论文解读Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthes
基于结构化潜代码的隐式神经表示新视图合成
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthes
论文地址:论文
https://arxiv.org/pdf/2012.15838.pdf
项目地址:Github
https://github.com/zju3dv/neuralbody
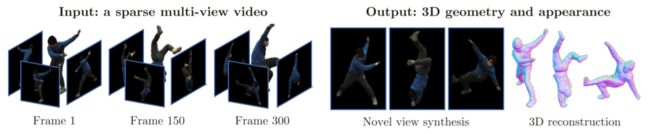
图 1:从稀疏多视图视频中合成表演者的新颖视图。 Neural Body 捕捉表演者的 3D 几何形状和外观,可用于 3D 重建和新颖的视图合成。
代码及补充材料可在 https://zju3dv.github.io/neuralbody/ 获取。
摘要
本文解决了人类表演者从一组非常稀疏的摄像机视图中合成新颖视图的挑战。 最近的一些工作表明,在给定密集输入视图的情况下,学习 3D 场景的隐式神经表示可以实现卓越的视图合成质量。 然而,如果视图高度稀疏,表示学习就会不适定。 为了解决这个不适定问题,我们的关键思想是整合对视频帧的观察。 为此,我们提出了神经体,一种新的人体表示,它假设不同帧上学习的神经表示共享锚定到可变形网格的同一组潜在代码,以便跨帧的观察可以自然地整合。 可变形网格还为网络提供几何指导,以更有效地学习 3D 表示。 为了评估我们的方法,我们创建了一个名为 ZJU-MoCap 的多视图数据集**,用于捕捉具有复杂动作的表演者**。 ZJU-MoCap 上的实验表明,我们的方法在新颖的视图合成质量方面大大优于先前的工作。 我们还展示了我们的方法重建移动人物的能力来自人物快照数据集上的单目视频。

图 2:神经体的基本思想。 Neural Body 根据同一组潜在代码在不同视频帧生成人体的隐式 3D 表示,这些潜在代码锚定到可变形网格的顶点。 对于每一帧,我们根据人体姿势变换代码的空间位置,并使用网络根据结构化潜在代码对任何 3D 位置的密度和颜色进行回归。 那么任意视点的图像都可以通过体绘制合成。
介绍
人类表演者的自由视点视频具有多种应用,例如电影制作、体育广播和远程呈现。 以前的自由视点视频系统要么依赖密集的摄像机阵列来进行基于图像的新颖视图合成 [20, 23],要么需要深度传感器进行高质量 3D 重建 [8, 14] 以产生逼真的渲染。 复杂的硬件使得 freeviewpoint 视频系统价格昂贵且仅适用于有限的环境。
这项工作的重点是从由数量非常有限的摄像机捕获的稀疏多视图视频中为人类表演者提供新颖的视图合成问题,如图 1 所示。这种设置显着降低了自由视点系统的成本,并且 使系统的适用范围更加广泛。 然而,这个问题极具挑战性。 传统的基于图像的渲染方法[20, 12]大多需要密集的输入视图,不能应用于此处。 对于基于重建的方法 [54, 22],摄像机之间的宽基线使得密集立体匹配变得棘手。 此外,由于稀疏视图中的自遮挡,人体的一部分可能是不可见的。 因此,这些方法往往会产生噪声和不完整的重建,从而导致严重的渲染伪影。
最近的作品 [58,47,44] 研究了隐式神经表征在新视图合成中的潜力。 NeRF [44] 表明,可以通过将 3D 场景表示为密度和颜色的隐式场来实现照片级真实感视图合成,这些隐式场是通过可微分渲染器从图像中学习的。 然而,当输入视图高度稀疏时,[44]的性能会急剧下降,如第 4.1 节中我们的实验结果所示。 原因是用非常稀疏的观察来学习神经表示是不合适的。 我们认为解决这个不适定问题的关键是聚合不同视频帧上的所有观察结果。 隆巴尔迪等人。 [37]通过使用具有不同潜在代码作为输入的相同网络对每个帧的 3D 表示进行回归来实现这一想法。 由于潜在代码是为每个帧独立获得的,因此缺乏足够的约束来有效地融合跨帧的观察结果。
