前端面试题——Vue 高频
目录
一、Vue的基本原理
二、双向数据绑定的原理
三、MVVM、MVC、MVP的区别
(1)MVC
(2)MVVM
(3)MVP
四、Computed 和 Watch 的区别
Computed:
Watch:
五、Computed 和 Methods 的区别
六、v-if 和 v-show的区别
七、data为什么是一个函数而不是对象
八、Vue 单页应用与多页应用的区别
九、对 React 和 Vue 的理解,它们的异同是什么
相似之处:
不同之处 :
十、对 SPA 单页面的理解,它的优缺点分别是什么?
优点:
缺点:
十一、简单说一下Vue的生命周期
十二、组件通信的方式有哪些?
(1) props / $emit
(2)eventBus事件总线($emit / $on)
(3)依赖注入(project / inject)
(4)ref / $refs
(5)$parent / $children
(6)$attrs / $listeners
(7)总结
十三、路由的 hash 和 history 模式的区别
1. hash模式
2. history模式
3. 两种模式对比
十四、对前端路由的理解
十五、Vuex 的原理以及自己的理解
Vuex 的原理
十六、Vuex中action和mutation的区别
十七、Redux 和 Vuex 有什么区别,它们的共同思想
(1)Redux 和 Vuex区别
(2)共同思想
十八、Vue3 有什么更新
(1)监测机制的改变
(2)只能监测属性,不能监测对象
(3)模板
(4)对象式的组件声明方式
(5)其它方面的更改
十九、defineProperty和proxy的区别
二十、对虚拟DOM的理解
二十一、DIFF算法的原理
二十二、Vue的优点
一、Vue的基本原理
当一个Vue实例创建时,Vue会遍历data中的属性,用 Object.defineProperty(vue3.0使用proxy )将它们转为 getter/setter,并且在内部追踪相关依赖,在属性被访问和修改时通知变化。 每个组件实例都有相应的 watcher 程序实例,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的setter被调用时,会通知watcher重新计算,从而致使它关联的组件得以更新。
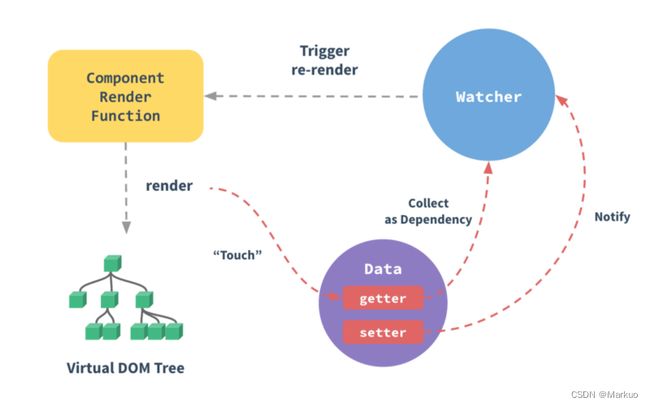
二、双向数据绑定的原理
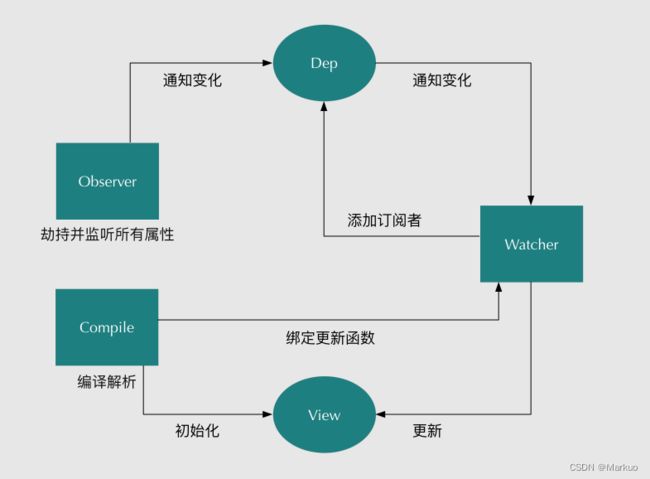
Vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。主要分为以下几个步骤:
- 需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上setter和getter这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化。
- compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图。
- Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情是: ①在自身实例化时往属性订阅器(dep)里面添加自己 ②自身必须有一个update()方法 ③待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
- MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
三、MVVM、MVC、MVP的区别
MVC、MVP 和 MVVM 是三种常见的软件架构设计模式,主要通过分离关注点的方式来组织代码结构,优化开发效率。
在开发单页面应用时,往往一个路由页面对应了一个脚本文件,所有的页面逻辑都在一个脚本文件里。页面的渲染、数据的获取,对用户事件的响应所有的应用逻辑都混合在一起,这样在开发简单项目时,可能看不出什么问题,如果项目变得复杂,那么整个文件就会变得冗长、混乱,这样对项目开发和后期的项目维护是非常不利的。
(1)MVC
MVC 通过分离 Model、View 和 Controller 的方式来组织代码结构。其中 View 负责页面的显示逻辑,Model 负责存储页面的业务数据,以及对相应数据的操作。并且 View 和 Model 应用了观察者模式,当 Model 层发生改变的时候它会通知有关 View 层更新页面。Controller 层是 View 层和 Model 层的纽带,它主要负责用户与应用的响应操作,当用户与页面产生交互的时候,Controller 中的事件触发器就开始工作了,通过调用 Model 层,来完成对 Model 的修改,然后 Model 层再去通知 View 层更新。

(2)MVVM
MVVM 分为 Model、View、ViewModel:
- Model代表数据模型,数据和业务逻辑都在Model层中定义;
- View代表UI视图,负责数据的展示;
