Python爬虫的urlib的学习(学习于b站尚硅谷)
目录
- 一、页面结构的介绍
-
- 1.学习目标
- 2.为什么要了解页面(html)
- 3. html中的标签(仅介绍了含表格、无序列表、有序列表、超链接)
- 4.本节的演示
- 二、Urllib
-
- 1.什么是互联网爬虫?
- 2.爬虫核心
- 3.爬虫的用途
- 4.爬虫的分类(通用爬虫、聚焦爬虫)
- 5.反爬手段
- 6.urllib库使用
- 7.获取百度的页面源码的演示
- 8. urllib的1个类型和6个方法的演示
-
- (1)数据类型是HTTPResponse
- (2)read()方法
- (3)readline()方法与readlines()
- (4)返回状态码getcode()
- (5)返回url地址geturl()
- (6)获取状态信息getheaders()
- 9. urllib_下载(下载网页、图片与视频)的演示
- 10.请求对象的定制
-
- (1)url的组成
- (2)User Agent的引入
- (2)User Agent(简称UA)介绍
- (3)代码演示
- 11.编解码
-
- (1)编码的由来
- (2)get请求的quote方法
- (3)get请求的quote方法的演示
- (4)get请求的urlencode方法
- (5)get请求的urlencode方法的演示
- (6)寻找爬虫的请求地址的示例(以百度翻译翻译单词为例)
- (7)post请求百度翻译的演示
- (8)post请求百度翻译之详细翻译的演示(出现反爬的第二种手段,Cookie)
- 12. ajax的get请求
-
- (1)ajax的get请求豆瓣电影第一页
- (2)ajax的get请求豆瓣电影前十页
- 13. ajax的post请求
- 14.爬虫常见的两个异常(URLError\HTTPError)
-
- (1)简介
- (2)代码演示
- 15.微博的cookie登陆
- 16.Handler处理器的基本使用
-
- (1)为什么要学习handler
- (2)代码演示(handler的语法参考演示的代码)
- 17.代理
-
- (1)代理的作用以及步骤
- (2)代码演示
- 18.代理池
说明:该文章是学习 尚硅谷在B站上分享的视频 Python爬虫教程小白零基础速通的 p51-104而记录的笔记,笔记来源于本人,关于python基础可以去CSDN上阅读本人学习黑马程序员的笔记。 若有侵权,请联系本人删除。笔记难免可能出现错误或笔误,若读者发现笔记有错误,欢迎在评论里批评指正。
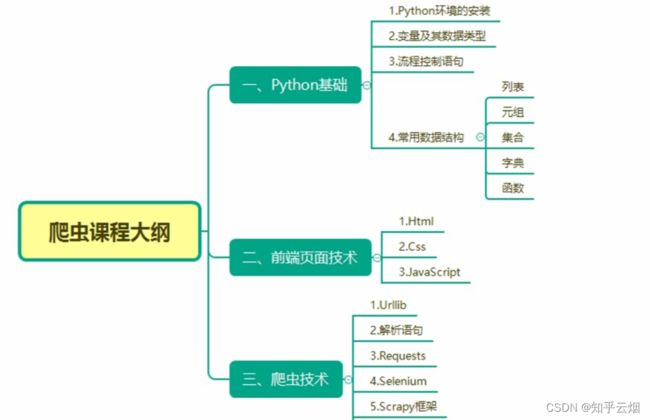
一、页面结构的介绍
1.学习目标
1简单了解html的基础语法。
2.为什么要了解页面(html)
如图,比如打开京东的页面,如果对京东售卖物品的分类感兴趣,想要爬取左侧信息。右键,打开检查。

之后,可以看到该网页的html代码,我们需要它的标签结构后,才能针对需要的汉字进行爬取。

3. html中的标签(仅介绍了含表格、无序列表、有序列表、超链接)
HTML是超文本标记语言(HyperText Markup Language)的缩写,是一种用于创建网页结构和内容的标记语言。它是构建和呈现网页的基本语言,用于描述网页的结构,包括文本、图像、链接、多媒体等元素的布局和排版。




4.本节的演示
如下图所示,打开软件,创建一个包含名为“爬虫的学习(尚硅谷)”文件夹的项目,然后创建文件“051_页面结构的介绍.html”。



编写代码后,直接点击浏览器,查看对应效果。代码如下,可参考注释进行理解。
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标题title>
head>
<body>
<table width="200px" height="20px" border="1px">
<tr>
<td>
姓名
td>
<td>
年龄
td>
<td>
性别
td>
tr>
<tr>
<td>
张三
td>
<td>
18
td>
<td>
男
td>
tr>
table>
<ul>
<li>铁锅炖大鹅li>
<li>小鸡炖蘑菇li>
<li>锅包肉li>
ul>
<ol>
<li>穿上衣服li>
<li>下床li>
<li>洗漱li>
ol>
<a href="http://www.atguigu.com/">尚硅谷a>
body>
html>

二、Urllib
1.什么是互联网爬虫?

如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据。
解释1:通过一个程序,根据Url(如http:/www.taobao.com)进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
2.爬虫核心
1.爬取网页:爬取整个网页包含了网页中所有的内容
2.解析数据:将网页中得到的数据进行解析
3.难点:爬虫和反爬虫之间的博弈
3.爬虫的用途

4.爬虫的分类(通用爬虫、聚焦爬虫)

5.反爬手段

6.urllib库使用

7.获取百度的页面源码的演示
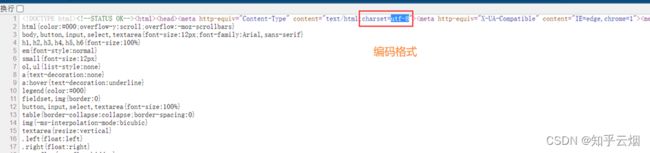
本次将以获取百度的页面源码为例,进行演示。首先,如下图,查看百度的页面源代码,知道待会需要获取的内容。然后从其中的html代码中找到编码格式,即html中的charset的值。
先打开软件,创建一个名为“053_urllib的基本使用”的py文件。


编写代码并运行。代码如下,可参考注释进行理解。然后将鼠标的光标放到运行结果上,使用搜索快捷键Ctr+F,可以搜索到“百度”。
"""
使用urllib来获取百度首页的源码
"""
import urllib.request
# 1.定义一个url,即要访问的地址
url = 'http://www.baidu.com'
# 2.模拟浏览器向服务器发送请求,即使用urlopen模拟浏览器打开网址
# ---> 服务器收到请求后,会进行反馈,包含状态码、页内源码、URL地址等等
response = urllib.request.urlopen(url)
# 3.获取响应中的页面的源码
# read方法 返回的是字节形式的二进制数据 ————数据为b'....'的形式
# 需要将二进制的数据转换成字符串
# 解码 (二进制 ---> 字符串) decode('编码格式') 编码格式对应于html中的charset的值
content = response.read().decode('UTF-8')
# 4.打印数据
print(content)
8. urllib的1个类型和6个方法的演示
(1)数据类型是HTTPResponse
创建一个名为“054_urllib的1个类型和6个方法”的py文件。