在本文中,我们为动态人类引入了一种新颖的隐式神经表示,称为“神经体”,以解决从稀疏视图合成新颖视图的挑战。 基本思想如图 2 所示。对于不同帧的隐式字段,神经体不是单独学习它们,而是从同一组潜在代码中生成它们。 具体来说,我们将一组潜在代码锚定到可变形人体模型(本工作中的 SMPL [38])的顶点,即它们的空间位置随着人体姿势的变化而变化。 为了获得帧的 3D 表示,我们首先根据人体姿势变换代码位置,这可以从稀疏的相机视图中可靠地估计 [3,13,15]。 然后,设计一个网络来根据这些潜在代码对任何 3D 点的密度和颜色进行回归。 潜在代码和网络都是共同学习的来自重建过程中所有视频帧的图像过程。 该模型的灵感来自统计学中的潜变量模型[36],它使我们能够有效地整合不同帧的观察结果。 该方法的另一个优点是,可变形模型提供了几何先验(粗糙表面位置),可以更有效地学习隐式场。
为了评估我们的方法,我们创建了一个多视图数据集称为 ZJU-MoCap,可以捕捉复杂动作中的动态人体。 在所有捕获的视频中,我们的方法在新颖的视图合成方面展示了最先进的性能。 我们还展示了我们的方法从人物快照数据集 [2] 上的单眼 RGB 视频中捕捉移动人物的能力。 此外,我们的方法可用于表演者的 3D 重建。 总的来说,这项工作有以下贡献:
• 我们提出了一种新方法,能够从稀疏的多视图视频中以复杂的动作合成表演者逼真的新颖视图。
• 我们提出了Neural Body,这是一种针对动态人类的新型隐式神经表示,它使我们能够有效地整合对视频帧的观察。
• 我们展示了显着的绩效改进-与之前的工作相比,我们的方法的评论
相关工作
基于图像的渲染, 这些方法旨在合成新颖的视图,而无需恢复详细的 3D 几何形状。 给定密集采样的图像,一些作品 [20, 9] 应用光场插值来获得新颖的视图。 尽管它们的渲染结果令人印象深刻,但可渲染视点的范围有限。 为了扩展范围,[6, 50]从输入图像推断深度图作为代理几何形状。 他们利用深度将观察到的图像扭曲成新颖的视图并执行图像混合。 然而,这些方法对重建代理几何的质量很敏感。 [28,23,7,62,31,30,63]用可学习的对应部分替换基于图像的渲染管道的手工部分,以提高鲁棒性。
人类表演捕捉, 大多数方法[46,8,14,22]采用传统的建模和渲染管道来合成人类的新颖视图。 它们依靠深度传感器 [8, 14, 60] 或密集的相机阵列 [11, 22] 来实现高保真度重建。 [40,43,64]用神经网络改进渲染管道,可以训练神经网络来补偿几何伪影。 为了在高度稀疏的多视图设置中捕获人体模型,基于模板的方法[4,10,17,59]假设存在预先扫描的人体模型。 他们通过变形模板形状以适应输入图像来重建动态人体。 然而,变形的几何形状往往不切实际,并且在大多数情况下无法获得预先扫描的人体形状。 最近,[45,52,66,53]使用网络从训练数据中捕获人类先验,这使他们能够从单个图像中恢复 3D 人体几何形状和纹理。 然而,他们很难实现逼真的视图合成或处理训练期间看不到的复杂人体姿势下的人。
基于神经表示的方法,在这些作品中,深度神经网络被用来从具有可微分渲染器的 2D 图像中学习场景表示,例如体素 [57, 37]、点云 [64, 1]、纹理网格 [61, 34, 32]、多平面 图像 [67, 16] 和隐式函数 [58, 35, 47, 44, 33]。 作为先驱,SRN [58] 提出了一种隐式神经表示,将 xyz 坐标映射到特征向量,并使用可微的光线行进算法来渲染 2D 特征图,然后使用像素生成器将其解释为图像。 NeRF [44] 表示具有隐式密度和颜色场的场景,非常适合可微分渲染并实现逼真的视图合成结果。 我们的方法不是使用单个隐函数来学习场景,而是引入了一组潜在代码,这些代码与网络一起使用来对局部几何和外观进行编码。 此外,将这些代码锚定到可变形模型的顶点使我们能够表示动态场景。

图 3:具有结构化潜在代码的隐式神经表示。 (a) 将结构化潜在代码输入到 SparseConvNet 中,输出潜在代码量。 此过程将表面上定义的输入代码扩散到附近的 3D 空间。 (b) 对于任何 3D 点,其潜在代码是使用三线性插值从其相邻顶点获得的潜在代码量并传递到 MLP 网络进行密度和颜色回归。
Neural Body神经体
对于表演者的稀疏多视点视频,我们的任务是生成表演者的自由视点视频。 我们将视频表示为 {Ic
t |c = 1, …,Nc, t = 1, …,Nt},其中 c 是摄像机索引,Nc 是摄像机数量,t 是帧索引,Nt 是帧数量 。 相机已预先校准。 对于每个图像,我们应用[19]来获取前景人体掩模并将背景图像像素的值设置为零。 所提出模型的概述如图所示:
