Linux_基础知识与常用命令
一、Linux系统的组件
Linux 操作系统的组件
- Linux 内核
- Shell
- 文件系统
- 实用程序
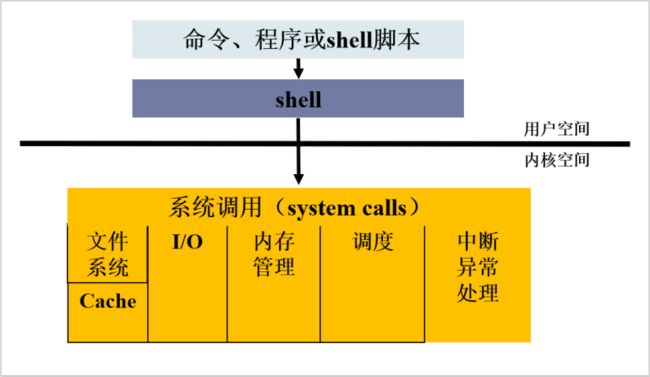
Linux 内核 : 内核(内核空间)是 Linux 系统的最底层,提供了系统的核心功能并允许进程以⼀种有序的⽅式访问硬件。用于控制进程、输⼊、输出设备、文件系统操作、管理内存。这些都不需要⽤户参与,系统⾃⾏完成。
Shell: Shell 是⼀个命令⾏解释器,它使得⽤户能够与操作系统进⾏交互。
文件系统:Linux 文件系统中的文件是数据的集合,文件系统不仅包含着文件中的数据而且还有文件系统的结构,所有Linux 用户和程序看到的文件、目录、软连接及文件保护信息等都存储在其中。
实用程序:标准的 Linux 系统都有一套实用程序,它们是专门服务于用户对系统进行操作的程序,例如编辑器(用于编辑文件)、过滤器(用于接收数据并过滤数据)、交互程序、执行标准的计算操作等。
二、Linux常用基础命令
pwd(print work directory):显示当前目录的绝对路径
cd(change directory):切换目录
常用目录:(./ 当前目录)(…/ 上层目录)(- 上一次操作所在路径)(~ 当前用户用户名路径)
ls(list show):列出当前目录下的内容
mkdir(make directory):新建文件夹
touch :创建文件
rm :删除文件
rm -rf :删除文件夹
clear :清屏
cp :复制文件
- cp hello.c world.c ,把 hello.c 复制⼀份命名为 world.c
- cp hello.c /home/linux/Cbase,把 hello.c 拷⻉到 Cbase ⽂件夹中,/home/linux/Cbase为路径
cp -a :复制文件夹
- cp old_dir new_dir -a ,把 old_dir 文件夹复制一份命名为 new_dir
- cp Cbase …/ -a ,把 Cbase ⽂件夹拷⻉到上层⽬录
mv :
- 移动文件( mv hello.c /home/linux/Cbase,把hello.c移动到Cbase⽂件夹中 )
- 把源⽂件重命名为⽬标⽂件( mv hello.c world.c,hello.c重命名为world.c )
- 把源⽂件移动到⽬标⽂件夹( mv Cbase …/ ,把Cbase⽂件夹移动到上层⽬录 )
find:搜索指定文件,格式:find 路径 -name ⽂件名
- find /home/linux -name hello.c ,在/home/linux⽬录下搜索hello.c
grep:搜索指定内容,格式:grep “字符串” ⽂件
- grep “hello” log.c ,在log.c⽂件中搜索"hello"字符串
- grep “main” * -nR ,在当前⽬录及⼦⽬录所有⽂件中搜索main
管道: 是将⼀个命令的输出当作另⼀个命令的输⼊,通过 | 连接多个命令。即: 后⼀个命令的操作,是在前⼀个命令操作结束的基础上进⾏的。
cat:显示指定文件的所有内容
cut:指定分割字符,分割指定内容, 格式:cut -d “分割字符” -f 字段
head:显示文件开头的前几行( ⼀般与管道联合使⽤ ),head -⾏数 ⽂件
tail:显示文件结尾的后几行( ⼀般与管道联合使⽤ ), tail -⾏数 ⽂件
举些例子:
- cat /etc/passwd | grep “linux”,在passwd文件中查找"linux"字符串
- ls /usr/include | grep “stdio.h”,在include文件夹中寻找"stdio.h"文件