首先,如下编写代码,发现传回的数据类型是HTTPResponse,需要记住。
"""
urllib的1个类型和6个方法的演示
"""
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器向服务器发送请求
response =urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
print(type(response))

(2)read()方法
read()方法是按照一字节一字节的方式读取数据,故效率不是很高,如下编写代码并运行。
"""
urllib的1个类型和6个方法的演示
"""
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
# # - 1个类型
# print(type(response))
# - 6个方法
# 按照一字节一字节的方式读取数据
content = response.read()
print(content)

如下图所示,仅仅在方法read()里面加一个数字“5”,可以达到仅读取5个字节的效果。

(3)readline()方法与readlines()
readline()方法仅仅只读取一行,如下编程并运行。
"""
urllib的1个类型和6个方法的演示
"""
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
# # - 1个类型
# print(type(response))
# - 6个方法
# # 按照一字节一字节的方式读取数据
# content = response.read()
# print(content)
# # 返回5个字节
# content = response.read(5)
# print(content)
# 仅读取一行
content = response.readline()
print(content)

readlines()方法按行读完,如下编程并运行。
"""
urllib的1个类型和6个方法的演示
"""
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
# # - 1个类型
# print(type(response))
# - 6个方法
# # 按照一字节一字节的方式读取数据
# content = response.read()
# print(content)
# # 返回5个字节
# content = response.read(5)
# print(content)
# # 仅读取一行
# content = response.readline()
# print(content)
# 按行读完
content = response.readlines()
print(content)

(4)返回状态码getcode()
返回的状态码如果是200,则证明逻辑没有错;如果返回404等逻辑就有错。如下编程并运行。
"""
urllib的1个类型和6个方法的演示
"""
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
# # - 1个类型
# print(type(response))
# - 6个方法
# 返回状态码
print(response.getcode())

(5)返回url地址geturl()
如下编程并运行。
"""
urllib的1个类型和6个方法的演示
"""
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
# # - 1个类型
# print(type(response))
# - 6个方法
# 返回url地址
print(response.geturl())

(6)获取状态信息getheaders()
如下编程并运行。
"""
urllib的1个类型和6个方法的演示
"""
import urllib.request
url = "http://www.baidu.com"
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 一个类型和六个方法
# response是HTTPResponse的类型
# # - 1个类型
# print(type(response))
# - 6个方法
# 获取状态信息
print(response.getheaders())

9. urllib_下载(下载网页、图片与视频)的演示
创建一个名为“055_urllib_下载”的py文件。
首先,如下图所示,编写代码来下载一个网页。
"""
urllib_下载的演示
"""
import urllib.request
# 下载网页
url_page = "http://www.baidu.com"
urllib.request.urlretrieve(url=url_page,filename='百度.html') # 两个参数: url:网址(下载路径);filename:文件名
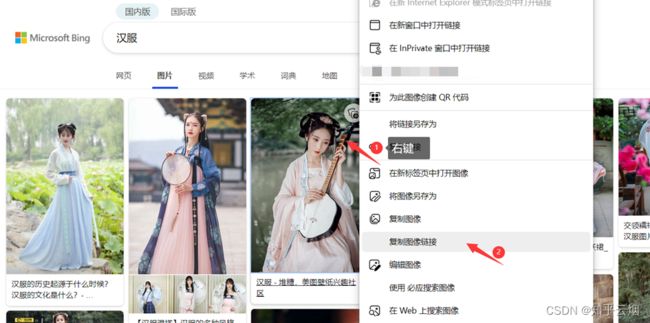
对于图片,比如搜一搜汉服,把喜欢的图片的链接通过右键、点击“复制图像链接”复制下来,放到PyCharm中,然后进行编程并运行。
"""
urllib_下载的演示
"""
import urllib.request
# 下载网页
# url_page = "http://www.baidu.com"
# urllib.request.urlretrieve(url=url_page, filename='百度.html') # 两个参数: url:网址(下载路径);filename:文件名
# 下载图片
url_img = "https://tse2-mm.cn.bing.net/th/id/OIP-C.k_bHY2iwL4tU5aT-NTZZ0wHaK_?w=182&h=270&c=7&r=0&o=5&dpr=1.5&pid=1.7"
urllib.request.urlretrieve(url_img, "汉服.png")

对于视频,找到一个能爬的(网址为“https://haokan.baidu.com/v?vid=15872748450455265454”,好多目前爬不了),然右键点击检查,再点击箭头并点击需要锁定的视频处,再在一串代码中找到vedio后src内的视频网址,双击视频网址后再复制。将该网址放到PyCharm中,然后进行编程并运行。(视频文件录成jif太大,只能来点图)
"""
urllib_下载的演示
"""
import urllib.request
# 下载网页
# url_page = "http://www.baidu.com"
# urllib.request.urlretrieve(url=url_page, filename='百度.html') # 两个参数: url:网址(下载路径);filename:文件名
# 下载图片
# url_img = "https://tse2-mm.cn.bing.net/th/id/OIP-C.k_bHY2iwL4tU5aT-NTZZ0wHaK_?w=182&h=270&c=7&r=0&o=5&dpr=1.5&pid=1.7"
# urllib.request.urlretrieve(url_img, "汉服.png")
# 下载视频
url_vedio = "https://vd3.bdstatic.com/mda-pfkn5iha3dssefej/1080p/cae_h264/1687362569032960204/mda-pfkn5iha3dssefej.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1690033157-0-0-2d1b3f972dbbf20fc58570f68a0feff9&bcevod_channel=searchbox_feed&cr=3&cd=0&pd=1&pt=3&logid=2357674890&vid=15872748450455265454&abtest=111611_3&klogid=2357674890"
urllib.request.urlretrieve(url_vedio, "视频.mp4")





10.请求对象的定制
(1)url的组成

注:上图所示的网址的前部分,粘贴到其他地方后有所变化,这是由于编码的不同导致的,粘贴到Visio后的编码是Unicode编码。另外,保留wd值前面的内容后,网页照样正常使用,说明wd后面的内容可能是广告等。

(2)User Agent的引入

如图,之所以爬取的信息比较少,是因为给的信息不够,导致遇到了反爬。产生这种反爬现象的原因就是缺少User Agent。
(2)User Agent(简称UA)介绍

