来自于alibaba的Datax使用
来自于alibaba的Datax使用
一. 介绍
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
二. 特征
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
DataX详细介绍
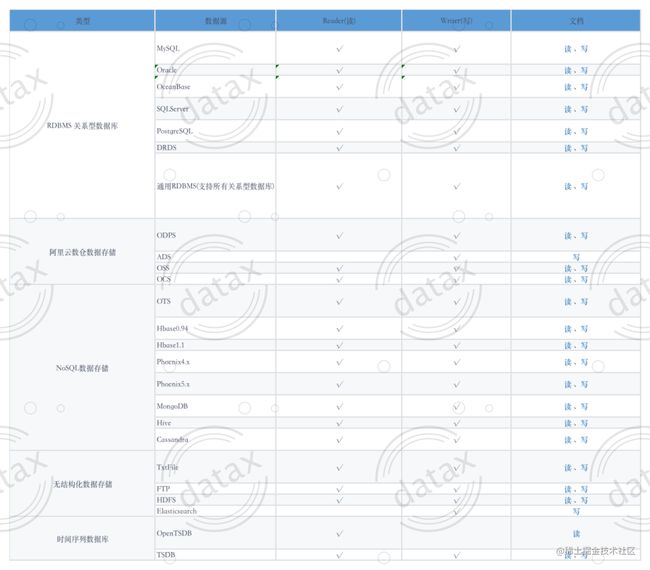
三. 支持的数据库
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南。
以上摘自:官方文档介绍
四. 常用的使用场景
1.1 MysqlReader 插件
1.1.1 快速介绍:
MysqlReader插件实现了从Mysql读取数据。在底层实现上,MysqlReader通过JDBC连接远程Mysql数据库,并执行相应的sql语句将数据从mysql库中SELECT出来。
不同于其他关系型数据库,MysqlReader不支持FetchSize.
1.1.2 实现原理:
简而言之,MysqlReader通过JDBC连接器连接到远程的Mysql数据库,并根据用户配置的信息生成查询SELECT SQL语句,然后发送到远程Mysql数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。
对于用户配置Table、Column、Where的信息,MysqlReader将其拼接为SQL语句发送到Mysql数据库;对于用户配置querySql信息,MysqlReader直接将其发送到Mysql数据库。
1.1.3 参数说明:
jdbcUrl:描述:描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。之所以使用JSON数组描述连接信息,是因为阿里集团内部支持多个IP探测,如果配置了多个,MysqlReader可以依次探测ip的可连接性,直到选择一个合法的IP。如果全部连接失败,MysqlReader报错。 注意,jdbcUrl必须包含在connection配置单元中。对于阿里集团外部使用情况,JSON数组填写一个JDBC连接即可。
username: 描述:目的数据库的用户名
password: 描述:目的数据库的密码
table: 描述:目的表的表名称(支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。)
注意:table 和 jdbcUrl 必须包含在 connection 配置单元中
column: 描述:目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: “column”: [“id”,“name”,“age”]。如果要依次写入全部列,使用*表示, 例如: “column”: ["*"]。
splitPk: 描述: MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错!
如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
where: 描述:筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。在实际业务场景中,往往会选择当天的数据进行同步,可以将where条件指定为gmt_create > $bizdate 。注意:不可以将where条件指定为limit 10,limit不是SQL的合法where子句。
where条件可以有效地进行业务增量同步。如果不填写where语句,包括不提供where的key或者value,DataX均视作同步全量数据。
querySql: 描述:在有些业务场景下,where这一配置项不足以描述所筛选的条件,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项之后,DataX系统就会忽略table,column这些配置型,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用select a,b from table_a join table_b on table_a.id = table_b.id
当用户配置querySql时,MysqlReader直接忽略table、column、where条件的配置,querySql优先级大于table、column、where选项。(非必选,但实际运用场景需要指定的逻辑,一切根据实际需要使用)
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
1.2 MysqlWriter 插件
1.2.1 快速介绍:
MysqlWriter 插件实现了写入数据到 Mysql 主库的目的表的功能。在底层实现上, MysqlWriter 通过 JDBC 连接远程 Mysql 数据库,并执行相应的 insert into … 或者 ( replace into …) 的 sql 语句将数据写入 Mysql,内部会分批次提交入库,需要数据库本身采用 innodb 引擎。
MysqlWriter 面向ETL开发工程师,他们使用 MysqlWriter 从数仓导入数据到 Mysql。同时 MysqlWriter 亦可以作为数据迁移工具为DBA等用户提供服务。
1.2.2 实现原理:
MysqlWriter 通过 DataX 框架获取 Reader 生成的协议数据,根据你配置的 writeMode 生成
insert into…(当主键/唯一性索引冲突时会写不进去冲突的行) 或者 replace into…(没有遇到主键/唯一性索引冲突时,与 insert into 行为一致,冲突时会用新行替换原有行所有字段) 的语句写入数据到 Mysql。出于性能考虑,采用了 PreparedStatement + Batch,并且设置了:rewriteBatchedStatements=true,将数据缓冲到线程上下文 Buffer 中,当 Buffer 累计到预定阈值时,才发起写入请求。
注意: 目的表所在数据库必须是主库才能写入数据;整个任务至少需要具备 insert/replace into…的权限,是否需要其他权限,取决于你任务配置中在 preSql 和 postSql 中指定的语句。
1.2.3 参数说明:
jdbcUrl:描述:目的数据库的 JDBC 连接信息。作业运行时,DataX 会在你提供的 jdbcUrl 后面追加如下属性:yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true
注意:
1、在一个数据库上只能配置一个 jdbcUrl 值。这与 MysqlReader 支持多个备库探测不同,因为此处不支持同一个数据库存在多个主库的情况(双主导入数据情况)
2、jdbcUrl按照Mysql官方规范,并可以填写连接附加控制信息,比如想指定连接编码为 gbk ,则在 jdbcUrl 后面追加属性 useUnicode=true&characterEncoding=gbk。具体请参看 Mysql官方文档或者咨询对应 DBA。
username: 描述:目的数据库的用户名
password: 描述:目的数据库的密码
table: 描述:目的表的表名称(支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。)
注意:table 和 jdbcUrl 必须包含在 connection 配置单元中
column: 描述:目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: “column”: [“id”,“name”,“age”]。如果要依次写入全部列,使用*表示, 例如: “column”: ["*"]。
session: 描述: DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性 (更改sql_mode选项等,非必选)
preSql: 描述:写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,请使用 @table 表示,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, … datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:“preSql”:[“delete from 表名”],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称。(写入前的前置处理,非必选)
postSql: 描述:写入数据到目的表后,会执行这里的标准语句。(原理同 preSql, 写入后的后置处理,非必选)
writeMode: 描述:控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句
batchSize: 描述:一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。(默认值:1024)
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19880808,
"type": "long"
},
{
"value": "1988-08-08 08:08:08",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=gbk",
"table": [
"test"
]
}
]
}
}
}
]
}
}
结合上方两个实例子实际使用场景:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/test_reader"],
"querySql": ["select id,unionid,mobile,state from test where state = 1"]
}
],
"password": "root",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"unionid",
"mobile",
"state"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test_writer",
"table": ["test_one"]
}
],
"password": "root",
"username": "root"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}