Elasticsearch入门简单版
文章目录
- Elasticsearch 入门与深入
-
- 一、Elasticsearch介绍
-
- 1、主要功能
- 2、版本与升级
-
- 新特性 5.x
- 新特性 6.x
- 新特性 7.x
- 二、ELK 家族成员介绍
-
-
- Logstash
- Kibana
- Elastic
- Beats
- X-Pack
-
- 三、Elasticsearch安装和配置
-
-
- 1、目录结构
- 2、jdk配置建议
- 3、插件安装
- 4、多节点启动
-
- 四、Kibana安装
- 五、Cerebro安装
- 六、Logstash安装
- Elasticsearch基本概念
-
- 一、名词介绍
-
- 1、文档
- 2、JSON 文档
- 3、文档的元数据
- 4、索引
- 5、关系型数据库和ES对应
- 6、简单API操作
- 二、节点、集群、分片及副本
-
- 1、节点
-
-
- a、Master-eligible nodes 和 Master Node
- b、Data node & Coordinating Node
- c、其他的节点类型
- d、配置节点类型
-
- 2、分片/副本
- 3、集群信息查看
- 三、文档CRUD
-
- 1、普通CRUD操作
- 2、批量操作_bulk
- 3、批量读取_mget
- 4、批量查询_mserch
- 5、常见错误返回结果
- 四、倒排索引
- 五、Analysis
-
- 1、Analysis组成
- 2、Elasticsearch的分词器
- 3、测试分词器
- 六、Search API
-
- 1、初体验
- 2、URL Search
-
- a、Query String Syntax
-
- 指定字段 v.s 范查询
- Term v.s Phrase(布尔条件)
- 分组与引号
- 布尔操作(尽量用括号括起来哈)
- 范围查询
- 算数符号
- 通配符查询
- 正则表达
- 模糊匹配与近似查询
- 2、Request Body Search
-
- a、分页-from/size
- b、排序-sort
- c、字段过滤-_source
- d、脚本字段-script_fields
- e、使用查询表达式 query的match
- f、短语搜索 query的match_phrase
- 3、Query String Query
-
- a、query_string
- b、simple_query_string
- 七、Mapping和常见字段
-
- 1、字段的数据类型
-
- a、简单类型
- b、复杂类型-对象和嵌套对象
- c、特殊类型
- 2、Dynamic Mapping
-
- a、类型自动识别
- b、Mapping的dynamic设定
- 3、Mapping设置及常见参数
-
- a、自定义Mapping的建议
- b、设置某字段是否可被索引
- c、设置倒排索引记录的内容
-
- 四种级别
- d、对null值实现搜索
-
- 添加数据时,传入null
- 查询数据时,查询NULL
- e、copy_to设置
-
- 测试 新建索引 时指定copy_to字段
- 添加数据,注意默认的词法分析,中文是一个字一个哦。。
- 4、多字段类型
- 5、精确值和全文本
- 八、自定义分词
-
- 1、Character Filters
-
-
- html_strip 去除 html 标签
- mapping 字符串替换
- pattern replace 正则匹配替换
-
- 2、Tokenizer
-
-
- elasticsearch 内置的 Tokenizer
-
- path_hierarchy 测试用例 - 按照url拆分
- whitespace测试用例 - 空格拆分
- 可以用Java开发插件,实现自己的 Tokenizer
-
- 3、Token Filters
-
-
- 自带的 Token Filters
-
- stop和lowercase 测试用例 - 空格拆分 且 去掉停用词
-
- 4、设置一个Custom Analizer
-
- a、创建自定义Analizer
- b、测试自定义分词器
- 九、自定义索引模板
-
- 1、index template
- 2、索引模板案例
-
-
- 创建任何索引的时候,会设定分片为1,副本为1
- 创建以test开头的索引,会设定分片为1,副本为2
- 同时会把日期格式的探测关闭,数字的探测打开(数字探测默认是关闭)
-
- 3、索引模板的工作方式
- 4、动态字段模板
-
-
- 定义在某个索引的mappings中
- 测试1,string转为boolean,根据名字前缀的正则
- 测试2 自动把正则组成成一个copy_to
-
- 十、聚合
-
- 1、聚合的分类
-
-
- **测试,查询航班目的地的统计信息,结果不在hits里,而在同级的aggregations中**
- **大多数 metric 是数学计算,仅输出一个值**
- **部分 metric 支持输出多个数值**
- **测试1,查看航班目的地的统计信息,增加均价,最高最低价格**
- 测试2,查看航班目的地的统计信息,平均票价,以及天气状况
-
- Elasticsearch深入搜索
- Elasticsearch分布式特性及分布式搜索机制
- Elasticsearch深入聚合分析
Elasticsearch 入门与深入
2004年 Shay Banon 基于Lucene开发了 Compass
2010年 Shay Banon 重写了 Compass,取名 Elasticsearch
查询性能好(Near Real Time)
支持分布式,可水平扩展
支持多语言的集成:降低全文检索的学习曲线,可以被任何编程语言调用
一、Elasticsearch介绍
1、主要功能
-
海量数据的用户式存储以及集群管理
- 服务与数据的高可用,水平扩展
-
近实时搜索,性能卓越
- 结构化 / 全文 / 地理位置 / 自动完成
-
海量数据的近实时分析
- 聚合功能
2、版本与升级
0.4:2010年2月第一次发布
1.0:2014年1月
2.0:2015年10月
5.0:2016年10月
6.0:2017年10月
7.0:2019年10月
新特性 5.x
- Lucene 6.x,性能提升,默认打分机制从TF-IDF 改为 BM 25
- 支持Ingest 节点 / Painless Scripting / Completion suggested 支持 / 原生的 Java REST 客户端
- Type 标记成 deprecated,支持了 Keyword 的类型
- 性能优化
- 内部引擎移除了避免同一文档并发更新的竞争锁,带来 15% — 20% 的性能提升
- Instant aggregation ,支持分片上聚合的缓存
- 新增了 Profile API
新特性 6.x
- Lucene 7.x
- 新功能
- 跨集群复制(CCR)
- 索引生命周期管理
- SQL 的支持
- 更友好的升级及数据迁移
- 在主要版本之间的迁移更为简化,体验升级
- 全新的基于操作的数据复制框架,可加快恢复数据
- 性能优化
- 有效存储稀疏字段的新方法,将该地了存储成本(浓稠索引就是1对1,稀疏索引就是一对区间头)
- 在索引时进行排序,可加快排序的查询性能
新特性 7.x
- Lucene 8.0
- 重大改进 - 正式废除当额索引下多 Type 的支持
- 7.1 开始。Security 功能免费使用
- ECK - Elasticsearch Operator on Kubernetes
- 新功能
- New Cluster coordination
- Feature - Complete High level REST client
- Script Score Query
- 性能优化
- 默认的 Primary Shard 数从 5 改为 1,避免 Over sharding
- 性能优化,更快的 Top K
二、ELK 家族成员介绍
搜索类:继承数据库同步数据 / 独立作为数据存储使用(不推荐)
日志型:Logstash 和 Beats 满足不同的数据源,Kafka作为消息队列
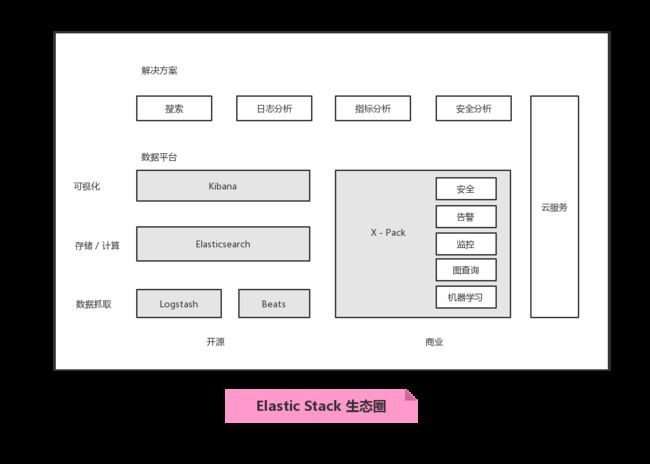
Logstash
数据处理通道
https://www.elastic.co/cn/logstash
- 开源的服务端数据处理管道,支持从不同来源采集数据,转换数据,并将数据发送到不同的存储库中、
- Logstash 诞生于 2009 年,最初涌过来做日志的采集与处理
- Logstash 创始人 Jordan Sisel
