分布式文件存储与数据缓存 Redis高可用分布式实践(下)
六、Redisweb实践 网页缓存

1.创建springboot项目
2.选择组件
Lombok
spring mvc
spring data redis
spring data jpa
3.编写配置文件
### 数据库访问配置
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.66.100:3307/test?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
########################################################
### Java Persistence Api --y
########################################################
# Specify the DBMS
spring.jpa.database = MYSQL
# Show or not log for each sql query
spring.jpa.show-sql = true
# Hibernate ddl auto (create, create-drop, update)
spring.jpa.hibernate.ddl-auto = update
# Naming strategy
#[org.hibernate.cfg.ImprovedNamingStrategy #org.hibernate.cfg.DefaultNamingStrategy]
spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.ImprovedNamingStrategy
# stripped before adding them to the entity manager)
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
########################################################
### 配置连接池数据库访问配置
########################################################
#Redis服务器连接地址
spring.redis.host=192.168.66.100
#Redis服务器连接端口
spring.redis.port=6379
#连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=8
#连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.pool.max-idle=8
#连接池中的最小空闲连接
spring.redis.pool.min-idle=0
#连接超时时间(毫秒)
spring.redis.timeout=30000
logging.pattern.console=%d{MM/dd HH:mm:ss.SSS} %clr(%-5level) --- [%-15thread] %cyan(%-50logger{50}):%msg%n
4.创建实体类
package com.zj.redis.pojo;
import lombok.Data;
import javax.persistence.*;
@Data
@Entity
@Table(name = "goods")
public class GoodsEntity {
//自增ID
@Id
@GeneratedValue(strategy= GenerationType.IDENTITY)//自增
private Long id;
// 商品名字
private String goodsName;
// 订单id
private String orderId;
// 商品数量
private Integer goodsNum;
// 商品价格
private Double price;
}
5.编写持久层
package com.zj.redis.mapper;
import com.zj.redis.pojo.GoodsEntity;
import org.springframework.data.jpa.repository.JpaRepository;
/*
GoodsEntity:表示的是实体类
Long:表示的是实体的主键的类型
*/
public interface GoodsMapper extends JpaRepository {
}
6.编写业务层
package com.zj.redis.service;
import com.zj.redis.mapper.GoodsMapper;
import com.zj.redis.pojo.GoodsEntity;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.Optional;
@Service
public class GoodsService {
@Resource
private GoodsMapper goodsMapper;
//根据商品的id查询商品的信息
public GoodsEntity selectById(Long id) {
Optional goodsEntity = goodsMapper.findById(id);
if ( goodsEntity.isPresent()){
return goodsEntity.get();
}
return null;
}
}
7.编写控制层
package com.zj.redis.controller;
import com.zj.redis.pojo.GoodsEntity;
import com.zj.redis.service.GoodsService;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class GoodsController {
@Resource
private GoodsService goodsService;
//根据id查询商品
@GetMapping("/goods")
public GoodsEntity findById(String id) {
return goodsService.selectById(Long.valueOf(id));
}
}
8.启动mysql的docker容器
#查看全部docker容器
[root@localhost /]# docker ps -a
#启动MySQL容器
[root@localhost /]# docker start 43f
9.navicat连接mysql容器
10.运行项目

数据库出现该表表示项目搭建成功!
11.浏览器请求

12.下载压测工具Jmeter并启动

13.修改语言

14.创建压测
添加线程组


15.添加HTTP请求

16.添加压测结果报告

没有加缓存的吞吐量:

17.添加redis缓存
package com.zj.redis.service;
import com.alibaba.fastjson.JSON;
import com.zj.redis.mapper.GoodsMapper;
import com.zj.redis.pojo.GoodsEntity;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import javax.annotation.Resource;
@Service
public class GoodsService {
@Resource
private GoodsMapper goodsMapper;
@Resource
private StringRedisTemplate stringRedisTemplate;
//根据商品的id查询商品的信息
public GoodsEntity selectById(Long id) {
String goodString = stringRedisTemplate.opsForValue().get("good:" + id);
//判断有没有缓存
if (StringUtils.isEmpty(goodString)) {
//从数据库查询信息
GoodsEntity goodsEntity = goodsMapper.findById(Long.valueOf(id)).get();
//将对象转为json格式
String goodsEntityJson = JSON.toJSONString(goodsEntity);
//添加到redis缓存
stringRedisTemplate.opsForValue().set("good:" + id, goodsEntityJson);
return goodsEntity;
}else {
//字符串转为对象类型
GoodsEntity goodsEntity = JSON.parseObject(goodString, GoodsEntity.class);
return goodsEntity;
}
}
}
开启redis:
[root@localhost src]# ./redis-server ../redis.conf
启动项目,访问

发现缓存中出现good。
18.继续压力测试

添加缓存后的吞吐量达到8400多。
总结:10000并发在不添加缓存的吞吐量是1062,在添加缓存后的吞吐量是8496.
七、Redis配置文件详解

在Redis的解压目录下有个很重要的配置文件 redis.conf ,关于Redis的很多功能的配置都在此文件中完成的,一般为了不破坏安装的文件,出厂默认配置最好不要去改。
units单位
配置大小单位,开头定义基本度量单位,只支持bytes,大小写不敏感。

INCLUDES
Redis只有一个配置文件,如果多个人进行开发维护,那么就需要多个这样的配置文件,这时候多个配置文件就可以在此通过 include /path/to/local.conf 配置进来,而原本的 redis.conf 配置文件就作为一个总闸。

NETWORK

参数:
- bind:绑定redis服务器网卡IP,默认为127.0.0.1,即本地回环地址。这样的话,访问redis服务只能通过本机的客户端连接,而无法通过远程连接。如果bind选项为空的话,那会接受所有来自于可用网络接口的连接。
- port:指定redis运行的端口,默认是6379。由于Redis是单线程模型,因此单机开多个Redis进程的时候会修改端口。
- timeout:设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接。默认值为0,表示不关闭。
- tcp-keepalive :单位是秒,表示将周期性的使用SO_KEEPALIVE检测客户端是否还处于健康状态,避免服务器一直阻塞,官方给出的建议值是300s,如果设置为0,则不会周期性的检测。
GENERAL

