【图像分类】CNN+Transformer结合系列.3
介绍两篇图像分类的论文:ResMLP(arXiv2305),MetaFormer(CVPR2022),两者都与Transformer有关系,前者基于transformer结构的特点设计ResMLP,后者认为宏观架构才是Transformer成功的原因并设计一个简单的PoolFormer结构。
ResMLP: Feedforward networks for image classification with data-efficient training, arXiv2105
论文:https://arxiv.org/abs/2105.03404
代码:https://github.com/rishikksh20/ResMLP-pytorch
解读:【图像分类】2022-ResMLP_resmlp代码_說詤榢的博客-CSDN博客
论文阅读:ResMLP: Feedforward networks for image classification with data-efficient training_多层感知机的经典论文_Phoenixtree_DongZhao的博客-CSDN博客
摘要
研究内容:本文提出了基于多层感知器的图像分类体系结构 ResMLP。
方法介绍:它是一种简单的残差网络,它可以替代
(i) 一个线性层,其中图像小块在各个通道之间独立而相同地相互作用,以及
(ii)一个两层前馈网络,其中每个通道在每个小块之间独立地相互作用。
实验结论:当使用大量数据增强和选择性蒸馏的现代训练策略进行训练时,它在 ImageNet 上获得了惊人的准确性/复杂度权衡。
本文还在自监督设置中训练 ResMLP 模型,以进一步去除使用标记数据集的先验。
最后,通过将模型应用于机器翻译,取得了令人惊讶的良好结果。
ResMLP方法
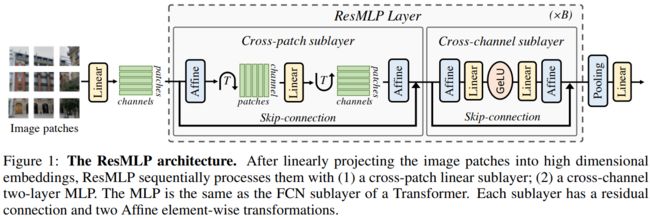
网络的基本block包括一个linear层和一个MLP,其中linear层完成patchs间的信息交互,而MLP则是各个patch的channel间的信息交互。
ResMLP,以N × N个不重叠的 patch 组成的网格作为输入,其中 patch 的大小通常等于16 × 16 。然后,这些 patches 独立通过一层线性层,形成一组![]() 维的embeddings。
维的embeddings。
所得的  embeddings 集合被输入到一个残差多层感知器层序列中,以产生一组
embeddings 集合被输入到一个残差多层感知器层序列中,以产生一组![]() 维输出 embeddings。然后,这些输出嵌入被平均 (“平均池化”) 作为一个 d 维向量来表示图像,该向量被送入线性分类器,以预测与图像相关的标签。训练使用交叉熵损失。
维输出 embeddings。然后,这些输出嵌入被平均 (“平均池化”) 作为一个 d 维向量来表示图像,该向量被送入线性分类器,以预测与图像相关的标签。训练使用交叉熵损失。

The Residual Multi-Perceptron Layer
ResMLP并没有采用LayerNorm,而是采用了一种Affine transformation来进行norm,这种norm方式不需要像LayerNorm那样计算统计值来做归一化,而是直接用两个学习的参数α和β做线性变换。
本文的网络是一系列具有相同结构的层:一个应用于 cross-patch 的线性子层,然后是应用于 cross-channel 的前馈子层。与 Transformer 层类似,每个子层都与跳接并行。self-attention 层的缺失使得训练更加稳定,允许用一个更简单的仿射变换替换层归一化,放射变换如下 所示。
![]()
其中 α 和 β 是可学习的权向量。此操作仅对输入元素进行缩放和移动。
与其他归一化操作相比,这个操作有几个优点:
- 首先,与 Layer Normalization 相比,它在推断时间上没有成本,因为它可以被相邻的线性层吸收。
- 其次,与 BatchNorm 和 Layer Normalization 相反,Aff 操作符不依赖于批统计。
- 与Aff 更接近的算符是 Touvron et al. 引入的 LayerScale,带有额外的偏差项。
为方便起见,用 Aff(X) 表示独立应用于矩阵 X 的每一列的仿射运算。
在每个残差块的开始 (“预归一化”) 和结束 (“后归一化”) 处应用Aff算子,作为一种预规范化Aff取代了 LayerNorm,而不使用通道统计。初始化α=1,β=0。作为后规范化,Aff类似于LayerScale。
ResMLP流程:将一组![]() 维的输入特征堆叠在一个
维的输入特征堆叠在一个![]() 矩阵X中,并输出一组
矩阵X中,并输出一组![]() 维输出特征,堆叠在一个矩阵Y中。其中 A, B 和 C 是该层的主要可学习权矩阵。
维输出特征,堆叠在一个矩阵Y中。其中 A, B 和 C 是该层的主要可学习权矩阵。
Differences with the Vision Transformer architecture
与 Vision Transformer 架构的差异:
ResMLP 体系结构与 ViT 模型密切相关。然而,ResMLP 与 ViT 不同,有几个简化:
• 无 self-attention 块:其被一个没有非线性的线性层所取代,
• 无位置 embedding:线性层隐式编码关于 embedding 位置的信息,
• 没有额外的 “class” tokens:只是在 patch embedding 上使用平均池化,
• 不基于 batch 统计的规范化:使用可学习的仿射运算符。
关键代码