- 2013 年被 Elasticsearch 收购
特性:
- 实时解析和转换数据
- 从 IP 地址破译出地理坐标
- 将PII 数据匿名化,完全排除敏感字段
- 可扩展
- 200 多个插件 (日志 / 数据库 / Arcsigh / Netflow
- 可靠性安全性
- Logstash 会通过持久化队列来保证至少将运行中的事件送达一次
- 数据传输加密
- 监控
Kibana
可视化分析利器,web
https://www.elastic.co/cn/kibana
- Kibana 名字的含义 = Kiwifruit + Banana
- 数据可视化工具,帮助用户解开对数据的任何疑问
- 基于 Logstash 的工具,2013年加入 Elastic 公司
Elastic
- 2015 年 3 月收购 Elastic Cloud ,提供 Cloud 服务
- 2015 年 3 月收购 PacketBeat
- 2016 年 9月收购 PreAlert - Machine Learning 异常检测
- 2017 年 6 月收购 Opbeat 进军 APM
- 2017 年 11 月收购 SaaS 厂商 Swiftype,提供网站和 App 搜索
- 2018 年 X-Pack 开源
Beats
清理的数据采集器
https://www.elastic.co/cn/beats
X-Pack
商业化套件
- 6.3 之前的版本,X-Pack 以插件方式安装
- X-Pack 开源之后,Elasticsearch & Kibana 支持 OSS版 和 Basic 两种版本
- 部分 X-Pack 功能支持免费使用,6.8 和 7.1 开始,Security 功能免费
- OSS,Basic,黄金级,白金级
- https://www.elastic.co/cn/subscriptions
三、Elasticsearch安装和配置
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
jdk11下载:https://download.java.net/java/GA/jdk11/13/GPL/openjdk-11.0.1_linux-x64_bin.tar.gz
can not run elasticsearch as root
# 创建用户 adduser elasticsearch01 # 创建密码 passwd elasticsearch01 # 给文件赋予权限 chown -R elasticsearch01 elasticsearch-6.0.0 # 切换用户 su elasticsearch01 # 后台启动 ./elasticsearch -d其他异常处理:https://blog.csdn.net/happyzxs/article/details/89156068
集群搭建:https://www.cnblogs.com/sanduzxcvbnm/p/12016216.html
- 注意配置的的data和log 会有权限问题,需要自己处理一下
1、目录结构
| 目录 | 配置文件 | 描述 |
|---|---|---|
| bin | 脚本文件,包括启动elasticsearch,安装插件。运行统计数据等 | |
| config | elasticsearch.yml | 集群配置文件,user,role based 相关配置 |
| JDK | Java 运行环境 | |
| data | path.data | 数据文件 |
| lib | Java类库 | |
| logs | path.log | 日志文件 |
| modules | 包含所有 ES 模块 | |
| plugins | 包含所有已安装插件 |
2、jdk配置建议
- Xmx 和 Xms 设置成一样
- Xmx 不要超过机器内存的50%
- 不要超过 30 GB – http://www.elastic.co/blog/a-heap-of-trouble
3、插件安装
- 查看1:
elasticsearch-plugin list - 查看2:http://localhost:9200/_cat/plugins
- 安装插件:
./elasticsearch-plugin install analysis-icu
4、多节点启动
-
多节点启动
./elasticsearch -E node.name=node1 -E cluster.name=elktest -E path.data=/tmp/es/node1_data -E http.port=9200 -d ./elasticsearch -E node.name=node2 -E cluster.name=elktest -E path.data=/tmp/es/node2_data -E http.port=9201 -d ./elasticsearch -E node.name=node3 -E cluster.name=elktest -E path.data=/tmp/es/node3_data -E http.port=9202 -d -
查看节点:http://localhost:9200/_cat/nodes
四、Kibana安装
下载地址:https://www.elastic.co/cn/downloads/kibana
其他操作类似elastic,例如插件安装等等
- 汉化加入配置:
i18n.locale: "zh-CN" - 后台启动:
nohup ./kibana & - 访问地址:http://localhost:5601
- 注意,如果是集群,需要指定集群配置,
elasticsearch.hosts
五、Cerebro安装
elastic集群监控
软件地址:https://github.com/lmenezes/cerebro/releases
相关安装和操作教程:https://www.jianshu.com/p/433d821f9667
六、Logstash安装
JRuby开发的(一个采用纯Java实现的Ruby解释器,由JRuby团队开发)
下载地址:https://www.elastic.co/cn/downloads/logstash
-
movielens测试数据集
例:Small: 100,000 ratings and 3,600 tag applications applied to 9,000 movies by 600 users. Last updated 9/2018. #修改movielens目录下的logstash.conf文件 #path修改为,你实际的movies.csv路径 input { file { path => "YOUR_FULL_PATH_OF_movies.csv" start_position => "beginning" sincedb_path => "/dev/null" } } #启动Elasticsearch实例,然后启动 logstash,并制定配置文件导入数据 bin/logstash -f /YOUR_PATH_of_logstash.conf -
logstash.conf文件内容
input { file { path => "/usr/local/soft/logstash-7.3.2/bin/movies.csv" start_position => "beginning" sincedb_path => "/dev/null" } } filter { csv { separator => "," columns => ["id","content","genre"] } mutate { split => { "genre" => "|" } remove_field => ["path", "host","@timestamp","message"] } mutate { split => ["content", "("] add_field => { "title" => "%{[content][0]}"} add_field => { "year" => "%{[content][1]}"} } mutate { convert => { "year" => "integer" } strip => ["title"] remove_field => ["path", "host","@timestamp","message","content"] } } output { elasticsearch { hosts => ["http://192.168.165.14:9200", "http://192.168.165.15:9200", "http://192.168.165.16:9200"] index => "movies" document_id => "%{id}" } stdout {} } -