具体配置详解:
- daemonize:设置为yes表示指定Redis以守护进程的方式启动(后台启动)。默认值为 no
- pidfile:配置PID文件路径,当redis作为守护进程运行的时候,它会把 pid 默认写到 /var/redis/run/redis_6379.pid 文件里面
- loglevel :定义日志级别。默认值为notice,有如下4种取值:
debug(记录大量日志信息,适用于开发、测试阶段)
verbose(较多日志信息)
notice(适量日志信息,使用于生产环境)
warning(仅有部分重要、关键信息才会被记录)
- logfile :配置log文件地址,默认打印在命令行终端的窗口上
- databases:设置数据库的数目。默认的数据库是DB 0 ,可以在每个连接上使用select 命令选择一个不同的数据库,dbid是一个介于0到databases - 1 之间的数值。默认值是 16,也就是说默认Redis有16个数据库。
SNAPSHOTTING
这里的配置主要用来做持久化操作。

参数:
save:这里是用来配置触发 Redis的持久化条件,也就是什么时候将内存中的数据保存到硬盘
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
REPLICATION

参数:
- slave-serve-stale-data:默认值为yes。当一个 slave 与 master 失去联系,或者复制正在进行的时候,
slave 可能会有两种表现:
如果为 yes ,slave 仍然会应答客户端请求,但返回的数据可能是过时,或者数据可能是空的在第一次同步的时候
- 如果为 no ,在你执行除了 info he salveof 之外的其他命令时,slave 都将返回一个 "SYNC with master in progress" 的错误
- slave-read-only:配置Redis的Slave实例是否接受写操作,即Slave是否为只读Redis。默认值为yes。
- repl-diskless-sync:主从数据复制是否使用无硬盘复制功能。默认值为no。
- repl-diskless-sync-delay:当启用无硬盘备份,服务器等待一段时间后才会通过套接字向从站传送RDB文件,这个等待时间是可配置的。
- repl-disable-tcp-nodelay:同步之后是否禁用从站上的TCP_NODELAY 如果你选择yes,redis会使用较少量的TCP包和带宽向从站发送数据。
SECURITY

requirepass:设置redis连接密码。
比如: requirepass 123 表示redis的连接密码为123。
CLIENTS

参数:
maxclients :设置客户端最大并发连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件。 描述符数-32(redis server自身会使用一些),如果设置 maxclients为0 。表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
MEMORY MANAGEMENT

参数:
- maxmemory:设置Redis的最大内存,如果设置为0 。表示不作限制。通常是配合下面介绍的maxmemory-policy参数一起使用。
- maxmemory-policy :当内存使用达到maxmemory设置的最大值时,redis使用的内存清除策略。有以下几种可以选择:
1)volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
2)allkeys-lru 利用LRU算法移除任何key
3)volatile-random 移除设置过过期时间的随机key
4)allkeys-random 移除随机ke
5)volatile-ttl 移除即将过期的key(minor TTL)
6)noeviction noeviction 不移除任何key,只是返回一个写错误 ,默认选项
- maxmemory-samples :LRU 和 minimal TTL 算法都不是精准的算法,但是相对精确的算法(为了节省内存)。随意你可以选择样本大小进行检,redis默认选择3个样本进行检测,你可以通过maxmemory-samples进行设置样本数。
APPEND ONLY MODE

参数:
- appendonly:默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式, 可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入appendonly.aof文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。默认值为no。
- appendfilename :aof文件名,默认是"appendonly.aof"
- appendfsync:aof持久化策略的配置;no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快;always表示每次写入都执行fsync,以保证数据同步到磁盘;everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
LUA SCRIPTING

参数:
lua-time-limit:一个lua脚本执行的最大时间,单位为ms。默认值为5000.
REDIS CLUSTER

参数:
- cluster-enabled:集群开关,默认是不开启集群模式。
- cluster-config-file:集群配置文件的名称。
- cluster-node-timeout :可以配置值为15000。节点互连超时的阀值,集群节点超时毫秒数
- cluster-slave-validity-factor :可以配置值为10。
八、Redis其他功能
8.1 发布订阅

什么是发布与订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
什么时候用发布订阅
看到发布订阅的特性,用来做一个简单的实时聊天系统再适合不过了。再比如,在一个博客网站中,有100个粉丝订阅了你,当你发布新文章,就可以推送消息给粉丝们拉。
Redis的发布与订阅
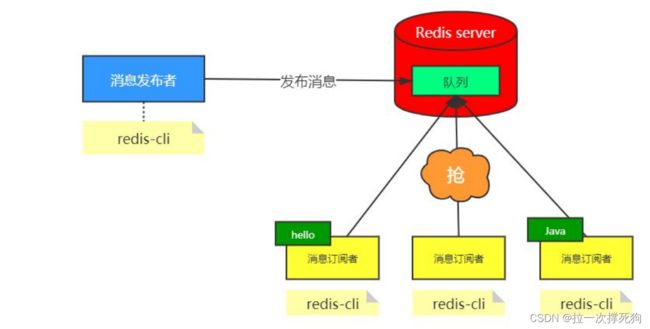
发布订阅命令行实现
订阅
subcribe 主题名字
示例:
127.0.0.1:6379> SUBSCRIBE topic1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "topic1"
3) (integer) 发布命令
publish topic1 hello
示例:
打开另一个客户端,给topic1发布消息hello
127.0.0.1:6379> PUBLISH topic1 hello
(integer) 1
注意:
返回的1是订阅者数量。
打开第一个客户端可以看到发送的消息
127.0.0.1:6379> SUBSCRIBE channel-1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel-1"
3) (integer) 1
1) "message"
2) "channel-1"
3) "hello"
注意:
发布的消息没有持久化,如果在订阅的客户端收不到hello,只能收到订阅后发布的消息。
8.2 慢查询

