基于Amoeba读写分离(三十六)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、pandas是什么?
- 二、使用步骤
- 1.引入库
- 2.读入数据
- 总结
前言
今天要学的是基于Amoeba读写分离。Amoeba是一个开源的关系型数据库管理系统,它支持读写分离的架构。在Amoeba中,读操作和写操作可以被分发到不同的节点上进行处理,以提高系统的性能和可扩展性。Amoeba的读写分离架构包括主节点和从节点。主节点负责处理写操作,而从节点负责处理读操作。主节点和从节点之间通过复制机制保持数据的一致性。当应用程序需要执行写操作时,它将请求发送到主节点。主节点在完成写操作后,会将数据的副本复制到从节点上。这样,应用程序可以立即从主节点中获得最新的数据。当应用程序需要执行读操作时,它可以选择直接向主节点发送请求,或者向从节点发送请求。如果应用程序向主节点发送读请求,主节点会立即返回最新的数据。如果应用程序向从节点发送读请求,从节点会检查是否有最新的数据副本可用。如果有,则从节点会返回最新的数据副本;如果没有,则从节点会向主节点请求最新的数据,并在获得数据后返回给应用程序。通过读写分离架构,Amoeba可以分担主节点的读写压力,提高系统的并发处理能力。同时,读操作可以通过从节点进行处理,减少了主节点的负载,提高了系统的性能和吞吐量。总结起来,基于Amoeba的读写分离架构可以提高数据库系统的性能和可扩展性。通过将读操作和写操作分发到不同的节点上进行处理,可以有效地分担主节点的负载,提高系统的并发处理能力。
提示:以下是本篇文章正文内容,下面案例可供参考
一、概述
在实际的生产环境中,如果对数据库的读和写都在同一个数据库服务器中操作,无论是安全性,高可用还是并发等各个方面都不能完全满足实际需求的,因此一般来说都是通过主从复制的方式来同步数据,再通过读写分离来提供数据的高并发负载能力这样的方案来进行部署。
简单来说,读写分离就是只在主服务器上写,只在从服务器上读,基本的原理是让主数据库处理事务性查询,而从数据库处理select查询,数据库复制被用来把事务性查询导致的改变更新同步到集群中的从数据库。
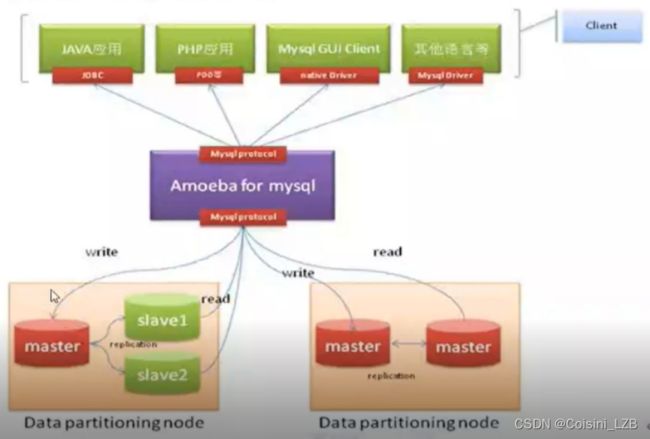
目前最常见的MySQL读写分离方案有两种:
- 基于程序代码内部实现
在代码中根据select,insert进行路由分类,这类方法也是目前大型生产环境应用最广泛的,优点是性能最好,因为在程序代码中实现,不需要增加额外的设备作为硬件开支,缺点是需要开发人员来实现,运维人员无从下手
- 基于中间代理层实现
代理一般位于客户端和数据库服务器之间,代理服务器接到客户端请求后通过判断转发到后端数据库,代表性程序:
(1)mysql-proxy为mysql开发早期开源项目,通过其自带的lua脚本进行SQL判断,虽然是mysql的官方产品,但是mysql官方不建议将其应用到生产环境。
(2)Amoeba(变形虫)该程序由java语言及逆行开发,阿里巴巴将其应用于生产环境,它不支持事物和存储过程。
MySQL Master IP:192.168.200.111
MySQL Slave1 IP:192.168.200.112
MySQL Slave2 IP:192.168.200.113
MySQL Amoeba IP:192.168.200.114
MySQL Client IP:192.168.200.115

Amoeba(变形虫)项目开源框架于2008年发布一款Amoeba for mysql软件,这个软件致力于mysql的分布式数据库前端代理层,主要为应用层访问mysql的时候充当SQL路由功能,并具有负载均衡,高可用性,SQL过滤,读写分离,可路由到相关的目标数据库,可并发请求多台数据库,通过Amoeba能够完成多数据源的高可用,负载均衡,数据切片的功能,目前Amoeba已经在很多企业的生产线上使用。
二、实验:
1、在主机Amoeba上安装java环境
因为Amoeba是基于jdk1.5版本开发的,所以官方推荐使用1.5或者1.6版本,高版本不建议使用。
[root@localhost ~]# chmod +x jdk-6u31-linux-x64.bin
[root@localhost ~]# ./jdk-6u31-linux-x64.bin
[root@localhost ~]# mv jdk1.6.0_31/ /usr/local/jdk1.6
[root@localhost ~]# vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
[root@localhost ~]# rm -rf /usr/bin/java
[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version
java version "1.6.0_31"
Java(TM) SE Runtime Environment (build 1.6.0_31-b04)
Java HotSpot(TM) 64-Bit Server VM (build 20.6-b01, mixed mode)
2、安装并配置Amoeba
[root@localhost ~]# mkdir /usr/local/amoeba
[root@localhost ~]# tar xf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
[root@localhost ~]# chmod -R 755 /usr/local/amoeba/3、配置Amoeba读写分离,两个Slave读负载均衡
在Master、Slave1、Slave2服务器中配置Amoeba的访问授权
MariaDB [(none)]> grant all on *.* to 'test'@'192.168.200.%' identified by '123.com';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.00 sec)编辑amoeba.xml配置文件
[root@localhost ~]# vim /usr/local/amoeba/conf/amoeba.xml
30 amoeba
32 123456
115 master
118 master
119 slaves 编辑dbServer.xml配置文件
[root@localhost ~]# vim /usr/local/amoeba/conf/dbServers.xml
3306
test
test
123.com
192.168.200.111
192.168.200.112
192.168.200.113
1
slave1,slave2
配置无误后,启动Amoeba软件,默认端口是TCP协议8066
[root@localhost ~]# /usr/local/amoeba/bin/amoeba start &
[root@localhost ~]# netstat -lnpt | grep 8066
tcp6 0 0 :::8066 :::* LISTEN 10099/java
[root@localhost ~]# netstat -anpt | grep 3306
tcp6 0 0 192.168.200.114:46412 192.168.200.111:3306 ESTABLISHED 10099/java
tcp6 0 0 192.168.200.114:47708 192.168.200.112:3306 ESTABLISHED 10099/java
tcp6 0 0 192.168.200.114:47892 192.168.200.113:3306 ESTABLISHED 10099/java
在Client上进行访问测试
[root@localhost ~]# yum -y install mariadb mariadb-devel然后可以通过代理访问MySQL