- ViewModel负责监听Model中数据的改变并且控制视图的更新,处理用户交互操作;
Model和View并无直接关联,而是通过ViewModel来进行联系的,Model和ViewModel之间有着双向数据绑定的联系。因此当Model中的数据改变时会触发View层的刷新,View中由于用户交互操作而改变的数据也会在Model中同步。
这种模式实现了 Model和View的数据自动同步,因此开发者只需要专注于数据的维护操作即可,而不需要自己操作DOM。
(3)MVP
MVP 模式与 MVC 唯一不同的在于 Presenter 和 Controller。在 MVC 模式中使用观察者模式,来实现当 Model 层数据发生变化的时候,通知 View 层的更新。这样 View 层和 Model 层耦合在一起,当项目逻辑变得复杂的时候,可能会造成代码的混乱,并且可能会对代码的复用性造成一些问题。MVP 的模式通过使用 Presenter 来实现对 View 层和 Model 层的解耦。MVC 中的Controller 只知道 Model 的接口,因此它没有办法控制 View 层的更新,MVP 模式中,View 层的接口暴露给了 Presenter 因此可以在 Presenter 中将 Model 的变化和 View 的变化绑定在一起,以此来实现 View 和 Model 的同步更新。这样就实现了对 View 和 Model 的解耦,Presenter 还包含了其他的响应逻辑。
四、Computed 和 Watch 的区别
Computed:
- 它支持缓存,只有依赖的数据发生了变化,才会重新计算
- 不支持异步,当Computed中有异步操作时,无法监听数据的变化
- computed的值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data声明过,或者父组件传递过来的props中的数据进行计算的
- 如果一个属性是由其他属性计算而来的,这个属性依赖其他的属性,一般会使用computed
- 如果computed属性的属性值是函数,那么默认使用get方法,函数的返回值就是属性的属性值;在computed中,属性有一个get方法和一个set方法,当数据发生变化时,会调用set方法
Watch:
- 它不支持缓存,数据变化时,它就会触发相应的操作
- 支持异步监听
- 监听的函数接收两个参数,第一个参数是最新的值,第二个是变化之前的值
- 当一个属性发生变化时,就需要执行相应的操作
- 监听数据必须是data中声明的或者父组件传递过来的props中的数据,当发生变化时,会触发其他操作,函数有两个的参数:
- immediate:组件加载立即触发回调函数
- deep:深度监听,发现数据内部的变化,在复杂数据类型中使用,例如数组中的对象发生变化。需要注意的是,deep无法监听到数组和对象内部的变化
- 当想要执行异步或者昂贵的操作以响应不断的变化时,就需要使用watch。
总结:
- computed 计算属性 : 依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值。
- watch 侦听器 : 更多的是**观察**的作用,无缓存性,类似于某些数据的监听回调,每当监听的数据变化时都会执行回调进行后续操作。
运用场景:
- 当需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时都要重新计算。
- 当需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许执行异步操作 ( 访问一个 API ),限制执行该操作的频率,并在得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
五、Computed 和 Methods 的区别
共同点:可以将同一函数定义为一个 method 或者一个计算属性。对于最终的结果,两种方式是相同的
不同点:
- computed:计算属性是基于它们的依赖进行缓存的,只有在它的相关依赖发生改变时才会重新求值
- method:调用总会执行该函数
六、v-if 和 v-show的区别
- v-if是动态的向DOM树内添加或者删除DOM元素;
- v-show是通过设置DOM元素的display样式属性控制显示隐藏;
编译过程:
- v-if切换有一个局部编译、卸载的过程,切换过程中合适地销毁和重建内部的事件监听和子组件;
- v-show只是简单的基于css切换;
编译条件:
- v-if是惰性的,如果初始条件为假,则什么也不做,只有在条件第一次变为真时才开始局部编译;
- v-show是在任何条件下,无论首次条件是否为真,都被编译,然后被缓存,而且DOM元素保留;
性能消耗:
- v-if有更高的切换消耗;
- v-show有更高的初始渲染消耗;
使用场景:
- v-if适合运营条件不大可能改变;
- v-show适合频繁切换;
七、data为什么是一个函数而不是对象