3. 神经体从附着在可变形人体模型表面的一组结构化潜在代码开始(第 3.1 节)。 表面周围任何位置的潜在代码都可以通过代码扩散过程(第 3.2 节)获得,然后通过神经网络解码为密度和颜色值(第 3.3 节)。 任何视点的图像都可以通过体积渲染生成(第 3.4 节)。 通过最小化渲染图像和输入图像之间的差异来共同学习结构化潜在代码和神经网络(第 3.5 节)。 神经体根据同一组潜在代码在每一帧生成人体几何形状和外观。 从统计角度来看,这是一种潜在变量模型[36],它将每帧观察到的变量与一组潜在变量相关联。 通过这样的潜变量模型,我们有效地整合了视频中的观察结果。

表 1:SparseConvNet 的架构。 每层由稀疏卷积、批量归一化和 ReLU 组成。
为了通过人体姿势控制潜在代码的空间位置,我们将这些潜在代码锚定到可变形人体模型(SMPL)[38]。 SMPL 是基于顶点的蒙皮模型,其定义为形状参数、姿态参数和相对于 SMPL 坐标系的刚性变换的函数。 该函数输出具有 6890 个顶点的姿势 3D 网格。 具体来说,我们在 SMPL 模型的顶点上定义一组潜在代码 Z = {z1, z2, …, z6890}。 对于帧 t,SMPL 参数 St 是使用[26]从多视图图像 {Ic t |c = 1, …,Nc} 估计的。 然后根据人体姿势 St 变换潜在代码的空间位置,以进行密度和颜色回归。 图 3 显示了一个示例。 在我们的实验中,潜在代码 z 的维度设置为 16。 与局部隐式表示[25,5,18]类似,潜在代码与神经网络一起使用来表示人类的局部几何形状和外观。 将这些代码锚定到可变形模型使我们能够代表动态的人类。 通过动态人类表示,我们建立了一个潜在变量模型,将同一组潜在代码映射到不同帧的密度和颜色的隐式字段,这自然地整合了观察结果。
3.2. 代码扩散
图3(a)显示了代码扩散的过程。 这隐式字段为 3D 空间中的每个点分配密度和颜色,这需要我们查询连续 3D 位置的潜在代码。 这可以通过三线性插值来实现。 然而,由于结构化潜在码在 3D 空间中相对稀疏,直接对潜在码进行插值会导致最多 3D 点的向量为零。 为了解决这个问题,我们将表面上定义的潜在代码扩散到附近的 3D 空间。 受[65,56,49]的启发,我们选择SparseConvNet[21]有效地处理结构化潜在代码,其架构如表1所示。具体来说,基于SMPL参数,我们计算人体的3D边界框,并将该框划分为体素尺寸为5mm×5mm的小体素 × 5 毫米。 非空体素的潜在代码是该体素内 SMPL 顶点的潜在代码的平均值。 SparseConvNet 利用 3D 稀疏卷积来处理输入量并输出具有 2×、4×、8×、16× 下采样大小的潜在代码量。 通过卷积和下采样,输入代码被扩散到附近的空间。 按照[56],对于 3D 空间中的任何点,我们从网络层 5、9、13、17 的多尺度代码量中插入潜在代码,并将它们连接成最终的潜在代码。 由于代码扩散不应受到世界坐标系中人体位置和方向的影响,因此我们将代码位置转换到 SMPL 坐标系。 对于 3D 空间中的任何点 x,我们查询其潜在代码来自潜在代码量。 具体来说,点 x 首先变换到 SMPL 坐标系,该坐标系将该点与 3D 空间中的潜在代码体积对齐。 然后,使用三线性插值计算潜在代码。 对于 SMPL 参数 St,我们将点 x 处的潜在代码表示为 ψ(x, Z, St)。 代码向量被传递到 MLP网络来预测点 x 的密度和颜色。
3.3. 密度和颜色回归
图 3(b) 概述了密度和颜色的回归
对于 3D 空间中的任意点。 密度和色域由 MLP 网络表示。 网络架构详情在补充材料中描述
Density model. For the frame t t t, the volume density at point x \mathbf{x} x is predicted as a function of only the latent code ψ ( x , Z , S t ) \psi\left(\mathbf{x}, \mathcal{Z}, S_t\right) ψ(x,Z,St), which is defined as:
σ t ( x ) = M σ ( ψ ( x , Z , S t ) ) \sigma_t(\mathbf{x})=M_\sigma\left(\psi\left(\mathbf{x}, \mathcal{Z}, S_t\right)\right) σt(x)=Mσ(ψ(x,Z,St))
