批量生成ChunJun json任务脚本
最近在研究chunjun,它是一款稳定、易用、高效、批流一体的数据集成框架。一直在用chunjun做数据抽取测试,json任务重复地在写,感觉十分浪费时间,于是想写个自动生成json脚本。
1.设计模板
模板通过excel设计,主要记录任务中一些参数,每一行就是一个任务,如:MySQL库的ip、端口、库表还有hive的库表、hive数据存储路径 等等

2.编写Python代码
2.1.读取模板任务
def readList_extract_Info():
"""
获取 模板 中的 整体 任务 数据
:return: 返回 所有任务 集合
"""
row_count = table.nrows-1
for row_item in range(row_count):
count = row_item+1
list = table.row_values(count)
job_list.append(list)
return job_list2.2.查询表分区并创建添加分区sql
chunjun 好像和 datax一样,不支持动态分区,所以在 数据抽取之前,需要创建分区,自动生成添加分区脚本。
def create_partition(job_list):
sql_list=[]
# 循环 出 每一个 任务 信息
for i in range(len(job_list)):
# 拼接 出 创建 分区 sql
sql = "alter table " + job_list[i][8] + "." + job_list[i][9] + " add if not exists partition("
# 判断 任务 中 是否 为分区表,如果为分区表,那么就要根据 任务 中的分区值 创建分区
if job_list[i][10]=="1":
# 取出 分区 字段名
partN_list = job_list[i][11].split(",")
# 取出 分区 字段值
partV_list = job_list[i][12].split(",")
# 判断 分区字段个数是否 和 分区字段值个数 一致
if len(partN_list)==len(partV_list):
for item in range(len(partN_list)):
# 将 分区字段名称 和 分区字段值 合并 类似:dt="2023",time="2024"
partName = partN_list[item]+"=\""+partV_list[item]+"\" "
if item == len(partN_list)-1:
sql = sql + partName+");"
else:
sql = sql + partName+","
sql_list.append(sql)
print(job_list[i][9]+"---->添加分区sql 创建成功!----> "+sql)
else:
print("分区字段个数不匹配,填写有误,不添加分区")
else:
print(job_list[i][9]+"---->不是分区表")
#判断 存储路径是否存在
if not os.path.exists(output_path):
# 不存在 创建
os.makedirs(output_path)
# 打开 存储文件,并写入 添加分区 sql
with open(os.path.join(output_path, "create_partition_sql.sql"), "w", encoding='UTF-8') as f:
for i in sql_list:
f.write(i+"\n")2.3.获取MySQL连接
def get_connection(mysql_host,mysql_port,mysql_user,mysql_passwd):
return pymysql.connect(host=mysql_host, port=mysql_port, user=mysql_user, passwd=mysql_passwd)2.4.获取数据源表的元数据
获取数据源表的字段名、字段类型
def get_mysql_meta(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd):
"""
获取 mysql的元数据
:param database:
:param table:
:param mysql_host:
:param mysql_port:
:param mysql_user:
:param mysql_passwd:
:return:
"""
connection = get_connection(mysql_host,mysql_port,mysql_user,mysql_passwd)
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS " \
"WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall把字段转换成想要 数组 [map]的形式:

