方向
我之前的文章中提到,CPU + GPU 是一种异构计算的组合,各有独立的内存,GPU的优势是更多的计算核心。该架构在并行计算上有很大优势,但是数据需要从主机和设备间相互拷贝,会造成一定的延迟。因此,要从下面两个方面来优化GPU程序:
- 充分利用GPU的多核心,最大化并行执行度
- 优化内存使用,最大化数据吞吐量,减少不必要的数据拷贝
哪个方向有更大收益,最终还是要看具体的计算场景。英伟达提供了非常强大的性能分析器nvprof和可视化版nvvp,使用性能分析器能监控到当前程序的瓶颈。据我了解,分析器只支持C/C++编译后的可执行文件,Python Numba目前应该不支持。
Profiler User's Guide : https://docs.nvidia.com/cuda/profiler-users-guide/index.html
并行计算优化
网格跨度
在上一篇文章中,我曾提到,CUDA的执行配置:[gridDim, blockDim]中的blockDim最大只能是1024,但是并没提到gridDim的最大限制。英伟达给出的官方回复是gridDim最大为一个32位整数的最大值,也就是2,147,483,648,大约二十亿。这个数字已经非常大了,足以应付绝大多数的计算,但是如果对并行计算的维度有更高需求呢?网格跨度有更好的并行计算效率。

这里仍然以[2, 4]的执行配置为例,该执行配置中整个grid只能并行启动8个线程,假如我们要并行计算的数据是32,会发现后面8号至31号数据共计24个数据无法被计算。
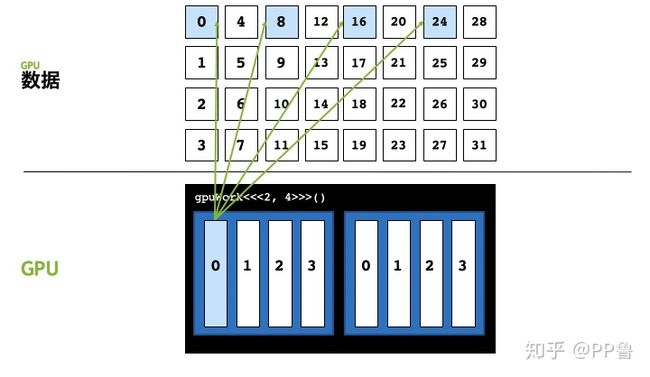
我们可以在0号线程中,处理第0、8、16、24号数据,就能解决数据远大于执行配置中的线程总数的问题,用程序表示,就是在核函数里再写个for循环。以打印为例,代码如下:
from numba import cuda
@cuda.jit
def gpu_print(N):
idxWithinGrid = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x
gridStride = cuda.gridDim.x * cuda.blockDim.x
# 从 idxWithinGrid 开始
# 每次以整个网格线程总数为跨步数
for i in range(idxWithinGrid, N, gridStride):
print(i)
def main():
gpu_print[2, 4](32)
cuda.synchronize()
if __name__ == "__main__":
main()注意,跨步大小为网格中线程总数,用gridDim.x * blockDim.x来计算。for循环的step是网格中线程总数,这也是为什么将这种方式称为网格跨步。如果网格总线程数为1024,那么0号线程将计算第0、1024、2048...号的数据。这里我们也不用再明确使用if (idx < N)来判断是否越界,因为for循环也有这个判断。
使用网格跨步的优势主要有:
- 扩展性:可以解决数据量比线程数大的问题
- 线程复用:CUDA线程启动和销毁都有开销,主要是线程内存空间初始化的开销;不使用网格跨步,CUDA需要启动大于计算数的线程,每个线程内只做一件事情,做完就要被销毁;使用网格跨步,线程内有
for循环,每个线程可以干更多事情,所有线程的启动销毁开销更少。 - 方便调试:我们可以把核函数的执行配置写为
[1, 1],如下所示,那么核函数的跨步大小就成为了1,核函数里的for循环与CPU函数中顺序执行的for循环的逻辑一样,非常方便验证CUDA并行计算与原来的CPU函数计算逻辑是否一致。
kernel_function[1,1](...)多流
之前我们讨论的并行,都是线程级别的,即CUDA开启多个线程,并行执行核函数内的代码。GPU最多就上千个核心,同一时间只能并行执行上千个任务。当我们处理千万级别的数据,整个大任务无法被GPU一次执行,所有的计算任务需要放在一个队列中,排队顺序执行。CUDA将放入队列顺序执行的一系列操作称为流(Stream)。
由于异构计算的硬件特性,CUDA中以下操作是相互独立的,通过编程,是可以操作他们并发地执行的:
- 主机端上的计算
- 设备端的计算(核函数)
- 数据从主机和设备间相互拷贝
- 数据从设备内拷贝或转移
- 数据从多个GPU设备间拷贝或转移