因此,需要伪装一下,可以去网上查一下UA,选择需要的UA。或者如下图,查询并使用自己的UA。

(3)代码演示
先打开软件,创建一个名为“056_请求对象的定制”的py文件。


如下编写代码后,也能获取网页为“https”开头的url的页面源代码了。
import urllib.request
url = "https://www.baidu.com"
'''
因为urlopen方法中不能存储字典,导致headers不能传递进去
所以需要请求对象的定制
'''
# 请求对象定制
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'}
request = urllib.request.Request(url=url, headers=headers) # 此处需关键字传参
response = urllib.request.urlopen(request)
content = response.read().decode('UTF-8')
print(content)
11.编解码
(1)编码的由来

注:a的ASCII码为97,A为65,0为48。
(2)get请求的quote方法
首先,看看get请求在浏览器的代码检查中的位置。

对于get请求的quote方法,它能将汉字等字符转成Unicode编码,代码示例如下。
import urllib.parse
print(urllib.parse.quote(‘周杰伦’))

(3)get请求的quote方法的演示
先打开软件,创建一个名为“057_get请求的quote方法”的py文件。

如下图,本次的需求是获取此网页(即“https://cn.bing.com/search?q=周杰伦”)的页面源码。
由于网址中存在汉字,需要将其中的汉字转变成Unicode编码,如下图,进行编码并运行,确认转换的网址没有问题。
"""
需求 获取“https://cn.bing.com/search?q=周杰伦”的网页源码
# https://cn.bing.com/search?q=%E5%91%A8%E6%9D%B0%E4%BC%A6
"""
import urllib.request
import urllib.parse
# url = "https://cn.bing.com/search?q=周杰伦"
url = "https://cn.bing.com/search?q="
'''
url需将汉字转变成Unicode编码,这是因为ASCII码中没有“周杰伦”这三个字
需要使用urllib.parse下的quote方法
'''
url += urllib.parse.quote('周杰伦')
print(url)

继续编写代码,即可得到该网址的页面源码。
"""
需求 获取“https://cn.bing.com/search?q=周杰伦”的网页源码
# https://cn.bing.com/search?q=%E5%91%A8%E6%9D%B0%E4%BC%A6
"""
import urllib.request
import urllib.parse
# url = "https://cn.bing.com/search?q=周杰伦"
url = "https://cn.bing.com/search?q="
'''
url需将汉字转变成Unicode编码,这是因为ASCII码中没有“周杰伦”这三个字
需要使用urllib.parse下的quote方法
'''
url += urllib.parse.quote('周杰伦')
# print(url) # 测试语句
# 请求对象定制(使用UA),解决反爬的第一种手段
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode("UTF-8")
print(content)
(4)get请求的urlencode方法

对于get请求的quote方法,它只能将一个词转为Unicode编码。当一个网址中出现了多处为汉字的时候,比如“https://cn.bing.com/search?q=周杰伦&sex=男”,该方法使用起来很不方便。
get请求的urlencode方法的应用场景和语法如下图所示。


(5)get请求的urlencode方法的演示
先打开软件,创建一个名为“058_get请求的urlencode方法”的py文件。本次需要获取“https://cn.bing.com/search?q=周杰伦&sex=男&location=中国台湾省”的网页源码。


由于网址中存在汉字,需要将其中的汉字转变成Unicode编码,如下图,进行编码并运行,确认转换的网址没有问题。
"""
get请求的urlencode方法的演示 - 获取下面网址的页面源码
https://cn.bing.com/search?q=周杰伦&sex=男&location=中国台湾省
"""
import urllib.request
import urllib.parse
# 请求资源路径
base_url = 'https://cn.bing.com/search?'
data = {
'q': '周杰伦',
'sex': '男',
'location': '中国台湾省'
}
new_data = urllib.parse.urlencode(data)
url = base_url + new_data
print(url) # 测试代码
继续编写代码,即可得到该网址的页面源码。
"""
get请求的urlencode方法的演示 - 获取下面网址的页面源码
https://cn.bing.com/search?q=周杰伦&sex=男&location=中国台湾省
"""
import urllib.request
import urllib.parse
# 请求资源路径
base_url = 'https://cn.bing.com/search?'
data = {
'q': '周杰伦',
'sex': '男',
'location': '中国台湾省'
}
new_data = urllib.parse.urlencode(data)
url = base_url + new_data
# print(url) # 测试代码
# 请求对象定制(使用UA),解决反爬的第一种手段
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
request = urllib.request.Request(url=url, headers=headers)
# 模拟服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码的数据
content = response.read().decode('UTF-8')
print(content)
(6)寻找爬虫的请求地址的示例(以百度翻译翻译单词为例)
如下图,在百度翻译页面中打开检查里的网络,输入“spider”时,可以在网络里看到很多次请求组成新的页面,在这一堆请求中,哪些才是我们想要的数据呢?才是翻译的接口?该如何寻找呢?
显然图片格式“jpg”、“png”都不是,找其他的对应的负载,然后再慢慢观察。最后发现sug文件记录了输入的“spider”。

然后点击预览,进而验证这就是我们需要的数据,找到我们想要的接口(显示“spider”的sug请求)。


那么怎么通过爬虫程序获取到这个数据呢?查看该sug标头里面的信息,可以知道它的请求地址为“https://fanyi.baidu.com/sug”,请求方式为“POST”。在负载中,发现它的请求参数为“spider”。

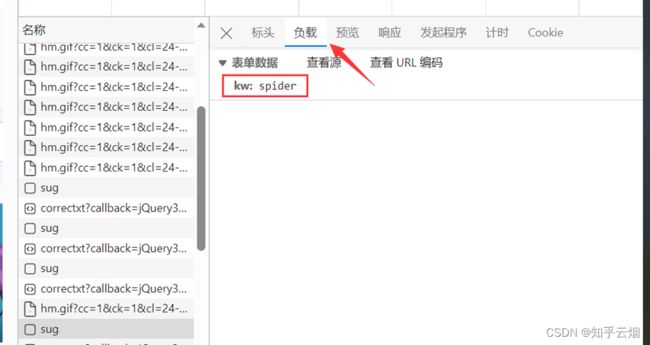
参数寻找完毕。需要注意的是,后面在编程时,post请求的参数在转变成Unicode字符后,还需要进行“UTF-8”的编码;post参数是不能直接拼接在url(即请求地址)后面的,而是需要放在请求对象定制的参数中,这一点与get请求不同。
(7)post请求百度翻译的演示
先打开软件,创建一个名为“059_post请求百度翻译”的py文件。