# https://github.com/rishikksh20/ResMLP-pytorch
import torch
import numpy as np
from torch import nn
from einops.layers.torch import Rearrange
class Aff(nn.Module):
def __init__(self, dim):
super().__init__()
self.alpha = nn.Parameter(torch.ones([1, 1, dim]))
self.beta = nn.Parameter(torch.zeros([1, 1, dim]))
def forward(self, x):
x = x * self.alpha + self.beta
return x
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class MLPblock(nn.Module):
def __init__(self, dim, num_patch, mlp_dim, dropout = 0., init_values=1e-4):
super().__init__()
self.pre_affine = Aff(dim)
self.token_mix = nn.Sequential(
Rearrange('b n d -> b d n'),
nn.Linear(num_patch, num_patch),
Rearrange('b d n -> b n d'),
)
self.ff = nn.Sequential(
FeedForward(dim, mlp_dim, dropout),
)
self.post_affine = Aff(dim)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x):
x = self.pre_affine(x)
x = x + self.gamma_1 * self.token_mix(x)
x = self.post_affine(x)
x = x + self.gamma_2 * self.ff(x)
return x
class ResMLP(nn.Module):
def __init__(self, in_channels, dim, num_classes, patch_size, image_size, depth, mlp_dim):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
self.num_patch = (image_size// patch_size) ** 2
self.to_patch_embedding = nn.Sequential(
nn.Conv2d(in_channels, dim, patch_size, patch_size),
Rearrange('b c h w -> b (h w) c'),
)
self.mlp_blocks = nn.ModuleList([])
for _ in range(depth):
self.mlp_blocks.append(MLPblock(dim, self.num_patch, mlp_dim))
self.affine = Aff(dim)
self.mlp_head = nn.Sequential(
nn.Linear(dim, num_classes)
)
def forward(self, x):
x = self.to_patch_embedding(x)
for mlp_block in self.mlp_blocks:
x = mlp_block(x)
x = self.affine(x)
x = x.mean(dim=1)
return self.mlp_head(x)
if __name__ == "__main__":
img = torch.ones([1, 3, 224, 224])
model = ResMLP(in_channels=3, image_size=224, patch_size=16, num_classes=1000,
dim=384, depth=12, mlp_dim=384*4)
parameters = filter(lambda p: p.requires_grad, model.parameters())
parameters = sum([np.prod(p.size()) for p in parameters]) / 1_000_000
print('Trainable Parameters: %.3fM' % parameters)
out_img = model(img)
print("Shape of out :", out_img.shape) # [B, in_channels, image_size, image_size]
MetaFormer Is Actually What You Need for Vision, CVPR2022
论文:https://arxiv.org/abs/2111.11418
代码:https://github.com/sail-sg/poolformer
解读:【图像分类】2022-MetaFormer CVPR_cvpr2022图像分类论文_說詤榢的博客-CSDN博客
MetaFormer:宏观架构才是通用视觉模型真正需要的! - 知乎 (zhihu.com)
MetaFormer is Actually What You Need for Vision - 知乎 (zhihu.com)
摘要
令牌混合器类型不重要,宏观架构才是通用视觉模型真正需要的.