什么是慢查询
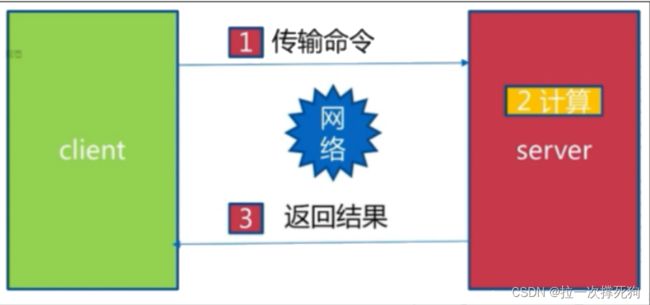
慢查询,顾名思义就是比较慢的查询,但是究竟是哪里慢呢?
Redis命令执行的整个过程

两点说明:
- 慢查询发生在第3阶段
- 客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素
- 慢查询日志是存放在Redis内存列表中。
什么是慢查询日志
慢查询日志是Redis服务端在命令执行前后计算每条命令的执行时长,当超过某个阈值时慢查询的命令就被记录在慢查询日志中。日志中记录了慢查询发生的时间,还有执行时长、具体什么命令等信息,它可以用来帮助开发和运维人员定位系统中存在的慢查询。
如何获取慢查询日志
可以使用slowlog get命令获取慢查询日志,在slowlog get后面还可以加一个数字,用于指定获取慢查询日志的条数,比如,获取3条慢查询日志:
127.0.0.1:6379> SLOWLOG get 3
1) 1) (integer) 0 #慢查询id
2) (integer) 1640056567 #时间戳
3) (integer) 11780 #执行时间
4) 1) "FLUSHALL" #执行慢查询的命令
5) "127.0.0.1:43406" #哪个客户端发出的命令
6) ""
参数:
- 唯一标识ID
- 命令执行的时间戳
- 命令执行时长
- 执行的命名和参数
如何获取慢查询日志的长度
可以使用slowlog len命令获取慢查询日志的长度。
> slowlog len
(integer) 121
注意:
当前Redis中有121条慢查询日志。
怎么配置慢查询的参数
- 命令执行时长的指定阈值 slowlog-log-slower-than。
slowlog-log-slower-than的作用是指定命令执行时长的阈值,执行命令的时长超过这个阈值时就会被记录下来。
- 存放慢查询日志的条数 slowlog-max-len。
slowlog-max-len的作用是指定慢查询日志最多存储的条数。实际上,Redis使用了一个列表存放慢查询日志,slowlog-max-len就是这个列表的最大长度。
查看慢日志配置
查看redis慢日志配置,登陆redis服务器,使用redis-cli客户端连接redis server
127.0.0.1:6379> config get slow*
1) "slowlog-max-len"
2) "128"
3) "slowlog-log-slower-than"
4) "10000"
慢日志说明:
10000阈值,单位微秒,此处为10毫秒,128慢日志记录保存数量的阈值,此处保存128条。
修改Redis配置文件
比如,把slowlog-log-slower-than设置为1000,slowlog-max-len设置为1200:
slowlog-log-slower-than 1000
slowlog-max-len 1200
使用config set命令动态修改
比如,还是把slowlog-log-slower-than设置为1000,slowlog-max-len设置为1200:
> config set slowlog-log-slower-than 1000
OK
> config set slowlog-max-len 1200
OK
> config rewrite
OK
实践建议
slowlog-max-len配置建议
- 线上建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。
- 增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为1000以上。
slowlog-log-slower-than配置建议
- 默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。
- 由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可支撑OPS不到1000。因此对于高OPS场景的Redis建议设置为1毫秒。
8.3 流水线pipeline

1次网络命令通信模型
经历了1次时间 = 1次网络时间 + 1次命令时间。
批量网络命令通信模型

经历了 n次时间 = n次网络时间 + n次命令时间
什么是流水线?

经历了 1次pipeline(n条命令) = 1次网络时间 + n次命令时间,这大大减少了网络时间的开销,这就是流水线。就是发送一次请求携带很多命令。
案例展示
从北京到上海的一条命令的生命周期有多长?

执行一条命令在redis端可能需要几百微秒,而在网络光纤中传输只花费了13毫秒。
注意:
在执行批量操作而没有使用pipeline功能,会将大量的时间耗费在每一次网络传输的过程上;而使用pipeline后,只需要经过一次网络传输,然后批量在redis端进行命令操作。这会大大提高了效率。
pipeline-Jedis实现
首先,创建springboot项目引入jedis依赖包:
redis.clients
jedis
3.6.0
没有pipeline的命令执行
@Test
void contextLoads() {
Jedis jedis = new Jedis("192.168.66.100",6379);
//开始时间
long start = System.currentTimeMillis();
for ( int i = 0 ; i < 10000 ; i ++ ){
jedis.hset("hashkey:" + i , "field" + i , "value" + i);
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("时间差:"+(end-start));
}
注意:
在不使用pipeline的情况下,使用for循环进行每次一条命令的执行操作,耗费的时间可能达到 1w 条插入命令的耗时为50s。
使用pipeline
@Test
void contextLoads() {
Jedis jedis = new Jedis("192.168.66.100", 6379);
//开始时间
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) { //创建100个pipeline对象
Pipeline pipeline = jedis.pipelined();
for (int j = i * 100; j < (i + 1) * 100; j++) {
pipeline.hset("hashkey:" + j, "field" + j, "value" + j);
}
pipeline.syncAndReturnAll();
//结束时间
}
long end = System.currentTimeMillis();
System.out.println("时间差:" + (end - start));
}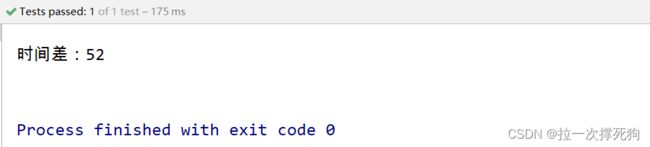
结论,使用pipeline 技术能提高访问速度。减少网络开销。
九、Redis数据安全
9.1 持久化机制概述

由于Redis的数据都存放在内存中,如果没有配置持久化,Redis重启后数据就全丢失了,于是需要开启Redis的持久化功能,将数据保存到磁盘上,当Redis重启后,可以从磁盘中恢复数据。
持久化机制概述
对于Redis而言,持久化机制是指把内存中的数据存为硬盘文件, 这样当Redis重启或服务器故障时能根据持久化后的硬盘文件恢复数 据。
持久化机制的意义
redis持久化的意义,在于故障恢复。比如部署了一个redis,作为cache缓存,同时也可以保存一些比较重要的数据。

