JAVA8-lambda表达式2:常用的集合类api
目录
引子
Stream接口
求值方法
常用的流操作
collect
map转换
filter过滤
方法引用
groupingBy
partitioningBy
引子
今天看到新闻,很多新闻类APP被处罚,其中就有今日头条的内涵段子,原因是低俗,涉黄。
对于这种,我是拍手称快的。做为一个码农,本质还是社会人,要有社会责任心,这种引导社会不良风气的东西,也要拒绝的,多少学生被游戏农药坑,女生被所谓的直播脱光衣服?做一个正直的人
前面介绍了Lambda表达式,有了初步概念,这一节我们来看下,它对于编程来说有什么好处,是不是能提高效率,让程序理简单?
Lambda表达式对集合类的API操作改进及新引进的流Stream,使我们对集合的操作多了一个选择
先来看一个例子,假设有一个学生类Person,
@Data
public class Person {
/**
* 名字
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer sex;
public Person(String name, Integer age, Integer sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
}并设置3位学生
// 学生集合
Person kobe = new Person("kobe", 40, 1);
Person jordan = new Person("jordan", 50, 1);
Person mess = new Person("mess", 20, 2);
List personList = Arrays.asList(kobe, jordan, mess); 现在有个需求,找出所有的男同学集合,用原来的方式,可能会这么写
// 找出所有男同学
// 原来的方式
List oldBoys = new ArrayList<>(personList.size());
for(Person p : personList) {
// 性别男
if (p.getSex() == 1) {
oldBoys.add(p);
}
}
log.info(oldBoys.toString()); 那写流方式呢?我们先看下写法
// 流方式
List newBoys = personList.stream().filter(p -> 1 == p.getSex()).collect(Collectors.toList());
log.info(newBoys.toString()); 咦,是不是有点奇怪?习惯这种写法吗?来分析下
1.personList.stream()返回一个Stream接口
2.顾名思义,方法filter应该是过滤操作,满足条件性别是男的同学
3.collect方法,收集上一步的流为List集合
整个流程图示例如下
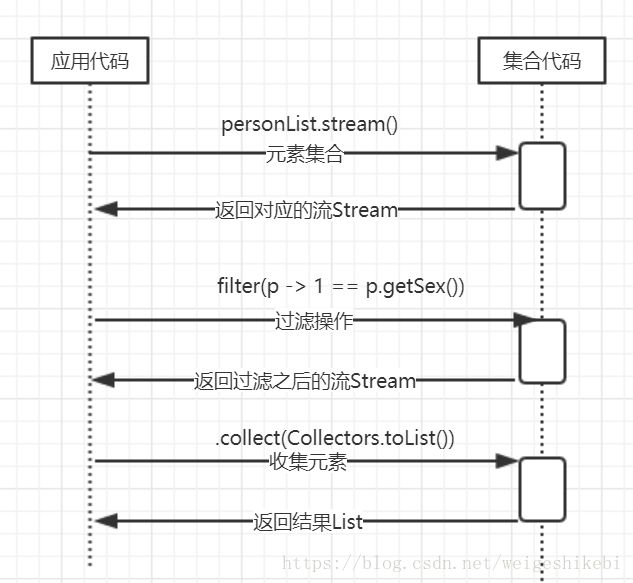
通过上面,我们发现跟以前代码有什么不同呢?有的,用流方式,应用代码不用再显示的控制循环,只要传入想要的行为,它自己控制迭代,并返回最终的结果,所以上图可以简化成下面这个图

构建操作指的是什么呢?就是我们对集合元素的各种限制条件,上面的过滤filter就是一种,再比如对上面得到的所有男同学按年龄排序,该如何写呢
// 所有男同学按年龄排序
List sortedBoys = personList.stream()
// 筛选出男同学
.filter(p -> 1 == p.getSex())
// 排序
.sorted(Comparator.comparing(Person::getAge))
.collect(Collectors.toList()); 是不是有点类似js的链式写法?这是因为filter,sorted返回的都是Stream接口!