视觉 Transformer 一般性的宏观架构,而不是令牌混合器 (Token Mixer) 对模型的性能更为重要。
本文提出Transformer的成功并不是源于其自注意力结构,而是其广义架构,
通常大家普遍认为基于自注意力的token mixer模块对于Transformer的贡献最大,但最近的工作表明Transformer模型可以被纯MLP 结构替代,并且仍然能够表现得很好,基于这些工作,作者提出了一种假设即Transformer中的自注意力模块并不是最重要的。
为了证明这个假设,通过一个简单的池化操作来替代attention模块来完成最基本的token mixing, 采用池化操作的原因是,池化不需要参数,并且也能够实现token mixing, 得到的模型称之为PoolFormer。
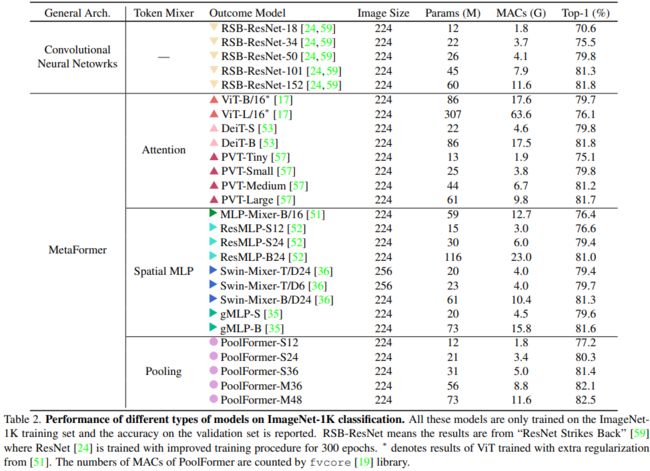
试验结果表明这个模型能够在多个视觉任务中达到很好的表现,比如在ImageNet1K数据集中,能够达到82.1%的准确率,超过DeiT-B(Transformer架构)和ResMLP-B24(MLP架构)的同时还能够大幅减小参数量。

本文的贡献主要有2个方面:
- 首先,将Transformer抽象为一个通用的MetaFormer,并通过经验证明了Transformer/MLP-Like模型的成功很大程度上归因于MetaFormer结构。具体地说,通过只使用一个简单的非参数池化算子作为一个极弱的token mixer,建立了一个简单的模型,发现它仍然可以获得具有很高竞争力的性能。
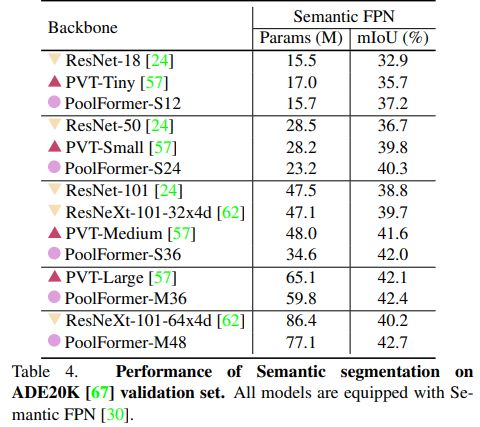
- 其次,对图像分类、目标检测、实例分割和语义分割等多个视觉任务上的PoolFormer进行了评估,发现其与精心设计token mixer的SOTA模型相比具有良好的性能。
PoolFormer方法
从Transformer中抽象出来,MetaFormer是一种通用架构,其中没有指定token mixer,而其他组件与Transformer保持相同。使用一个简单的令牌混合器 (Token Mixer):池化操作 (Pooling)。池化操作只有最最基本的融合不同空间位置信息的能力,它没有任何的权重。
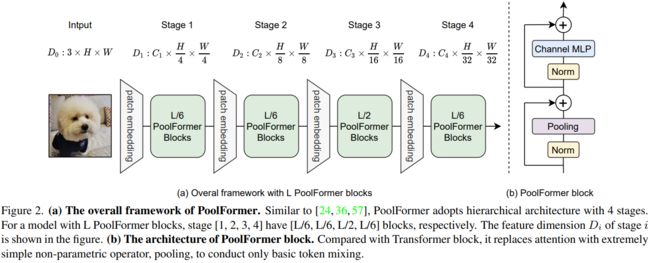
PoolFormer的模型结构

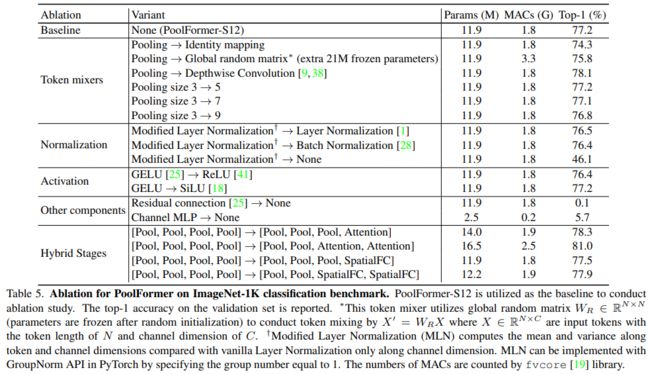
实验


关键代码
# Copyright 2021 Garena Online Private Limited
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
PoolFormer implementation
"""
import os
import copy
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from timm.models.layers.helpers import to_2tuple
# try:
# from mmseg.models.builder import BACKBONES as seg_BACKBONES
# from mmseg.utils import get_root_logger
# from mmcv.runner import _load_checkpoint
# has_mmseg = True
# except ImportError:
# print("If for semantic segmentation, please install mmsegmentation first")
# has_mmseg = False
# try:
# from mmdet.models.builder import BACKBONES as det_BACKBONES
# from mmdet.utils import get_root_logger
# from mmcv.runner import _load_checkpoint
# has_mmdet = True
# except ImportError:
# print("If for detection, please install mmdetection first")
# has_mmdet = False
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .95, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'classifier': 'head',
**kwargs
}
default_cfgs = {
'poolformer_s': _cfg(crop_pct=0.9),
'poolformer_m': _cfg(crop_pct=0.95),
}