Redis提供了两个不同形式的持久化方式
- RDB(Redis DataBase)
- AOF(Append Only File)
9.2 RDB持久化机制

RDB是什么
在指定的时间间隔内将内存的数据集快照写入磁盘,也就是行话讲的快照,它恢复时是将快照文件直接读到内存里。

注意:
将redis内存数据保存到磁盘的文件是二进制压缩文件。
配置dump.rdb文件
RDB保存的文件,在redis.conf中配置文件名称,默认为dump.rdb。

rdb文件的保存路径,也可以修改。默认为Redis启动时命令行所在的目录下


RDB触发机制
-
通过配置redis.conf文件中的RDB配置来决定触发时间

快照默认配置:
- save 3600 1:表示3600秒内(一小时)如果至少有1个key的值变化,则保存。
- save 300 100:表示300秒内(五分钟)如果至少有100个 key 的值变化,则保存。
- save 60 10000:表示60秒内如果至少有 10000个key的值变化,则保存。
给redis.conf添加新的快照策略,30秒内如果有5次key的变化,则触发快照。配置修改后,需要重启Redis服务。
save 3600 1
save 300 100
save 60 10000
save 30 5
-
通过执行flushall清除命令,也会触发rdb规则。
-
通过执行save与bgsave命令也会触发rdb
save
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止,不建议使用。
bgsave
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。
stop-writes-on-bgsave-error
默认值是yes。当Redis无法写入磁盘的话,直接关闭Redis的写操作。

rdbcompression
默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。

rdbchecksum
默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。

恢复数据
只需要将rdb文件放在Redis的启动目录,Redis启动时会自动加载dump.rdb并恢复数据。
优势
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适合使用
- 节省磁盘空间
- 恢复速度快
劣势
- 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
9.3 AOF持久化机制

AOF是什么
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来。

AOF默认不开启
可以在redis.conf中配置文件名称,默认为appendonly.aof。

注意:
AOF文件的保存路径,同RDB的路径一致都是在redis文件根目录下,如果AOF和RDB同时启动,Redis默认读取AOF的数据。
开启AOF
设置Yes:修改默认的appendonly no,改为yes
appendonly yes
注意:
修改完需要重启redis服务。
AOF同步频率设置

参数:
- appendfsync always
始终同步,每次Redis的写入都会立刻记入日志,性能较差但数据完整性比较好。
- appendfsync everysec
每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
- appendfsync no
redis不主动进行同步,把同步时机交给操作系统。
优势
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
劣势
- 比起RDB占用更多的磁盘空间。
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
9.4 企业中该如何选择持久化机制

不要仅仅使用RDB
RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据。
也不要仅仅使用AOF
- 你通过AOF做冷备,没有RDB做冷备来的恢复速度更快。
- RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug。
综合使用AOF和RDB两种持久化机制
用AOF来保证数据不丢失,作为数据恢复的第一选择,用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复。

十、Redis事务
10.1 事务概念与ACID特性

数据库层面事务
在数据库层面,事务是指一组操作,这些操作要么全都被成功执行,要么全都不执行。
数据库事务的四大特性
- A:Atomic,原子性,将所有SQL作为原子工作单元执行,要么全部执行,要么全部不执行;
- C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B账户则必定加上了100;
- I:Isolation,隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;
- D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储。
Redis事务
Redis事务是一组命令的集合,一个事务中的所有命令都将被序列化,按照一次性、顺序性、排他性的执行一系列的命令。

Redis事务三大特性
- 单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断;
- 没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”。
- 不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚;
Redis事务执行的三个阶段

- 开启:以
MULTI开始一个事务; - 入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面;
- 执行:由
EXEC命令触发事务;
10.2 事务的基本操作
Multi、Exec、discard
事务从输入Multi命令开始,输入的命令都会依次压入命令缓冲队列中,并不会执行,直到输入Exec后,Redis会将之前的命令缓冲队列中的命令依次执行。组队过程中,可以通过discard来放弃组队。
- 正常执行
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379(TX)> set id 2
QUEUED
127.0.0.1:6379(TX)> get id
QUEUED
127.0.0.1:6379(TX)> incr id
QUEUED
127.0.0.1:6379(TX)> incr id
QUEUED
127.0.0.1:6379(TX)> exec #提交事务
1) OK
2) "2"
3) (integer) 3
4) (integer) 4- 放弃事务
127.0.0.1:6379> MULTI #开启事务
OK
127.0.0.1:6379(TX)> get id
QUEUED
127.0.0.1:6379(TX)> incr id
QUEUED
127.0.0.1:6379(TX)> DISCARD #放弃事务
OK
127.0.0.1:6379> get id
"4"
127.0.0.1:6379> - 全体连坐
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set name zj
QUEUED
127.0.0.1:6379(TX)> get name
QUEUED
127.0.0.1:6379(TX)> incr t1
QUEUED
127.0.0.1:6379(TX)> get t1
QUEUED
127.0.0.1:6379(TX)> set email
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379(TX)> exec
(error) EXECABORT Transaction discarded because of previous errors.
注意:
命令集合中含有错误的指令(注意是语法错误),均连坐,全部失败。一人犯罪全家遭殃。
- 冤有头,债有主
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> set age 11
QUEUED
127.0.0.1:6379(TX)> incr t1
QUEUED
127.0.0.1:6379(TX)> set email [email protected]
QUEUED
127.0.0.1:6379(TX)> incr email #语法正确,但是执行的时候会错误,该命令不会被执行。
QUEUED
127.0.0.1:6379(TX)> get age
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) (integer) 5
3) OK
4) (error) ERR value is not an integer or out of range
5) "11"
注意:
运行时错误,即非语法错误,正确命令都会执行,错误命令返回错误。
十一、Redis集群
11.1 主从复制概念