where M σ M_\sigma Mσ represents an MLP network with four layers.
Color model. Similar to [ 37 , 44 ] [37,44] [37,44], we take both the latent code ψ ( x , Z , S t ) \psi\left(\mathbf{x}, \mathcal{Z}, S_t\right) ψ(x,Z,St) and the viewing direction d \mathbf{d} d as input for the color regression. To model the location-dependent incident light, the color model also takes the spatial location x \mathrm{x} x as input. We observe that temporally-varying factors affect the human appearance, such as secondary lighting and selfshadowing. Inspired by the auto-decoder [48], we assign a latent embedding ℓ t \ell_t ℓt for each video frame t t t to encode the temporally-varying factors.
Specifically, for the frame t t t, the color at x \mathrm{x} x is predicted as a function of the latent code ψ ( x , Z , S t ) \psi\left(\mathbf{x}, \mathcal{Z}, S_t\right) ψ(x,Z,St), the viewing direction d \mathbf{d} d, the spatial location x \mathrm{x} x, and the latent embedding ℓ t \boldsymbol{\ell}_t ℓt. Following [51, 44], we apply the positional encoding to both the viewing direction d \mathbf{d} d and the spatial location x \mathbf{x} x, which enables better learning of high frequency functions. The color model at frame t t t is defined as:
c t ( x ) = M c ( ψ ( x , Z , S t ) , γ d ( d ) , γ x ( x ) , ℓ t ) , \mathbf{c}_t(\mathbf{x})=M_{\mathbf{c}}\left(\psi\left(\mathbf{x}, \mathcal{Z}, S_t\right), \gamma_{\mathbf{d}}(\mathbf{d}), \gamma_{\mathbf{x}}(\mathbf{x}), \ell_t\right), ct(x)=Mc(ψ(x,Z,St),γd(d),γx(x),ℓt),
where M c M_{\mathrm{c}} Mc represents an MLP network with two layers, and γ d \gamma_{\mathbf{d}} γd and γ x \gamma_{\mathbf{x}} γx are positional encoding functions for viewing direction and spatial location, respectively. We set the dimension of ℓ t \ell_t ℓt to 128 in experiments.
