统一观测|借助 Prometheus 监控 ClickHouse 数据库
引言
ClickHouse 作为用于联机分析(OLAP)的列式数据库管理系统(DBMS), 最核心的特点是极致压缩率和极速查询性能。同时,ClickHouse 支持 SQL 查询,在基于大宽表的聚合分析查询场景下展现出优异的性能。因此,获得了广泛的应用。本文旨在分享阿里云可观测监控 Prometheus 版对开源 ClickHouse 的监控实践。
一、ClickHouse 简介
(一)技术特点
- 列式存储与数据压缩:
在执行数据查询时,列式存储可以减少数据扫描范围和数据传输大小,提高数据查询的效率。
- 完备的 DBMS 功能
-
- DDL (数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无须重启服务;
- DML(数据操作语言):可以动态查询、插入、修改或删除数据。
- 权限控制:
可按照用户粒度设置数据库或表的操作权限,保障数据安全性。
- 数据备份与恢复
提供数据备份导出与导入恢复机制,满足生产环境要求。
- 分布式管理
提供集群模式,自动管理多个数据库节点。
(二)ClickHouse 典型适用场景
- 复杂查询聚合的 OLAP 场景;
- 需要支持稳定大量数据写入;
- 不需要高频查询;
- 不需要高级 DBMS 功能,如事务性;不需要经常很复杂的表间操作,比如 join 操作。
(三)ClickHouse 核心概念
- ClickHouse 集群(Cluster)
在物理构成上,ClickHouse 集群是由多个 ClickHouse Server 实例组成的分布式数据库。这些 ClickHouse Server 根据规格的不同可以包含 1 个或多个副本(Replica)、1 个或多个分片(Shard)。在逻辑构成上,一个ClickHouse 集群可以包含多个数据库(Database)对象。
- 分片(Shard)
在超大规模海量数据处理场景下,单台服务器的存储、计算资源会成为瓶颈。为了进一步提高效率,ClickHouse 将海量数据分散存储到多台服务器上,每台服务器只存储和处理海量数据的一部分,在这种架构下,每台服务器被称为一个分片(Shard)。
- 副本(Replica)
为了在异常情况下保证数据的安全性和服务的高可用性,ClickHouse 提供副本机制,将单台服务器的数据冗余存储在2台或多台服务器上。
- 数据库(Database)
数据库是云数据库 ClickHouse 集群中的最高级别对象,内部包含表(Table)、列(Column)、视图(View)、函数、数据类型等。
- 表(Table)
表是数据的组织形式,由多行、多列构成。
二、ClickHouse Metrics 监控参考模型
我们从 Metrics 采集、监控大盘、告警规则等三个方面定义 ClickHouse Metrics 监控的参考模型,以便实现监控闭环。
(一)Metrics 采集
- 主机节点监控即硬件资源(Node-Exporter)
-
- 处理器、内存负载;
- 磁盘存储;
- ClickHouse 服务指标监控(集成进 ClickHouse-Exporter)
-
- 系统指标(metrics): system.metrics 表用于统计 ClickHouse 服务在运行时,当前正在执行的高层次的概要信息,包括了正在执行的查询总次数、正在发生的合并操作总次数等。具体指标通过执行
select * from system.metrics; - 系统事件(events):system.events 用于统计 ClickHouse 服务在运行过程中已经执行过的高层次的 累积概要信息,包括查询总次数、 SELECT 查询总次数等,具体指标通过执行查询
select * from system.events–> 64个指标; - 系统异步指标(asynchronous_ metrics):asynchronous_metrics 用于统计 ClickHouse 服务运行过程时,当前正在后台 异步运行的高层次的概要信息,包括当前分配的内存、执行队列中的任务数量等。 具体指标通过执行查询
select * from system.asynchronous_metrics--> 500个指标; - 查询日志:查询日志目前主要有6种类型,所有查询日志在默认配置下都是关闭状态,需要在 config.xml文件配置,开启日志后可以到对应的日志表进行日志查询
system.query_log。
- 系统指标(metrics): system.metrics 表用于统计 ClickHouse 服务在运行时,当前正在执行的高层次的概要信息,包括了正在执行的查询总次数、正在发生的合并操作总次数等。具体指标通过执行
(1)主机节点监控
该部分指标主要来源于 Node-Exporter , 提供集群/ ECS 节点 CPU、内存、磁盘、inode 等监控指标。
(2)ClikcHouse 服务指标
ClikckHouse 内置 Metrics、events 和 asynchronous_metrics 三张系统表用于存放其监控指标,通过预先安装 clickhouse-exporter 将这三张系统表中的数据转化、发送给阿里云可观测监控 Prometheus 版。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HnNhT8a5-1690884166323)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/4751cbf35ce647358882850f99c9107c~tplv-k3u1fbpfcp-watermark.image?)]