概述
在现有企业中80%公司大部分使用的是redis单机服务,在实际的场景当中单一节点的redis容易面临风险。
面临问题:
- 机器故障。我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的。
- 容量瓶颈。redis的数据保存在内存中,当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了。当然,你可以重新买个 128G 内存的新机器。
解决办法
要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上。
注意:
Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis的高可用,实现对数据的冗余备份从而保证数据和服务的高可用。
什么是主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。

主从复制的作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
11.2 主从复制搭建

通过不同的端口,来模拟不同的redis服务。但是在实际的开发中肯定不是这样搭建的主从集群。企业中一台服务器搭建一个redis
新建redis6379.conf配置文件
在新建配置文件之前先将redis服务停掉。
[root@localhost ~]# lsof -i:6379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 1855 root 6u IPv4 33744 0t0 TCP *:6379 (LISTEN)
redis-ser 1855 root 7u IPv6 33745 0t0 TCP localhost:6379 (LISTEN)
[root@localhost ~]# kill 1855
在redis根目录下编写配置文件
include /usr/local/redis-6.2.6/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
新建redis6380.conf配置文件
include /usr/local/redis-6.2.6/redis.conf
pidfile /var/run/redis_6381.pid
port 6381
dbfilename dump6381.rdb
新建redis6381.conf配置文件
include /usr/local/redis-6.2.6/redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
启动三台redis服务器
./redis-server ../redis6379.conf
./redis-server ../redis6380.conf
./redis-server ../redis6381.conf
查看系统进程

打开三个窗口连接不同端口下的redis服务
./redis-cli -p 6379
./redis-cli -p 6380
./redis-cli -p 6381查看服务详情
127.0.0.1:6379> info replication
127.0.0.1:6380> info replication
127.0.0.1:6381> info replication在从库中指定主库
slaveof 127.0.0.1:6380> slaveof 127.0.0.1 6379
127.0.0.1:6381> slaveof 127.0.01 6379
主机写数据
127.0.0.1:6379> set test1 testvalue
OK从机读数据
127.0.0.1:6380> get test1
"testvalue"
127.0.0.1:6381> get test1
"testvalue"注意,从节点只能读数据不能写数据。
11.3 主从复制原理刨析

主从复制可以分为3个阶段
-
连接建立阶段(即准备阶段)
-
数据同步阶段
-
命令传播阶段
复制过程大致分为6个过程

1、保存主节点(master)信息。
执行 slaveof 后 查看状态信息
info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
2、从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该主节点建立网络连接

3、从节点与主节点建立网络连接
从节点会建立一个 socket 套接字,从节点建立了一个端口为51234的套接字,专门用于接受主节点发送的复制命令。

4、从节点发送ping命令到主节点

作用:
- 检测主从之间网络套接字是否可用。
- 检测主节点当前是否可以接受命令 。
5、权限认证
如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程
6、同步数据集
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。

主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
例如:
保存一个缓存
set name zj记录命令为
$3 \r \n set \r \n $4 \r \n name \r \n $5 \r \n baizhan \r \n
偏移量 1000 1001 1002 1003 1004 1005 1006 1007 1008 字节值 $ 3 \r \n $ 4 n a m
7、命令持续复制。
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
11.4 哨兵监控概述

Redis主从复制缺点
当主机 Master 宕机以后,我们需要人工解决切换。

暴漏问题:
一旦主节点宕机,写服务无法使用,就需要手动去切换,重新选取主节点,手动设置主从关系。
主从切换技术
当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
哨兵模式概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。

哨兵作用
- 集群监控:负责监控redis master和slave进程是否正常工作
- 消息通知:如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果master node挂掉了,会自动转移到slave node上
- 配置中心:如果故障转移发生了,通知client客户端新的master地址
11.5 配置哨兵监控

新建sentinel-26379.conf配置文件
#端口
port 26380
#守护进程后台运行
daemonize yes
#日志文件
logfile "26380.log"
#主节点
sentinel monitor mymaster 192.168.66.100 6379 2
参数:
sentinel monitor mymaster 192.168.92.128 6379 2 配置的含义是:该哨兵节点监控192.168.92.128:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移。
新建sentinel-26380.conf文件
#端口
port 26380
#守护进程运行
daemonize yes
#日志文件
logfile "26380.log"
sentinel monitor mymaster 192.168.66.100 6379 2
新建sentinel-26381.conf文件
#端口
port 26381
#守护进程运行
daemonize yes
#日志文件
logfile "26381.log"
sentinel monitor mymaster 192.168.66.100 6379 2
实际开发中一个redis中搭配一个哨兵。
哨兵节点的启动
[root@localhost src]# ./redis-sentinel ../ sentinel-26379.conf
[root@localhost src]# ./redis-sentinel ../ sentinel-26380.conf
[root@localhost src]# ./redis-sentinel ../ sentinel-26381.conf查看哨兵节点状态
[root@localhost src]# ./redis-cli -p 26379
127.0.0.1:26379>
127.0.0.1:26379>
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.66.100:6379,slaves=2,sentinels=3
11.6 哨兵监控原理刨析

监控阶段
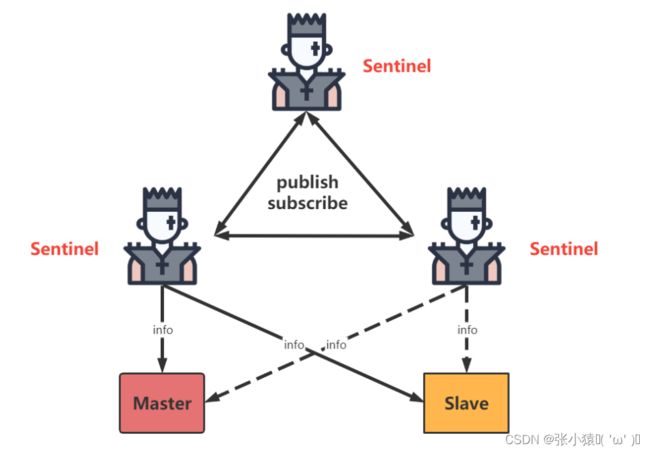
过程:
- sentinel(哨兵1)----->向master(主)和slave(从)发起info,拿到全信息。
- sentinel(哨兵2)----->向master(主)发起info,就知道已经存在的sentinel(哨兵1)的信息,并且连接slave(从)。
- sentinel(哨兵2)----->向sentinel(哨兵1)发起subscribe(订阅)。
通知阶段
sentinel不断的向master和slave发起通知,收集信息。
故障转移阶段
通知阶段sentinel发送的通知没得到master的回应,就会把master标记为SRI_S_DOWN,并且把master的状态发给各个sentinel,其他sentinel听到master挂了,说我不信,我也去看看,并把结果共享给各个sentinel,当有一半的sentinel都认为master挂了的时候,就会把master标记为SRI_0_DOWN。