- head -10 /etc/passwd,显示/etc/passwd⽂件开头前10⾏
- tail -1 /etc/passwd,显示/etc/passwd⽂件最后⼀⾏的信息
- tail -1 /etc/passwd | cut -d “:” -f 1,3,4 ,将passwd⽂件最后⼀⾏中信息以冒号为分隔符分割成一块一块,并显示这些“块”中的第1,3,4个。
wc : 统计某个⽂件的⾏数 / 单词个数 / 字节数
- -l 显示⼀个⽂件的⾏数
- -w 显示⼀个⽂件的单词个数
- -c 显示⼀个⽂件的字节数
三、Linux常用特殊符号
| 符号 | 含义 | 举例 |
|---|---|---|
| 星号 * | 匹配任意⻓度的字符串 | 输入:ls file_*.txt 输出:file_1.txt file_2.txt file_3.txt |
| 问号 ? | 匹配⼀个⻓度的字符串 | 输入:ls file_?.txt 输出:file_1.txt file_a.txt file.x.txt |
| 方括号 [ … ] | 匹配其中指定的⼀个字符 | 输入:ls file_[otr].txt 输出:file_o.txt file_r.txt file_t.txt |
| 方括号 [ - ] | 匹配指定的⼀个字符范围 | 输入:ls file_[a-z].txt 输出:file_a.txt file_b.txt file_z.txt |
| 方括号 [ ^… ] | 除了其中指定的字符, 其他均可匹配 | 输入:ls file_[^obt].txt 输出:除了 file_o.txt,file_b.txt,file_t.txt 外的其他文件 |
| 输出重定向 > | 把本来应该输出到屏幕上的正确的数据,修改输出到其他的地⽅ (比如⽂件)。 | echo “hello world” > log.txt 把hello world写⼊log.txt⽂件中,写⼊前会把log.txt⽂件内容清空,没有文件创建文件 echo “happy” >> log.txt 追加的⽅式写,不清空文件内容 |
| 输入重定向 < | 改变默认的输⼊源,把本来应该从键盘输⼊的信息该从其他位置获取 (比如文件)。 | cat < /etc/passwd > a.txt 通过重定向 /etc/passwd 作为输⼊设备,并输出重定向到 a.txt, 最终实现将 /etc/passwd ⽂件中内容复制到 a.txt 中 |
| 错误重定向 2> | 把本来应该输出到屏幕上错误的信息改输出到⽂件中 | bababa123 2> log.txt bababa作为一条错误的命令, 本来应该向屏幕上输出command not found ,这条命令现在会输出到log.txt⽂件中。 |
命令置换 |
将⼀个命令的输出当作另⼀个命令的参数 | command1 `command2` command2的输出当作command1的参数。 如 find `pwd` -name hello.c |
四、vim编辑器与gcc编译器
vim编辑器: 编辑代码的工具
vim + hello.c 打开 hello.c 文件,此时不能编辑代码,只能进行命令操作。
| 模式 | 使用方法 |
|---|---|
| 编辑模式 | 点击“ i ”键,终端的左下⻆会出现 insert 关键字,此时进入编辑模式 |
| 命令模式 | 代码编辑完毕后,按下 esc 键,退出编辑模式。 按下“ : ”键,在窗口底部出现冒号后便成功进入命令模式 |
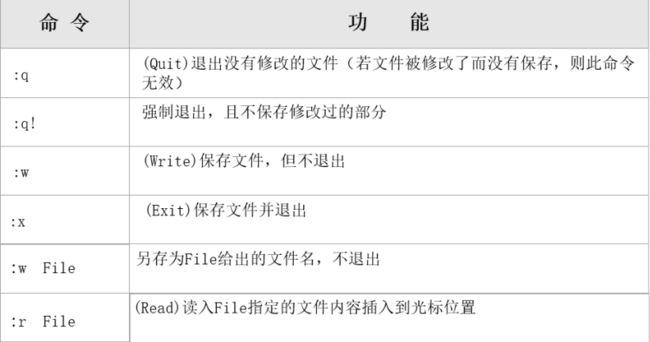
命令模式下常用命令:
gcc编译器: 编译代码的工具
gcc命令:
- gcc hello.c 编译代码, 系统默认会在当前⽬录下,⽣成⼀个叫做 a.out 的⽂件【all out】
