自然语言处理,Datawhale 夏令营,学习笔记7.22
前言
今年看了不少AI相关书籍,但只是有了些概念,于是参加了Datawhale主办的AI夏令营,看看能否学些东西。
学习手册:https://datawhaler.feishu.cn/docx/WirRd4oB5oMe2ixw1rxcTnHFnHh
实践任务:基于论文摘要的文本分类与关键词抽取挑战赛https://challenge.xfyun.cn/topic/info?type=abstract-of-the-paper&ch=ZuoaKcY
实践教程:https://datawhaler.feishu.cn/docx/EVoodR6WroWZxXxa3a0cukIanRO
任务一:
-
机器通过对论文摘要等信息的理解,判断该论文是否属于医学领域的文献。
提供的材料
以下为数据集预览:


以下为实践教程提供的实践思路:
任务一:文献领域分类
针对文本分类任务,可以提供两种实践思路,一种是使用传统的特征提取方法(如TF-IDF/BOW)结合机器学习模型,另一种是使用预训练的BERT模型进行建模。使用特征提取 + 机器学习的思路步骤如下:
-
数据预处理:首先,对文本数据进行预处理,包括文本清洗(如去除特殊字符、标点符号)、分词等操作。可以使用常见的NLP工具包(如NLTK或spaCy)来辅助进行预处理。
-
特征提取:使用TF-IDF(词频-逆文档频率)或BOW(词袋模型)方法将文本转换为向量表示。TF-IDF可以计算文本中词语的重要性,而BOW则简单地统计每个词语在文本中的出现次数。可以使用scikit-learn库的TfidfVectorizer或CountVectorizer来实现特征提取。
-
构建训练集和测试集:将预处理后的文本数据分割为训练集和测试集,确保数据集的样本分布均匀。
-
选择机器学习模型:根据实际情况选择适合的机器学习模型,如朴素贝叶斯、支持向量机(SVM)、随机森林等。这些模型在文本分类任务中表现良好。可以使用scikit-learn库中相应的分类器进行模型训练和评估。
-
模型训练和评估:使用训练集对选定的机器学习模型进行训练,然后使用测试集进行评估。评估指标可以选择准确率、精确率、召回率、F1值等。
-
调参优化:如果模型效果不理想,可以尝试调整特征提取的参数(如词频阈值、词袋大小等)或机器学习模型的参数,以获得更好的性能。
以下为提供的baseline代码:
1.导入包,包括pandas,词袋模型BOW,逻辑回归模型,过滤警告消息。
# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer
# 导入LogisticRegression回归模型
from sklearn.linear_model import LogisticRegression
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)2.读取数据和数据预处理。包括填充缺失值,使用title、author、abstract、keywords组成text,再用词袋模型提取text特征
# 读取数据集
train = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
# 提取文本特征,生成训练集与测试集
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])3.使用逻辑回归模型,训练,使用,生成文件
# 引入模型
model = LogisticRegression()
# 开始训练,这里可以考虑修改默认的batch_size与epoch来取得更好的效果
model.fit(train_vector, train['label'])
# 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
# 生成任务一推测结果
test[['uuid', 'Keywords', 'label']].to_csv('submit_task1.csv', index=None)把生成的文件提交
分数为0.99384

以上任务还算简单,除了BOW模型了解以来用的很少。
逻辑回归调参
逻辑回归的参数主要考虑调整的有:multi_class、solver、penalty。
考虑调参之前,要先把训练集分割,用于评价。可以取train.csv后1000条,生成vaild.csv,然后将原代码
# 读取数据集
train = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/test.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')改为:
# 读取数据集
train = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/train.csv')[:5000]
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('./基于论文摘要的文本分类与关键词抽取挑战赛公开数据/vaild.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
test.drop(['label'], axis=1)测试:
a = test.label
for multi_class in ['ovr','multinomial']:
for solver in ['newton-cg', 'liblinear', 'lbfgs', 'sag', 'saga']:
for penalty in ['l1','l2','elasticnet','none']:
try:
model = LogisticRegression(multi_class=multi_class, solver=solver,penalty=penalty)
model.fit(train_vector, train['label'])
except:
continue
b = model.predict(test_vector)
print(f1_score(a,b),multi_class,solver,penalty)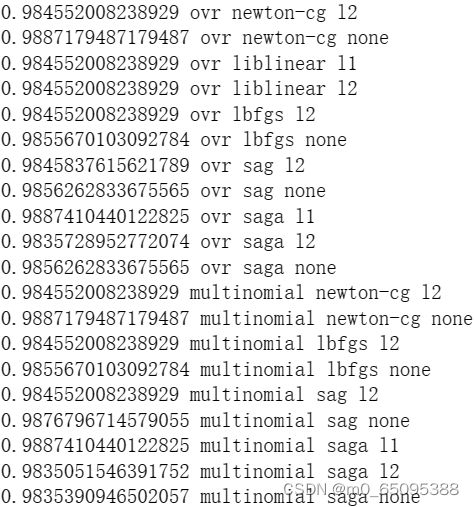
结论是,不如啥参数都不调。