注释:python3 需要把 map 外面再 套一层 list,不然会出异常
def get_mysql_columns(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd):
return list(map(lambda x:{"name":x[0],"type":x[1]},get_mysql_meta(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd)))2.5.数据源表字段类型转换
注释:python3 需要把 map 外面再 套一层 list,不然会出异常
把字段转换成想要 数组 [map]的形式:
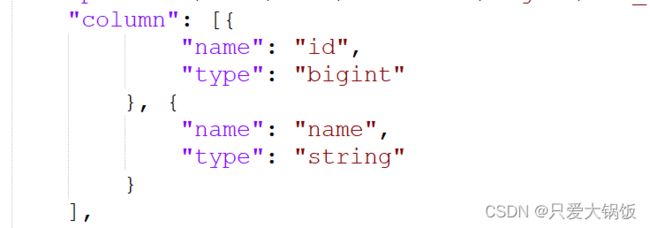
def get_hive_columns(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd)
return list(map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta))2.6.生成json文件模型
def generate_json(list):
# 判断 Hive的存储 路径 是否 填写
if len(list[13])==0:
list[13] ="/user/hive/warehouse/"
# 判断 Hive的存储 路径 最后一个字符 为 /
if list[13][-1]!="/":
list[13]+="/"
# 拼接 hive 文件 存储 路径 /user/hive/warehouse/stg.db/stu/
path = list[13]+list[8]+".db/"+list[9]+"/"
# 判断 是否 有分区 ,循环 分区
if list[10]=="1":
partN_list = list[11].split(",")
partV_list = list[12].split(",")
if len(partN_list) == len(partV_list):
# hive 表若有分区,它的存储路径拼接 /user/hive/warehouse/stg.db/stu/dt=2023/time=2024
for item in range(len(partN_list)):
partName = partN_list[item] + "=" + partV_list[item] + "/"
path=path+partName
job = {"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": list[2],
"password": list[3],
"column": get_mysql_columns(list[4], list[5],list[0],int(list[1]),list[2],list[3]),
"splitPk": "",
"connection": [{
"table": [list[5]],
"jdbcUrl": ["jdbc:mysql://" + list[0] + ":" + str(int(list[1])) + "/" + list[4]]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + list[6] + ":" + str(int(list[7])),
"fileType": list[15],
"path": path,
#"fileName": source_table,
"column": get_hive_columns(list[4], list[5],list[0],int(list[1]),list[2],list[3]),
"writeMode": list[14],
"fieldDelimiter": "\t"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([list[8], list[9], "json"])), "w", encoding='UTF-8') as f:
json.dump(job, f)
print("数据源表:" + list[5] + " 数据抽取到目标表:" + list[9] + " [chunjun json脚本已创建在【"+output_path+"】目录下]")3.整体代码
# ecoding=utf-8
import json
import getopt
import os
import sys
import pymysql
import xlrd
# 打开文件
data = xlrd.open_workbook("F:\\模板.xlsx")
# 获取第一个sheet内容
table = data.sheet_by_index(0)
job_list=[]
#生成添加分区文件和json脚本的目标路径,可根据实际情况作出修改
output_path = "F:\\"
def readList_extract_Info():
"""
获取 模板 中的 整体 任务 数据
:return: 返回 所有任务 集合
"""
row_count = table.nrows-1
for row_item in range(row_count):
count = row_item+1
list = table.row_values(count)
job_list.append(list)
return job_list
def create_partition(job_list):
sql_list=[]
# 循环 出 每一个 任务 信息
for i in range(len(job_list)):
# 拼接 出 创建 分区 sql
sql = "alter table " + job_list[i][8] + "." + job_list[i][9] + " add if not exists partition("
# 判断 任务 中 是否 为分区表,如果为分区表,那么就要根据 任务 中的分区值 创建分区
if job_list[i][10]=="1":
# 取出 分区 字段名
partN_list = job_list[i][11].split(",")
# 取出 分区 字段值
partV_list = job_list[i][12].split(",")
# 判断 分区字段个数是否 和 分区字段值个数 一致
if len(partN_list)==len(partV_list):
for item in range(len(partN_list)):
# 将 分区字段名称 和 分区字段值 合并 类似:dt="2023",time="2024"
partName = partN_list[item]+"=\""+partV_list[item]+"\" "
if item == len(partN_list)-1:
sql = sql + partName+");"
else:
sql = sql + partName+","
sql_list.append(sql)
print(job_list[i][9]+"---->添加分区sql 创建成功!----> "+sql)
else:
print("分区字段个数不匹配,填写有误,不添加分区")
else:
print(job_list[i][9]+"---->不是分区表")
#判断 存储路径是否存在
if not os.path.exists(output_path):
# 不存在 创建
os.makedirs(output_path)
# 打开 存储文件,并写入 添加分区 sql
with open(os.path.join(output_path, "create_partition_sql"), "w", encoding='UTF-8') as f:
for i in sql_list:
f.write(i+"\n")
def get_connection(mysql_host,mysql_port,mysql_user,mysql_passwd):
"""
mysql 连接
:param mysql_host:
:param mysql_port:
:param mysql_user:
:param mysql_passwd:
:return:
"""
return pymysql.connect(host=mysql_host, port=mysql_port, user=mysql_user, passwd=mysql_passwd)
def get_mysql_meta(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd):
"""
获取 mysql的元数据
:param database:
:param table:
:param mysql_host:
:param mysql_port:
:param mysql_user:
:param mysql_passwd:
:return:
"""
connection = get_connection(mysql_host,mysql_port,mysql_user,mysql_passwd)
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS " \
"WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_mysql_columns(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd):
"""
获取 mysql 表 字段
:param database:
:param table:
:param mysql_host:
:param mysql_port:
:param mysql_user:
:param mysql_passwd:
:return:
"""
return list(map(lambda x:{"name":x[0],"type":x[1]},get_mysql_meta(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd)))
def get_hive_columns(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table,mysql_host,mysql_port,mysql_user,mysql_passwd)
return list(map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta))
def generate_json(list):
# 判断 Hive的存储 路径 是否 填写
if len(list[13])==0:
list[13] ="/user/hive/warehouse/"
# 判断 Hive的存储 路径 最后一个字符 为 /
if list[13][-1]!="/":
list[13]+="/"
# 拼接 hive 文件 存储 路径 /user/hive/warehouse/stg.db/stu/
path = list[13]+list[8]+".db/"+list[9]+"/"
# 判断 是否 有分区 ,循环 分区
if list[10]=="1":
partN_list = list[11].split(",")
partV_list = list[12].split(",")
if len(partN_list) == len(partV_list):
# hive 表若有分区,它的存储路径拼接 /user/hive/warehouse/stg.db/stu/dt=2023/time=2024
for item in range(len(partN_list)):
partName = partN_list[item] + "=" + partV_list[item] + "/"
path=path+partName
job = {"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": list[2],
"password": list[3],
"column": get_mysql_columns(list[4], list[5],list[0],int(list[1]),list[2],list[3]),
"splitPk": "",
"connection": [{
"table": [list[5]],
"jdbcUrl": ["jdbc:mysql://" + list[0] + ":" + str(int(list[1])) + "/" + list[4]]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + list[6] + ":" + str(int(list[7])),
"fileType": list[15],
"path": path,
#"fileName": source_table,
"column": get_hive_columns(list[4], list[5],list[0],int(list[1]),list[2],list[3]),
"writeMode": list[14],
"fieldDelimiter": "\t"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([list[8], list[9], "json"])), "w", encoding='UTF-8') as f:
json.dump(job, f)
print("数据源表:" + list[5] + " 数据抽取到目标表:" + list[9] + " [chunjun json脚本已创建在【"+output_path+"】目录下]")
if __name__ == '__main__':
job_list=readList_extract_Info()
create_partition(job_list)
for i in job_list:
generate_json(i)
4.运行结果
代码运行结果:

产出脚本:

create_partition_sql.sql

stg.stu_no_part.json
notepadt++ 格式化代码
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "000000",
"column": [{
"name": "id",
"type": "int"
}, {
"name": "name",
"type": "varchar"
}
],
"splitPk": "",
"connection": [{
"table": ["stu"],
"jdbcUrl": ["jdbc:mysql://192.168.233.130:3306/test"]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://192.168.233.130:8020",
"fileType": "text",
"path": "/user/hive/warehouse/stg.db/stu_no_part/",
"column": [{
"name": "id",
"type": "bigint"
}, {
"name": "name",
"type": "string"
}
],
"writeMode": "append",
"fieldDelimiter": "\t"
}
}
}
]
}
}