指定elasticsearch地址和端口
-
启动:./logstash -f logstash.conf
Elasticsearch基本概念
一、名词介绍
1、文档
Document
- Elasticsearch是面向文档的额,文档是所有可搜索数据的最小单位
- 日志文件的日志项
- 一本电影的基本信息 / 一张唱片的详细信息
- MP3播放器里的一首歌 / 一篇 PDF 文档的具体内容
- 文档会被序列化成 JSON 格式,保存再 Elasticsearch中
- JSON 对象由字段组成
- 每个字段都有对应的字段类型(字符串 / 数值 / 布尔 / 日期 / 二进制 / 范围类型)
- 每个文档都有一个 Unique ID
- 你可以自己指定ID
- 或者通过 Elasticsearch 自动生成
2、JSON 文档
- 一篇文档包含了一系列的字段。类似数据库表中以条记录
- JSON 文档,格式灵活,不需要预先定义格式
- 字段的类型可以指定或者通过 Elasticsearch 自动推算
- 支持数组 / 嵌套
- CSV file 转换为 JSON(使用logstash)
3、文档的元数据
元数据,用于标注文档的相关信息
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 19,
"_primary_term" : 1,
"found" : true,
"_source" : {
"year" : 1995,
"title" : "Toy Story",
"id" : "1",
"genre" : [
"Adventure",
"Animation",
"Children",
"Comedy",
"Fantasy"
],
"@version" : "1"
}
}
| key | 描述 |
|---|---|
| _index | 文档所属的索引名 |
| _type | 文档所属的类型名 |
| _id | 文档唯一id |
| _source | 文档的原始json数据 |
| _version | 文档的版本信息 |
| _score | 相关性打分 |
4、索引
{
"movies" : {
"aliases" : { },
"mappings" : {
"properties" : {
"@version" : {...},
"genre" : {...},
"id" : {...},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"year" : {...}
}
},
"settings" : {
"index" : {
"creation_date" : "1588399246401",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "ZC8ASqi2Rr-MBgjXRXTIxw",
"version" : {
"created" : "7030299"
},
"provided_name" : "movies"
}
}
}
}
- index:索引是文档的容器,是一类文档的结合
- index 体现了逻辑空间的概念:每个索引都有自己的 Mapping 定义,用于定义包含的文档的字段名和字段类型
- Shard 体现了物理空间的概念:索引中的数据分散再 Shard 上
- 索引的 Mapping 与 Settings
- Mapping 定义文档字段的类型
- Setting 定义不同的数据分布
5、关系型数据库和ES对应
| RDBMS | Elasticsearch |
|---|---|
| Table表 | index(type)7.0开始,一个索引只能创建一个Type=_doc |
| Row行数据 | Doucment(具体的数据) |
| Column字段 | Field字段 |
| Schema(表定义,Schema是数据库,瞎说) | Mapping 索引信息 |
| SQL | DSL |
6、简单API操作
# 查看索引相关信息(setting\mapping)
GET movies
GET .kibana_task_manager
# 查看索引的文档总数
GET movies/_count
# 查看前10条文档,了解文档格式
POST kibana_sample_data_ecommerce/_search
{}
POST movies/_search
{}
// _cat 相关api
# 查看 indeces
GET /_cat/indices/kibana*?v
GET /_cat/indices/kibana*?v&s=index
GET /_cat/indices?bytes=b&v
GET /_cat/indices?format=json&pretty
# 查看状态为绿的索引
GET /_cat/indices?v&health=green
# 按照文档的某个字段排序
GET /_cat/indices?v&s=docs.count:desc
GET /_cat/indices?v&s=store.size:asc
# 查看具体的字段
GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs,count,mt
二、节点、集群、分片及副本
一个节点代表一个实例,多个节点组成一个集群
1、节点
- 每个节点都有自己的名字,通过配置文件配置,或者启动过的时候
-E node.name=node1指定 - 每个节点再启动之后,会分配一个UID,保存在data目录下
a、Master-eligible nodes 和 Master Node
- 每个节点启动后,默认就是一个Master Node节点
- 可以设置 node. master:false 禁止
- Master-eligible 节点可以参加选主流程,成为Master 节点
- 当第一个节点启动的时候,它会将自己选举成Mater节点
- 每个节点都保存了集群的状态,只有Master 节点才能修改集群的状态信息
- 集群状态(Cluster State),维护了一个集群中,必要的信息
- 所有的节点信息
- 所有的索引和相关的Mapping 与 Setting 信息
- 分片的路由信息
- 除了master 节点,其他节点不可以修改集群状态信息
- 集群状态(Cluster State),维护了一个集群中,必要的信息
b、Data node & Coordinating Node
-
Data Node
- 可以保存数据的节点,叫做Data Node,负责保存分片数据。在数据扩展上起到了至关重要的作用。
-
Coordinating Node
- 负责接受Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordinating Node 的职责
c、其他的节点类型
- Hot & Warm Node
- 不同硬件配置的 Data Node,用来实现 Hot & Warm 架构,降低集群部署的成本
- Machine Learning Node
- 负责跑 机器学习的 Job,用来做异常检测
- Tribe Node
- Tribe Node 连接到不同的Elasticsearch 集群,并且支持将这些集群当作一个单独的集群处理
- 5.3开始使用 Cross Cluster Serarch
d、配置节点类型
开发环境一个节点承担多种校角色,生产环境中,应该设置单一的角色的节点。(瞎说,看实际情况)
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | node.master | ture |
| data | node.data | ture |
| ingest | node.ingest | ture |
| coordinating only | 无 | 每个节点默认都是 coordinating 节点。设置其他类型全部为false |
| machine learning | node.ml | true (需 enable x-parck) |
2、分片/副本
Primary Shard & Replica Shard
-
主分片
用以解决数据水平扩展的问题。通过分片,可以将数据分布到集群内的所有节点上
- 一个分片是一个运行的 Lucene 的实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