如下进行编程并运行,发现获取的数据的格式为json。
"""
post请求百度翻译的演示
"""
import urllib.request
import urllib.parse
# 请求地址 - 从百度翻译的检查的网络里直接复制过来
url = 'https://fanyi.baidu.com/sug'
# post请求的参数 (必须要进行编码)
data = {
'kw': 'spider'
}
data = urllib.parse.urlencode(data).encode('UTF-8')
# 请求对象定制(使用UA),解决反爬的第一种手段。
# Request还可以将参数和请求地址产生一种联系
# 注:post参数是不会直接拼接在url(即请求地址)后面的,而是需要放在请求对象定制的参数中。
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
request = urllib.request.Request(url=url, data=data, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('UTF-8')
print(content) # 测试代码
print(type(content))

继续编程并运行。
"""
post请求百度翻译的演示
"""
import urllib.request
import urllib.parse
import json
# 请求地址 - 从百度翻译的检查的网络里直接复制过来
url = 'https://fanyi.baidu.com/sug'
# post请求的参数 (必须要进行编码)
data = {
'kw': 'spider'
}
data = urllib.parse.urlencode(data).encode('UTF-8')
# 请求对象定制(使用UA),解决反爬的第一种手段。
# Request还可以将参数和请求地址产生一种联系
# 注:post参数是不会直接拼接在url(即请求地址)后面的,而是需要放在请求对象定制的参数中。
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
request = urllib.request.Request(url=url, data=data, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('UTF-8')
print(content) # 测试代码
print(type(content))
# 将json字符串转为python中的json对象,这样就能显示其中的中文了
obj = json.loads(content)
print(obj)

(8)post请求百度翻译之详细翻译的演示(出现反爬的第二种手段,Cookie)
在百度翻译中,还有一个以“v2trans”开头的详细翻译的接口,同样的可以去它的请求地址、请求方法与请求参数,发现请求参数变多了。本次将演示详细翻译的数据爬取,目的是:将再次熟悉百度翻译的post请求以及认识一个新的反爬手段。


打开软件,创建一个名为“060_post请求百度翻译之详细翻译”的py文件。


输入下列代码后运行,会出现未知错误,这是因为未向服务器说明自己的请求标头的信息(第二个反爬手段)。
"""
post请求百度翻译之详细翻译的演示
"""
import urllib.request
import urllib.parse
import json
# 先将接口地址复制过来
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
# 参数
data = {
'from': 'en',
'to': 'zh',
'query': 'spider',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '63766.268839',
'token': '9f53213d7ab95e5ac27fd0c681269057',
'domain': 'common',
'ts': '1690240111733'
}
# post请求的参数必须要进行编码(调用encode编码)
data = urllib.parse.urlencode(data).encode('UTF-8')
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制(使用UA),解决反爬的第一种手段。
request = urllib.request.Request(url=url, data=data, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('UTF-8')
print(content) # 测试代码
print(type(content))
# 将json字符串转为python中的json对象,这样就能显示其中的中文了
obj = json.loads(content)
print(obj)


于是将请求标头复制到代码中,并注释一行,发现能有结果。然后再在标头里慢慢注释,发现仅需要“Cookie”就能得到我们想要的结果。


12. ajax的get请求
本次将以第一个案例熟悉本次演示需要熟悉的网页,用第二个案例介绍ajax的get请求。
(1)ajax的get请求豆瓣电影第一页
如下图所示,打开豆瓣网站(https://movie.douban.com/),选择排行榜,选择想要关注的电影类型,比如“动作”。
如下图,打开检查里的网络,再刷新一下网页。现在需要思考哪一个接口才是我们需要找的?
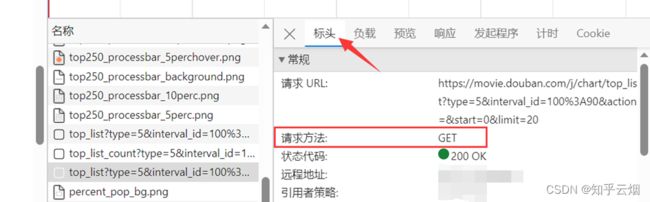
然后一个一个接口不断寻找,找到后,发现接口如下图所示,而且每页是20个电影。


