数据库常用命令
文章目录
-
- 1. 数据库操作命令
-
- 0.语法
- 1.进入数据库
- 2.查看数据库列表信息
- 3.查看数据库中的数据表信息
- 2.SQL语句命令
-
- 1. 创建数据表
- 2. 基本查询语句
- 3. SQL排序
- 4. SQL分组统计
- 5. 分页查询
- 6. 多表查询
- 7.自关联查询
- 8.子查询
- 3. SQL 高级应用
-
- 1. ER图
- 2. 外键
- 3. 索引
- 4. 事务
- 5. 视图
- 6.日志
安装mysql教程:
https://blog.csdn.net/yaoyyl/article/details/107279989
启动mysql服务终止服务
1. 数据库操作命令
0.语法
- SQL语句可以单行或多行书写,以分号结尾。
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。3.注释
- 单行注释:–注释内容或#注释内容(MySQL特有)
- 多行注释:/* 注释 */
1.进入数据库
mysql -u root -p
设置密码
update user set authentication_string=password("xxxxxx") where user="root"; #这里xxxx代表你的密码
2.查看数据库列表信息
show databases;

-- 查看当前数据库
select database();
-- 创建数据库
create database nini charset=utf8;
-- 验证创建数据库是否成功
show databases;
-- 移除数据库
drop database nini;
-- 进入数据库(test)查看数据表
use test;
show tables;
-- 查看数据表(goods)中所有数据
select * from goods;
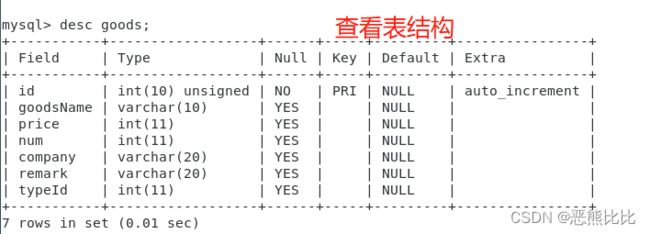
-- 查看表(goods)结构
desc goods;
添加表
3.查看数据库中的数据表信息
(1)进入数据库
use mysql;
(2)查看数据表
show tables;