针对这种互相独立的硬件架构,CUDA使用多流作为一种高并发的方案:把一个大任务中的上述几部分拆分开,放到多个流中,每次只对一部分数据进行拷贝、计算和回写,并把这个流程做成流水线。因为数据拷贝不占用计算资源,计算不占用数据拷贝的总线(Bus)资源,因此计算和数据拷贝完全可以并发执行。如图所示,将数据拷贝和函数计算重叠起来的,形成流水线,能获得非常大的性能提升。实际上,流水线作业的思想被广泛应用于CPU和GPU等计算机芯片设计上,以加速程序。

以向量加法为例,上图中第一行的Stream 0部分是我们之前的逻辑,没有使用多流技术,程序的三大步骤是顺序执行的:先从主机拷贝初始化数据到设备(Host To Device);在设备上执行核函数(Kernel);将计算结果从设备拷贝回主机(Device To Host)。当数据量很大时,每个步骤的耗时很长,后面的步骤必须等前面执行完毕才能继续,整体的耗时相当长。以2000万维的向量加法为例,向量大约有几十M大小,将整个向量在主机和设备间拷贝将占用占用上百毫秒的时间,有可能远比核函数计算的时间多得多。将程序改为多流后,每次只计算一小部分,流水线并发执行,会得到非常大的性能提升。
默认情况下,CUDA使用0号流,又称默认流。不使用多流时,所有任务都在默认流中顺序执行,效率较低。在使用多流之前,必须先了解多流的一些规则:
- 给定流内的所有操作会按序执行。
- 非默认流之间的不同操作,无法保证其执行顺序。
- 所有非默认流执行完后,才能执行默认流;默认流执行完后,才能执行其他非默认流。
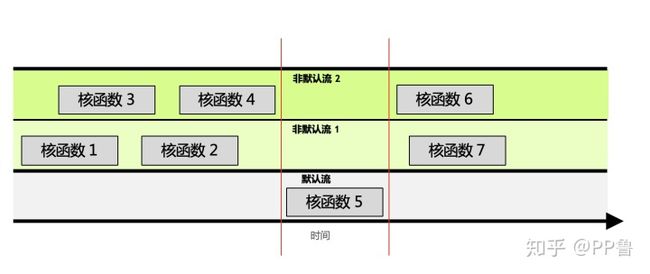
参照上图,可将这三个规则解释为:
- 非默认流1中,根据进流的先后顺序,核函数1和2是顺序执行的。
- 无法保证核函数2与核函数4的执行先后顺序,因为他们在不同的流中。他们执行的开始时间依赖于该流中前一个操作结束时间,例如核函数2的开始依赖于核函数1的结束,与核函数3、4完全不相关。
- 默认流有阻塞的作用。如图中红线所示,如果调用默认流,那么默认流会等非默认流都执行完才能执行;同样,默认流执行完,才能再次执行其他非默认流。
可见,某个流内的操作是顺序的,非默认流之间是异步的,默认流有阻塞作用。
如果想使用多流时,必须先定义流:
stream = numba.cuda.stream()CUDA的数据拷贝以及核函数都有专门的stream参数来接收流,以告知该操作放入哪个流中执行:
numba.cuda.to_device(obj, stream=0, copy=True, to=None)numba.cuda.copy_to_host(self, ary=None, stream=0)
核函数调用的地方除了要写清执行配置,还要加一项stream参数:
kernel[blocks_per_grid, threads_per_block, stream=0]
根据这些函数定义也可以知道,不指定stream参数时,这些函数都使用默认的0号流。
对于程序员来说,需要将数据和计算做拆分,分别放入不同的流里,构成一个流水线操作。
将之前的向量加法的例子改为多流处理,完整的代码为:
from numba import cuda
import numpy as np
import math
from time import time
@cuda.jit
def gpu_add(a, b, result, n):
idx = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
if idx < n :
result[idx] = a[idx] + b[idx]
def main():
n = 20000000
x = np.arange(n).astype(np.int32)
y = 2 * x
start = time()
x_device = cuda.to_device(x)
y_device = cuda.to_device(y)
out_device = cuda.device_array(n)
threads_per_block = 1024
blocks_per_grid = math.ceil(n / threads_per_block)
# 使用默认流
gpu_add[blocks_per_grid, threads_per_block](x_device, y_device, out_device, n)