然后点击标头,发现这是一个get请求。
打开软件,创建一个名为“061_ajax的get请求豆瓣电影第一页”的py文件。

将刚刚所找到的接口的请求地址复制到PyCharm中,然后再进行编程并运行。

"""
获取豆瓣电影的第一页的数据并且保存起来
- get请求
"""
import urllib.request
import json
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 1.请求对象定制(使用UA),解决反爬的第一种手段
request = urllib.request.Request(url=url, headers=headers)
# 2.模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 3.获取响应的数据
content = response.read().decode('UTF-8')
# 4.处理数据(本人加的,只获取感兴趣的内容。 如果有不懂的,可以去阅读本人的CSDN上的python入门中有关json的部分。)
# 假设本次只想储存序号和电影名字
content = json.loads(content)
content_changed = []
for index in content:
content_changed.append({'rank': index['rank'], 'title': index['title']})
content_changed = json.dumps(content_changed,ensure_ascii=False)
# ensure_ascii=False表示不用转换成ASCII码 如果为了节省空间,请不要写ensure_ascii=False
# 5.数据下载到本地
'''
open方法默认情况下使用的是gbk的编码
- 如果我们要想保存汉字那么需要在open方法中指定编码格式为utf-8
'''
# 法1
# fp = open('douban.json', 'w', encoding='UTF-8')
# fp.write(content)
# fp.close() # 别忘了关闭文件
# 法2
with open('douban.json', 'w', encoding='utf-8') as fp:
fp.write(content_changed)
(2)ajax的get请求豆瓣电影前十页
如图所示,豆瓣排行榜的动作电影不止一页,鼠标滚轮向下滚动,会发现:随着页面的向下,它会不断地向下加载。这个操作的后端使用的是ajax。如何拿到前十页的数据是本次的关键。
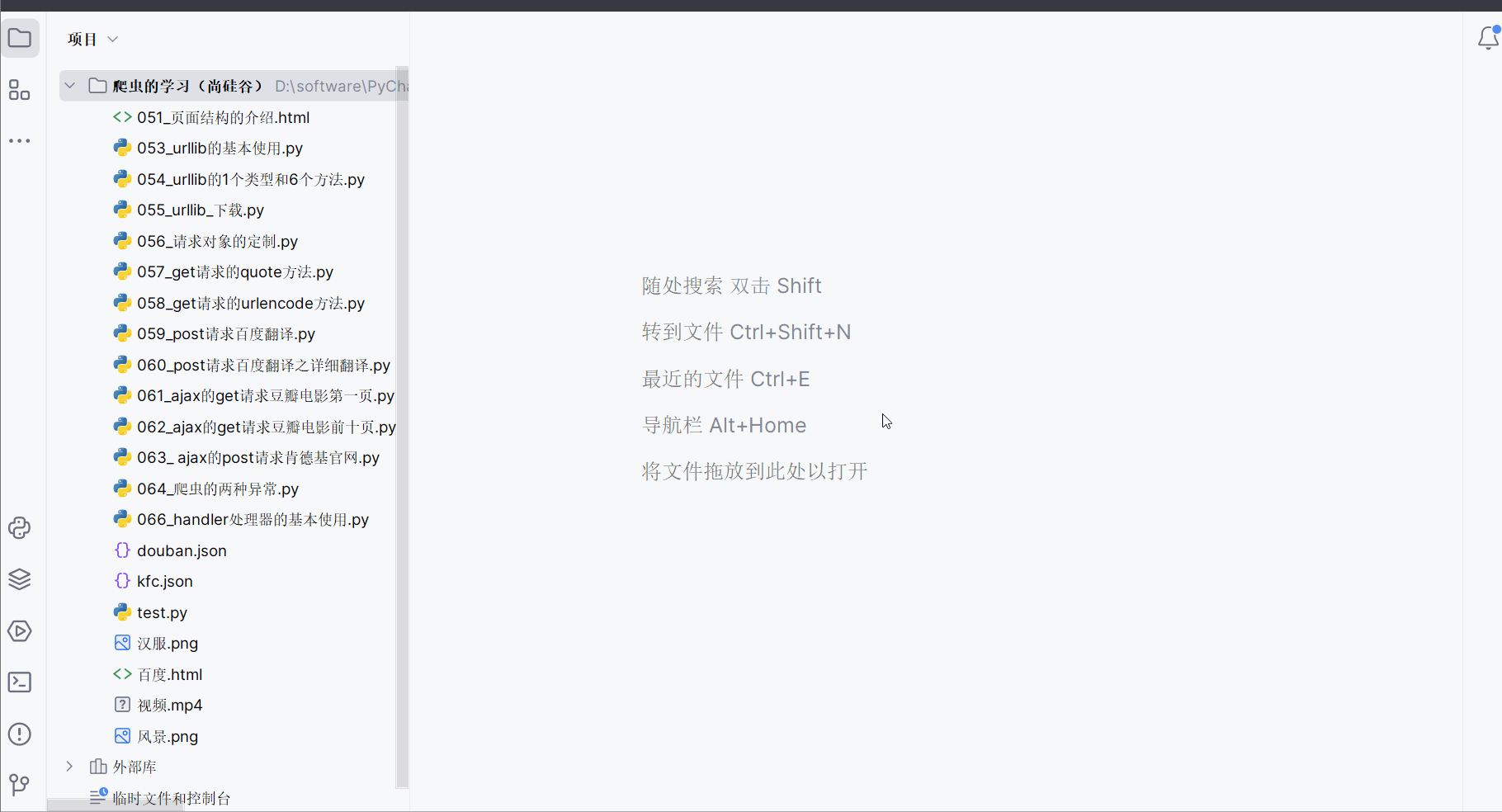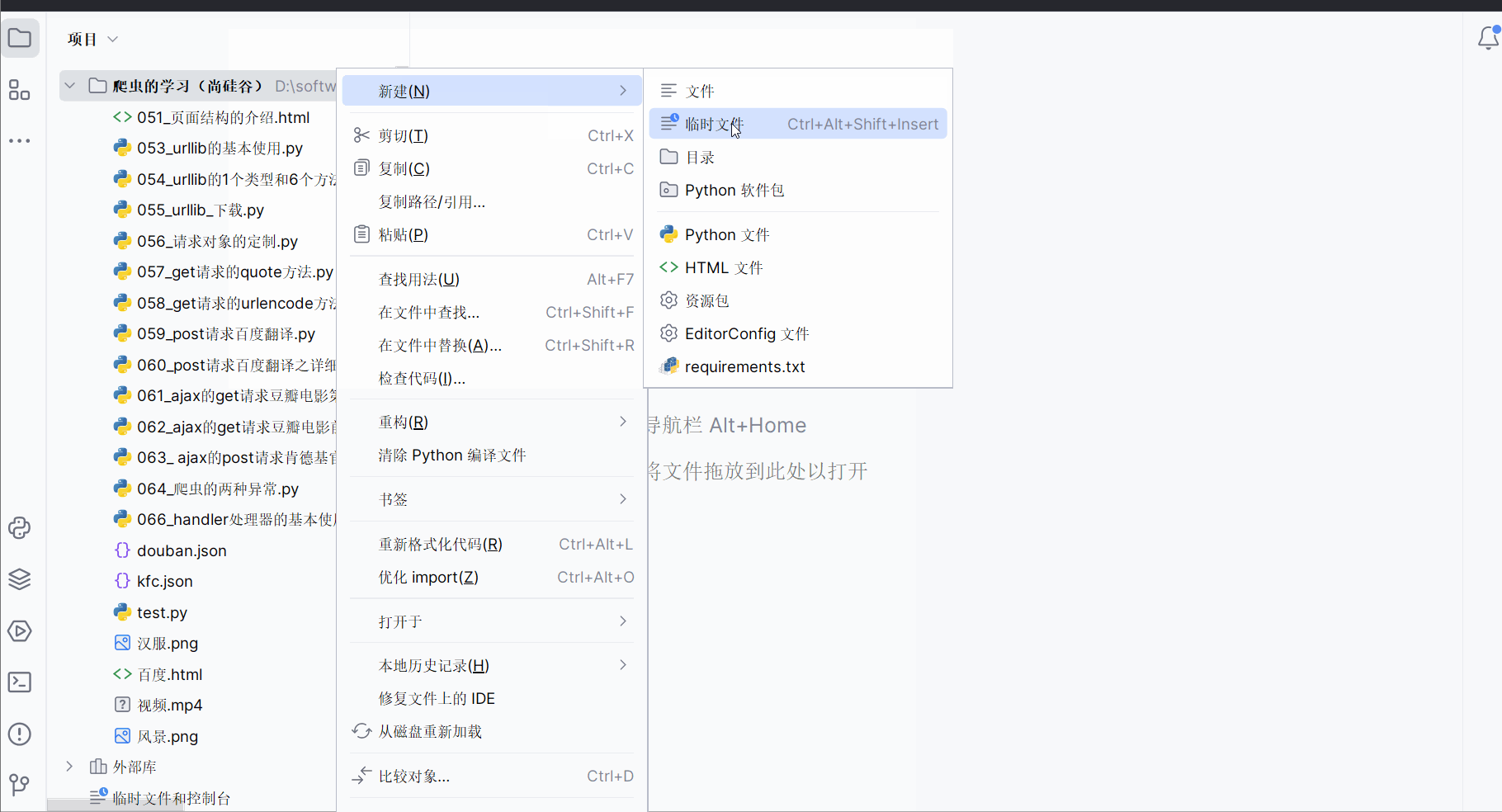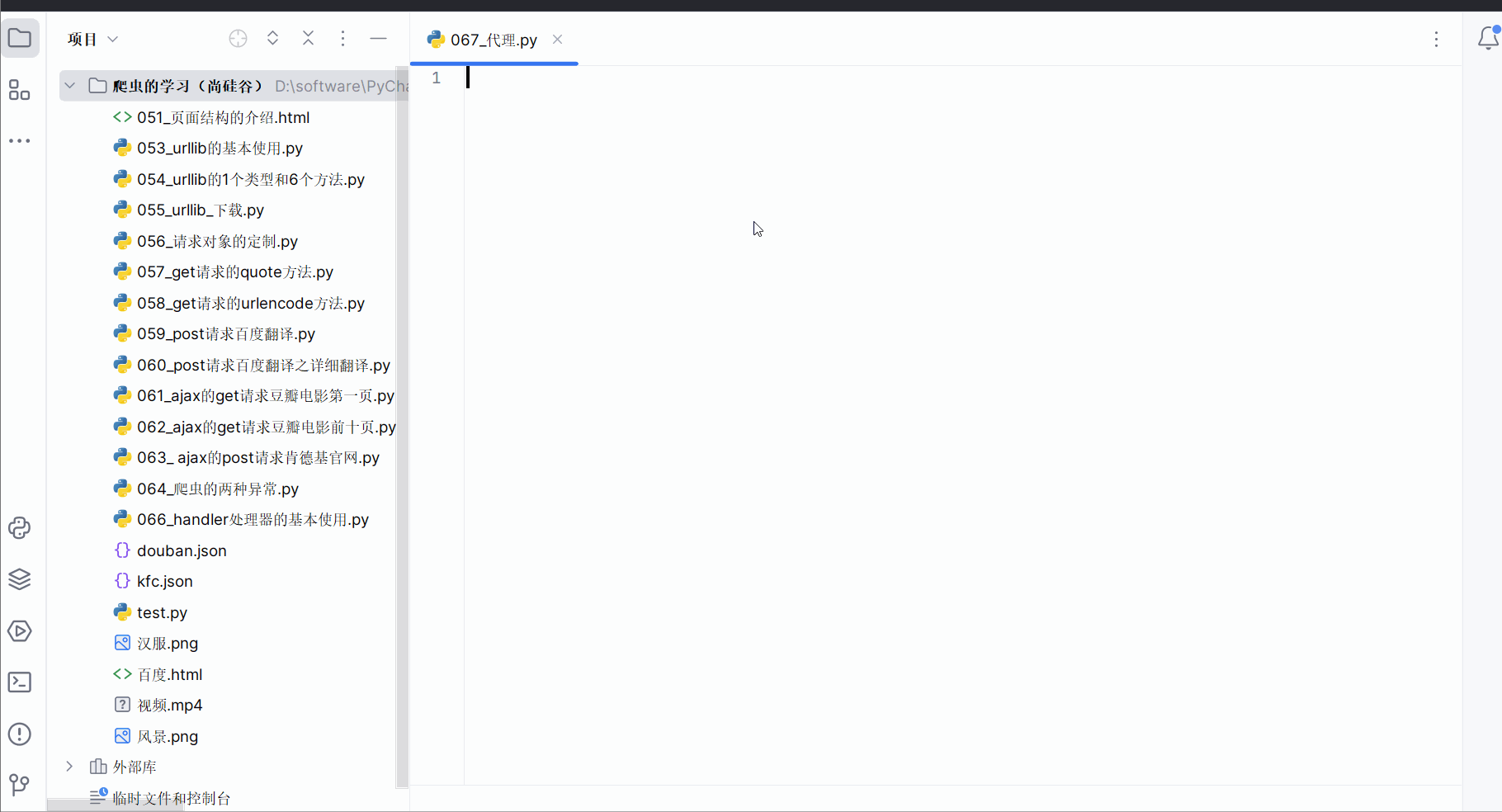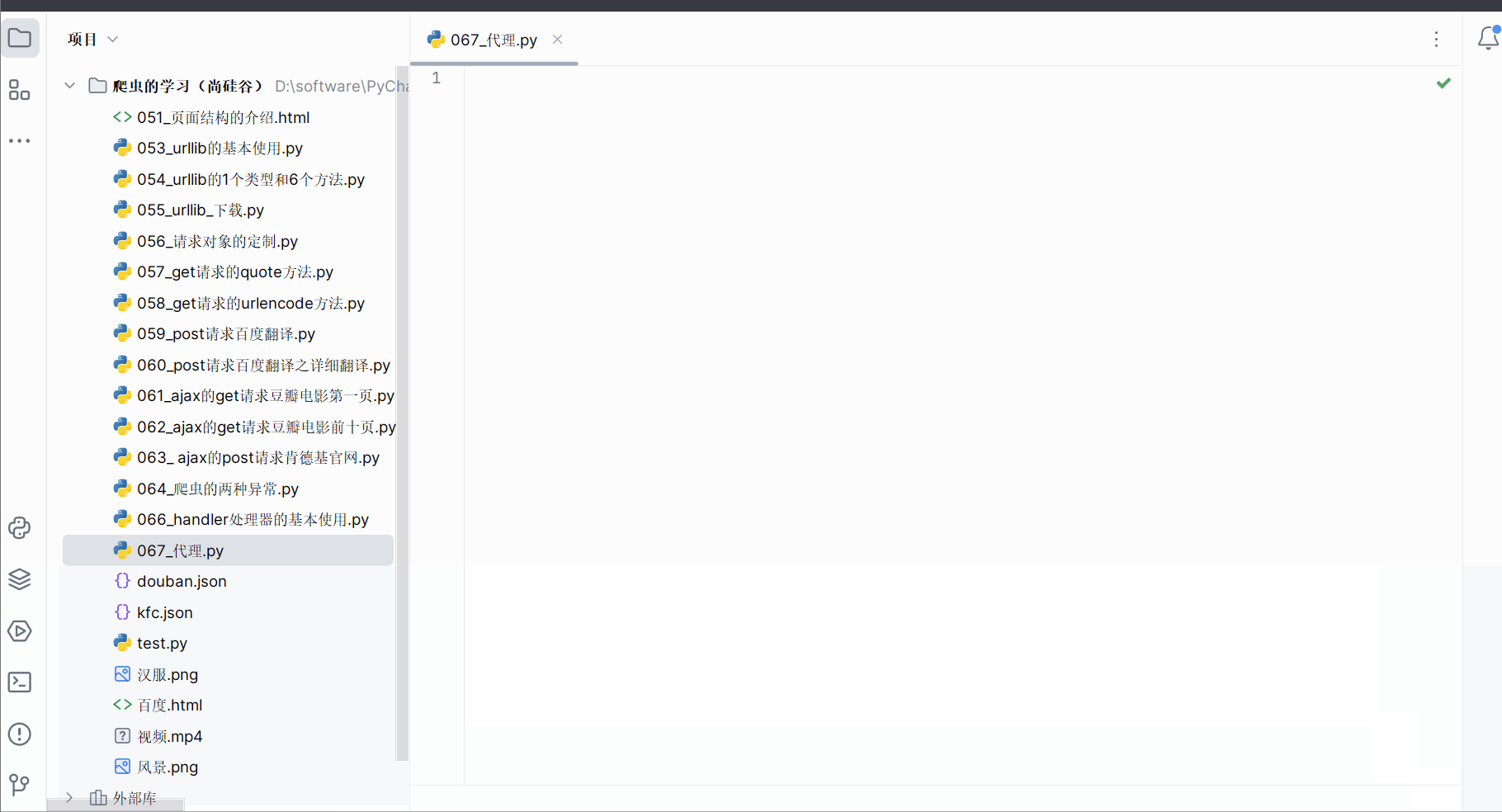
打开软件,创建一个名为“062_ajax的get请求豆瓣电影前十页”的py文件。