2.SQL语句命令
1. 创建数据表
drop table if exists category;
create table category(
id int unsigned primary key auto_increment,
typeId int,
cateName varchar(10)
);
insert into category values
(0, 001, '一次性口罩'),
(0, 002, 'KN95口罩'),
(0, 003, 'N95口罩'),
(0, 004, '医用口罩');
drop table if exists goods;
create table goods(
id int unsigned primary key auto_increment,
goodsName varchar(10),
price int,
num int,
company varchar(20),
remark varchar(20),
typeId int
);
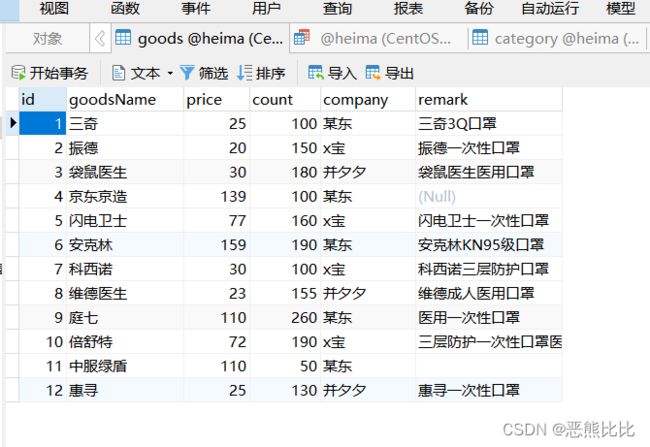
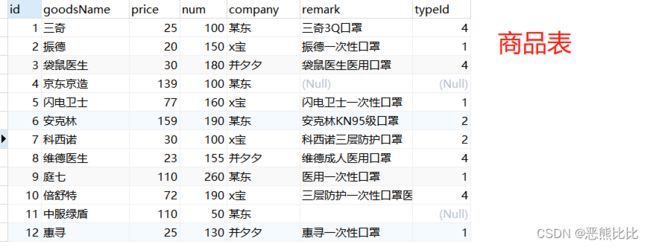
insert into goods values
(0, '三奇', 25, 100, '某东', '三奇3Q口罩', 4),
(0, '振德', 20, 150, 'x宝', '振德一次性口罩', 1),
(0, '袋鼠医生', 30, 180, '并夕夕','袋鼠医生医用口罩', 4),
(0, '京东京造', 139, 100, '某东', null, null),
(0, '闪电卫士', 77, 160, 'x宝', '闪电卫士一次性口罩', 1),
(0, '安克林', 159, 190, '某东','安克林KN95级口罩', 2),
(0, '科西诺', 30, 100, 'x宝', '科西诺三层防护口罩', 2),
(0, '维德医生', 23, 155, '并夕夕', '维德成人医用口罩', 4),
(0, '庭七', 110, 260, '某东', '医用一次性口罩', 1),
(0, '倍舒特', 72, 190, 'x宝', '三层防护一次性口罩医用口罩', 4),
(0, '中服绿盾', 110, 50, '某东', '', null),
(0, '惠寻', 25, 130, '并夕夕', '惠寻一次性口罩', 1);
2. 基本查询语句
-- 基础查询操作
-- 查全部
SELECT * FROM goods;
-- 查部分
SELECT goodsName,price FROM goods;
-- 起别名
SELECT goodsName as '商品名称' FROM goods;
-- 去重
SELECT DISTINCT(company) FROM goods;
-- 条件查询
SELECT * FROM goods WHERE company='并夕夕';
-- 模糊查询
SELECT * FROM goods WHERE remark like '%一次性口罩';
-- 范围查询
SELECT goodsName 商品名称,price 价格 FROM goods WHERE price BETWEEN 10 and 50;
-- 判空查询
SELECT * FROM goods WHERE remark is null;
3. SQL排序
-- sql排序
-- 语句:ORDER BY asc\dese
-- 按商品价格升序
SELECT * FROM goods;
SELECT * FROM goods ORDER BY price ASC;
-- 按商品价格降序,价格相同时 按数目升序排列
SELECT * FROM goods ORDER BY price DESC,num ASC;
4. SQL分组统计
-- SQL 分组统计
-- 聚合函数: count min max avg
-- 语句分组:group by
SELECT * FROM goods;
-- 统计表单数据量
SELECT count(*) FROM goods; -- 12
-- 统计表单中各商品的平均数量
SELECT AVG(num) FROM goods; -- 147.0833
-- 查询每家公司商品的数量信息
SELECT company,count(*) FROM goods GROUP BY company;
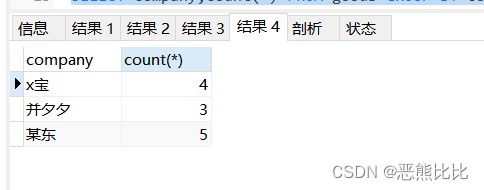
分组+条件删选
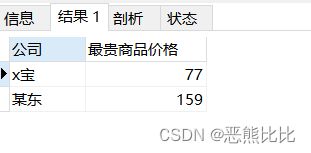
-- 查询某东和x宝的最贵商品
SELECT company 公司,MAX(price) 最贵商品价格 FROM goods GROUP BY company HAVING company!='并夕夕';
SELECT company 公司,MAX(price) 最贵商品价格 FROM goods GROUP BY company HAVING company in ('某东','x宝');

where和having区别:
- where是针对From进行删选;
- having是针对分组后(group by)的结果进行删选;
- 只有having后才能用聚合函数;
这里是我的一个疑问和解答
为什么不能直接使用where进行以上条件删选? 而是一定要分组(group by),正如如下代码:
SELECT company 公司,MAX(price) 最贵商品价格 FROM goods WHERE company in (‘某东’,‘x宝’);
.
运行结果是这样的:

解释:
解释1:分组的意义
- GROUP BY 语句根据一个或多个字段对结果集进行分组(也就是把值相同放到一个组中,显示组中一条记录),实现对每个组而不是对整个结果集统计。比如统计每个公司最贵的商品价格,重点理解查询条件的是每个,也就是我们要对表中的数据根据公司要分个类,其次是在分类结果中在依次寻求必要条件,如果没有group by的话,where后只能加一个表项中的一个条件。
解释2:使用where如何分组
- 重要的一点:where在分组前加条件,having在分组后加条件
SELECT company 公司,MAX(price) 最贵商品价格 FROM goods WHERE company in ('某东','x宝') GROUP BY company;
group by详解:https://blog.csdn.net/qq_39221436/article/details/122576925
5. 分页查询
-- 分页查询
-- 页是查询页的页,不是数据表的页
-- 语句:limit satrt,count
-- 查询商品表5-10行数据 (起始显示第五行,一共显示6行)
SELECT * FROM goods;
SELECT * FROM goods LIMIT 4,6;

