逻辑回归变量系数可为负数吗?应该如何解释?
之前很多学员来问逻辑回归变量系数是否都应该为正数,如果出现负的变量系数该怎么办?是否需要重新建模?这些学员都是在网上搜索时,被错误信息误导。网上信息可以随意转载,且无人审核对错。我见过最多情况时很多文章正确信息夹杂着错误或不准确信息。今天我们来谈一下逻辑回归变量系数正负的问题。
逻辑回归模型中的变量系数可以是负数。在逻辑回归中,变量系数表示了自变量对因变量的影响程度,它的正负号表示了影响的方向。正系数表示自变量增加会增加因变量的概率,负系数则表示自变量增加会减少因变量的概率。因此,负系数在逻辑回归模型中是合理存在的。
为了更好解释,我展示了英文原文释义Negative coefficients in a logistic regression model translate into odds ratios that are less than one (viz., (0,1)). That in turn, means that the predicted probability is decreasing as the covariate increases.
与预测变量 X 相关的逻辑回归系数 β 是 X 中每单位变化产生结果的对数几率的预期变化。因此,将预测变量增加 1 个单位(或从 1 个级别到下一个级别)会乘以具有以下结果的几率:结果为 e β。
这是一个例子:
假设我们要研究吸烟10年与心脏病的风险。下表显示了使用吸烟作为预测因子来模拟心脏病存在的逻辑回归的摘要:
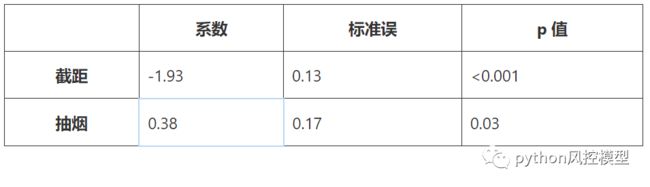
问题是:如何解读吸烟系数:β=0.38?
首先请注意,该系数具有统计显着性(与 p 值 < 0.05 相关),因此我们的模型表明吸烟确实会影响 10 年患心脏病的风险。因为它是一个正数,我们可以说吸烟会增加患心脏病的风险。
但增加多少呢?
1. 如果吸烟是一个二元变量(0:不吸烟者,1:吸烟者):
那么:e β = e 0.38 = 1.46 将是吸烟与心脏病风险相关的比值比。
这意味着:吸烟组患心脏病的几率是不吸烟组的1.46倍。
或者我们可以这样说:
吸烟组患心脏病的几率比不吸烟组高 46% (1.46 – 1 = 0.46)。
如果心脏病是一种罕见的结果,那么优势比就可以很好地近似相对风险。在这种情况下我们可以说:
与不吸烟者相比,吸烟者患心脏病的概率增加 1.46 倍。
或者我们可以这样说:
与不吸烟组相比,吸烟组患心脏病的相对风险高出 46%。
负系数注释:
如果 β = – 0.38,则 e β = 0.68,解释为:吸烟与心脏病相对风险降低32% (1 – 0.68 = 0.32)相关。
为了解释具有多个级别的分类预测变量,我撰写了以下文章:R 中的逻辑回归(带有分类变量)。
如何解释标准误?
标准误差是逻辑回归系数不确定性的度量。它对于计算相应系数的 p 值和置信区间非常有用。
从上表中我们可以得到:SE = 0.17。
我们可以使用以下公式计算 95% 置信区间:
95% 置信区间= exp(β ± 2 × SE) = exp(0.38 ± 2 × 0.17) = [ 1.04, 2.05 ]
所以我们可以说:
我们有 95% 的信心认为,吸烟者患心脏病的几率比不吸烟者平均高 4 至 105%(1.04 – 1 = 0.04 和 2.05 – 1 = 1.05)。
或者,更宽松地说:
根据我们的数据,与不吸烟者相比,我们预计吸烟者患心脏病的几率会增加 4% 至 105%。
如何解释拦截?