class PatchEmbed(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
class LayerNormChannel(nn.Module):
"""
LayerNorm only for Channel Dimension.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, eps=1e-05):
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x):
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight.unsqueeze(-1).unsqueeze(-1) * x \
+ self.bias.unsqueeze(-1).unsqueeze(-1)
return x
class GroupNorm(nn.GroupNorm):
"""
Group Normalization with 1 group.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size//2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class PoolFormerBlock(nn.Module):
"""
Implementation of one PoolFormer block.
--dim: embedding dim
--pool_size: pooling size
--mlp_ratio: mlp expansion ratio
--act_layer: activation
--norm_layer: normalization
--drop: dropout rate
--drop path: Stochastic Depth,
refer to https://arxiv.org/abs/1603.09382
--use_layer_scale, --layer_scale_init_value: LayerScale,
refer to https://arxiv.org/abs/2103.17239
"""
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Pooling(pool_size=pool_size)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
# The following two techniques are useful to train deep PoolFormers.
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def basic_blocks(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
"""
generate PoolFormer blocks for a stage
return: PoolFormer blocks
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PoolFormerBlock(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
blocks = nn.Sequential(*blocks)
return blocks
class PoolFormer(nn.Module):
"""
PoolFormer, the main class of our model
--layers: [x,x,x,x], number of blocks for the 4 stages
--embed_dims, --mlp_ratios, --pool_size: the embedding dims, mlp ratios and
pooling size for the 4 stages
--downsamples: flags to apply downsampling or not
--norm_layer, --act_layer: define the types of normalization and activation
--num_classes: number of classes for the image classification
--in_patch_size, --in_stride, --in_pad: specify the patch embedding
for the input image
--down_patch_size --down_stride --down_pad:
specify the downsample (patch embed.)