6. 多表查询
-- 多表查询
-- 类:内连接、左连接、右连接
-- 语句:inner join、LEFT JOIN、RIGHT JOIN
-- aim:对连接后的表进行字段显示限制;
SELECT * FROM goods;
SELECT * FROM category;
-- 内连接
SELECT * FROM goods INNER JOIN category ON goods.typeId=category.typeId;
-- 左连接
SELECT * FROM goods LEFT JOIN category ON goods.typeId=category.typeId;
-- 右连接
SELECT * FROM goods RIGHT JOIN category ON goods.typeId=category.typeId;

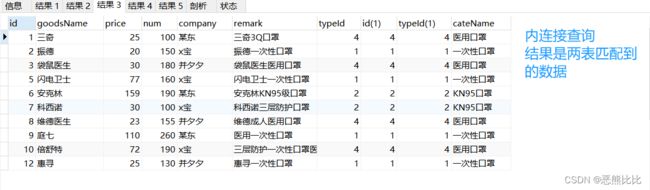

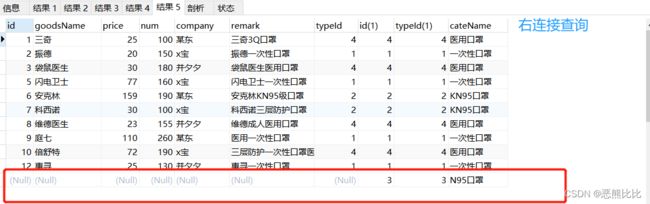
7.自关联查询
-- 自关联
-- 条件:一个数据表,表中至少有两个数据项相关联;
-- 方法:起别名,将一个表变成两个表
SELECT * FROM areas;
-- 选择所以河北的城市
SELECT * FROM areas a1 INNER JOIN areas a2 on a1.aid=a2.pid WHERE a1.atitle = '河北省';
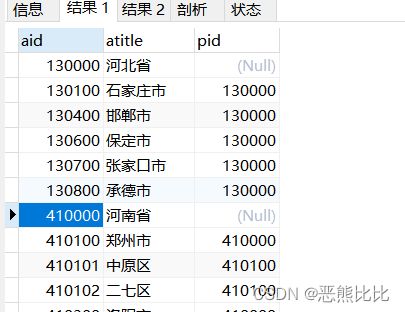
8.子查询
-- 子查询
-- 在一条语句中,利用另一条语句充当数据或条件。
-- 充当条件
-- 查高于平均价的商品信息
SELECT * FROM goods WHERE price>(SELECT AVG(price) FROM goods);
-- 充当数据
-- 查询所有来着pdd的商品信息
SELECT * FROM category c INNER JOIN (SELECT * FROM goods WHERE company='并夕夕') a ON c.typeId=a.typeId;
3. SQL 高级应用
1. ER图
the-表的另一种表现形式;

2. 外键
The -一个实体(从表 子)的某个字段指向另一个实体(主表 父)的主键,则称外键;
作用 - 外键可以对关系字段起到约束作用,当从表的关系字段写值时,会关联主表查询此值是否存在,存在则填写成功,不存在则填写失败;
-- 主表
drop table if exists class;
create table class(
id int unsigned primary key auto_increment,
name varchar(10)
);
-- 从表
drop table if exists stu;
create table stu(
name varchar(10),
class_id int unsigned
-- stu 表的 class_id 指向 class 表的 id, class_id 是 stu 表的外键
-- 创表时添加外键
-- foreign key(自己的字段名) references 目标表名(目标表的主键)
foreign key(class_id) references class(id)
);
-- 扩展1 : 对于已经存在的表添加外键
-- alter table 从表名 add foreign key (从表字段) references 主表名(主表主键);
alter table stu add foreign key (class_id) references class(id);
-- 扩展2 : 查看外键和删除外键
-- 查看外键
-- show create table 表名
show create table stu;
-- CREATE TABLE `stu` (
-- `name` varchar(10) DEFAULT NULL,
-- `class_id` int(10) unsigned DEFAULT NULL,
-- KEY `class_id` (`class_id`),
-- CONSTRAINT `stu_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `class` (`id`)
-- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
-- 删除外键
-- alter table stu drop foreign key 外键名称
alter table stu drop foreign key stu_ibfk_1;
3. 索引
-- 开启时间监测
set profiling=1;
-- 查询示例数据 num = 10000 的值
select * from test_index where num = 10000;
-- 查看运行时间
show profiles;
-- 添加索引(对已存在的表添加索引)
-- create index 索引名称 on 表名(目标字段)
create index num_index on test_index(num);
-- 再次执行查询数据操作
select * from test_index where num = 10000;
-- 再次查看运行时间
show profiles;