截距为 β 0 = -1.93,应假设模型中所有预测变量的值为 0 来解释它。
如果我们使用以下公式计算逆 logit,则截距可以很容易地用概率(而不是几率)来解释:
e β 0 ÷ (1 + e β 0 ) = e -1.93 ÷ (1 + e -1.93 ) = 0.13,因此:
不吸烟者在未来10年内患心脏病的概率是0.13。
即使不计算这个概率,如果我们只看系数的符号,我们就知道:
-
如果截距有负号:那么得到结果的概率将< 0.5。
-
如果截距有正号:那么得到结果的概率将 > 0.5。
-
如果截距等于0:那么得到结果的概率恰好为 0.5。
有关如何解释各种情况下截距的更多信息,请参阅我的另一篇文章:解释逻辑回归截距。
2. 如果吸烟是一个数值变量(终生使用烟草量,以千克为单位)
然后:e β (= e 0.38 = 1.46) 告诉我们预测变量(吸烟)每变化 1 个单位,结果(心脏病)的几率将发生多大变化。
所以:
一生吸烟量增加 1 公斤,患心脏病的几率就会增加 1.46 倍。
或者同样:
一生吸烟量增加 1 公斤,患心脏病的几率就会增加 46%。
解释标准化变量的系数
标准化变量是重新调整平均值为 0、标准差为 1 的变量。这是通过减去变量的每个值的平均值并除以标准差来完成的。
标准化会产生可比的回归系数,除非模型中的变量具有不同的标准差或遵循不同的分布(有关更多信息,我推荐我的两篇文章:标准化与非标准化回归系数以及如何评估线性和逻辑回归中的变量重要性)。
无论如何,当您的模型中有超过 1 个预测变量,每个预测变量都以不同的尺度进行测量,并且您的目标是比较每个预测变量对结果的影响时,标准化很有用。
标准化后,具有最大系数的预测变量 X i是对结果 Y 影响最重要的预测变量。
然而,标准化系数本身并没有直观的解释。因此,在上面的示例中,如果吸烟是标准化变量,则解释为:
吸烟每增加 1 个标准差,患心脏病的几率就会增加46% (e β = 1.46)。
3. 如果吸烟是序数变量(0:不吸烟者,1:轻度吸烟者,2:中度吸烟者,3:重度吸烟者)
有时将吸烟分为几个有序类别是有意义的。这种分类允许 10 年患心脏病的风险从一个类别改变到下一个类别,并迫使其在每个类别内保持恒定,而不是随着吸烟习惯的每一个微小变化而波动。
在这种情况下,系数 β = 0.38 也将用于计算 e β (= e 0.38 = 1.46),其解释如下:
吸烟量从一级增加到一级会使患心脏病的几率增加 1.46 倍。
或者,我们可以说:
吸烟量从一级增加到一级会导致患心脏病的几率增加 46%。
重要提示:
关于统计显着性和 p 值:
如果模型中包含 20 个预测变量,则平均有 1 个预测变量具有统计显着性 p 值 (p < 0.05),这只是偶然的。
所以要注意:
-
仅根据 p 值从逻辑回归模型中包含/排除变量。
-
仅仅因为它们的 p 值小于 0.05,就将统计效应标记为“真实”。
如果你得到一个非常大的逻辑回归系数怎么办?
在上面的示例中,如果我们想研究吸烟对心脏病的影响,并且样本中的大多数参与者都是非吸烟者,则可能会出现非常高的系数和标准误差。这是因为高度倾斜的预测变量更有可能产生完美分离的逻辑模型。
因此,为了研究自变量 X 对结果 Y 的影响,需要自变量 X 具有一定的可变性。因此,在对数据进行建模之前,请确保您做好数据的前期描述性统计工作,保证数据合理性。
如果大家对逻辑回归和评分卡知识感兴趣,欢迎大家收藏和报名《python信用评分卡建模(附代码)》课程,课程详细介绍了逻辑回归的每个知识细节,包括woe编码,多种策略分箱,iv统计,并有实战数据集和Python代码实现。具体目录大家可微信扫码查阅了解。

版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。