--fork_feat: whether output features of the 4 stages, for dense prediction
--init_cfg, --pretrained:
for mmdetection and mmsegmentation to load pretrained weights
"""
def __init__(self, layers, embed_dims=None,
mlp_ratios=None, downsamples=None,
pool_size=3,
norm_layer=GroupNorm, act_layer=nn.GELU,
num_classes=1000,
in_patch_size=7, in_stride=4, in_pad=2,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=False,
init_cfg=None,
pretrained=None,
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PatchEmbed(
patch_size=in_patch_size, stride=in_stride, padding=in_pad,
in_chans=3, embed_dim=embed_dims[0])
# set the main block in network
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios[i],
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i+1]:
# downsampling between two stages
network.append(
PatchEmbed(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i+1]
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
# TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used.
cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...`
"""
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.apply(self.cls_init_weights)
self.init_cfg = copy.deepcopy(init_cfg)
# load pre-trained model
# if self.fork_feat and (
# self.init_cfg is not None or pretrained is not None):
# self.init_weights()
# init for classification
def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
# init for mmdetection or mmsegmentation by loading
# imagenet pre-trained weights
def init_weights(self, pretrained=None):
pass
# logger = get_root_logger()
# if self.init_cfg is None and pretrained is None:
# logger.warn(f'No pre-trained weights for '
# f'{self.__class__.__name__}, '
# f'training start from scratch')
# pass
# else:
# assert 'checkpoint' in self.init_cfg, f'Only support ' \
# f'specify `Pretrained` in ' \
# f'`init_cfg` in ' \
# f'{self.__class__.__name__} '
# if self.init_cfg is not None:
# ckpt_path = self.init_cfg['checkpoint']
# elif pretrained is not None:
# ckpt_path = pretrained
#
# ckpt = _load_checkpoint(
# ckpt_path, logger=logger, map_location='cpu')
# if 'state_dict' in ckpt:
# _state_dict = ckpt['state_dict']
# elif 'model' in ckpt:
# _state_dict = ckpt['model']
# else:
# _state_dict = ckpt
#
# state_dict = _state_dict
# missing_keys, unexpected_keys = \
# self.load_state_dict(state_dict, False)
# show for debug
# print('missing_keys: ', missing_keys)
# print('unexpected_keys: ', unexpected_keys)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
return x
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
if self.fork_feat:
# output the features of four stages for dense prediction
return outs
# output only the features of last layer for image classification
return x
def forward(self, x):
# input embedding
x = self.forward_embeddings(x)
# through backbone
x = self.forward_tokens(x)
if self.fork_feat:
# otuput features of four stages for dense prediction
return x
x = self.norm(x)
cls_out = self.head(x.mean([-2, -1]))
# for image classification
return cls_out
model_urls = {
"poolformer_s12": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s12.pth.tar",
"poolformer_s24": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s24.pth.tar",
"poolformer_s36": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s36.pth.tar",
"poolformer_m36": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_m36.pth.tar",
"poolformer_m48": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_m48.pth.tar",
}
@register_model
def poolformer_s12(pretrained=False, **kwargs):
"""
PoolFormer-S12 model, Params: 12M
--layers: [x,x,x,x], numbers of layers for the four stages
--embed_dims, --mlp_ratios:
embedding dims and mlp ratios for the four stages
--downsamples: flags to apply downsampling or not in four blocks
"""
layers = [2, 2, 6, 2]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s12']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint)