-
副本
用以解决数据高可用的问题。分片是主分片的拷贝
- 副本分片数,可以动态的调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
-
对于生产环境中分片的设定,需要提前做好容量规划
- 分片数设置过小
- 导致后续无法增加节点实现水品扩展
- 单个分片的数据量过大,导致数据重新分配耗时
- 分片数设置过大(默认主分片设置成1,解决了over-sharding的问题)
- 影响搜索结果的相关性打分,影响系统结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
- 分片数设置过小
3、集群信息查看
-
GET _cluster/health
- Green:主分片与副本都正常分配
- Yellow:主分片全部正常分配,有副本分片未能正常分配
- Red:有主分片未能分配
- 例如,当服务器的磁盘容量超过 85% 时,去创建了一个新的索引。
-
GET _cat/nodes
三、文档CRUD
1、普通CRUD操作
| index | PUT users/_doc/1 {“user”:“Mike”,“post_data”:“2020-05-03T14:29:12”,“message”:“trying out Kibana”} |
指定id,如果id已经存在,删除原来的 再创建新的,版本信息+1 |
| create | POST users/_doc {“user”:“Jack”,“post_data”:“2020-05-03T14:29:12”,“message”:“trying out Kibana”} PUT users/_doc/1?op_type=create {“user”:“Jack”,“post_data”:“2020-05-03T14:32:12”,“message”:“trying out Kibana”} |
自动生成_id 如果_id已经存在,会失败 |
| get | GET users/_search GET users/_doc/1 |
查看索引前十条记录 根据id查询文档 |
| update | POST users/_update/1/ {“doc”:{“post_data”:“2020-05-03T14:44:12”,“message”:“trying out Elasticsearch”,“test”:652}} |
文档增加/修改字段 doc 是关键语法,payload需要包含再doc中 指定id不存在报错 |
| delete | DELETE users/_doc/1 | 删除指定_id |
2、批量操作_bulk
- 支持再一次API调用中,对不同的索引进行操作
- 支持四种类型操作
- index
- create
- update
- delete
- 可以再URL中指定 index,也可以再请求的 Payload 中进行
- 操作中单条失败,并不会影响其它结果
- 返回结果包括了每一条操作执行的结果
例:
POST _bulk {"index":{"_index":"users","_id":"1"}} {"user":"qilou","test":520} {"delete":{"_index":"users2","_id":3}} {"create":{"_index":"users2","_id":4}} {"field1":"qilou","field2":"520"} {"update":{"_id":"4","_index":"users"}} {"doc":{"field1":"qilou","field2":"520"}} # 上面有index delete create update
3、批量读取_mget
批量操作,可以减少网络连接所产生的开源,提高性能
GET _mget {"docs":[{"_index":"users","_id":11},{"_index":"movies","_id":4}]}
4、批量查询_mserch
- 都是关键字,例如 from 代表开始索引,size 代表从from开始查询多少条
- index 是查询条件,作用于下一条query查询语句的
POST kibana_sample_data_ecommerce/_msearch {} {"query":{"match_all":{}},"from":0,"size":10} {} {"query":{"match_all":{}},"size":10} {"index":"twitter2"} {"query":{"match_all":{}}}
5、常见错误返回结果
| 问题 | 原因 |
|---|---|
| 无法连接 | 网络故障或集群挂了 |
| 连接无法关闭 | 网络故障或节点出错 |
| 429 | 集群过于繁忙 |
| 4XX | 请求体格式有错 |
| 500 | 集群内部错误 |
四、倒排索引
。。。
五、Analysis
文本分析是把全文本转换一系列单词(term / token)的过程,也叫分词
Analysis 是通过Analyzer 来实现的
数据写入和查询时采用的分析器需要相同
1、Analysis组成
- Character Filters(针对原始文本处理,例如去除html)
- Tokenizer(按照规则切分为单词)
- Token Filter(将切分的单词进行加工,小写,删除stopwords,增加同义词)
2、Elasticsearch的分词器
===========================================================
elasticsearch内置的分词器
===========================================================
-
standard Analyzer 默认分词器,按词切分,小写处理
-
simple Analyzer 按照非字母切分(符号被过滤,非字符的都被去除),小写处理
-
stop Analyzer 按照非字母切分(符号被过滤,非字符的都被去除),小写处理,停用词过滤(the,a,is)
-
whitespace Analyzer 按照空格切分,不转小写
-
keyword Analyzer 不分词,直接将输入做输出
-
pattern Analyzer 正则表达式,默认 \W+ (非字符分隔)
-
language 提供了30 多种常见语言的分词器
- arabic、armenian、basque、bengali、brazilian、bulgarian、catalan、cjk、czech、danish、dutch、english、finnish、french、galician、german、greek、hindi、hungarian、indonesian、irish、italian、latvian、lithuanian、norwegian、persian、portuguese、romanian、russian、sorani、spanish、swedish、turkish、thai。
-
customer Analyzer 自定义分词器
===========================================================
===========================================================
相关的中文分词器
===========================================================
-
icu_analyzer 中文分词器
- 需要安装plugin:elasticsearch-plugin install analysis-icu
- 提供了 Unicode 的支持,更好的支持亚洲语言
-
IK 中文分词器
- 支持自定义词库,支持热更新分词字典
- https://github.com/medcl/elasticsearch-analysis-ik
-
THULAC 中文分词器
- THU Lexucal Analyzer for chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
- https://github.com/microbun/elasticsearch-thulac-plugin
3、测试分词器
# 使用分词器测试
GET /_analyze
{
"analyzer": "stop",
"text": "Mastering Elasticsearch,elasticsearch in Action"
}
六、Search API