gpu_result = out_device.copy_to_host()
cuda.synchronize()
print("gpu vector add time " + str(time() - start))
start = time()
# 使用5个stream
number_of_streams = 5
# 每个stream处理的数据量为原来的 1/5
# 符号//得到一个整数结果
segment_size = n // number_of_streams
# 创建5个cuda stream
stream_list = list()
for i in range (0, number_of_streams):
stream = cuda.stream()
stream_list.append(stream)
threads_per_block = 1024
# 每个stream的处理的数据变为原来的1/5
blocks_per_grid = math.ceil(segment_size / threads_per_block)
streams_out_device = cuda.device_array(segment_size)
streams_gpu_result = np.empty(n)
# 启动多个stream
for i in range(0, number_of_streams):
# 传入不同的参数,让函数在不同的流执行
x_i_device = cuda.to_device(x[i * segment_size : (i + 1) * segment_size], stream=stream_list[i])
y_i_device = cuda.to_device(y[i * segment_size : (i + 1) * segment_size], stream=stream_list[i])
gpu_add[blocks_per_grid, threads_per_block, stream_list[i]](
x_i_device,
y_i_device,
streams_out_device,
segment_size)
streams_gpu_result[i * segment_size : (i + 1) * segment_size] = streams_out_device.copy_to_host(stream=stream_list[i])
cuda.synchronize()
print("gpu streams vector add time " + str(time() - start))
if __name__ == "__main__":
main()是否使用多流的计算时间差距非常大:
gpu vector add time 9.33862018585205
gpu streams vector add time 1.4097239971160889在上面的程序中,我将向量分拆成了5份,同时也创建了5个流,每个流执行1/5的“拷贝、计算、回写”操作,多个流之间异步执行,最终得到非常大的性能提升。
多流不仅需要程序员掌握流水线思想,还需要用户对数据和计算进行拆分,并编写更多的代码,但是收益非常明显。对于计算密集型的程序,这种技术非常值得认真研究。
内存优化
我在本系列第一篇文章提到,CPU和GPU组成异构计算架构,如果想从内存上优化程序,我们必须尽量减少主机与设备间的数据拷贝,并将更多计算从主机端转移到设备端。尽量在设备端初始化数据,并计算中间数据,并尽量不做无意义的数据回写。
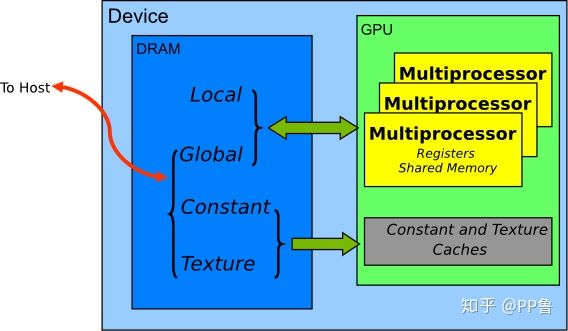
GPU的内存结构如图所示:GPU的计算核心都在Streaming Multiprocessor(SM)上,Multiprocessor里有计算核心可直接访问的寄存器(Register)和共享内存(Shared Memory);多个SM可以读取显卡上的显存,包括全局内存(Global Memory)。每个Multiprocessor上的Shared Memory相当于该Multiprocessor上的一个缓存,一般都很小,当前最强的GPU Telsa V100的Shared Memory也只有96KB。注意,Shared Memory和Global Memory的字面上都有共享的意思,但是不要将两者的概念混淆,Shared Memory离计算核心更近,延迟很低;Global Memory是整个显卡上的全局内存,延迟高。