[root@localhost ~]# mysql -uamoeba -p123456 -h 192.168.200.114 -P 8066
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 2037510537
Server version: 5.1.45-mysql-amoeba-proxy-2.2.0 MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]>在MySQL主服务器上创建一个表,会自动同步到各个从服务器上,然后关掉各个服务器上的Slave功能,在分别插入语句测试。
主服务器
MariaDB [(none)]> create database Rich;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> use Rich;
Database changed
MariaDB [Rich]> create table student (id int(10),name varchar(10),address varchar(20));
Query OK, 0 rows affected (0.00 sec)分别在两台从服务器上
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| Rich |
| mysql |
| performance_schema |
| sampdb |
| test |
+--------------------+
6 rows in set (0.00 sec)
MariaDB [(none)]> use Rich;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MariaDB [Rich]> show tables;
+----------------+
| Tables_in_Rich |
+----------------+
| student |
+----------------+
1 row in set (0.00 sec)
MariaDB [(none)]> stop slave;
Query OK, 0 rows affected (0.01 sec)Master
MariaDB [(none)]> use Rich;
MariaDB [Rich]> insert into student values('1','Rich','this_is_master');
Query OK, 1 row affected (0.00 sec)Slave1
MariaDB [(none)]> use Rich;
MariaDB [Rich]> insert into student values('2','Rich','this_is_slave1');
Query OK, 1 row affected (0.00 sec)Slave2
MariaDB [(none)]> use Rich;
MariaDB [Rich]> insert into student values('3','Rich','this_is_slave2');
Query OK, 1 row affected (0.00 sec)
操作测试:
在测试机上第1次查询结果
MySQL [Rich]> select * from student;
+------+------+----------------+
| id | name | address |
+------+------+----------------+
| 2 | Rich | this_is_slave1 |
+------+------+----------------+
1 row in set (0.00 sec)在测试机上第2次查询结果
MySQL [Rich]> select * from student;
+------+------+----------------+
| id | name | address |
+------+------+----------------+
| 3 | Rich | this_is_slave2 |
+------+------+----------------+
1 row in set (0.02 sec)在测试机上第3次查询结果
MySQL [Rich]> select * from student;
+------+------+----------------+
| id | name | address |
+------+------+----------------+
| 2 | Rich | this_is_slave1 |
+------+------+----------------+
1 row in set (0.03 sec)
测试写操作:
在Client上插入一条语句:
MySQL [Rich]> insert into student values ('4','Rich','write_test');
Query OK, 1 row affected (0.01 sec)
MySQL [Rich]> select * from student;
+------+------+----------------+
| id | name | address |
+------+------+----------------+
| 3 | Rich | this_is_slave2 |
+------+------+----------------+
1 row in set (0.01 sec)
MySQL [Rich]> select * from student;
+------+------+----------------+
| id | name | address |
+------+------+----------------+
| 2 | Rich | this_is_slave1 |
+------+------+----------------+
1 row in set (0.00 sec)但在Client上查询不到,最终只有在Master上才能看到这条语句内容,说明写操作在master服务器上
MariaDB [Rich]> select * from student;
+------+------+----------------+
| id | name | address |
+------+------+----------------+
| 1 | Rich | this_is_master |
| 4 | Rich | write_test |
+------+------+----------------+
3 rows in set (0.00 sec)由此验证,已经实现了MySQL读写分离,目前所有的写操作都在Master主服务器上,用来避免数据的不同步,所有的读操作都平分给了Slave从服务器,用来分担数据库压力。
分别在两台从服务器上启用slave功能
MariaDB [Rich]> start slave;
Query OK, 0 rows affected (0.00 sec)现在在Client测试机上查看
MySQL [Rich]> select * from student;
+------+------+----------------+
| id | name | address |
+------+------+----------------+
| 3 | Rich | this_is_slave2 |
| 1 | Rich | this_is_master |
| 4 | Rich | write_test |
+------+------+----------------+
4 rows in set (0.00 sec)总结
以上就是今天要讲的内容,好好练哦!