URI Search
- 在URL 中使用查询参数
Request Body Search
- 使用Elasticsearch 提供的,基于 JSON 格式的更加完备的 Query Domain Specific Language (DSL)
-
查询指定的索引
语法 范围 /_search 在集群上的所有索引查询,默认前10个文档 /index1/_search 同上,只是在指定的索引index1中查询 /index1,index2/_search 同上,只是在指定的索引index1和index2中查询 /index*/_search 同上,只是在以index开头的索引中查询,通配符
1、初体验
-
URL查询
-
使用 “q” ,指定查询字符串
-
query string syntax,KV键值对
curl -XGET "http://192.168.165.14:9200/kibana_sample_data_ecommerce/_search?q=customer_first_name:Eddie"
-
-
-
Request Body
-
支持POST和GET
curl -XGET "http://192.168.165.14:9200/kibana_sample_data_ecommerce/_search" -H'Content-Type:application/json' -d'{"query":{"match_all":{}}}'
-
2、URL Search
GET /movies/_search?q=2012&df=title,year&sort=year:desc&from=0&size=10&timeout=1s { "profile": true }
- q 指定查询语句,使用 Query String Syntax
- 也可以直接q=title:2012 直接用k:v查询,要在多个字段查询,可以直接用df
- df 默认字段,不指定是所有字段中查询
- sort 排序 / from 和size 用于分页
- profile 可以查看查询时如何被执行的
a、Query String Syntax
-
指定字段 v.s 范查询
- q=title:2012
-
Term v.s Phrase(布尔条件)
- q=title:Hello World 等效于 Hello OR World。
- q=title:“Hello World” 等效于 Hello AND World。Phrase 查询,还要求前后顺序保持一致
-
分组与引号
- q=title:(beautiful AND mind)
- q=title:“beautiful mind”
-
布尔操作(尽量用括号括起来哈)
- AND / OR / NOT 或者 && / || / !
- 必须大写
- q=title:(beautiful NOT nihao)
- 分组
- + 表示 必须
- - 表示必须没有
- q=titile:(+beautiful -mind)
- 注意:自己测试
- AND / OR / NOT 或者 && / || / !
-
范围查询
-
区间表示:[] 闭区间,{}开区间,{}一定要用分组() 不然报错。
[] 闭区间,包含它
{}开区间,不包含
- q=year:({2016 TO 2018}) 等同q=year:2017
- q=year:[* TO 2010] 等同于<=2010
-
-
算数符号
- q=year:>2010
- q=year:(>2010 AND<=2018) 。本人测试,这个用&& 会报语法错误
- q=year:(+>2010 +<=2018) 这种写法没问题,但是,我就想问没逻辑的?year字段里面同时有2010和2018。脑子瓦特了。真的忍无可忍。讲的不清不楚,完全自己测试。浪费学习时间。花钱算是白花了
-
通配符查询
- ? 代表1个字符,* 代表0或多个字符
- q=title:mi?d
- q=title:be*
-
正则表达
- title:[bt]oy
-
模糊匹配与近似查询
- q=title:beautifl~1
- 上面的意思就是和beautifl词差别在1个(含)之内
- q=title:“lord rings”~2
- 上面就是两个词之间最多2个(含)以下组合的都符合条件
- “Lord of the Rings, The”,这个就服务,中间时2个词,没超过
- 上面就是两个词之间最多2个(含)以下组合的都符合条件
- q=title:beautifl~1
2、Request Body Search
将查询语句通过 HTTP Request Body 发送给 Elasticsearch
Query DSL
POST /movies,404_idx/_search?ignore_unavailable=true { "profile": true, "query": { "match_all": {} } }
a、分页-from/size
- 从from开始,返回20个数据,默认10个结果。获取越靠后的翻页成本较高
POST /movies/_search
{
"from": 100,
"size": 20,
"query": {
"match_all": {}
}
}
b、排序-sort
最好在数字型和日期型字段上排序
POST /movies/_search
{
"sort": [{"year": {"order": "desc"}}],
"from": 100,
"size": 20,
"query": {
"match_all": {}
}
}
##################或者,这种更精简,推荐用下面这种#######
POST /movies/_search
{
"sort": [{"year":"desc"},{"_id":"desc"}],
"from": 100,
"size": 20,
"query": {
"match_all": {}
}
}
c、字段过滤-_source
- 只显示
year和_i开头字段的数据,支持通配符
POST /movies/_search
{
"_source": ["year","title"],
"sort": [{"year":"desc"},{"_i*":"desc"}],
"from": 100,
"size": 20,
"query": {
"match_all": {}
}
}
d、脚本字段-script_fields
- 对字段order_date的值与’hello’进行拼接,然后返回新的字段名为“new_field”,在元信息的
fields里面 - fields元信息和_source元信息同级。(实在不明白请看下面的相应信息,明白的可以跳过)
{
"script_fields": {
"new_field": {
"script": {
"lang": "painless",
"source": "doc['order_date'].value+'hello'"
}
}
},
"_source": [
"order_date",
"order_id"
],
"from": 10,
"size": 1,
"query": {
"match_all": {}
}
}
- 返回结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4675,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "kibana_sample_data_ecommerce",
"_type" : "_doc",
"_id" : "INnh2HEBko7oswXuqL26",
"_score" : 1.0,
"_source" : {
"order_date" : "2020-05-11T10:46:34+00:00",
"order_id" : 727381
},
"fields" : {
"new_field" : [
"2020-05-11T10:46:34.000Zhello"
]
}
}
]
}
}
e、使用查询表达式 query的match
- 查询title中有 hello 或者 word单词的
POST /movies/_search
{
"query": {
"match": {
"title": "hello word"
}
}
}
- 查询title 有hello 和world 的结果
POST /movies/_search
{
"query": {
"match": {
"title": {
"query": "hello world",
"operator": "and"
}
}
}
}
f、短语搜索 query的match_phrase