⚠️注意: 以上列出的为关键指标,更多详细指标详见: 应用实时监控服务ARMS控制台-Prometheus监控-Prometheus实例列表-选择实例-集成中心-ClickHouse
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Eq7CbV73-1690884166324)(https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/d8ff3a8873ab472d8643e9e6ef6f88c5~tplv-k3u1fbpfcp-watermark.image?)]
(二)ClickHouse 监控大盘
我们默认提供了arms-clickhouse-ecs和arms-clickhouse-k8s两个大盘,分别针对 ClickHouse 安装在ACK 集群/ ECS 中两个场景,这两个大盘中图标均来自于上述 Metrics 指标。
⚠️注意: 主机节点监控需提前安装 Node-Exporter,以下大盘图示数值仅为展示作用,不具备参考价值,实际数值依 ClickHouse 环境而定
(1)主机节点指标
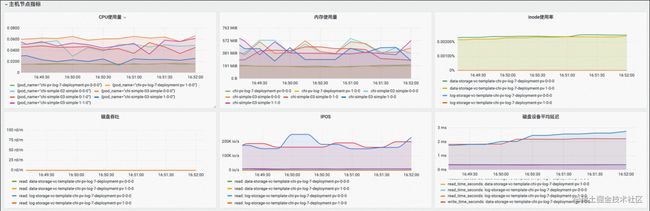
(2)ClickHouse Server指标