JavaScript中的对象是引用类型的数据,当多个实例引用同一个对象时,只要一个实例对这个对象进行操作,其他实例中的数据也会发生变化。而在Vue中,更多的是想要复用组件,那就需要每个组件都有自己的数据,这样组件之间才不会相互干扰。所以组件的数据不能写成对象的形式,而是要写成函数的形式。数据以函数返回值的形式定义,这样当每次复用组件的时候,就会返回一个新的data,也就是说每个组件都有自己的私有数据空间,它们各自维护自己的数据,不会干扰其他组件的正常运行。
八、Vue 单页应用与多页应用的区别
概念:
- SPA单页面应用(SinglePage Web Application),指只有一个主页面的应用,一开始只需要加载一次js、css等相关资源。所有内容都包含在主页面,对每一个功能模块组件化。单页应用跳转,就是切换相关组件,仅仅刷新局部资源。
- MPA多页面应用 (MultiPage Application),指有多个独立页面的应用,每个页面必须重复加载js、css等相关资源。多页应用跳转,需要整页资源刷新。
| 对比项 \ 模式 | SPA | MPA |
|---|---|---|
| 结构 |
一个主页面+许多模块组件 | 许多完整的页面 |
| 体验 | 页面切换快,体验佳;当初次加载文件过多时,需要做相关的调优。 | 页面切换慢,网速慢的时候,体验尤其不好 |
| 资源文件 | 组件公用的资源只需要加载一次 | 每个页面都要自己加载公用的资源 |
| 适用场景 | 对体验度和流畅度有较高要求的应用,不利于SEO(可借助SSR优化SEO) | 适用于对SEO要求较高的应用 |
| 过渡动画 | Vue 提供了 transition 的封装组件,容易实现 | 很难实现 |
| 内容更新 | 相关组件的切换,即局部更新 | 整体HTML的切换,费钱(重复HTTP请求) |
| 路由模式 | 可以适用hash,也可以适用history | 普通链接跳转 |
| 数据传递 | 因为单页面,使用全局变量就好(Vuex) | cookie、localStorage等缓存方案,URL参数,调用接口保存等 |
| 相关成本 | 前期开发成本较高,后期维护较为容易 | 前期开发成本低,后期维护就比较麻烦,因为可能一个功能需要改很多地方 |
九、对 React 和 Vue 的理解,它们的异同是什么
相似之处:
- 都将注意力集中保持在核心库,而将其他功能如路由和全局状态管理交给相关的库;
- 都有自己的构建工具,能让你得到一个根据最佳实践设置的项目模板;
- 都使用了Virtual DOM(虚拟DOM)提高重绘性能;
- 都有props的概念,允许组件间的数据传递;
- 都鼓励组件化应用,将应用分拆成一个个功能明确的模块,提高复用性。
不同之处 :
(1)数据流
Vue默认支持数据双向绑定,而React一直提倡单向数据流
(2)虚拟DOM
Vue2.x开始引入"Virtual DOM",消除了和React在这方面的差异,但是在具体的细节还是有各自的特点。
Vue宣称可以更快地计算出Virtual DOM的差异,这是由于它在渲染过程中,会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树。
对于React而言,每当应用的状态被改变时,全部子组件都会重新渲染。当然,这可以通过 PureComponent/shouldComponentUpdate这个生命周期方法来进行控制,但Vue将此视为默认的优化。
(3)组件化
React与Vue最大的不同是模板的编写。
Vue鼓励写近似常规HTML的模板。写起来很接近标准 HTML元素,只是多了一些属性。
React推荐你所有的模板通用JavaScript的语法扩展——JSX书写。
具体来讲:React中render函数是支持闭包特性的,所以import的组件在render中可以直接调用。但是在Vue中,由于模板中使用的数据都必须挂在 this 上进行一次中转,所以 import 一个组件完了之后,还需要在 components 中再声明下。
(4)监听数据变化的实现原理不同
Vue 通过 getter/setter 以及一些函数的劫持,能精确知道数据变化,不需要特别的优化就能达到很好的性能
React 默认是通过比较引用的方式进行的,如果不优化(PureComponent/shouldComponentUpdate)可能导致大量不必要的vDOM的重新渲染。这是因为 Vue 使用的是可变数据,而React更强调数据的不可变。
(5)高阶组件
react可以通过高阶组件(HOC)来扩展,而Vue需要通过mixins来扩展。
高阶组件就是高阶函数,而React的组件本身就是纯粹的函数,所以高阶函数对React来说易如反掌。相反Vue.js使用HTML模板创建视图组件,这时模板无法有效的编译,因此Vue不能采用HOC来实现。
(6)构建工具
两者都有自己的构建工具:
- React ==> Create React APP
- Vue ==> vue-cli
(7)跨平台
- React ==> React Native
- Vue ==> Weex
-
十、对 SPA 单页面的理解,它的优缺点分别是什么?