- 查询title字段中有one love的结果,位置必须是这样不能是 one I love
POST /movies/_search
{
"query": {
"match_phrase": {
"title": {
"query": "one love"
}
}
}
}
- 查询title字段中有one love的结果,slop代表他们中间可以有几个词,此时 one I love 就符合结果了
POST /movies/_search
{
"query": {
"match_phrase": {
"title": {
"query": "one love",
"slop": 1
}
}
}
}
3、Query String Query
主要是
query里面支持的查询方式之前已经讲了
match和match_phrase以及match_all
a、query_string
- 在单个字段下查询
POST movies/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "hello NOT word"
}
}
}
- 在多个字段下,查询
POST movies/_search
{
"query": {
"query_string": {
"fields": ["title","genre"],
"query": "(hello AND word) OR (beautiful && +Girls)"
}
}
}
b、simple_query_string
类似query_string,但是会忽略语法错误,只支持部分查询语句
- 不支持AND OR NOT,会当作字符串处理
- 不支持&&等,会当作特殊符号给排除了
- 单词之间默认关系是OR,指定default_operator
- 支持用 ±| 代替 AND OR NOT
- 查询单词hello并且不包含word的标题
POST movies/_search
{
"query": {
"simple_query_string": {
"query": "(+hello -word)",
"fields": ["title"],
"default_operator": "AND"
}
}
}
七、Mapping和常见字段
Mapping 类似数据库中的 表的定义,作用如下:
- 定义索引中的字段的名称
- 定义字段的数据类型,例如字符串,数字,布尔……
- 字段,倒排索引的相关配置(Analyzed or Not Analyzed,Analyzer)
Mapping 会把 JSON 文档映射成 Lucene 所需要的扁平格式。
7.0之前每个mapping都有一个type,7.0之后不需要在mapping中定义指定type信息
1、字段的数据类型
a、简单类型
- text / keyword
- date
- integer / floating
- boolean
- ipv4 & ipv6
b、复杂类型-对象和嵌套对象
- 对象类型 / 嵌套类型
c、特殊类型
- geo_point & geo_shape / percolator
2、Dynamic Mapping
在写入文档的瘦,如果索引不存在,会自动创建索引
Dynamic Mapping 的机制,使得我们不用手动定义Mapping,Elasticsearch可以自动推算出字段的类型
但是有的时候也会推算不对,例如地址位置信息
当类型设置不对的时候会导致一些功能无法正常运行,例如 Range 查询
# 查看mapping GET movies/_mapping
a、类型自动识别
| JSON类型 | Elasticsearch类型 |
|---|---|
| 字符串 | 匹配日期格式,设置成Date 匹配数字设置为 float 或者 long ,该选项默认关闭 设置为text,并且增加keyword字段 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | properties 也就是object |
| 数组 | 由第一个非空数值的类型所决定,如果是string 那么就是字符串类型 |
| 空值 | 忽略 |
- 测试
PUT mapping_test/_doc/1
{
"uid": "123",
"name": "lilei",
"create_date": "2019-10-10T22:11:22+00:00",
"isVip": false,
"isAdmin": "true",
"age": 22,
"heigh": "180",
"money": 12.3,
"ip":"192.168.1.11",
"language": [
"java",
"python"
],
"children": {
"number": 3
},
"geoip": {
"lon": 31.3,
"lat": 30.1
}
}
# uid 是text类型
# name 是text类型
# create_date 是date类型
# isVip 是boolean类型
# isAdmin 是text类型
# age 是long类型
# height 是text类型
# money 是float类型
# ip 是 text类型
# language 是text类型,根据第一个值推断的类型
# children 是properties 也就是object类型
# geoip 是properties 也就是object类型,这也就是地理位置推算有问题的地方
b、Mapping的dynamic设定
不支持对已有字段类型进行改变,如果必须改变,就只能Reindex API来重建索引了
- 设置Mapping,默认是true
PUT dynamic_mapping_test/_mapping { "dynamic": false }
| 设置 | 文档索引 | 字段索引 | Mapping更新 | 描述 |
|---|---|---|---|---|
| “true” | YES | YES | YES | 一旦有新增字段的文档写入,Mapping也同时被更新 |
| “false” | YES | NO | NO | 一旦有新增字段的文档写入,Mapping不会更新 新增的字段数据,也无法被索引,新增字段被丢弃 |
| “strict” | NO | NO | NO | 新增字段时,数据写入直接出错 |
- 新增字段
PUT dynamic_mapping_test/_doc/1
{
"newField":"someValue"
}
3、Mapping设置及常见参数
创建一个Index
PUT test_users { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "mobile": { "type": "long" } } } }
a、自定义Mapping的建议
- 可以参考 API 手册,纯手写
- 为了减少输入的工作量,减少出错的概率,可以按照如下
- 创建一个临时的 index,写入一些样本数据
- 通过访问Mapping API 获得该临时文件的动态 Mapping 定义
- 修改后用,使用该配置创建你的索引
- 删除临时索引,避免类型人工推断错误。
b、设置某字段是否可被索引
index参数
- 创建时可以设定字段是否被索引,默认都是true,注意只是不能被索引(使用会报错),不是不可见
PUT test_users
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"mobile": {
"type": "long",
"index": false
}
}
}
}
c、设置倒排索引记录的内容
index_options 参数
PUT test_users { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "mobile": { "type": "long", "index": false }, "bio": { "type": "text", "index_options": "docs" } } } }
-
四种级别
- docs 记录doc id
freqs 记录doc id 和 term frequencies
positions 记录doc id 和 term frequencies / term position
offsets 记录 doc id 和 term frequencies / term position / character offects
- docs 记录doc id
-
text类型默认记录 positions,其他默认为docs
-