./a.out 执⾏ a.out ⽂件,输出对应的结果。 - gcc hello.c -o exec 编译代码, ⽤户⾃定义⽣成的可执⾏⽂件名字。
./exec 执⾏./exec ⽂件,输出对应的结果。
gcc编译过程:预处理——>编译——>汇编——>链接
- 预处理 ----> ⽣成预处理过的 C 代码 xx.i
- 编译 ----> 把我们预处理过的代码⽣成我们的汇编代码 xx.s
- 汇编 ----> 把汇编代码⽣成我们的⽬标⽂件 xx.o
- 链接 ----> 把我们的⽬标⽂件⽣成我们的可执⾏⽂件
gcc命令输入时可加参数:
- -E 使编译器在预处理结束的时候停⽌
- -S 使编译器在编译结束的时候停⽌
- -c 使编译器在汇编结束的时候停⽌
- -o 输出 gcc 编译的结果
五、 sed 命令与awk命令
sed命令
简介:
- Vim 采⽤的是交互式⽂本编辑模式,可以⽤键盘命令来交互性地插⼊、删 除或替换数据中的⽂本。但 sed 命令不同,它采⽤的是流编辑模式,最明显的特点是,在 sed 处理数据之前,需要预先提供⼀组规则,sed 会按照此规则来编辑数据。
使⽤场景:
- 超⼤⽂件处理;
- 对⽂件进⾏批量增加,替换等。
- 有规律的⽂本,例如 以分号,空格等分隔的⽇志⽂件等;
sed 会根据脚本命令来处理⽂本⽂件中的数据,这些命令要么从命令⾏中输⼊,要么存储在⼀ 个⽂本⽂件中,此命令执⾏数据的顺序如下:
- 每次仅读取⼀⾏内容;
- 根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源⽂件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
- 将执⾏结果输出。
当⼀⾏数据匹配完成后,它会继续读取下⼀⾏数据,并重复这个过程,直到将⽂件中所有数据处理完毕。
语法格式:sed [options] ‘{command}[flags]’ [filename]
[options]:
- -e (脚本命令) 该选项会将其后⾯的脚本命令添加到已有的命令中。
- -f (脚本⽂件) 该选项会将其⽂件中的脚本命令添加到已有的命令中。
- -n 只显示匹配的⾏
- -i 直接对原⽂件进⾏操作,会修改原⽂件内容。sed命令默认不修改⽂件
{command}:
- i :insert,在指定匹配到的⾏前⾯添加新⾏内容为 string
- a :append,在指定或匹配到的⾏后⾯追加新⾏,内容为 string
- d :delete,删除符合地址定界条件的的⾏
- p :print,默认 sed 对模式空间内的处理完毕后,将输出的结果输出在标准输出, 添加 p 命令后,相当于既输出了原⽂,⼜⼀次输出了模式匹配处理后的内容。
- s : 查找并替换,默认只替换每⾏中第⼀次被模式匹配到的字符串 ,如果修饰符为 g, 则为全部替换。
[flags]:
- n : 1~512之间的数字 表示指定要替换的字符串出现第⼏次时才进⾏替换。
例如,⼀⾏中有 3 个 A,但⽤户只想替换第⼆个 A,这是就⽤到这个标记; - g : 对数据中所有匹配到的内容进⾏替换,如果没有 g,则只会在第⼀次匹配成功时做替换操作。
例如,⼀⾏数据中有 3 个 A,则只会替换第⼀个 A; - p : 会打印与替换命令中指定的模式匹配的⾏。此标记通常与 -n 选项⼀起使⽤。
一些例子:
显示 /etc/passwd 第三⾏的信息
- sed -n ‘3p’ /etc/passwd 这⾥的 3 代表⾏数,p 代表输出结果
在 / etc/passwd 中第⼀⾏前添加⼀⾏内容为”Good Good Study"
- sed -e ‘1iGood Good Study’ /etc/passwd 这⾥的 1 代表第⼀⾏,i 代表 insert 插⼊的意思。表示在第 1 ⾏前插⼊新的字符串。