(3)MergeTree 指标
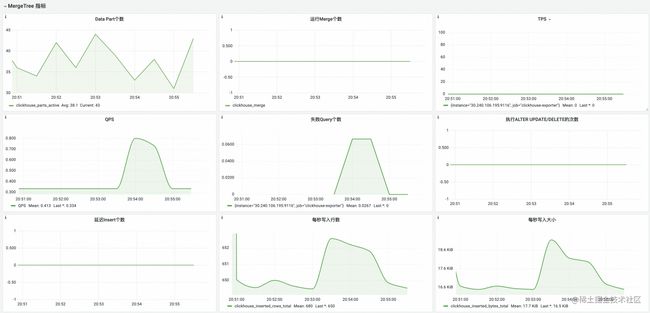
(4)消息队列指标

(三)告警规则
参考前面对各项主要指标介绍,针对 ClickHouse 可以重点配置以下告警项,这些告警项已内置到arms-clickhouse告警规则中,可依据自身业务情况及经验调整告警阈值:
- 【L0】CPU 超过 90%
- 【L0】Mem 超过 90%
- 【L0】Disk 超过 90%
- 【L0】Inode 使用率超过 90%
- 【L0】写入失败率超过 5%
- 【L1】运行 Query 个数超过 95
- 【L1】连接数超过 4k
- 【L1】失败 Query 个数超过 10
(四)相关实践示例
(1)CPU 过高
- 确认 CPU 占用过高是由 ClickHouse 引起的。可以通过 top 命令
top -H -p xxx查看系统的 CPU 占用率,找出占用 CPU 比较高的进程。如果发现 ClickHouse 进程占用了大量 CPU 资源,那么就需要进一步排查。 - 使用 ClickHouse 内置查询来查看系统的状态。可以使用以下查询:
SHOW PROCESSLIST query WHERE query NOT LIKE '%SYSTEM%' ORDER BY elapsed DESC LIMIT 10
这个查询可以列出最耗时的查询,找到可能引起 CPU 占用过高的查询语句。
- 检查 ClickHouse 配置。一些配置参数可能导致 ClickHouse 占用大量 CPU 资源。可以查看 ClickHouse 配置文件,确认配置是否合理,是否需要调整。
- 检查 ClickHouse 日志。ClickHouse 日志中可能包含错误信息或警告信息,可以帮助找出问题所在。
- 检查硬件资源是否充足。如果系统 CPU、内存等硬件资源不足,那么 ClickHouse 可能会出现 CPU 占用过高的情况。可以检查系统的硬件资源使用情况,确认是否需要升级硬件。
- 升级 ClickHouse 版本。如果是 ClickHouse 版本的问题,可以考虑升级到更稳定的版本。
(2)内存过高
- 使用内置查询查看内存占用情况。可以使用以下查询来查看 ClickHouse 系统的内存占用情况:
SELECT * FROM system.metrics WHERE metric LIKE '%memory%';
这个查询会列出 ClickHouse 的各个内存指标,包括总内存、已用内存、缓存内存等。可以根据这些指标来判断内存占用是否过高。
- 检查 ClickHouse 的配置。一些配置参数可能会导致 ClickHouse 占用大量的内存资源。可以查看 ClickHouse 的配置文件,确认配置是否合理,是否需要调整。
- 检查系统的内存资源使用情况。如果系统的内存资源不足,那么 ClickHouse 可能会出现内存占用过高的情况。可以使用命令
free -m查看系统的内存使用情况。 - 检查 ClickHouse 的日志。ClickHouse 的日志中可能包含错误信息或警告信息,可以帮助找出问题所在。
- 升级 ClickHouse 版本。如果是 ClickHouse 版本的问题,可以考虑升级到更稳定的版本。
- 减少查询语句的数据量和计算量。如果查询语句的数据量和计算量过大,那么 ClickHouse 可能会占用大量的内存资源。可以考虑优化查询语句,减少数据量和计算量。
(3)Disk 占用过高
- 使用系统工具查看磁盘占用情况。可以使用命令
df -h来查看系统的磁盘使用情况,查看是否有磁盘空间不足的情况。 - 检查 ClickHouse 的配置。一些配置参数可能会导致 ClickHouse 占用大量的磁盘资源。可以查看 ClickHouse 的配置文件,确认配置是否合理,是否需要调整。
- 使用 ClickHouse 内置的查询来查看磁盘占用情况。可以使用以下查询来查看 ClickHouse 的磁盘占用情况:
SELECT database, table, sum(bytes) AS total_size FROM system.parts WHERE active GROUP BY database, table ORDER BY total_size DESC
这个查询会列出 ClickHouse 的各个表的占用磁盘空间情况,可以根据这个查询来判断磁盘占用是否过高。
- 检查 ClickHouse 的日志。ClickHouse 的日志中可能包含错误信息或警告信息,可以帮助找出问题所在。
- 清理不必要的数据。如果 ClickHouse 中存在不必要的数据,可以考虑进行清理,释放磁盘空间。
三、如何使用阿里云可观测监控 Prometheus 版监控ClickHouse 服务
(一)安装 Prometheus 监控
(1)前序条件:已根据安装ClickHouse 安装环境,创建对应Prometheus 实例。
根据 ClickHouse 安装方式:
- 如果 ClickHouse 部署在 ACK 中, 并创建了Prometheus for 容器实例,创建请参考
Prometheus for 容器服务; - 如果 ClickHouse 部署在 ECS 中, 并创建了Prometheus for ECS 实例,创建请参考
Prometheus for ECS。
(2)安装方式一:Prometheus for 容器服务
在Prometheus for 容器服务实例中,ClickHouse 已经默认在集成中心中展示,用户可以在应用实时监控服务ARMS控制台-Prometheus监控-Prometheus实例列表-选择Prometheus for 容器服务实例-集成中心中找到入口,点击 ClickHouse 图标,可以看到常见的指标列表和大盘缩略图。点击+安装可以接入 ClickHouse 监控,配置如下图:
- Exporter 名称: 自定义 Exporter 名称;
- ClickHouse Scrape 地址: IP + Port, Exporter 能够访问的 ClickHouse 地址 ;
- ClickHouse 用户名: 登陆用户名;
- ClickHouse 密码: 登陆密码;
- Metrics 采集间隔(秒): 默认 30s 采集一次, 一般不需要更改。
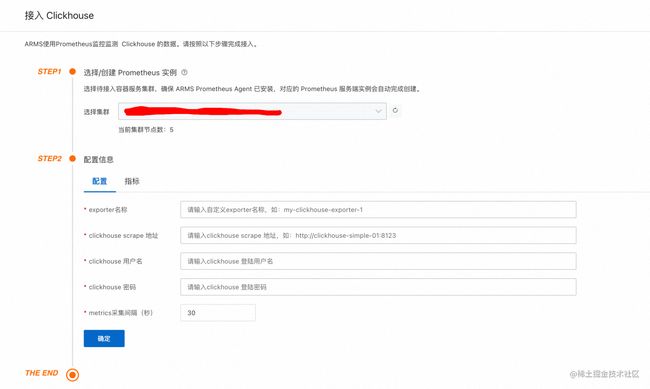
点击确定后, clickhouse-exporter-填入的名称的 Exporter 会被安装到 arms-prom 命名空间下,并自动完成采集 job 的配置。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GA1WKNkd-1690884166325)(https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f786418e6ef34e38bf36b235c00919c2~tplv-k3u1fbpfcp-watermark.image?)]
可以在应用实时监控服务ARMS控制台-Prometheus监控-Prometheus实例列表-选择Prometheus for 容器服务实例-集成中心-已安装-ClikckHouse中快速浏览相关的 Target/指标/大盘/告警/服务发现/ Exporter 等信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-po1p9fXY-1690884166326)(https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/19151467be0c4cfcb05491b42c772f70~tplv-k3u1fbpfcp-watermark.image?)]
(3)安装方式二:Prometheus for ECS
安装 ClickHouse 相同 VPC 的Prometheus for ECS实例,由于Prometheus for ECS实例中 ClickHouse 的主机节点监控来自于Node-Exportor,所以先安装 Node-Exportor。用户可以在
应用实时监控服务ARMS控制台-Prometheus监控-Prometheus实例列表-选择Prometheus for ECS实例-集成中心中找到入口,点击Node-Exporter图标,点击+安装可以接入 Node-Exporter 监控,然后选择对应 ECS 实例安装即可。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vd88MhI2-1690884166326)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/94f139bc30e348fdbbee9d46adada401~tplv-k3u1fbpfcp-watermark.image?)]
用户可以在应用实时监控服务ARMS控制台-Prometheus监控-Prometheus实例列表-选择Prometheus for ECS实例-集成中心中找到入口,点击 ClickHouse 图标,点击+安装可以接入 ClickHouse 监控,配置与上述Prometheus for 容器服务相同。
(4)指标未采集的排查方法
⚠️注意: 下面是Prometheus for 容器实例的排查方法,Prometheus for ECS实例请联系Prometheus值班-美娜
ClickHouse-Exporter 本身的主要工作是指标映射,需要填入正确 ClickHouse 抓取 URL及登陆用户名、密码。如果出现指标采集不到的问题,可以参考如下的排查思路。
- 检查 Prometheus Target 状态,如果 Target 显示为
Unhealthy状态,请排查clickhouse-exporterPod 运行状态;如果 Target 状态正常,继续下一步。