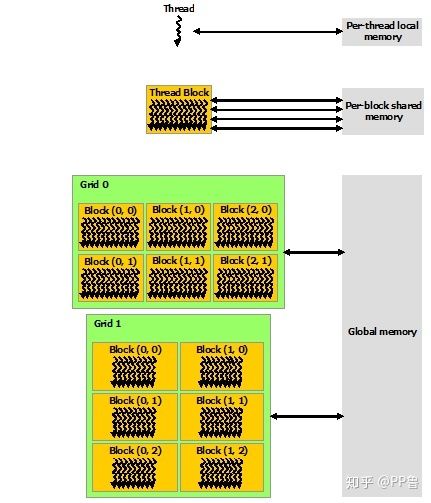
从软件角度来看,CUDA的线程可以访问不同级别的存储,每个Thread有独立的私有内存;每个Block中多个Thread都可以在该Block的Shared Memory中读写数据;整个Grid中所有Thread都可以读写Global Memory。Shared Memory的读写访问速度会远高于Global Memory。内存优化一般主要利用Shared Memory技术。下文将以矩阵乘法为例,展示如何使用Shared Memory来优化程序。
二维和三维执行配置
在解释内存优化前,先填一下之前埋下的多维执行配置的坑。我们之前使用的threadIdx 和blockIdx变量都是一维的,实际上,CUDA允许这两个变量最多为三维,一维、二维和三维的大小配置可以适应向量、矩阵和张量等不同的场景。

一个二维的执行配置如上图所示,其中,每个block有(3 * 4)个Thread,每个grid有(2 * 3)个Block。 二维块大小为 (Dx, Dy),某个线程号 (x, y) 的公式为 (x + y Dx);三维块大小为 (Dx, Dy, Dz),某个线程号(x, y, z) 的公式为 (x + y Dx + z Dx Dy)。各个内置变量中.x .y和.z为不同维度下的值。
例如,一个二维配置,某个线程在矩阵中的位置可以表示为:
col = cuda.threadIdx.y + cuda.blockDim.y * cuda.blockIdx.y
row = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x如何将二维Block映射到自己的数据上并没有固定的映射方法,一般情况将.x映射为矩阵的行,将.y映射为矩阵的列。Numba提供了一个更简单的方法帮我们计算线程的编号:
row, col = cuda.grid(2)其中,参数2表示这是一个2维的执行配置。1维或3维的时候,可以将参数改为1或3。
对应的执行配置也要改为二维:
threads_per_block = (16, 16)
blocks_per_grid = (32, 32)
gpu_kernel[blocks_per_grid, threads_per_block](16, 16)的二维Block是一个常用的配置,共256个线程。本系列第二篇文章也提到,每个Block的Thread个数最好是128、256或512,这与GPU的硬件架构高度相关。
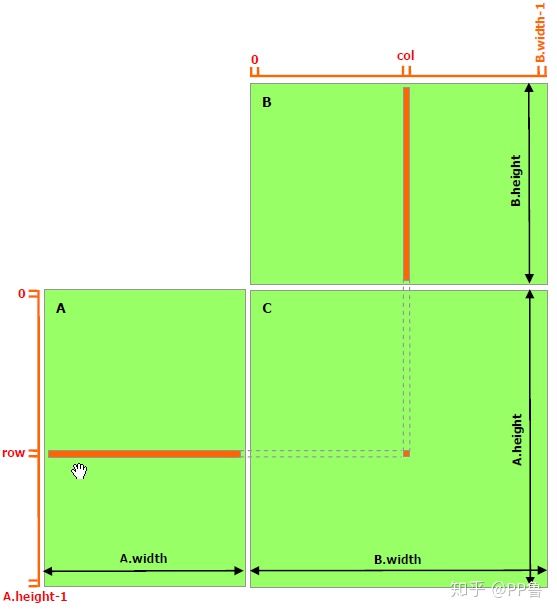
一个C = AB的矩阵乘法运算,需要我们把A的某一行与B的某一列的所有元素一一相乘,求和后,将结果存储到结果矩阵C的(row, col)上。在这种实现中,每个线程都要读取A的一整行和B的一整列,共计算M行*P列。以计算第row行为例,计算C[row, 0]、C[row, 1]...C[row, p-1]这些点时都需要从Global Memory中把整个第row行读取一遍。可以算到,A矩阵中的每个点需要被读 B.width 次,B矩阵中的每个点需要被读 A.height 次。这样比较浪费时间。因此,可以将多次访问的数据放到Shared Memory中,减少重复读取的次数,并充分利用Shared Memory的延迟低的优势。
from numba import cuda
import numpy as np
import math
from time import time
@cuda.jit
def matmul(A, B, C):
""" 矩阵乘法 C = A * B
"""
# Numba库提供了更简易的计算方法
# x, y = cuda.grid(2)
# 具体计算公式如下
row = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
col = cuda.threadIdx.y + cuda.blockDim.y * cuda.blockIdx.y
if row < C.shape[0] and col < C.shape[1]:
tmp = 0.