先将第一页的数据的请求地址复制到PyCharm中。

然后,如下图所示,然后点击清空已有请求的按钮。接着,将网页向下滑。找到对应地址,并复制到PyCharm中。
同理,找到第三页的地址,并复制到PyCharm中。然后观察这几个地址,发现它们仅仅是“start”的值依次为0、20、40、60…,对应第1、2、3、…页,其他均没有变化。

删去上次运行的结果,即删去文件“douban.json”。
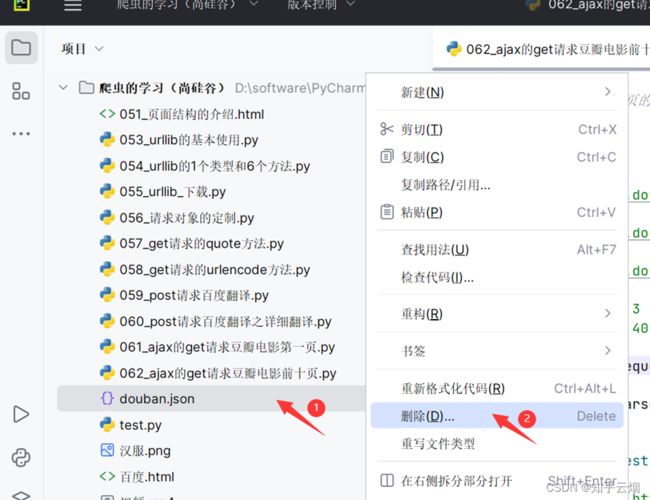


然后,如下进行编程并运行。在运行程序后产生的文件中使用快捷键Ctr+Alt+L,一以便查看文件里的内容。(运行程序时间有点长,说明程序有待优化。)
"""
获取豆瓣电影的前十页的数据并且保存起来
- get请求
"""
'''
# 第一页
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
# 第二页
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
# 第三页
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20
# page 1 2 3 4
# start 0 20 40 60 规律为( page - 1 ) * 20
'''
import urllib.request
import json
import urllib.parse
def create_request(page: int):
"""
请求对象定制(使用UA),解决反爬的第一种手段
:param page: 页码
:return: 请求对象定制的结果request
"""
# 请求地址
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start': (page - 1) * 20,
'limit': 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
"""
获取page页数据
:param request: 请求对象定制的结果
:return: 第page页数据
"""
# (1).模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# (2).获取响应的数据
content = response.read().decode('UTF-8')
return content
def deal_content(content, content_changed):
"""
处理page页数据,假设本次只想储存序号和电影名字
:param content: 从豆瓣上获取的某一页的原始数据
:param content_changed: 根据需要修改后只含序号和电影名字的数据
:return: 返回处理原始数据后的只含序号和电影名字的数据
"""
content = json.loads(content) # json字符串转成python中的json对象
for index in content:
content_changed.append({'rank': index['rank'], 'title': index['title']})
return content_changed
def down_load(content_changed):
"""
数据下载到本地
:param content_changed: 处理过后的数据
:return: 无返回值
"""
# 将数据转为json类型
content_changed = json.dumps(content_changed, ensure_ascii=False)
# ensure_ascii=False表示不用转换成ASCII码 如果为了节省空间,请不要写ensure_ascii=False
'''
open方法默认情况下使用的是gbk的编码
- 如果我们要想保存汉字那么需要在open方法中指定编码格式为utf-8
'''
# 法1
# fp = open('douban.json', 'w', encoding='UTF-8')
# fp.write(content)
# fp.close() # 别忘了关闭文件
# 法2
with open('douban.json', 'w', encoding='utf-8') as fp:
fp.write(content_changed)
# 程序的入口
if __name__ == '__main__':
# 1.输入起始、结束页码
start_page = int(input("请输入起始的页码:"))
end_page = int(input("请输入结束的页码:"))
# 2.从豆瓣上获取对应数据
content_changed = []
for page in range(start_page, end_page + 1):
# 2.1 第page页的请求对象定制
request = create_request(page)
# 2.2 获取page页数据
content = get_content(request)
# 2.3 处理page页数据(本人加的,只获取感兴趣的内容。 如果有不懂的,可以去阅读本人的CSDN上的python入门中有关json的部分。)
# 假设本次只想储存序号和电影名字
content_changed = deal_content(content, content_changed)
# 3.数据下载到本地
down_load(content_changed)
13. ajax的post请求
本次将以爬取肯德基的一些信息为例介绍ajax的post请求,具体为北京哪些位置有肯德基,爬取前10页就可以了。如下图,在百度上搜索“肯德基”,点进去后点击“餐厅查询”,将城市选为“北京”。