问题来了:
这时就要把master给换掉了,到底谁当Master呢。
投票方式

方式:
自己最先接到哪个sentinel的竞选通知就会把票投给它。
剔除一些情况:
- 不在线的
- 响应慢的
- 与原来master断开时间久的
- 优先级原则

11.7 哨兵监控故障转移监控

演示故障转移
#查看主节点所在端口6379进程的PID
[root@localhost src]# lsof -i:6379
#杀死主节点的redis服务模拟故障
[root@localhost src]# kill -9 PID
查看哨兵节点信息
[root@localhost src]# ./redis-cli -p 26379
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6381,slaves=5,sentinels=3
注意:
会发现主节点还没有切换过来,因为哨兵发现主节点故障并转移,需要一段时间。
重启6379节点
[root@localhost src]# ./redis-cli info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
master_link_status:down
该节点变为了从节点
6379节点的配置文件被改写
故障转移阶段,哨兵和主从节点的配置文件都会被改写
include /usr/local/redis/redis.conf
pidfile "/var/run/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
# Generated by CONFIG REWRITE
daemonize yes
protected-mode no
appendonly yes
slowlog-max-len 1200
slowlog-log-slower-than 1000
save 5 1
user default on nopass ~* &* +@all
dir "/usr/local/redis"
replicaof 127.0.0.1 6381
结论
- 哨兵系统中的主从节点,与普通的主从节点并没有什么区别,故障发现和转移是由哨兵来控制和完成的。
- 哨兵节点本质上是redis节点,是redis节点的不同进程。
- 每个哨兵节点,只需要配置监控主节点,便可以自动发现其他的哨兵节点和从节点。因为主节点中包含从节点的信息。
- 在哨兵节点启动和故障转移阶段,各个节点的配置文件会被重写(config rewrite)。
11.8 Cluster模式概述

Redis有三种集群模式
- 主从模式
- Sentinel模式
- Cluster模式
哨兵模式的缺点

缺点:
- 当master挂掉的时候,sentinel 会选举出来一个 master,选举的时候是没有办法去访问Redis的,会存在访问瞬断的情况;
- 哨兵模式,对外只有master节点可以写,slave节点只能用于读。尽管Redis单节点最多支持10W的QPS,但是在电商大促的时候,写数据的压力全部在master上。
- Redis的单节点内存不能设置过大,若数据过大在主从同步将会很慢;在节点启动的时候,时间特别长;
Cluster模式概述

Redis集群是一个由多个主从节点群组成的分布式服务集群,它具有复制、高可用和分片特性。当缓存的数据特别大的时候建议使用Cluster模式。数据不大的情况下使用哨兵模式即可。
Redis集群的优点
- Redis集群有多个master,可以减小访问瞬断问题的影响
- Redis集群有多个master,可以提供更高的并发量
- Redis集群可以分片存储,这样就可以存储更多的数据
11.9 Cluster模式搭建

Redis的集群搭建最少需要3个master节点,我们这里搭建3个master,每个下面挂一个slave节点,总共6个Redis节点;

环境准备
第1台机器(纯净): 192.168.66.100 8001端口 8002端口
第2台机器(redis-2): 192.168.66.101 8001端口 8002端口
第3台机器(redis-3): 192.168.66.102 8001端口 8002端口
关闭三台虚拟机的防火墙
systemctl stop firewalld.service
将纯净虚拟机中的redis压缩文件上传到redis-2和redis-3虚拟机中
scp -r redis-6.2.6.tar.gz/ 192.168.66.101:$PWD
scp -r redis-6.2.6.tar.gz/ 192.168.66.102:$PWD将redis-2和redis-3的压缩文件分别解压到/user/local下
tar -zxvf redis-6.2.6.tar.gz -C /usr/local将redis-2和redis-3中解压后的文件进行编译
[root@localhost redis-6.2.6]# make注意:文件的编译需要C语言环境。
#检查当前的虚拟机是否安装了C语言环境 gcc --version #安装gcc yum install -y gcc
将编译完的文件进行安装
[root@localhost redis-6.2.6]# make install分别在三台机器的redis安装目录下创建文件夹redis-cluster
[root@localhost redis-6.2.6]# mkdir redis-cluster
#在文件夹下创建用于存放配置文件的文件夹
[root@localhost redis-cluster]# mkdir 8001
[root@localhost redis-cluster]# madir 8002
在纯净虚拟机中将redis的核心配置文件redis.conf拷贝到/redis-cluster/8001下
[root@localhost redis-6.2.6]# cp redis.conf redis-cluster/8001
修改8001下的redis.conf配置文件
#修改配置文件中的端口号为8001
port 8001
#开启守护线程(后台运行)
daemonize yes
#修改pidfile,pidfile参数用于指定一个文件路径,用于存储Redis服务器进程的PID(进程ID)
pidfile /var/run/redis_8001.pid
#指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据
dir /usr/local/redis-6.2.6/redis-cluster/8001/
#启动集群模式
cluster-enabled yes
#集群节点信息文件,这里800x最好和port对应上
cluster-config-file nodes-8001.conf
# 节点离线的超时时间
cluster-node-timeout 5000
#去掉bind绑定访问ip信息
#bind 127.0.0.1
#关闭保护模式
protected-mode no
#启动AOF文件
appendonly yes
将该配置文件复制到8002目录下
[root@localhost 8001]# cp redis.conf ../8002
#将8001改为8002
:%s/8001/8002/g将本机机器上的文件拷贝到另外两台机器上
# 第二台机器
[root@localhost 8001]# scp -r redis.conf 192.168.66.101:$PWD
[root@localhost 8002]# scp -r redis.conf 192.168.66.101:$PWD
#第三台机器
[root@localhost 8001]# scp -r redis.conf 192.168.66.102:$PWD
[root@localhost 8002]# scp -r redis.conf 192.168.66.102:$PWD
分别启动这6个redis实例
[root@localhost src]# ./redis-server ../redis-cluster/8001/redis.conf
[root@localhost src]# ./redis-server ../redis-cluster/8002/redis.conf检查是否启动成功
ps -ef |grep redis在纯净虚拟机使用redis-cli创建整个redis集群
[root@localhost src]# ./redis-cli --cluster create --cluster-replicas 1 192.168.66.100:8001 192.168.66.100:8002 192.168.66.101:8001 192.168.66.101:8002 192.168.66.102:8001 192.168.66.102:8002
- --cluster-replicas 1:表示1个master下挂1个slave; --cluster-replicas 2:表示1个master下挂2个slave。
查看帮助命令
src/redis‐cli --cluster help
参数:
- create:创建一个集群环境host1:port1 ... hostN:portN
- call:可以执行redis命令
- add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
- del-node:移除一个节点
- reshard:重新分片
- check:检查集群状态
验证集群 在纯净虚拟机连接任意一个客户端
[root@localhost src]# ./redis-cli -c -h 192.168.66.101 -p 8001
192.168.66.101:8001>参数:
- ‐c表示集群模式
- -h指定ip地址
- -p表示端口号
查看集群的信息
cluster info
11.10 Cluster模式原理