for k in range(A.shape[1]):
tmp += A[row, k] * B[k, col]
C[row, col] = tmp
def main():
# 初始化矩阵
M = 6000
N = 4800
P = 4000
A = np.random.random((M, N)) # 随机生成的 [M x N] 矩阵
B = np.random.random((N, P)) # 随机生成的 [N x P] 矩阵
start = time()
A = cuda.to_device(A)
B = cuda.to_device(B)
C_gpu = cuda.device_array((M, P))
# 执行配置
threads_per_block = (16, 16)
blocks_per_grid_x = int(math.ceil(A.shape[0] / threads_per_block[0]))
blocks_per_grid_y = int(math.ceil(B.shape[1] / threads_per_block[1]))
blocksPerGrid = (blocks_per_grid_x, blocks_per_grid_y)
# 启动核函数
matmul[blocksPerGrid, threads_per_block](A, B, C_gpu)
# 数据拷贝
C = C_gpu.copy_to_host()
cuda.synchronize()
print("gpu matmul time :" + str(time() - start))
start = time()
C_cpu = np.empty((M, P), np.float)
np.matmul(A, B, C_cpu)
print("cpu matmul time :" + str(time() - start))
# 验证正确性
if np.allclose(C_cpu, C):
print("gpu result correct")
if __name__ == "__main__":
main()Shared Memory
接下来的程序利用了Shared Memory来做矩阵乘法。这个实现中,跟未做优化的版本相同的是,每个Thread计算结果矩阵中的一个元素,不同的是,每个CUDA Block会以一个 BLOCK_SIZE * BLOCK_SIZE 子矩阵为基本的计算单元。具体而言,需要声明Shared Memory区域,数据第一次会从Global Memory拷贝到Shared Memory上,接下来可多次重复利用Shared Memory上的数据。

from numba import cuda, float32
import numpy as np
import math
from time import time
# thread per block
# 每个block有 BLOCK_SIZE x BLOCK_SIZE 个元素
BLOCK_SIZE = 16
@cuda.jit
def matmul(A, B, C):
""" 矩阵乘法 C = A * B
"""
row = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
col = cuda.threadIdx.y + cuda.blockDim.y * cuda.blockIdx.y
if row < C.shape[0] and col < C.shape[1]:
tmp = 0.
for k in range(A.shape[1]):
tmp += A[row, k] * B[k, col]
C[row, col] = tmp
@cuda.jit
def matmul_shared_memory(A, B, C):
"""
使用Shared Memory的矩阵乘法 C = A * B
"""
# 在Shared Memory中定义向量
# 向量可被整个Block的所有Thread共享
# 必须声明向量大小和数据类型
sA = cuda.shared.array(shape=(BLOCK_SIZE, BLOCK_SIZE), dtype=float32)
sB = cuda.shared.array(shape=(BLOCK_SIZE, BLOCK_SIZE), dtype=float32)
tx = cuda.threadIdx.x
ty = cuda.threadIdx.y
row = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
col = cuda.threadIdx.y + cuda.blockDim.y * cuda.blockIdx.y
if row >= C.shape[0] and col >= C.shape[1]:
# 当(x, y)越界时退出
return
tmp = 0.