然后点击检查里的网络,选择第1页,发现有一个接口是我们需要的数据。


为什么说它是ajax请求呢?这是因为出现了“X-Requested-With:XMLHttpRequest”,另外,本次的请求是ajax的post请求。


打开软件,创建一个名为“063_ ajax的post请求肯德基官网”的py文件。


将第1页的请求地址以及负载里的表单信息复制到PyCharm中,同理将第2页、第3页的请求地址以及负载里的表单信息复制到PyCharm中。

观察这几页信息的规律,发现只有“pageIndex”的值不同,依次为1、2、3。

之后如下进行编程并运行,在查看生成的json文件时使用快捷键Ctr+Alt+L有助于浏览结果。
"""
北京哪些位置有肯德基?爬取前10页数据。
- post请求
"""
'''
# 第一页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
# 第二页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
# 第三页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 北京
# pid:
# pageIndex: 3
# pageSize: 10
'''
import urllib.request
import urllib.parse
import json
def crate_request(page: int):
"""
请求对象定制
:param page: 页码
:return: 某一页的请求对象定制
"""
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid': '',
'pageIndex': str(page),
'pageSize': '10'
}
# post的参数需要编码
data = urllib.parse.urlencode(data).encode('UTF-8')
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
return urllib.request.Request(url=base_url, data=data, headers=headers)
def get_content(request):
"""
获取网页源码
:param request: 请求对象定制的结果
:return: 网页源码
"""
response = urllib.request.urlopen(request)
content = response.read().decode('UTF-8')
content = json.loads(content)
return content
def down_load(all_content):
fp = open('kfc.json', 'w', encoding='UTF-8')
all_content = json.dumps(all_content, ensure_ascii=False)
fp.write(all_content)
fp.close()
if __name__ == '__main__':
start_page = int(input("请输入起始页码:"))
end_page = int(input("请输入结束页码:"))
all_content = []
for page in range(start_page, end_page + 1):
# 请求对象定制
request = crate_request(page)
# 获取网页源码
content = get_content(request)
# 将数据添加到存储所有数据的列表all_content中
all_content.append(content)
# 下载
down_load(all_content)
14.爬虫常见的两个异常(URLError\HTTPError)
(1)简介

(2)代码演示
本次以捕获一个CSDN上的网页源码为例进行演示。如下图,点开一个CSDN链接。为了删去一些没用的广告,可以在网址中把离detail最近的那个问号以及后面的部分删除,留下的链接为“https://blog.csdn.net/sulixu/article/details/119818949”。
先打开软件,创建一个名为“064_爬虫的两种异常”的py文件。


如下进行编码,成功获得该链接的网页源码。
import urllib.request
url='https://blog.csdn.net/sulixu/article/details/119818949'
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request=urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
# 读取数据
content=response.read().decode('UTF-8')
print(content)
然后刻意在url后面加个“1”,发现报错,是一个HTTPError,该错误是URLError的子类。

用户往往看不懂错误,为了不让用户,所以如果再出现HTTPError,就显示“系统正在升级。。。”,所以如下加入try…except语句。
import urllib.request
import urllib.error
url='https://blog.csdn.net/sulixu/article/details/1198189491'
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
try:
# 请求对象定制
request=urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
# 读取数据
content=response.read().decode('UTF-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级。。。')

如果出现URLError,一般是主机地址的参数写错了,比如将url改成“http://www.goudan1111.com”,如下图所示。

同样,为了不直接显示报错,可以进行如下编码,然后运行。
import urllib.request
import urllib.error
# url='https://blog.csdn.net/sulixu/article/details/1198189491'
url ='http://www.goudan1111.com'
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
try:
# 请求对象定制
request=urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
# 读取数据
content=response.read().decode('UTF-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级。。。')
except urllib.error.URLError:
print('我都说了,系统正在升级。。。')

15.微博的cookie登陆
对于某些需要登陆才能获取相关信息的网站上,此时需要cookie绕过登陆,进入某个页面后,然后才能做一些信息采集。这一节需进行获取微博(“https://weibo.cn/pub/”)上的一些信息进行演示。
由于本次演示需要登陆微博,就不再去跟着演示了。演示的代码无非是在捕获并保存页面源码的基础上修改请求头,对应参数为检查-网络-info-标头-请求标头里的一堆参数。这些参数中,cookie和referer起了主要作用。
"""
微博cookie登陆的演示
- 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
"""
# 个人后息页面是Utf-8 但是还报错了编码错误 因为并没有进入到个人信息页面而是跳转到了登陆页面
# 那么登陆页面不是Utf-8 所以报错
# cookie中携带着你的登陆后息 如果有登陆之后的cookie 那么我们就可以携带着cookie.进入到任何页面
# referer 判断当前路径是不是由上一个路径进来的 一般情况下是做 图片防盗链
16.Handler处理器的基本使用
(1)为什么要学习handler


(2)代码演示(handler的语法参考演示的代码)
先打开软件,创建一个名为“066_handler处理器的基本使用”的py文件。

如下进行编码,通过使用handler处理器来获取百度首页的网页源码。
"""
handler处理器的基本使用的演示
- 需求:使用handler来访问百度 获取网页源码
"""
import urllib.request
# 要访问的地址
url = 'http://www.baidu.com'
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# handler的使用基本上需要三个单词:handler、build_opener、open
# (1)获取handler对象
handler = urllib.request.HTTPHandler()
# (2)获取opener对象
opener = urllib.request.build_opener(handler)
# (3)调用open方法
response = opener.open(request)
content = response.read().decode('UTF-8')
print(content)
17.代理
(1)代理的作用以及步骤

(2)代码演示
先打开软件,创建一个名为“067_代理”的py文件。

如下图所示,搜索“ip”,将网址上带广告的部分删除,然后复制到PyCharm中,并把“https”改成“http”。

在下面代码的基础上,加上Cookies,然后运行可以得到百度搜索“ip”的网页源码。
import urllib.request
url = 'http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=ip'
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取响应的信息
content = response.read().decode('UTF-8')
# 保存
with open('代理.html', 'w', encoding='UTF-8') as fp:
fp.write(content)

如下图所示,可以去“快代理”里面找一些代理ip。

如下继续编程,加上代理。运行后发现需要安全验证。后面想办法去windows里设置代理ip,然后得到Cookie,失败了。估计免费的ip不行,得买。
import urllib.request
url = 'http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=ip'
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
# handler的使用基本上需要三个单词:handler、build_opener、open
# proxies为代理ip
proxies = {
'http': '58.20.184.187:9091' # 值为主机+端口号
}
handler = urllib.request.ProxyHandler(proxies=proxies) # ProxyHandler有代理
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('UTF-8')
# 保存
with open('代理.html', 'w', encoding='UTF-8') as fp:
fp.write(content)
18.代理池
如果高频次使用一个ip去访问一个网站,这个ip很可能会被封。所以为了避免这种情况,提出了代理池的概念,里面有一堆高匿的ip。
先打开软件,创建一个名为“068_代理池”的py文件。

如下进行编程,由于个人还是不知道怎么获取对应ip的Cookie,因此进入百度还是需要安全验证。
import urllib.request
import random
url = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=ip'
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
# handler的使用基本上需要三个单词:handler、build_opener、open
# proxies为代理ip
proxies_pool = [
{'http': '58.20.184.187:9091'},
{'http': '117.68.194.137:9999'}
]
proxies = random.choice(proxies_pool)
handler = urllib.request.ProxyHandler(proxies=proxies) # ProxyHandler有代理
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('UTF-8')
# 保存
with open('代理池.html', 'w', encoding='UTF-8') as fp:
fp.write(content)