Stream接口
Stream接口就是流操作的上层接口,如果一个方法返回Stream,我们就可以继续使用它,进行其它任何想要的元素处理,而不用显示的遍历它,这称之为内部迭代;相反,原来的java迭代方式称为外部迭代
所以对于外部迭代,要应用程序去写很多样板代码去控制循环,使程序意图不清晰,不仔细读一遍代码,很难理解意图,比如
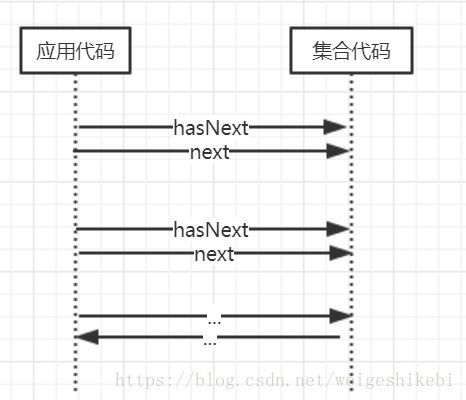
那有人会说,如果一个操作,产生了多个Stream,是不是内部就会循环多次,效率反而不如以前,因为只循环一次?看一个例子
,统计所有年龄>20的同学个数
// 男同学人数
personList.stream()
// 不为空
.filter(p -> {
System.out.println("过滤非空的同学");
return !Objects.isNull(p);
})
// 筛选出男同学
.filter(p -> 1 == p.getSex())
// 年龄大于20
.filter(p -> p.getAge() > 20);执行一下,会发现
// 男同学人数
personList.stream()
// 不为空
.filter(p -> {
System.out.println("过滤非空的同学");
return !Objects.isNull(p);
})
// 筛选出男同学
.filter(p -> {
System.out.println("筛选出男同学");
return 1 == p.getSex();
})
// 年龄大于20
.filter(p -> {
System.out.println("年龄大于20");
return p.getAge() > 20;
});执行一下,会发现,并没有日志打印。
修改一下
// 男同学人数
long boys = personList.stream()
// 不为空
.filter(p -> {
System.out.println("过滤非空的同学");
return !Objects.isNull(p);
})
// 筛选出男同学
.filter(p -> {
System.out.println("筛选出男同学");
return 1 == p.getSex();
})
// 年龄大于20
.filter(p -> {
System.out.println("年龄大于20");
return p.getAge() > 20;
})
.count();
可以发现,最多打印的日志有3次,所以流并不会比原来的迭代效率低(没有基准测试验证过,下次可以测试下),相关,由于实现在底层会有自动优化,真实会快的多
那么,有个问题,为什么上面的代码会没有输出呢,加了count才打印?
求值方法
前面返回Stream的方法,统一称为惰性求值方法,这个时候并不会产生新的集合,所有的操作只是产生新集合的配方
而count,collect这种产生新集合的方法,称为及早求值方法,会结束流操作,返回新的集合
那么怎么判断一个操作是及早还是隋性操作呢?easy,如果返回的是Stream,就是随性;反之,返回空或者另外一个值就是及早求值;所以我们构建操作的过程,可以指定多个随性操作,形成一个随性链,等到要结束它的时候,调用一个及早求值方法,返回想要的结果,这也是正是它的设计初衷
常用的流操作
collect
很常见的一个需求,如果要获取所有学生的姓名集合,怎么搞?如果用原来的方式,代码可能如下
// 获取学生的姓名
List names = new ArrayList<>(personList.size());
for (Person p : personList) {
names.add(p.getName());
} 那java8呢,我们看一下
// 获取学生的姓名
List personNames = personList.stream().map(Person::getName).collect(Collectors.toList()); 先用流方式,转化为名称,再收敛为List集合。collect方法,我喜欢称之为收敛,是一个及早求值的方法;它还可以转化为map,比如,将学生信息映射为一个名称为key,年龄为value的集合
// 获取学生姓名,年龄信息
Map personMap = personList.stream().collect(Collectors.toMap(Person::getName, Person::getAge)); 但是上面的方法有一个前提,就是key不能重复,如果2个学生姓名一样,方法会报错(相信我,你一定会碰到类似情况);这个也很容易理解,一般来说,做为map的key应该唯一,如果你实在有这种重复的情况,可以选择自己处理key,比如