把 / etc/passwd 中所有名字为 root 的字符串改为 class
- sed -e ‘s/root/class/g’ /etc/passwd
- sed -n ‘s/root/class/2p’ /etc/passwd
-n 选项会禁⽌ sed 输出,但 p 标记会输出修改过的⾏,将⼆者匹配使⽤的效果就是只输出被替换命令修改过的⾏。
删除 / etc/passwd 中内容并列出⾏号,并且将第 2~5 ⾏删除
- cat -n /etc/passwd | sed ‘2,5d’ ,cat -n 会显示⾏号,这⾥利⽤管道来显示内容。
把 / etc/passwd ⽂件中 root ⽤户的信息以带⾏号的形式重定向到 log.txt ⽂件中, 要求把 log.txt⽂件中 root 替换为 linux,并且 log.txt 中保存替换后的⽂件内容。
- cat /etc/passwd | grep -n “root” > log.txt
sed -i ‘s/root/linux/g’ log.txt
cat log.txt
awk命令
AWK 语⾔的基本功能是在⽂件或者字符串中基于指定规则浏览和抽取信息。awk 抽取信息后,才能对其他⽂本操作。它是⼀个强⼤的⽂本分析⼯具。简单来说 awk 就是把⽂件逐⾏的读⼊,以空格为默认分隔符将每⾏切⽚,切开的部分再进⾏各种分析处理。
sed 命令常⽤于⼀整⾏的处理。⽽ awk 更倾向于把⼀⾏分为多个 “字段” 然后进⾏处理。
适⽤场景
- 超⼤⽂件处理;
- 输出格式化的⽂本报表;
- 执⾏算数运算;
- 执⾏字符串操作等。
语法格式: awk [options] ‘pattern {action}’ filename
[options]:
- -F : 指明输⼊时⽤到的字段分隔符,默认分隔符为空格或tab键
- -v (var=VALUE) : ⾃定义变量
pattern:匹配规则,⼀般使⽤关系表达式作为条件,条件符合执⾏对应的动作。
{action}:某些计算操作/格式化数据/流控制语句
filename:⽂件名
举个例子:
新建⼀个 student.txt, 内容如下:
ID NAME PHP Linux MySQL Avereage
1 Liming 82 95 86 87.66
2 Sc 74 96 87 85.66
3 Gao 99 83 93 91.66
- 输出⽂件内容 : awk ‘{print}’ student.txt
- 输出第 2 列内容 : awk ‘{print$2}’ student.txt
NAME
Liming
Sc
Gao
- 格式输出 : awk ‘{print $2 $6}’ student.txt , 不调整格式输出,连在⼀起
NAMEAvereage
Liming87.66
Sc85.66
Gao91.66
- awk ‘{print $2"\t"$6}’ student.txt
NAME Avereage
Liming 87.66
Sc 85.66
Gao 91.66
awk输出磁盘信息: df -Th | grep tmpfs | awk ‘{print $1"\t"$5}’
udev 921M
tmpfs 186M
tmpfs 945M
tmpfs 5.0M
tmpfs 945M
tmpfs 189M
默认情况下,awk 会从输⼊中读取⼀⾏⽂本,然后针对该⾏的数据执⾏程序脚本,但有 时可能需要在处理数据前运⾏⼀些脚本命令,这就需要使⽤ BEGIN 关键字。
[linux#linux] awk 'BEGIN{print "test start!"}{print $2 "\t" $5}' student.txt
test start!