SPA( single-page application )仅在 Web 页面初始化时加载相应的 HTML、JavaScript 和 CSS。一旦页面加载完成,SPA 不会因为用户的操作而进行页面的重新加载或跳转,取而代之的是利用路由机制实现 HTML 内容的变换,UI 与用户的交互,避免页面的重新加载。
优点:
- 用户体验好、快,内容的改变不需要重新加载整个页面,避免了不必要的跳转和重复渲染;
- 基于上面一点,SPA 相对对服务器压力小;
- 前后端职责分离,架构清晰,前端进行交互逻辑,后端负责数据处理;
缺点:
- 初次加载耗时多:为实现单页 Web 应用功能及显示效果,需要在加载页面的时候将 JavaScript、CSS 统一加载,部分页面按需加载;
- 前进后退路由管理:由于单页应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,所有的页面切换需要自己建立堆栈管理;
- SEO 难度较大:由于所有的内容都在一个页面中动态替换显示,所以在 SEO 上其有着天然的弱势;
十一、简单说一下Vue的生命周期
Vue 实例有⼀个完整的⽣命周期。开始创建→初始化数据→编译模版→挂载Dom→渲染→更新→渲染→卸载等⼀系列过程,称这是Vue的⽣命周期。
- beforeCreate(创建前):数据观测和初始化事件还未开始,此时 data 的响应式追踪、event/watcher 都还没有被设置,也就是说不能访问到data、computed、watch、methods上的方法和数据。
- created(创建后):实例创建完成,实例上配置的 options 包括 data、computed、watch、methods 等都配置完成,但是此时渲染得节点还未挂载到 DOM,所以不能访问到 `$el` 属性。
- beforeMount(挂载前):在挂载开始之前被调用,相关的render函数首次被调用。实例已完成以下的配置:编译模板,把data里面的数据和模板生成html。此时还没有挂载html到页面上。
- mounted(挂载后):在el被新创建的 vm.$el 替换,并挂载到实例上去之后调用。实例已完成以下的配置:用上面编译好的html内容替换el属性指向的DOM对象。完成模板中的html渲染到html 页面中。此过程中进行ajax交互。
- beforeUpdate(更新前):响应式数据更新时调用,此时虽然响应式数据更新了,但是对应的真实 DOM 还没有被渲染。
- updated(更新后):在由于数据更改导致的虚拟DOM重新渲染和打补丁之后调用。此时 DOM 已经根据响应式数据的变化更新了。调用时,组件 DOM已经更新,所以可以执行依赖于DOM的操作。然而在大多数情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环。该钩子在服务器端渲染期间不被调用。
- beforeDestroy(销毁前):实例销毁之前调用。这一步,实例仍然完全可用,`this` 仍能获取到实例。
- destroyed(销毁后):实例销毁后调用,调用后,Vue 实例指示的所有东西都会解绑定,所有的事件监听器会被移除,所有的子实例也会被销毁。该钩子在服务端渲染期间不被调用。
- 另外还有 `keep-alive` 独有的生命周期,分别为 `activated` 和 `deactivated` 。用 `keep-alive` 包裹的组件在切换时不会进行销毁,而是缓存到内存中并执行 `deactivated` 钩子函数,命中缓存渲染后会执行 `activated` 钩子函数。
十二、组件通信的方式有哪些?