// 获取学生姓名,年龄信息,处理重复key:用新的key覆盖旧key
Map dulipcateMap = personList.stream()
.collect(Collectors.toMap(Person::getName, Person::getAge, (o, n) -> n)); map转换
在上面介绍collect的时候,我们看到了一个方法,map,我觉得称之为转换好一点,比如把A变成B,男变成女

它是一个惰性求值方法,我们可以传入一个Lambda表达式,指定转换规则,比如再有一个类Teacher,将年龄>45的学生变成都(很有可能啊,徒弟长大后又成了师父)
// 将age>45的学生提拔成师父
personList.stream().filter(p -> p.getAge()> 45).map(p -> {
Teacher t = new Teacher();
t.setName(p.getName());
t.setAge(p.getAge());
t.setSex(p.getSex());
return t;
}).collect(Collectors.toList());所以对于map转换来说,只要指定转换的配方(一个函数式接口,也即lambda表达式),剩下的交给jvm就可以了

filter过滤
在上面一个示例中,出现了filter方法,它的作用是过滤符合条件的元素,比如过滤年龄大于45的同学,或者男同学
personList.stream()
// 不为空
.filter(p -> {
System.out.println("过滤非空的同学");
return !Objects.isNull(p);
})
// 筛选出男同学
.filter(p -> {
System.out.println("筛选出男同学");
return 1 == p.getSex();
})
// // 年龄大于20
.filter(p -> {
System.out.println("年龄大于20");
return p.getAge() > 20;
})
它接受一个函数式接口,根据过滤条件返回true或false,找出符合条件的元素
![]()
我们发现filter之后元素变少,map之后不变;
方法引用
上面在转换的时候,我们取值的时候有2种写法,比如p -> p.getName,Person::getName,有什么区别?没有区别
所有可以调用Lambda的地方,都可以用::这种方法引用!
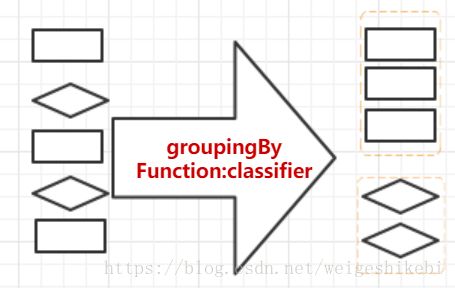
groupingBy
我们知道,SQL中的group by,现在java中也有类似的分组方法了,groupingBy!我们来对比下
// 学生集合
Person kobe = new Person("kobe", 40, 1);
Person jordan = new Person("jordan", 50, 1);
Person mess = new Person("mess", 20, 2);
List personList = Arrays.asList(kobe, jordan, mess);
// 按性别分组
Map> groupSex = personList.stream().collect(Collectors.groupingBy(Person::getSex)); 以前的方式,一种可能的实现
Map> sexMap = new HashMap<>();
for (Person p : personList) {
if (sexMap.containsKey(p.getSex())) {
sexMap.get(p.getSex()).add(p);
continue;
}
if (null == sexMap.get(p.getSex())) {
sexMap.put(p.getSex(), new ArrayList<>());
}
sexMap.get(p.getSex()).add(p);
} 
partitioningBy
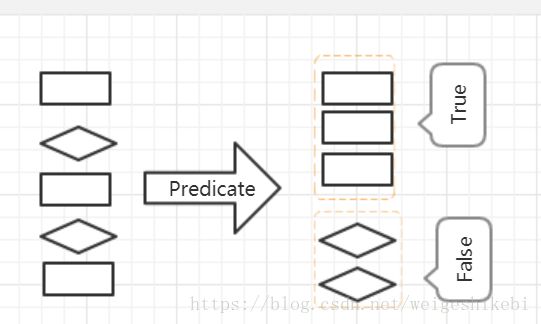
数据分块。我们可以用流操作把数据分成2个集合,利用Predicate对象判断属于哪个部分,并根据布尔值返回等到一个Map.比如想把所有同学按性别划分
// 按性别划分
Map> partionSex = personList.stream().collect(Collectors.partitioningBy(p -> p.getSex() == 1));