记录内容越多,占用存储空间越大
d、对null值实现搜索
null_value参数
只有keyword 类型支持设定 null_value,只有设置了才能支持"NULL"的搜索
设置
PUT test_users { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "mobile": { "type": "long", "index": false }, "bio": { "type": "text", "index_options": "docs" }, "nullvalue":{ "type": "keyword", "null_value": "NULL" } } } }
-
添加数据时,传入null
POST test_users/_doc/1 { "name":"li,.ei", "age":123, "mobile":1234412313, "bio":123123, "nullvalue": null } -
查询数据时,查询NULL
GET test_users/_search { "query": {"query_string": { "default_field": "nullvalue", "query":"NULL" }} }
e、copy_to设置
_all 在 7 中被 copy_to所代替
- 用于满足一些特定的搜索
- 通过配置。可以让搜索的时候聚合到多个字段
- copy_to的字段不会出现在查询结果的_source中
-
测试 新建索引 时指定copy_to字段
PUT test_users { "mappings": { "properties": { "firstName": { "type": "text", "copy_to": "fullName" }, "lastName": { "type": "text", "copy_to": "fullName" } } } } -
添加数据,注意默认的词法分析,中文是一个字一个哦。。
POST test_users/_doc/1 { "firstName":"李", "lastName":"雷" } # 测试上面的查询,注意注意,中文是一个字一个词。。。 GET test_users/_search?q=fullName:(李 AND 雷) POST test_users/_search { "query": { "query_string": { "default_field": "fullName", "query": "李 AND 雷" } } }
4、多字段类型
后面自己去查询。这人的视频。。真无语。 看着头大。乱七八糟的。
好像就是子字段。。
5、精确值和全文本
exact_value
- 包括数字 / 日志 / 具体的一个字符串(例如 App Store一个整体)
- elasticsearch中的 keyword
- 精确值不会分词。就是一个整体
full text
- 全文本,非结构化的文本数据
- elasticsearch中的 text,会根据分词器进行分词
八、自定义分词
当 Elasticsearch 自带的分词器无法满足时,可以自定义分词器。通过自组合不同的组件来实现:
- Character Filter(针对原始文本处理,例:去除html)
- Tokenizer(按照规则切分为单词)
- TokenFilter(将切分的单词进行加工,小写,删除stopwords,增加同义词)
1、Character Filters
-
在 Tokenizer 之前对文本进行处理,例如增加删除及替换字符。可以配置多个Character Filters。会影响 Tokenizer 的 position 和 offset 信息
-
一些自带的 Character Filters
-
html_strip 去除 html 标签
POST _analyze { "tokenizer": "keyword", "char_filter": ["html_strip"], "text": ["hello world"] }mapping 字符串替换
# 中划线替换成下划线 POST _analyze { "tokenizer": "standard", "char_filter": [ { "type": "mapping", "mappings": ["- => _"] } ], "text": "test-id,123-456! test-900 650-423-1234" } # 表情符号替换成英文 POST _analyze { "tokenizer": "standard", "char_filter": [ { "type": "mapping", "mappings": [":) => happy",":( => sad"] } ], "text": ["I am felling :)","Feeling : :( today"] }pattern replace 正则匹配替换
# 正则匹配,留下$1。。。 POST _analyze { "tokenizer": "standard", "char_filter": [ { "type": "pattern_replace", "pattern": "http://(.*)", "replacement": "$1" } ], "text": "http://www.elastic.co" }
-
2、Tokenizer
-
将原始的文本按照一定的规则,切分为词(term or token)
-
elasticsearch 内置的 Tokenizer
-
whitespace / standard / uax_url_email / pattern / keyword / path hierarchy
-
path_hierarchy 测试用例 - 按照url拆分
POST _analyze { "tokenizer": "path_hierarchy", "text": "/usr/local/soft/elasticsearch" } # /usr # /usr/local # /usr/local/soft # /usr/local/soft/elasticsearch -
whitespace测试用例 - 空格拆分
# 按照空格拆分 POST _analyze { "tokenizer": "whitespace", "text": ["The rain in Spain falls mainly on the plain."] }
-
-
-
可以用Java开发插件,实现自己的 Tokenizer
3、Token Filters
注意传递多个,一定要注意先后顺序
-
将 Tokenizer 输出的单词(term),进行增加、修改、删除
-
自带的 Token Filters
-
lowercase / stop / synonym(添加近义词)
-
stop和lowercase 测试用例 - 空格拆分 且 去掉停用词
# The 虽然也是停用词,但是会保留。因为是大写,因为只会去掉是小写的停用词 POST _analyze { "tokenizer": "whitespace", "filter": [ "stop" ], "text": [ "The rain in Spain falls mainly on the plain." ] } # 这个就是把不管大写小写的停用词都去掉,先小写,再去停用词 POST _analyze { "tokenizer": "whitespace", "filter": [ "lowercase","stop" ], "text": [ "The rain in Spain falls mainly on the plain." ] }
-
-
4、设置一个Custom Analizer
可以在创建索引的时候设置一个自定义的分词器
只需要再settings里面设置好
a、创建自定义Analizer
PUT my_index
{
"mappings": {},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer_自定义名": {
"type": "custom",
"char_filter": [
"emoticons_自定义名"
],
"tokenizer": "punctuation_自定义名",
"filter": [
"lowercase",
"english_stop_自定义名"
]
}
},
"tokenizer": {
"punctuation_自定义名": {
"type": "pattern",
"pattern": "[ .,!?]"