(1) props / $emit
父组件通过 props 向子组件传递数据,子组件通过 $emit 和父组件通信
- 父组件向子组件传值
props 只能是父组件向子组件进行传值,`props`使得父子组件之间形成了一个单向下行绑定。子组件的数据会随着父组件不断更新。
props 可以显示定义一个或一个以上的数据,对于接收的数据,可以是各种数据类型,同样也可以传递一个函数。
props 属性名规则:若在 props 中使用驼峰形式,模板中需要使用短横线的形式。
父组件
子组件
{{msg}}
- 子组件向父组件传值
$emit 绑定一个自定义事件,当这个事件被执行的时就会将参数传递给父组件,而父组件通过 v-on 监听并接收参数。
父组件
{{currentIndex}}
子组件
{{item}}
(2)eventBus事件总线($emit / $on)
eventBus 事件总线适用于父子组件、非父子组件等之间的通信,使用步骤如下:
- 创建事件中心管理组件之间的通信
GlobalBus.js
// 全局 事件监听
import Vue from 'vue';
export const GlobalBus = new Vue();- 发送事件
假设有两个兄弟组件 firstCom 和 secondCom :
在 firstCom 组件中发送事件:
- 接收事件
在 secondCom 组件中发送事件:
求和: {{count}}
在上述代码中,这就相当于将 num 值存贮在了事件总线中,在其他组件中可以直接访问。事件总线就相当于一个桥梁,不用组件通过它来通信。
虽然看起来比较简单,但是这种方法也有不变之处,如果项目过大,使用这种方式进行通信,后期维护起来会很困难。
(3)依赖注入(project / inject)
这种方式就是Vue中的依赖注入,该方法用于父子组件之间的通信。当然这里所说的父子不一定是真正的父子,也可以是祖孙组件,在层数很深的情况下,可以使用这种方法来进行传值。就不用一层一层的传递了。
project / inject 是 Vue提供的两个钩子,和data、methods是同级的。并且project的书写形式和data一样。
- project 钩子用来发送数据或方法
- inject 钩子用来接收数据或方法
父组件
provide() {
return {
num: this.num
};
}子组件
inject: ['num']还可以这样写,这样写就可以访问父组件中的所有属性:
provide() {
return {
app: this
};
}
data() {
return {
num: 1
};
}
inject: ['app']
console.log(this.app.num)注意:依赖注入所提供的属性是非响应式的。
(4)ref / $refs
这种方式也是实现父子组件之间的通信。
ref: 这个属性用在子组件上,它的引用就指向了子组件的实例。可以通过实例来访问组件的数据和方法。
子组件
export default {
data () {
return {
name: 'JavaScript'
}
},
methods: {
sayHello () {
console.log('hello')
}
}
}父组件
(5)$parent / $children
- 使用 $parent 可以让组件访问父组件的实例(访问的是上一级父组件的属性和方法)
- 使用 $children 可以让组件访问子组件的实例,但是,$children 并不能保证顺序,并且访问的数据也不是响应式的。
子组件
{{message}}
获取父组件的值为: {{parentVal}}
父组件
{{msg}}
在上面的代码中,子组件获取到了父组件的`parentVal`值,父组件改变了子组件中`message`的值。
需要注意:
- 通过$parent访问到的是上一级父组件的实例,可以使用$root来访问根组件的实例
- 在组件中使$children拿到的是所有的子组件的实例,它是一个数组,并且是无序的
- 在根组件#app上拿$parent得到的是new Vue()的实例,在这实例上再拿$parent得到的是undefined,而在最底层的子组件拿$children是个空数组
- $children 的值是数组,而$parent是个对象
(6)$attrs / $listeners
考虑一种场景,如果A是B组件的父组件,B是C组件的父组件。如果想要组件A给组件C传递数据,这种隔代的数据,该使用哪种方式呢?