3.4. 体积渲染
给定一个视点,我们利用经典的体积渲染将神经体渲染成 2D 图像的技术。 像素颜色是通过体积渲染积分方程[27]估计的,该方程沿着相应的相机光线累积体积密度和颜色。 在实践中,积分是使用数值求积来近似的 [41, 44]。 给定一个像素,我们首先使用相机参数和样本 Nk 个点 {xk}Nk (1)3.3 计算其相机光线 r。 密度和颜色回归 图 3(b) 概述了 3D 空间中任意点的密度和颜色回归。 密度和色域由 MLP 网络表示。 补充材料中描述了网络架构的详细信息。沿着近边界和远边界之间的摄像机光线 r,k=1。场景边界是基于 SMPL 模型估计的。 然后,神经体预测这些点的体积密度和颜色。 对于视频帧t,渲染颜色~Ct®
C ~ t ( r ) = ∑ k = 1 N k T k ( 1 − exp ( − σ t ( x k ) δ k ) ) c t ( x k ) , where T k = exp ( − ∑ j = 1 k − 1 σ t ( x j ) δ j ) , \begin{gathered} \tilde{C}_t(\mathbf{r})=\sum_{k=1}^{N_k} T_k\left(1-\exp \left(-\sigma_t\left(\mathbf{x}_k\right) \delta_k\right)\right) \mathbf{c}_t\left(\mathbf{x}_k\right), \\ \text { where } T_k=\exp \left(-\sum_{j=1}^{k-1} \sigma_t\left(\mathbf{x}_j\right) \delta_j\right), \end{gathered} C~t(r)=k=1∑NkTk(1−exp(−σt(xk)δk))ct(xk), where Tk=exp(−j=1∑k−1σt(xj)δj),
where δ k = ∥ x k + 1 − x k ∥ 2 \delta_k=\left\|\mathbf{x}_{k+1}-\mathbf{x}_k\right\|_2 δk=∥xk+1−xk∥2 is the distance between adjacent sampled points. We set N k N_k Nk as 64 in all experiments. With volume rendering, our model is optimized by comparing the rendered and observed images.
3.5. 训练
通过体积渲染技术,我们优化神经体以最小化观察图像的渲染误差{Ic t |c = 1, …,Nc, t = 1, …,Nt}:
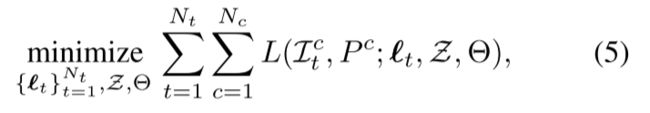
其中 θ 表示网络参数,Pc 是相机参数,L 是测量渲染图像和观察图像之间差异的总平方误差。相应的损失函数定义为:
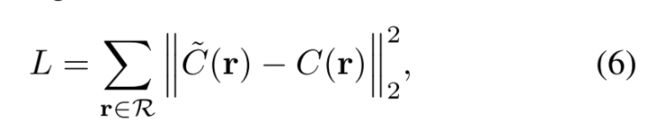
其中 R 是穿过图像像素的相机光线集,C® 表示真实像素颜色。 与逐帧重建方法 [54, 44] 相比,我们的方法使用视频中的所有图像来优化模型,并具有更多信息来恢复 3D 结构。 我们采用 Adam 优化器 [29] 来训练 Neu-真实的身体。
学习率从 5e−4 开始,随着优化呈指数衰减到 5e−5。 我们在四个 2080 Ti GPU 上进行训练。 300 帧的四视图视频的训练通常需要大约 200k 次迭代汇合(约14小时)。
3.6. 应用
训练好的神经体可用于新颖的视图表演者的合成和 3D 重建。 视图合成是通过体绘制来实现的。 动态人类的新颖视图合成产生了自由视点视频,使观众可以自由地从任意角度观看人类表演者。 我们的实验结果表明,生成的视频表现出较高的帧间和视图间一致性,这在补充材料中有所体现。 对于 3D 重建,我们首先以 5mm×5mm×5mm 的体素尺寸离散化场景。 然后,我们评估所有体素的体积密度并使用Marching Cubes 算法[39]。