}
},
"char_filter": {
"emoticons_自定义名": {
"type": "mapping",
"mappings": [
":) => _happy_",
":( => _sad_"
]
}
},
"filter": {
"english_stop_自定义名": {
"type": "stop",
"stopwords": "_english_"
}
}
}
}
}
b、测试自定义分词器
POST my_index/_analyze
{
"analyzer": "my_custom_analyzer_自定义名",
"text": ["I'm a :) person, and you?"]
}
九、自定义索引模板
集群上的索引会越来越多,例如,我们会对日志每天创建一个索引
- 使用多个索引可以让我们更好的管理数据,提高性能
- logs-2020-05-01
- logs-2020-05-02
- logs-2020-06-03
1、index template
- Index template 帮助我们设定 mapping 和 settings,并按照一定过的规则,自动匹配到新创建的索引之上
- 模板仅在一个索引被创建时,才会产生作用。修改模板不会影响已创建的索引。
- 可以设定多个模板,这些设置会被 “merge” 在一起
- 可以指定 “order” 的数值,控制 “merging” 的过程
- GET _template/* 或 GET _template 查看所有模板
2、索引模板案例
-
创建任何索引的时候,会设定分片为1,副本为1
PUT _template/template_default
{
"index_patterns": ["*"],
"order": 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
# 测试模板
POST romdon_test/_doc/1
{
"name":"李磊",
"create_date":"2019-10-10T22:11:22+00:00",
"age":"123"
}
# name 是text类型
# create_date 是date类型
# age 是text类型
-
创建以test开头的索引,会设定分片为1,副本为2
-
同时会把日期格式的探测关闭,数字的探测打开(数字探测默认是关闭)
PUT _template/template_test
{
"index_patterns": ["test*"],
"order": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 2
},
"mappings": {
"date_detection": false,
"numeric_detection": true
}
}
# 测试模板
POST test_heihei/_doc/1
{
"name":"李磊",
"create_date":"2020-05-06T22:11:22+00:00",
"age":"123"
}
# name 是text类型
# create_date 是text类型
# age 是long类型
3、索引模板的工作方式
- 当一个索引被创建时
- 1、应用elasticsearch 默认的 setting 和mappings
- 2、应用 order 数值低的 index template 中的设定
- 3、应用 order 数值高的 index template 中的设定,之前的索引设置相同的会被覆盖
- 4、应用创建索引时,用户自定义的 setting 和mappings ,之前的索引模板设置相同的会被覆盖
4、动态字段模板
根据 Elasticsearch 识别的数据类型,结合字段名称,来动态设定字段类型
- 所有的字符类型都设定成 keyword,或者关闭keyword字段
- is 开头的字段都设置成 boolean 类型
- long_开头的都设置成long 类型
-
定义在某个索引的mappings中
- template有名称、匹配规则是数组、为匹配到的字段设置mapping
- match_mapping_tyoe:匹配自动识别的字段类型,string,boolean等
- match,unmatch:匹配字段名
- path_match,path_unmatch:
- 注意数组的顺序,还有数组里面都是用的{},dynamic_templates、strings_as_boolean等都是关键字
-
测试1,string转为boolean,根据名字前缀的正则
PUT my_test_index3
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean_自定义": {
"match_mapping_type": "string",
"match": "is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keyword_自定义": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
# 测试
POST my_test_index3/_doc/1
{
"isVIP":"true",
"name":"lilei"
}
-
测试2 自动把正则组成成一个copy_to
PUT my_test_index1
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
# 测试 ,注意正则里面是name这个对象。
PUT my_test_index1/_doc/1
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}
GET my_test_index1
GET my_test_index/_search?q=full_name:John
GET my_test_index/_search?q=full_name:Winston # 这个就没有被copy_to
十、聚合
就是语句支持统计分析。。。I fuck you
1、聚合的分类
-
Bucket Aggregation 一些列满足特定条件的文档的集合
-
支持很多类型的Buccket,例如Term & Range (时间 / 年龄区间 / 地理位置)
-
测试,查询航班目的地的统计信息,结果不在hits里,而在同级的aggregations中
GET kibana_sample_data_flights/_search { "size": 0, "aggs": { "fligth_dest_自定义名字": { "terms": { "field": "DestCountry_待分组的字段" } } } }
-
-
Metric Aggregation 一些数学运算,可以对文档字段进行统计分析
基于数据集计算结果,除了支持在字段上进行计算,同样也支持在脚本(painless script)产生的结果上进行计算
-
大多数 metric 是数学计算,仅输出一个值
- min / max / sum / avg / cardinality
-
部分 metric 支持输出多个数值
- stats / percentiles / percentile_ranks
-
测试1,查看航班目的地的统计信息,增加均价,最高最低价格
GET kibana_sample_data_flights/_search { "size": 0, "aggs": { "fligth_dest_自定义名字": { "terms": { "field": "DestCountry" }, "aggs": { "average_proce_自定义": { "avg": { "field": "AvgTicketPrice" } }, "max_price_自定义": { "max": { "field": "AvgTicketPrice" } }, "min_price_自定义": { "min": { "field": "AvgTicketPrice" } } } } } } -
测试2,查看航班目的地的统计信息,平均票价,以及天气状况
GET kibana_sample_data_flights/_search { "size": 0, "aggs": { "flight_dest_自定义": { "terms": { "field": "DestCountry" }, "aggs": { "average_price_自定义": { "avg": { "field": "AvgTicketPrice" } }, "weather_自定义": { "terms": { "field": "DestWeather" } } } } } }
-
-
Pipeline Aggregation 对其他的聚合结果进行二次聚合
-
Matrix Aggregation 支持对多个字段的操作并提供一个结果矩阵
Elasticsearch深入搜索
Elasticsearch分布式特性及分布式搜索机制
Elasticsearch深入聚合分析
Elasticsearch数据建模
Elasticsearch保护你的数据
Elasticsearch水平扩展Elasticsearch集群
Elasticsearch生产环境的集群运维
Elasticsearch索引生命周期的管理
用Logstash 和 Beats 构建数据管道
用Kibana 进行数据可视化分析
探索 X-park 套件
实战1:电影搜索服务
实战2:stackoverflow用户调查问卷分析
Elastic认证