如果是用 props / $emit 来一级一级的传递,确实可以完成,但是比较复杂;如果使用事件总线,在多人开发或者项目较大的时候,维护起来很麻烦;如果使用Vuex,的确也可以,但是如果仅仅是传递数据,那可能就有点浪费了。
针对上述情况,Vue引入了 $attrs / $listeners,实现组件之间的跨代通信。
先来看一下inheritAttrs,它的默认值true,继承所有的父组件属性除props之外的所有属性;inheritAttrs:false只继承class属性 。
- $attrs:继承所有的父组件属性(除了prop传递的属性、class 和 style ),一般用在子组件的子元素上
- $listeners:该属性是一个对象,里面包含了作用在这个组件上的所有监听器,可以配合 v-on="$listeners"将所有的事件监听器指向这个组件的某个特定的子元素。(相当于子组件继承父组件的事件)
A组件(APP.vue):
//此处监听了两个事件,可以在B组件或者C组件中直接触发
B组件(Child1.vue):
props: {{pChild1}}
$attrs: {{$attrs}}
C 组件 (Child2.vue):
props: {{pChild2}}
$attrs: {{$attrs}}
在上述代码中:
- C组件中能直接触发test的原因在于 B组件调用C组件时 使用 v-on 绑定了`$listeners` 属性
- 在B组件中通过v-bind 绑定`$attrs`属性,C组件可以直接获取到A组件中传递下来的props(除了B组件中props声明的)
(7)总结
父子组件间通信
- 子组件通过 props 属性来接受父组件的数据,然后父组件在子组件上注册监听事件,子组件通过 emit 触发事件来向父组件发送数据。
- 通过 ref 属性给子组件设置一个名字。父组件通过 $refs 组件名来获得子组件,子组件通过 $parent 获得父组件,这样也可以实现通信。
- 使用 provide/inject,在父组件中通过 provide提供变量,在子组件中通过 inject 来将变量注入到组件中。不论子组件有多深,只要调用了 inject 那么就可以注入 provide中的数据。
兄弟组件间通信
- 使用 eventBus 的方法,它的本质是通过创建一个空的 Vue 实例来作为消息传递的对象,通信的组件引入这个实例,通信的组件通过在这个实例上监听和触发事件,来实现消息的传递。
- 通过 $parent/$refs 来获取到兄弟组件,也可以进行通信。
任意组件之间
- 使用 eventBus ,其实就是创建一个事件中心,相当于中转站,可以用它来传递事件和接收事件。
如果业务逻辑复杂,很多组件之间需要同时处理一些公共的数据,这个时候采用上面这一些方法可能不利于项目的维护。这个时候可以使用 vuex ,vuex 的思想就是将这一些公共的数据抽离出来,将它作为一个全局的变量来管理,然后其他组件就可以对这个公共数据进行读写操作,这样达到了解耦的目的。
十三、路由的 hash 和 history 模式的区别
Vue-Router有两种模式:hash模式和history模式。默认的路由模式是hash模式。
1. hash模式
简介:hash模式是开发中默认的模式,它的URL带着一个#,例如:http://www.abc.com/#/vue,它的hash值就是#/vue。
特点:hash值会出现在URL里面,但是不会出现在HTTP请求中,对后端完全没有影响。所以改变hash值,不会重新加载页面。这种模式的浏览器支持度很好,低版本的IE浏览器也支持这种模式。hash路由被称为是前端路由,已经成为SPA(单页面应用)的标配。
原理:hash模式的主要原理就是onhashchange()事件:
window.onhashchange = function(event) {
console.log(event.oldURL, event.newURL);
let hash = location.hash.slice(1);
}使用onhashchange()事件的好处就是,在页面的hash值发生变化时,无需向后端发起请求,window就可以监听事件的改变,并按规则加载相应的代码。除此之外,hash值变化对应的URL都会被浏览器记录下来,这样浏览器就能实现页面的前进和后退。虽然是没有请求后端服务器,但是页面的hash值和对应的URL关联起来了。
2. history模式
简介:history模式的URL中没有#,它使用的是传统的路由分发模式,即用户在输入一个URL时,服务器会接收这个请求,并解析这个URL,然后做出相应的逻辑处理。
特点:当使用history模式时,URL就像这样:http://abc.com/user/id。相比hash模式更加好看。但是,history模式需要后台配置支持。如果后台没有正确配置,访问时会返回404。
API:history api可以分为两大部分,切换历史状态和修改历史状态:
- 修改历史状态:包括了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法,这两个方法应用于浏览器的历史记录栈,提供了对历史记录进行修改的功能。只是当他们进行修改时,虽然修改了url,但浏览器不会立即向后端发送请求。如果要做到改变url但又不刷新页面的效果,就需要前端用上这两个API。
- 切换历史状态:包括 forward()、back()、go() 三个方法,对应浏览器的前进,后退,跳转操作。
虽然history模式丢弃了丑陋的#。但是,它也有自己的缺点,就是在刷新页面的时候,如果没有相应的路由或资源,就会刷出404来。
如果想要切换到history模式,就要进行以下配置(后端也要进行配置):
const router = new VueRouter({
mode: 'history',
routes: [...]