Redis Cluster将所有数据划分为16384个slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。只有master节点会被分配槽位,slave节点不会分配槽位。通过槽位就能直接定位到数据的存储的位置。当客户端连接到redis集群的时候,集群会返回给客户端一个槽位表并缓存到客户端本地,该表明确划分了各redis服务器数据的槽位范围,存储数据时通过槽位定位算法决定数据保存在哪个服务器上。
槽位定位算法: k1 = 127001
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
HASH_SLOT = CRC16(key) % 16384
192.168.66.101:8001> set k1 v1
-> Redirected to slot [12706] located at 192.168.66.102:8001
OK
192.168.66.102:8001>在101机器主节点上存储数据,返回槽位为12706,当前主节点切换为102表示该数据存储到了102机器上。
注意:
根据k1计算出的槽值进行切换节点,并存入数据。不在一个slot下的键值,是不能使用mget、mset等多建操作。
可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到同一个slot中。
192.168.66.102:8001> mset k1{test} v1 k2{test} v2 k3{test} v3
-> Redirected to slot [6918] located at 192.168.66.101:8001
OK
192.168.66.101:8001> get k2{test}
"v2"查看节点的信息
192.168.66.101:8001> cluster nodes杀死Master节点
lsof -i:8001
kill -9 pid
当一个master死往后会重新选举产生一个master。
11.11 Java操作Redis集群

Jedis整合Redis
redis.clients
jedis
3.6.0
junit
junit
4.12
test
public class TestJedis {
@Test
public void testCluster() {
//Set集合保存节点数据
Set redisNodes = new HashSet();
redisNodes.add(new HostAndPort("192.168.66.100",8001));
redisNodes.add(new HostAndPort("192.168.66.100",8002));
redisNodes.add(new HostAndPort("192.168.66.101",8001));
redisNodes.add(new HostAndPort("192.168.66.101",8002));
redisNodes.add(new HostAndPort("192.168.66.102",8001));
redisNodes.add(new HostAndPort("192.168.66.102",8002));
//构建redis集群实例,建立连接
JedisCluster jedisCluster = new JedisCluster(redisNodes);
//添加元素
jedisCluster.set("name","zhangsan");
//获取元素
System.out.println(jedisCluster.get("name"));
}
} SpringBoot 整合 Redis
pom依赖
org.springframework.boot
spring-boot-starter-data-redis-reactive
org.springframework.boot
spring-boot-starter-test
test
配置文件
##服务器
spring.redis.cluster.nodes=192.168.66.100:8001,192.168.66.100:8002,192.168.66.101:8001,192.168.66.101:8002,192.168.66.102:8001,192.168.66.102:8002
## 连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=300
## Redis数据库索引(默认为0)
spring.redis.database=0
## 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
## 连接池中的最大空闲连接
spring.redis.pool.max-idle=100
## 连接池中的最小空闲连接
spring.redis.pool.min-idle=20
## 连接超时时间(毫秒)
spring.redis.timeout=60000
@SpringBootTest
class RedisApplicationTests {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Test
void test(){
//添加值
stringRedisTemplate.opsForValue().set("age","23");
//获取值
String age = stringRedisTemplate.opsForValue().get("age");
System.out.println(age);
}
}十二、Redis企业级解决方案
12.1 Redis脑裂

什么是Redis的集群脑裂
Redis的集群脑裂是指因为网络问题,导致Redis Master节点跟Redis slave节点和Sentinel集群处于不同的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。说白了就是sentinel向主节点“喊话”的时候,主节点因为网络的问题没有及时恢复,让sentinel误认为主节点已经挂了。又重新选举产生了新的主节点。

注意:
此时存在两个不同的master节点,就像一个大脑分裂成了两个。集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的Master节点将无法同步这些数据,当网络问题解决之后,sentinel集群将原先的Master节点降为slave节点,此时再从新的master中同步数据,将会造成大量的数据丢失。
解决方案
redis.conf配置参数:
min-replicas-to-write 1
min-replicas-max-lag 5
参数:
- 第一个参数表示最少的slave节点为1个
- 第二个参数表示数据复制和同步的延迟不能超过5秒
配置了这两个参数:如果发生脑裂原Master会在客户端写入操作的时候拒绝请求。这样可以避免大量数据丢失。
12.2 缓存预热

缓存冷启动
因为浏览器请求数据时先到redis缓存中查找数据,假如缓存中没有数据就会访问数据库获取数据,那么并发量上来Mysql就裸奔挂掉了。

缓存冷启动场景
新启动的系统没有任何缓存数据,在缓存重建数据的过程中,系统性能和数据库负载都不太好,所以最好是在系统上线之前就把要缓存的热点数据加载到缓存中,这种缓存预加载手段就是缓存预热。

