通过python获取A网站的所有图片并保存到对应文件夹
目录
一.需要用到的库、
二.思路(图解)、
三.具体实现过程
四.案例代码以及结果、
一.需要用到的库、
需要用到的库(如果没有需要用pip工具进行下载对应的库)
1.OS(与操作系统交互的一个接口,它提供了许多函数操作文件和目录。)
用到的方法
os.mkdir(path): 创建一个新目录(文件夹)。
os.path.join() 路径的拼接
2.requests(Python语言中一个HTTP客户端库,可以用于发送HTTP/1.1请求。)
用到的方法
requests.get(url, params=None, **kwargs):发送GET请求。
3.from bs4 import BeautifulSoup(是一个Python库,用于在HTML和XML文档中解析数据)
用到的方法
soup = BeautifulSoup(html_doc,'html.parser')
find_all():返回所有匹配的元素
二.思路(图解)、
由于网页的图片是单独存在一个链接里,所以想要得到图片那么需要取得所有图片的链接地址,再一个个的到图片的链接进行下载。

很明显看到网页中图片就在旁边的src中

1).那么首先可以通过requests对整体网页进行请求,再通过beautifulsoup进行解析得到网页整体代码
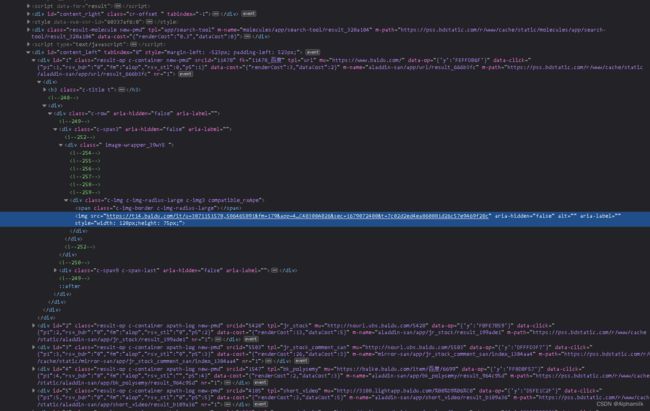
2). 接下来,通过beautifulsoup中的find_all("img")的方法得到所有img标签内容
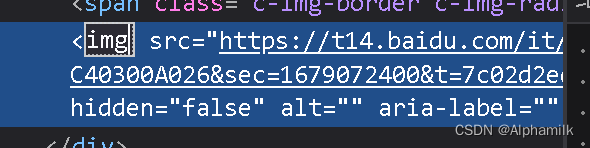
3). 再通过beautifulsoup中get("src")的方法得到src中链接
https://t14.baidu.com/it/u=3871151578,586465891&fm=179&app=42&size=w621&n=0&f=PNG?s=56F72C72CCB47E904B7DA3C40300A026&sec=1679072400&t=7c02d2ed4ea860881d26c57e9469f20c https://t14.baidu.com/it/u=3871151578,586465891&fm=179&app=42&size=w621&n=0&f=PNG?s=56F72C72CCB47E904B7DA3C40300A026&sec=1679072400&t=7c02d2ed4ea860881d26c57e9469f20c链接内部就是图片了
https://t14.baidu.com/it/u=3871151578,586465891&fm=179&app=42&size=w621&n=0&f=PNG?s=56F72C72CCB47E904B7DA3C40300A026&sec=1679072400&t=7c02d2ed4ea860881d26c57e9469f20c链接内部就是图片了
4).下一步就是重新通过requests的get进行访问,得到图片地址链接的内容即图片
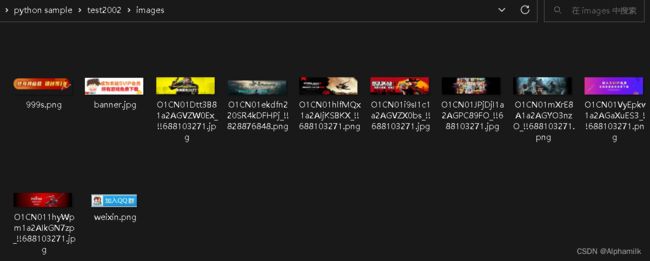
最后就是打开文件夹,然后给每张图片给上图片名字并保存到文件之中
三.具体实现过程
1).插入库(调用库中的方法)
import os
import requests
from bs4 import BeautifulSoup2).
#选择爬取的网站
url="https://sc.chinaz.com/tupian/"
#设置文件夹名称并判断是否存在该文件夹,若没有则重新创建一个
save_folder = "./images"
if not os.path.exists(save_folder):
os.makedirs("./images")3).
#发出对网站的请求,并解析返回网页代码
response = requests.post(url)
soup = BeautifulSoup(response.content,'html.parser')4).
#读取所有img的标签并通过beautifulsoup的get方法得到src即图片存放的链接
images = soup.find_all("img")
for image in images:
img_url = image.get("src")5).注意这里判断要判断img_url是否以http开头,因为有时候数据不以http开头,则后面函数requests.get传参会报错
#判断url是否存在,再requests.get请求图片地址
#通过os.path.join拼接文件名
#打开文件,将请求到的内容写入文件
if img_url and img_url.startswith('http'):
img_response = requests.get(img_url)
filename = os.path.join(save_folder,os.path.basename(img_url))
with open(filename,"wb") as f:
f.write(img_response.content)
四.案例代码以及结果、
import os
import requests
from bs4 import BeautifulSoup
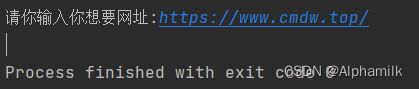
url = input('请你输入你想要网址:')
save_folder = "./images"
if not os.path.exists(save_folder):
os.makedirs("./images")
response = requests.get(url)
soup = BeautifulSoup(response.content,'html.parser')
images = soup.find_all("img")
for image in images:
img_url = image.get("src")
if img_url and img_url.startswith('http'):
img_response = requests.get(img_url)
filename = os.path.join(save_folder,os.path.basename(img_url))
with open(filename,"wb") as f:
f.write(img_response.content)
结果展示:(可以直接复制代码,然后复制链接即可用)