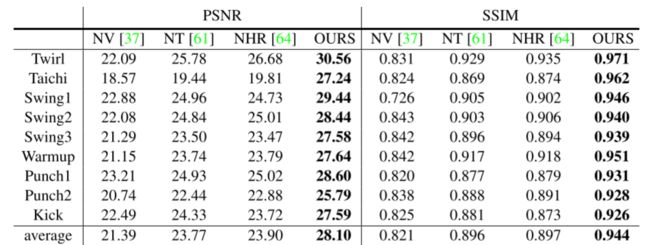
表 2:ZJU-MoCap 数据集的 PSNR 和 SSIM 结果(越高越好)。 “NV”是指神经体积,“NT”表示神经纹理。
实验 4.1
ZJU-MoCap 数据集上的结果 我们创建了一个名为 ZJU-Mocap 的多视图数据集,用于评估我们的方法。 该数据集使用具有 21 个同步摄像机的多摄像机系统捕获 9 个动态人类视频。 我们选择四个均匀分布的摄像机进行训练,并使用其余摄像机进行测试。 所有序列的长度都在 60 到 300 帧之间。 人类会做出复杂的动作,包括旋转、太极、摆臂、热身、拳击和踢腿。
指标, 对于新颖的视图合成,我们按照[44]使用两个标准指标来评估我们的方法:峰值信噪比(PSNR)和结构相似性指数(SSIM)。 对于 3D 重建,我们仅提供定性结果,因为没有真实的人体几何形状。
新颖视图合成的性能。 我们将我们的方法与处理动态场景的最先进的视图合成方法 [37,61,64] 进行比较。 所有方法都为每个场景训练一个单独的网络。 1) Neural Volumes [37] 将每帧的多视图图像编码为潜在向量,并将其解码为离散化 RGBα 体素网格。 2)神经纹理[61]提出了潜在的纹理映射来将粗网格渲染成2D图像。 由于[61]不是开源的,我们重新实现它并采用SMPL网格作为输入网格。 3)NHR [64]使用网络将输入点云渲染为图像。 这里我们将 SMPL 顶点作为输入点云。 表 2 显示了我们的方法与 [37,[61, 64]分别就 PSNR 度量和 SSIM 度量而言。 对于这两个指标,我们的模型在所有方法中实现了最佳性能。 特别是,我们的方法在 PSNR 方面优于以前的方法至少 4.20,在 SSIM 方面优于以前的方法至少 0.047。 与从个体学习 3D 表示相反虚拟潜在向量[37],神经体生成隐式来自同一组潜在代码的不同帧的字段。

图 4:ZJU-MoCap 数据集上的新颖视图合成。 “NV”表示神经体积[37],“NT”表示神经纹理[61]。 输入视频由四个摄像机捕获。 我们选择两种新颖的观点进行定性比较。 我们的方法明显优于[37, 44]。 此外,与图像到图像的翻译方法[61, 64]相比,我们可以生成时间一致的自由视点视频,这些视频在补充材料中呈现。
结果表明,我们的方法更好地整合了跨视频帧对目标表演者的观察。 图 4 显示了我们方法的定性结果其他方法[37,61,64,44]。 这里 NeRF [44] 为每个视频帧训练一个单独的网络。 [44, 37] 的渲染结果表明它们没有准确捕捉 3D 人体几何形状和外观。 NeRF [44] 的结果没有出现合理的形状,这表明 NeRF 未能学习正确的 3D 人体表示。 神经体积 [37] 给出了模糊的结果。 作为图像到图像的转换方法,[61, 64]难以控制渲染视点。 相比之下,我们的方法给出了逼真的新颖视图。 此外,我们的方法可以生成帧间和视图间一致的自由视点视频,这些视频在补充材料中呈现。
3D 重建性能。 我们在 ZJU-MoCap 数据集上测试了最先进的多视图方法 COLMAP [54, 55] 和 DVR [47]。 COLMAP [54, 55] 是一种成熟的多视图立体算法,DVR [47] 通过可微渲染器学习占用场 [42]。 我们发现他们无法仅从四个输入视图中恢复合理的 3D 人体形状。 为了进行比较,我们选择基于学习的方法,PIFuHD [53],作为基线方法。 PIFuHD 在 450 个高分辨率摄影测量扫描上训练单视图重建网络。 我们使用其发布的代码和预训练的模型进行推理。 第一个视图作为 PIFuHD 的输入。 为了提高其性能,我们删除了输入图像的背景。 [24, 52]提出了多视图重建网络,但他们没有发布预训练的模型,所以我们不与他们进行比较。 图 5 展示了我们的定性比较
方法和 PIFuHD。 神经体为人类在复杂的运动中生成精确的几何形状。 由于我们的方法从多视图图像中学习 3D 人体表示,因此重建人体模型的 3D 人体姿势与观察结果高度一致。 PIFuHD 的重建结果表明它不能很好地概括我们的数据。 对于具有复杂人体姿势的人,PIFuHD 无法恢复正确的人体形状。此外,其重建模型与从多视图图像中观察到的人体姿势不一致。