# 以一个 BLOCK_SIZE x BLOCK_SIZE 为单位
for m in range(math.ceil(A.shape[1] / BLOCK_SIZE)):
sA[tx, ty] = A[row, ty + m * BLOCK_SIZE]
sB[tx, ty] = B[tx + m * BLOCK_SIZE, col]
# 线程同步,等待Block中所有Thread预加载结束
# 该函数会等待所有Thread执行完之后才执行下一步
cuda.syncthreads()
# 此时已经将A和B的子矩阵拷贝到了sA和sB
# 计算Shared Memory中的向量点积
# 直接从Shard Memory中读取数据的延迟很低
for n in range(BLOCK_SIZE):
tmp += sA[tx, n] * sB[n, ty]
# 线程同步,等待Block中所有Thread计算结束
cuda.syncthreads()
# 循环后得到每个BLOCK的点积之和
C[row, col] = tmp
def main():
# 初始化矩阵
M = 6000
N = 4800
P = 4000
A = np.random.random((M, N)) # 随机生成的 [M x N] 矩阵
B = np.random.random((N, P)) # 随机生成的 [N x P] 矩阵
A_device = cuda.to_device(A)
B_device = cuda.to_device(B)
C_device = cuda.device_array((M, P)) # [M x P] 矩阵
# 执行配置
threads_per_block = (BLOCK_SIZE, BLOCK_SIZE)
blocks_per_grid_x = int(math.ceil(A.shape[0] / BLOCK_SIZE))
blocks_per_grid_y = int(math.ceil(B.shape[1] / BLOCK_SIZE))
blocks_per_grid = (blocks_per_grid_x, blocks_per_grid_y)
start = time()
matmul[blocks_per_grid, threads_per_block](A_device, B_device, C_device)
cuda.synchronize()
print("matmul time :" + str(time() - start))
start = time()
matmul_shared_memory[blocks_per_grid, threads_per_block](A_device, B_device, C_device)
cuda.synchronize()
print("matmul with shared memory time :" + str(time() - start))
C = C_device.copy_to_host()
if __name__ == "__main__":
main()进行Shared Memory优化后,计算部分的耗时减少了近一半:
matmul time :1.4370720386505127
matmul with shared memory time :0.7994928359985352在上面的实现过程中,有些地方也比较容易让人迷惑。
- 声明Shared Memory。这里使用了
cuda.shared.array(shape,type),shape为这块数据的向量维度大小,type为Numba数据类型,例如是int32还是float32。这个函数只能在设备端使用。定义好后,这块数据可被同一个Block的所有Thread共享。需要注意的是,这块数据虽然在核函数中定义,但它不是单个Thread的私有数据,它可被同Block中的所有Thread读写。 - 数据加载。每个Thread会将A中的一个元素加载到sA中,一个Block的 BLOCK_SIZE x BLOCK_SIZE 个Thread可以把sA填充满。
cuda.syncthreads()会等待Block中所有Thread执行完之后才执行下一步。所以,当执行完这个函数的时候,sA和sB的数据已经拷贝好了。 - 数据复用。A中的某个点,只会被读取 B.width / BLOCK_SIZE 次;B中的某个点,只会被读 A.height / BLOCK_SIZE 次。
for n in range(BLOCK_SIZE)这个循环做子矩阵向量乘法时,可多次复用sA和sB的数据。 - 子矩阵的数据汇总。我们以一个 BLOCK_SIZE x BLOCK_SIZE 的子矩阵为单位分别对A从左到右,对B从上到下平移并计算,共循环 A.width / BLOCK_SIZE 次。在某一步平移,会得到子矩阵的点积。
for m in range(math.ceil(A.shape[1] / BLOCK_SIZE))这个循环起到了计算A从左到右与B从上到下点积的过程。
总结
一般情况下,我们主要从“增大并行度”和“充分利用内存”两个方向对CUDA来进行优化。本文针对这两种方向,分别介绍了多流和共享内存技术。这两种技术有一定的学习成本,但收益非常大,建议有计算密集型任务的朋友花一些时间了解一下这两种技术和背景知识。本文展示的CUDA接口均为Python Numba版封装,其他CUDA优化技巧可能还没完全被Numba支持。CUDA C/C++的接口更丰富,可优化粒度更细,对于有更复杂需求的朋友,建议使用C/C++进行CUDA编程。