})3. 两种模式对比
调用 history.pushState() 相比于直接修改 hash,存在以下优势:
- pushState() 设置的新 URL 可以是与当前 URL 同源的任意 URL;而 hash 只可修改 # 后面的部分,因此只能设置与当前 URL 同文档的 URL;
- pushState() 设置的新 URL 可以与当前 URL 一模一样,这样也会把记录添加到栈中;而 hash 设置的新值必须与原来不一样才会触发动作将记录添加到栈中;
- pushState() 通过 stateObject 参数可以添加任意类型的数据到记录中;而 hash 只可添加短字符串;
- pushState() 可额外设置 title 属性供后续使用
hash模式下,仅hash符号之前的url会被包含在请求中,后端如果没有做到对路由的全覆盖,也不会返回404错误;history模式下,前端的url必须和实际向后端发起请求的url一致,如果没有对用的路由处理,将返回404错误。
hash模式和history模式都有各自的优势和缺陷,还是要根据实际情况选择性的使用。
十四、对前端路由的理解
在前端技术早期,一个 url 对应一个页面,如果要从 A 页面切换到 B 页面,那么必然伴随着页面的刷新。这个体验并不好,不过在最初也是无奈之举——用户只有在刷新页面的情况下,才可以重新去请求数据。
后来,改变发生了——Ajax 出现了,它允许人们在不刷新页面的情况下发起请求;与之共生的,还有“不刷新页面即可更新页面内容”这种需求。在这样的背景下,出现了 SPA(单页面应用)。
SPA极大地提升了用户体验,它允许页面在不刷新的情况下更新页面内容,使内容的切换更加流畅。但是在 SPA 诞生之初,人们并没有考虑到“定位”这个问题——在内容切换前后,页面的 URL 都是一样的,这就带来了两个问题:
- SPA 其实并不知道当前的页面“进展到了哪一步”。可能在一个站点下经过了反复的“前进”才终于唤出了某一块内容,但是此时只要刷新一下页面,一切就会被清零,必须重复之前的操作、才可以重新对内容进行定位——SPA 并不会“记住”你的操作。
- 由于有且仅有一个 URL 给页面做映射,这对 SEO 也不够友好,搜索引擎无法收集全面的信息
为了解决这个问题,前端路由出现了。
前端路由可以帮助我们在仅有一个页面的情况下,“记住”用户当前走到了哪一步——为 SPA 中的各个视图匹配一个唯一标识。这意味着用户前进、后退触发的新内容,都会映射到不同的 URL 上去。此时即便他刷新页面,因为当前的 URL 可以标识出他所处的位置,因此内容也不会丢失。
那么如何实现这个目的呢?首先要解决两个问题:
- 当用户刷新页面时,浏览器会默认根据当前 URL 对资源进行重新定位(发送请求)。这个动作对 SPA 是不必要的,因为我们的 SPA 作为单页面,无论如何也只会有一个资源与之对应。此时若走正常的请求-刷新流程,反而会使用户的前进后退操作无法被记录。
- 单页面应用对服务端来说,就是一个URL、一套资源,那么如何做到用“不同的URL”来映射不同的视图内容呢?
从这两个问题来看,服务端已经完全救不了这个场景了。所以要靠咱们前端自力更生,不然怎么叫“前端路由”呢?作为前端,可以提供这样的解决思路:
- 拦截用户的刷新操作,避免服务端盲目响应、返回不符合预期的资源内容。把刷新这个动作完全放到前端逻辑里消化掉。
- 感知 URL 的变化。这里不是说要改造 URL、凭空制造出 N 个 URL 来。而是说 URL 还是那个 URL,只不过我们可以给它做一些微小的处理——这些处理并不会影响 URL 本身的性质,不会影响服务器对它的识别,只有我们前端感知的到。一旦我们感知到了,我们就根据这些变化、用 JS 去给它生成不同的内容。
十五、Vuex 的原理以及自己的理解
Vuex 的原理
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。每一个 Vuex 应用的核心就是 store(仓库)。“store” 基本上就是一个容器,它包含着你的应用中大部分的状态 ( state )。
- Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
- 改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样可以方便地跟踪每一个状态的变化。
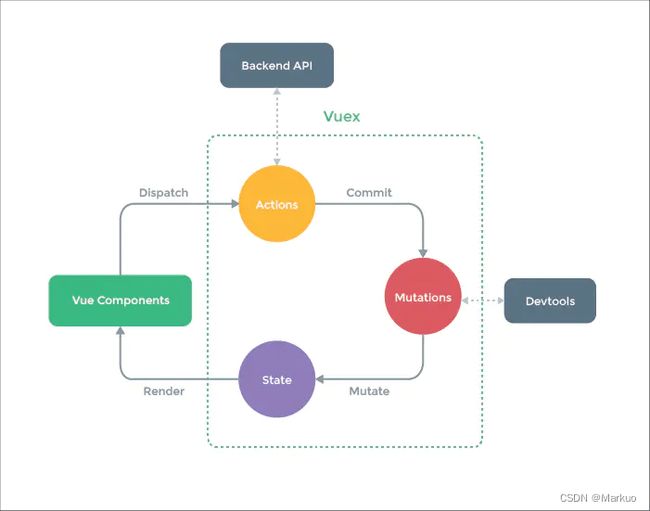
Vuex为Vue Components建立起了一个完整的生态圈,包括开发中的API调用一环。
(1)核心流程中的主要功能:
- Vue Components 是 vue 组件,组件会触发(dispatch)一些事件或动作,也就是图中的 Actions;