解决思路
- 提前给redis中灌入部分数据,再提供服务
- 如果数据量非常大,就不可能将所有数据都写入redis,因为数据量太大了,第一是因为耗费的时间太长了,第二根本redis容纳不下所有的数据
- 需要根据当天的具体访问情况,实时统计出访问频率较高的热数据
- 然后将访问频率较高的热数据写入redis中,肯定是热数据也比较多,我们也得多个服务并行读取数据去写,并行的分布式的缓存预热

12.3 缓存穿透

概念
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。

解释:
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
解决方案
- 对空值缓存:如果一个查询返回的数据为空(不管数据是否存在),我们仍然把这个空结果缓存,设置空结果的过期时间会很短,最长不超过5分钟。
- 布隆过滤器:如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
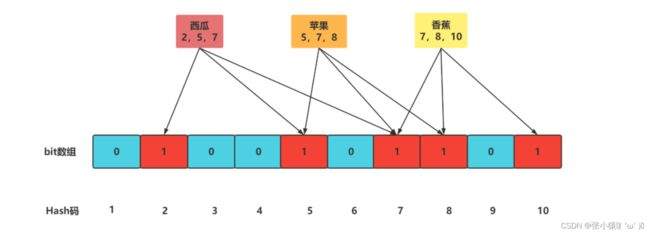
注意:
布隆说不存在一定不存在,布隆说存在你要小心了,它有可能不存在。
代码实现布隆过滤器
cn.hutool
hutool-all
5.7.17
// 初始化 注意 构造方法的参数大小10 决定了布隆过滤器BitMap的大小
BitMapBloomFilter filter = new BitMapBloomFilter(10);
filter.add("123");
filter.add("abc");
filter.add("ddd");
boolean abc = filter.contains("abc");
System.out.println(abc);
12.4 缓存击穿

概念
某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。

解决方案
- 互斥锁:在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,其他线程直接查询缓存。
- 热点数据不过期:直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。
public String get(String key) throws InterruptedException {
String value = jedis.get(key);
// 缓存过期
if (value == null){
// 设置3分钟超时,防止删除操作失败的时候 下一次缓存不能load db
Long setnx = jedis.setnx(key + "mutex", "1");
jedis.pexpire(key + "mutex", 3 * 60);
// 代表设置成功
if (setnx == 1){
// 数据库查询
//value = db.get(key);
//保存缓存
jedis.setex(key,3*60,"");
jedis.del(key + "mutex");
return value;
}else {
// 这个时候代表同时操作的其他线程已经load db并设置缓存了。 需要重新重新获取缓存
Thread.sleep(50);
// 重试
return get(key);
}
}else {
return value;
}
}
12.5 缓存雪崩

概念
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
缓存正常从Redis中获取,示意图如下:

缓存失效瞬间示意图如下:

解决方案
- 过期时间打散:既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同一时刻失效。
- 热点数据不过期:该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
- 加互斥锁: 该方式和缓存击穿一样,按 key 维度加锁,对于同一个 key,只允许一个线程去计算,其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。
public Object GetProductListNew(String cacheKey) {
int cacheTime = 30;
String lockKey = cacheKey;
// 获取key的缓存
String cacheValue = jedis.get(cacheKey);
// 缓存未失效返回缓存
if (cacheValue != null) {
return cacheValue;
} else {
// 枷锁
synchronized(lockKey) {
// 获取key的value值
cacheValue = jedis.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//这里一般是sql查询数据
// db.set(key)
// 添加缓存
jedis.set(cacheKey,"");
}
}
return cacheValue;
}
}
注意:
加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。
12.6 Redis开发规范

key设计技巧
- 1、把表名转换为key前缀,如
tag: - 2、把第二段放置用于区分key的字段,对应msyql中主键的列名,如
user_id - 3、第三段放置主键值,如
2,3,4 - 4、第四段写存储的列名
| user_id | name | age |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | lisi | 20 |
# 表名 主键 主键值 存储列名字
set user:user_id:1:name 张三
set user:user_id:1:age 20
#查询这个用户
keys user:user_id:9*value设计
拒绝bigkey
防止网卡流量、慢查询,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
命令使用
1、禁用命令
禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
2、合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
3、使用批量操作提高效率
- 原生命令:例如mget、mset。
- 非原生命令:可以使用pipeline提高效率。
注意:
但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。
4、不建议过多使用Redis事务功能
Redis的事务功能较弱(不支持回滚),而且集群版本(自研和官方)要求一次事务操作的key必须在一个slot上。
客户端使用
- Jedis :https://github.com/xetorthio/jedis 重点推荐
- Spring Data redis :https://github.com/spring-projects/spring-data-redis 使用Spring框架时推荐
- Redisson :https://github.com/mrniko/redisson 分布式锁、阻塞队列的时重点推荐
1、避免多个应用使用一个Redis实例
不相干的业务拆分,公共数据做服务化。
2、使用连接池
可以有效控制连接,同时提高效率,标准使用方式:
执行命令如下:
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
//具体的命令
jedis.executeCommand()
} catch (Exception e) {
logger.error("op key {} error: " + e.getMessage(), key, e);
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if (jedis != null)
jedis.close();
}
12.7 数据一致性

缓存已经在项目中被广泛使用,在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作。

缓存说明:
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。缓存过期的时间越短,越能保证数据的一致性。
三种更新策略
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
先更新数据库,再更新缓存
这套方案,大家是普遍反对的。为什么呢?
线程安全角度
同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
先删缓存,再更新数据库
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存 (2)请求B查询发现缓存不存在 (3)请求B去数据库查询得到旧值 (4)请求B将旧值写入缓存 (5)请求A将新值写入数据库
注意:
该数据永远都是脏数据。

这种情况存在并发问题吗?
(1)缓存刚好失效 (2)请求A查询数据库,得一个旧值 (3)请求B将新值写入数据库 (4)请求B删除缓存 (5)请求A将查到的旧值写入缓存
发生这种情况的概率又有多少?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的,因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。