-- 扩展1 : 查看索引
-- show index from 表名
show index from test_index;
-- 扩展2 : 创表时添加
create table create_index(
id int primary key,
name varchar(10) unique, -- unique : 设置端唯一值
age int,
key(age) -- 指定添加索引方法
);
-- 查看索引
show index from create_index;
-- 扩展3 : 删除索引
-- drop index 索引名称 on 表名;
drop index age on create_index;
4. 事务
THe- 事务可以称为是一个操作序列,一系列操作要么都执行,要么都不执行,对于数据库来说,数据操作要么都实现要么都不实现,最终要保证数据的一致性。
事务实现
- 前提:数据库的数据引擎类型必须是innodb(查看创表语句)

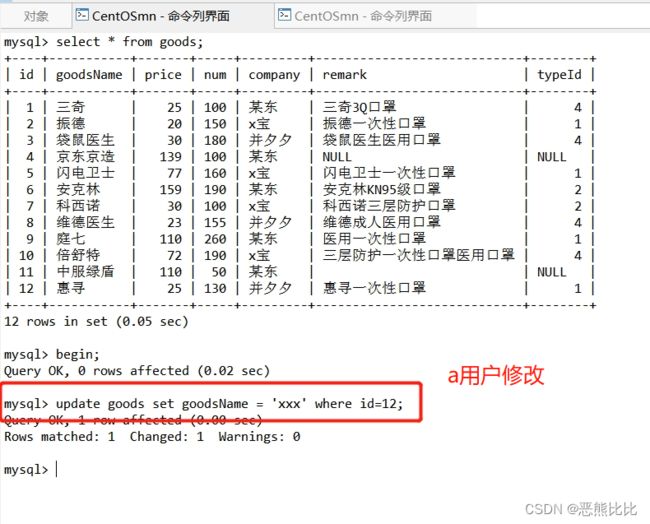

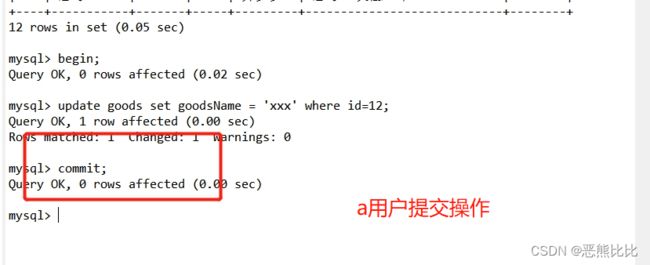

-- 注意:一般由修改数据产生
-- 开始事务
begain;
-- 提交事务
commit;
-- 回滚(撤销)
rollback;
5. 视图
the-能够封装sql语句,以类似于表的形式存在;
aim-隐藏真实表的操作信息
-- 创建视图语法
-- create view 视图名称 as select 语句;
-- 视图
CREATE VIEW v_goods as select * from goods;
-- 复杂 SQL 语句视图封装
select go.goodsName, ca.cateName from goods go inner join category ca on go.typeId = ca.typeId;
-- 封装连接查询语句时, 如果存在重名字段名称, 需要通过别名进行修改
create view v_goods_cate as select go.*, ca.id 序号, ca.typeId 类型, ca.cateName from goods go inner join category ca on go.typeId = ca.typeId;
select * from v_goods_cate;
-- 删除视图语句
-- drop view 视图名称
drop view v_goods_cate;
6.日志
注意:mysql自带日志功能,但是开启日志会消耗数据库性能,因此默认情况是不开启;
-- 查看日志功能是否开启
show variables like 'general%';
-- 开启操作
set global general_log = 1;
-- 关闭操作
set global general_log = 0;
