Vuepress配置Algolia搜索的方法以及避坑指南
今天是2023年高考的第一天,身为高一学生的我也报名去体验了一下,感觉山东今年的语文和数学题都不是很难(至少比一模二模都简单)(当然我的成绩肯定是很糟糕)
祝愿所有考生都能取得好成绩!
这是什么
Algolia DocSearch 官网的 Slogan 是这样的:Free Algolia Search For Developer Docs,也就是说,Algolia 为开发者提供免费的搜索服务。
事实上这就是一个针对某个站点的搜索引擎,他会和搜索引擎一样对你的网站进行爬取,随后会向你提供一个 API 接口,用户在你的网站上搜索时只需调用该 API 即可。
可别小看它,下面的这些项目都采用了他们的服务:

另外在开始正文前特别说明一点:虽然文档搜索(DocSearch)是我们很多人对 Algolia 唯一的了解,但他们的业务不止于此。
如何使用
本文介绍的是向官方申请爬取的访问方式。根据其文档,你也可以自己运行爬虫后将数据上传到 Algolia 获取服务,有需要的请自行阅读研究:Run your own | DocSearch by Algolia
申请爬取
首先访问 DocSearch by Algolia,在此页面点击“Apply”,填写你的网站地址、邮箱以及开源地址(DocSearch 要求你的网站必须是开源的)。
申请后只需要等待官方给你发来邮件就可以了。Algolia 会发来两封邮件,分别告知你申请通过和爬取完成,根据本人经验这两封邮件的送达时间相差不超过15分钟。在收到第一封邮件前,我的等待时长为三天。
获取API信息
在官方发来的邮件中,提取出 appId apiKey 和 indexName 三个信息,然后根据自己使用的 Vuepress 框架的文档进行配置即可。
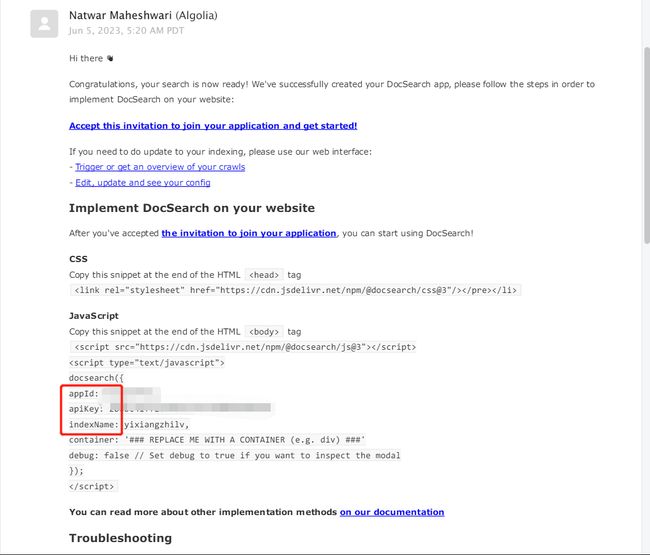
配置完成后,请尝试搜索一个关键词(确保你的网站中有文档包含这一关键词),如果正常返回了搜索结果,那么恭喜你已经完成了配置;如果你和我一样,搜什么都是 No Results,那么请继续往下看。
修改爬取配置
为什么完成爬取后仍然什么也搜不到?这是因为 Algolia 爬取时,只将每个页面匹配指定的元素选择器的元素下的文字建立索引,因此对于大多数情况我们需要手动指定选择器。
配置地址:Crawlers | Crawler Admin Console
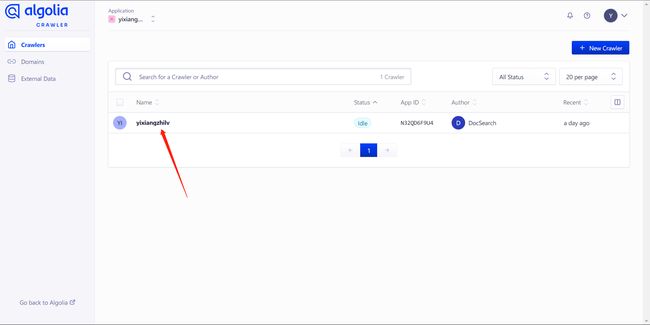
在首页,点击你的应用程序,然后在新页面中点击左侧的 Editor:
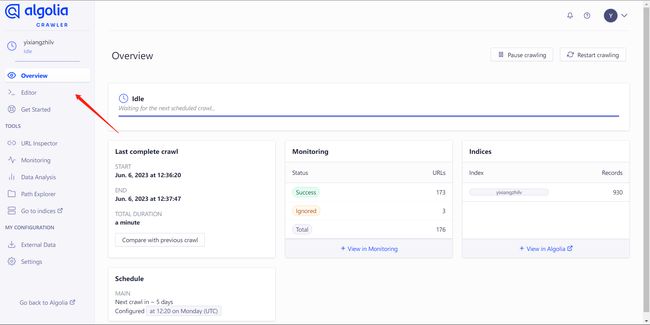
在配置界面中是一个很长的 JS 文件,我们只需要关注前面这一部分:
new Crawler({
rateLimit: 8,
maxDepth: 10,
maxUrls: 5000,
startUrls: ["https://www.yixiangzhilv.com/"],
renderJavaScript: false,
sitemaps: ["https://www.yixiangzhilv.com/sitemap.xml"],
ignoreCanonicalTo: true,
discoveryPatterns: ["https://www.yixiangzhilv.com/**"],
schedule: "at 12:20 on Monday",
actions: [
{
indexName: "yixiangzhilv",
pathsToMatch: ["https://www.yixiangzhilv.com/**"],
recordExtractor: ({ helpers }) => {
return helpers.docsearch({
recordProps: {
lvl1: ".page-container h1",
content: ".theme-reco-default-content p, .content__default li",