NAME MySQL
Liming 86
Sc 87
Gao 93
和 BEGIN 关键字相对应,END 关键字允许我们指定⼀些脚本命令,awk 会在读完数据后执⾏它们。
[linux#linux] awk '{print $2 "\t" $5}END{print "test END!"}' student.txt
NAME MySQL
Liming 86
Sc 87
Gao 93
test END!
六、文件信息与压缩命令
1.文件信息
在 linux 中可以这么说,所有的设备都是⽂件。
例如,⼀块硬盘是⼀个⽂件,这个硬盘上的分区也是⼀个⽂件,声卡、网卡等硬件设备在操作系统看来也是⼀个⽂件。
我们可以通过 ls -ld命令查看文件的详细信息,此处为 bin 目录下的所有文件的详细信息。
以 -rwxr-xr-x 1 root root 1113504 Apr 18 2022 /bin/bash 为例进行说明。
(1).文件类型信息:
首先第一位上的标识符表明了文件类型信息:
- b : 块设备⽂件 (block) 如硬盘
- c : 字符设备⽂件 character 如鼠标
- d : ⽬录⽂件 directroy
- - : 普通⽂件 regular
- l : 软链接⽂件(windows快捷⽅式) link
- p : 管道⽂件(常⽤于进程通信) pipe
- s : unix域socket⽂件(常⽤于进程通信)
(2).文件权限信息:
而后的九位”rwxr-xr-x“为文件权限信息,每三位分别表示了不同角色,分别为: ⽂件所有者权限、⽂件所有者所在组的组员权限、其他⼈权限。
其中: r 表示文件可读, w 表示文件可写入, x 表示文件可执⾏。
我们通常也将文件权限使用八进制数组合来进行方便记忆:
不同的权限使用八进制数表示为: r :4,w :2,x :1,在表示一个角色的权限时,使用加法来进行表示。
比如,当前文件的文件所有者权限为:rwx,使用八进制数通过加法后表示为”7“;⽂件所有者所在组的组员权限为:r-x,则表示为”5“;其他⼈权限同样表示为”5“。
如此,我们使用”755“就可以来表示这个文件的所有权限信息。
(3).其他信息
- 第三部分: 1 -> 硬链接数
- 第四部分: root -> ⽂件所有者名
- 第五部分: root -> ⽂件所属于组
- 第六部分: 1113504 ->⽂件⼤⼩ (默认单位byte)
- 第七部分: Apr 18 2022 ->⽂件最后⼀次修改时间
- 第⼋部分: /bin/bash ->⽂件名
(4).文件权限更改
格式: chmod + 权限 + ⽂件名
比如:
- 改变 main.c 文件权限为所有用户可读可写可执行:chmod 777 main.c
- 仅为文件所有者可读不可写,其他人均不可读写与执行:chmod 400 main.c
- 所有人对此文件无任何权限:chmod 000 main.c
2.压缩命令
linux ⽀持常⽤的两种压缩格式
- gzip : linux ⽀持的压缩格式的⼀种,优点是压缩速度较快
- bzip2 :linux ⽀持的压缩格式的⼀种,优点是压缩后存储空间占⽤较⼩。
使用 zip 命令进行文件压缩,unzip命令进行文件解压缩。
- zip test.zip hello.c log.c
- unzip test.zip
使用 tar 命令进行文件压缩及相关操作:
- c -> 创建
- x -> 释放
- z -> gzip 操作
- j -> bzip2 操作
- v -> 显示过程
- f -> 指定⽂件名(⼀定需要放在最后)
举例:
- sudo tar -czvf work.tar.gz work :将 work 文件通过 gzip 操作进行压缩,并指定压缩包名称为 work.tar.gz,要求显示压缩过程。
- sudo tar -cjvf work.tar.bz2 work :与上例不同的是使用 bzip2 操作进行压缩。
- sudo tar -xzvf work.tar.gz 解压
- sudo tar -xjvf work.tar.bz2 解压
- sudo tar -xvf work.tar.gz/work.tar.bz2(两种压缩包都可以释放)
- sudo tar -xvf work.tar.gz -C 指定的⽬录 , 解压到指定位置。