return model
@register_model
def poolformer_s24(pretrained=False, **kwargs):
"""
PoolFormer-S24 model, Params: 21M
"""
layers = [4, 4, 12, 4]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s24']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint)
return model
@register_model
def poolformer_s36(pretrained=False, **kwargs):
"""
PoolFormer-S36 model, Params: 31M
"""
layers = [6, 6, 18, 6]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
# if pretrained:
# url = model_urls['poolformer_s36']
# checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
# model.load_state_dict(checkpoint)
return model
@register_model
def poolformer_m36(pretrained=False, **kwargs):
"""
PoolFormer-M36 model, Params: 56M
"""
layers = [6, 6, 18, 6]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_m']
if pretrained:
url = model_urls['poolformer_m36']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint)
return model
@register_model
def poolformer_m48(pretrained=False, **kwargs):
"""
PoolFormer-M48 model, Params: 73M
"""
layers = [8, 8, 24, 8]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_m']
if pretrained:
url = model_urls['poolformer_m48']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint)
return model
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
model=poolformer_s12(num_classes=10)
y=model(x)
print(y.shape)
# if has_mmseg and has_mmdet:
# """
# The following models are for dense prediction based on
# mmdetection and mmsegmentation
# """
# @seg_BACKBONES.register_module()
# @det_BACKBONES.register_module()
# class poolformer_s12_feat(PoolFormer):
# """
# PoolFormer-S12 model, Params: 12M
# """
# def __init__(self, **kwargs):
# layers = [2, 2, 6, 2]
# embed_dims = [64, 128, 320, 512]
# mlp_ratios = [4, 4, 4, 4]
# downsamples = [True, True, True, True]
# super().__init__(
# layers, embed_dims=embed_dims,
# mlp_ratios=mlp_ratios, downsamples=downsamples,
# fork_feat=True,
# **kwargs)
#
# @seg_BACKBONES.register_module()
# @det_BACKBONES.register_module()
# class poolformer_s24_feat(PoolFormer):
# """
# PoolFormer-S24 model, Params: 21M
# """
# def __init__(self, **kwargs):
# layers = [4, 4, 12, 4]
# embed_dims = [64, 128, 320, 512]
# mlp_ratios = [4, 4, 4, 4]
# downsamples = [True, True, True, True]
# super().__init__(
# layers, embed_dims=embed_dims,
# mlp_ratios=mlp_ratios, downsamples=downsamples,
# fork_feat=True,
# **kwargs)
#
# @seg_BACKBONES.register_module()
# @det_BACKBONES.register_module()
# class poolformer_s36_feat(PoolFormer):
# """
# PoolFormer-S36 model, Params: 31M
# """
# def __init__(self, **kwargs):
# layers = [6, 6, 18, 6]
# embed_dims = [64, 128, 320, 512]
# mlp_ratios = [4, 4, 4, 4]
# downsamples = [True, True, True, True]
# super().__init__(
# layers, embed_dims=embed_dims,
# mlp_ratios=mlp_ratios, downsamples=downsamples,
# layer_scale_init_value=1e-6,
# fork_feat=True,
# **kwargs)
#
# @seg_BACKBONES.register_module()
# @det_BACKBONES.register_module()
# class poolformer_m36_feat(PoolFormer):
# """
# PoolFormer-S36 model, Params: 56M
# """
# def __init__(self, **kwargs):
# layers = [6, 6, 18, 6]
# embed_dims = [96, 192, 384, 768]
# mlp_ratios = [4, 4, 4, 4]
# downsamples = [True, True, True, True]
# super().__init__(
# layers, embed_dims=embed_dims,
# mlp_ratios=mlp_ratios, downsamples=downsamples,
# layer_scale_init_value=1e-6,
# fork_feat=True,
# **kwargs)
#
# @seg_BACKBONES.register_module()
# @det_BACKBONES.register_module()
# class poolformer_m48_feat(PoolFormer):
# """
# PoolFormer-M48 model, Params: 73M
# """
# def __init__(self, **kwargs):
# layers = [8, 8, 24, 8]
# embed_dims = [96, 192, 384, 768]
# mlp_ratios = [4, 4, 4, 4]
# downsamples = [True, True, True, True]
# super().__init__(
# layers, embed_dims=embed_dims,
# mlp_ratios=mlp_ratios, downsamples=downsamples,
# layer_scale_init_value=1e-6,
# fork_feat=True,
# **kwargs)