lvl0: {
selectors: "p.sidebar-heading.open",
defaultValue: "Documentation",
},
lvl2: ".theme-reco-default-content h2",
lvl3: ".theme-reco-default-content h3",
lvl4: ".theme-reco-default-content h4",
lvl5: ".theme-reco-default-content h5",
lang: "",
tags: {
defaultValue: ["v1"],
},
},
aggregateContent: true,
});
},
},
],
...
}
其中startUrls pathsToMatch等参数大家根据自己需要配置即可,需要注意的就是某些时候可能初次生成的文档中这里列举的 URL 不是网站根目录,而是/docs/**等,大家注意甄别。另外,如果是前端渲染的项目,需要开启renderJavaScript选项(2023.7.12补充:我最开始没开启也成功了,后来开始报错,才发现这个问题,不知道之前为什么不开启也可以)
我们重点要关注的是recordProps。下面我放出我拿到的默认配置和我修改后的配置,大家可以对比一下:
默认配置
recordProps: {
lvl1: ".content__default h1",
content: ".content__default p, .content__default li",
lvl0: {
selectors: "p.sidebar-heading.open",
defaultValue: "Documentation",
},
lvl2: ".content__default h2",
lvl3: ".content__default h3",
lvl4: ".content__default h4",
lvl5: ".content__default h5",
lang: "",
tags: {
defaultValue: ["v1"],
},
},
修改后的配置
recordProps: {
lvl1: ".page-container h1",
content: ".theme-reco-default-content p, .content__default li",
lvl0: {
selectors: "p.sidebar-heading.open",
defaultValue: "Documentation",
},
lvl2: ".theme-reco-default-content h2",
lvl3: ".theme-reco-default-content h3",
lvl4: ".theme-reco-default-content h4",
lvl5: ".theme-reco-default-content h5",
lang: "",
tags: {
defaultValue: ["v1"],
},
},
:::
::::
看出区别了吗?其实就是我们需要根据自己网站的正文在 HTML 文档中的所处元素位置来告诉 Algolia 要从什么元素提取文字。如对于我使用的 vuepress-theme-reco 主题,就需要从 .theme-reco-default-content 中提取:

修改好后,在网站右侧的 URL Tester 中可以输入自己网站某个界面的网址进行测试(注意选择正文界面而非首页,毕竟首页并没有东西用来建索引),如果看到 Records 中有内容就是成功啦。
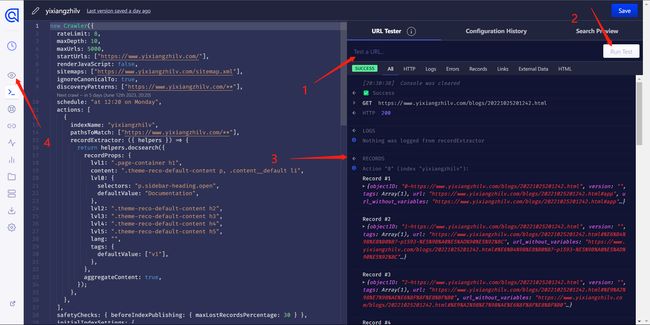
在此之后点击上图中 4 标注的小眼睛回到 Overview 界面,点击右上角的 Restart crawling 按钮重新启动爬虫,然后耐心等待爬取完成就可以啦!

参考资料
- 默认主题配置 | VuePress
- VuePress 不用Algolia 全文搜索那就缺了灵魂 - 掘金