4.2. 单目视频的结果
我们证明我们的方法能够重建PeopleSnapshot 数据集上的单眼视频中的动态人物 [2]。 该数据集捕获表演者在保持 A 姿势时旋转的情况。 由于移动人体的姿势并不复杂,因此可以从单目视频中准确估计 SMPL 参数。 我们com-使用[2]中提出的方法对神经体进行优化,该方法对 SMPL 模型的顶点进行变形以适应视频序列上的 2D 人体轮廓。 继[2]之后,我们报告了 People-Snapshot 数据集的定性结果。
新颖视图合成的性能。 图 6 显示了新颖视图合成的定性比较。 我们的方法比[2]渲染了更多的外观细节,尤其是穿着宽松衣服的表演者的7个细节。 例如,Neural Body 准确地渲染了第一人称的衬衫,而 [2] 渲染的衬衫则紧密贴合人体。 一些场景是在室外环境中拍摄的,表现出强烈的光照变化。 逼真的渲染结果表明神经体可以处理复杂的光照条件。
3D 重建性能。 我们的方法和 [2] 的定性结果如图 7 所示。神经体比 [2] 恢复了更多的几何细节。 例如,头发形状与 RGB 观察结果高度一致。 最后一列的结果表明我们的方法可以处理穿着宽松衣服的人,而[2] 无法恢复此类数据的正确形状。
4.3. ZJU-Mocap 数据集的消融研究
我们对视频“Twirl”进行消融研究。 我们首先分析每帧潜在嵌入的效果。 然后我们探索使用不同数量的视频帧和输入视图训练的模型的性能。 每帧潜在嵌入的影响。 我们训练一个没有潜在嵌入的模型 {t}Nt t=1 被提议在第 3.3 节中,给出了 30.03 PSNR,低于完整模型的 30.56 PSNR。 这一比较表明,潜在嵌入产生了 0.53 PSNR 改进。 摄像机视图数量的影响。 表 3 ,对比我们用不同数量的摄像机视图训练的模型。 结果表明,训练视图的数量提高了新视图合成的性能。 在单一视图上训练的神经体仍然优于在四个视图上训练的 [37],这在消融研究的测试视图上给出了 23.12 PSNR 和 0.875 SSIM。 视频长度的影响。 我们用 1 来训练我们的模型,分别为 60、300、600 和 1200 帧。 结果是在视频“Twirl”的第一帧上评估的。 表 4 显示了定量结果,这表明对视频进行训练可以提高视图合成性能,但对太多帧进行训练可能会降低性能,因为网络难以拟合很长的视频。

图 5:ZJU-MoCap 数据集的 3D 重建。 神经体实现高质量重建。 我们的方法能够恢复衣服,例如第三人的连帽衫。 PIFuHD [53] 不能很好地概括数据集。

图 6:单目视频的新颖视图合成。 我们的方法比 People-Snapshot [2] 渲染了更多的外观细节,例如第一人的衬衫和第二人的裤子。 放大查看详细信息。

图 7:单目视频的 3D 重建。 与 People-Snapshot [2] 中的方法相比,Neural Body 生成更详细的几何形状,并且可以处理穿着宽松衣服的人。

表 3:在 ZJUMoCap 数据集的视频“Twirl”上使用不同数量的摄像机视图训练的模型结果。 我们选择六个摄像机视图进行消融研究并使用剩余的视图进行测试。

表 4:使用不同数量的训练帧训练的模型的结果。 我们在 1、60、300、600 和 1200 帧并在“Twirl”的第一帧上进行测试。
结论
我们引入了一种新颖的隐式神经表示,名为 Neural Body,用于从稀疏的多视图视频中合成动态人体的新颖视图。 神经体定义了一组潜在代码,它们使用神经网络对局部几何形状和外观进行编码。 我们将这些潜在代码锚定到可变形人体模型的顶点以代表动态人体。 这使我们能够建立一个潜在变量模型,该模型可以从同一组潜在代码生成不同视频帧的隐式场,从而有效地合并跨视频帧对表演者的观察。 我们通过体积渲染的视频学习了神经体。 为了评估我们的方法,我们创建了一个名为 ZJU-MoCap 的多视图数据集,用于捕捉复杂运动中的动态人体。 与之前的工作相比,我们展示了卓越的视图合成质量新收集的数据集和人物快照数据集。