- 若 Target 状态正常,但抓取指标量很少且指标全为
go_相关查看clickhouse-exporterPod 日志,确认日志中是否有报错信息。

- 查看
clickhouse-exporterPod 日志,确定 Exporter 抓取目标 URL 是否正常。

(二)查看大盘
如需要查看 ClickHouse 相关大盘,可以从应用实时监控服务ARMS控制台-Prometheus监控-Prometheus实例列表-实例详情页-集成中心-已安装-ClikckHouse中点选大盘,列出两类大盘arms-clickhouse-ecs和arms-clickhouse-k8s,根据环境选择对应的大盘模板。
以下是arms-clickhouse-k8sVariables 参数说明:
- datasource : 数据源,选择对应的实例名称;
- job: 新建 clickhouse-exporter 对应 job 名称,与 clickhouse-exporter 名称一致,用于展示ClickHouseServer 指标、MergeTree 指标、消息队列指标;
- namespace: ClickHouse Pod 所在的命名空间,用于主机节点指标筛选;
- Pod: 可根据需要选择对应的 ClickHouse Pod,用于主机节点指标筛选。

以下是arms-clickhouse-ecsVariables参数说明:
- datasource: 数据源,选择对应的实例名称;
- job: 新建的 clickhouse-exporter 对应 job 名称,与clickhouse-exporter 名称一致,用于展示ClickHouseServer 指标、MergeTree 指标、消息队列指标;
- instance: ecs 实例 IP,用于主机节点筛选。

(三)配置告警
在集成中心安装 ClickHouse 监控时,已经默认增加了arms-clickhouse告警分组的相关规则,但未启用,您只需要简单修改参数并确认启用即可。
可以从应用实时监控服务ARMS控制台-Prometheus监控-Prometheus实例列表-实例详情页-集成中心-已安装-ClikckHouse中选择告警-创建告警规则进入规则新增页面,在其中告警分组选择arms-clickhouse告警分组并根据环境选择您需要启用的告警指标,确认参数阈值并保存,即可完成告警规则的创建。

四、自建 Prometheus 与阿里云可观测监控 Prometheus 版监控 ClickHouse 优劣对比
Prometheus 作为目前主流可观测开源项目之一,已被众多企业所广泛应用,但还会遇到不少困难与挑战:
- 每套完整的自建观测系统都需要安装并配置 Prometheus、Grafana、AlertManager 等组件,部署过程复杂、实施周期长,并且每次升级都需要对每个组件进行维护;
- 开源分享的相关大盘不够专业,更新速度慢,缺少开箱即用的丰富指标;
- 由于安全、组织管理等因素,用户业务通常部署在多个相互隔离的 VPC,需要在多个 VPC 内都重复、独立部署 Prometheus,导致部署和运维成本高。
针对以上问题,阿里云可观测监控 Prometheus 版进行了以下优化:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8VBeUhSX-1690884166329)(https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/e9e4aa28a9284725a73a048ce209d91d~tplv-k3u1fbpfcp-watermark.image?)]
结束语
阿里云可观测监控 Prometheus 版与阿里云容器服务无缝集成,提供了开源 ClickHouse 的指标采集、用户大盘、告警规则等项目的一键集成,用户免运维,开箱即用,目前 ClickHouse 指标采集功能仍在不断演进中,欢迎大家试用和提出改进意见。