- 在组件中发出的动作,肯定是想获取或者改变数据的,但是在 vuex 中,数据是集中管理的,不能直接去更改数据,所以会把这个动作提交(Commit)到 Mutations 中;
- 然后 Mutations 就去改变(Mutate)State 中的数据;
- 当 State 中的数据被改变之后,就会重新渲染(Render)到 Vue Components 中去,组件展示更新后的数据,完成一个流程。
(2)各模块在核心流程中的主要功能:
- Vue Components∶ Vue组件。HTML页面上,负责接收用户操作等交互行为,执行dispatch方法触发对应action进行回应。
- dispatch∶操作行为触发方法,是唯一能执行action的方法。
- actions∶ 操作行为处理模块。负责处理Vue Components接收到的所有交互行为。包含同步/异步操作,支持多个同名方法,按照注册的顺序依次触发。向后台API请求的操作就在这个模块中进行,包括触发其他action以及提交mutation的操作。该模块提供了Promise的封装,以支持action的链式触发。
- commit∶状态改变提交操作方法。对mutation进行提交,是唯一能执行mutation的方法。
- mutations∶状态改变操作方法。是Vuex修改state的唯一推荐方法,其他修改方式在严格模式下将会报错。该方法只能进行同步操作,且方法名只能全局唯一。操作之中会有一些hook暴露出来,以进行state的监控等。
- state∶ 页面状态管理容器对象。集中存储Vuecomponents中data对象的零散数据,全局唯一,以进行统一的状态管理。页面显示所需的数据从该对象中进行读取,利用Vue的细粒度数据响应机制来进行高效的状态更新。
- getters∶ state对象读取方法。图中没有单独列出该模块,应该被包含在了render中,Vue Components通过该方法读取全局state对象。
十六、Vuex中action和mutation的区别
mutation中的操作是一系列的同步函数,用于修改state中的变量的的状态。当使用vuex时需要通过commit来提交需要操作的内容。mutation 非常类似于事件:每个 mutation 都有一个字符串的 事件类型 (type) 和 一个 回调函数 (handler)。这个回调函数就是实际进行状态更改的地方,并且它会接受 state 作为第一个参数:
const store = new Vuex.Store({
state: {
count: 1
},
mutations: {
increment (state) {
state.count++ // 变更状态
}
}
})当触发一个类型为 increment 的 mutation 时,需要调用此函数:
store.commit('increment')而Action类似于mutation,不同点在于:
- Action 可以包含任意异步操作。
- Action 提交的是 mutation,而不是直接变更状态。
const store = new Vuex.Store({
state: {
count: 0
},
mutations: {
increment (state) {
state.count++
}
},
actions: {
increment (context) {
context.commit('increment')
}
}
})Action 函数接受一个与 store 实例具有相同方法和属性的 context 对象,因此你可以调用 context.commit 提交一个 mutation,或者通过 context.state 和 context.getters 来获取 state 和 getters。
所以,两者的不同点如下:
- Mutation专注于修改State,理论上是修改State的唯一途径;Action业务代码、异步请求。
- Mutation:必须同步执行;Action:可以异步,但不能直接操作State。
- 在视图更新时,先触发actions,actions再触发mutation
- mutation的参数是state,它包含store中的数据;store的参数是context,它是 state 的父级,包含 state、getters
十七、Redux 和 Vuex 有什么区别,它们的共同思想
(1)Redux 和 Vuex区别
- Vuex改进了Redux中的Action和Reducer函数,以mutations变化函数取代Reducer,无需switch,只需在对应的mutation函数里改变state值即可
- Vuex由于Vue自动重新渲染的特性,无需订阅重新渲染函数,只要生成新的State即可
- Vuex数据流的顺序是∶View调用store.commit提交对应的请求到Store中对应的mutation函数->store改变(vue检测到数据变化自动渲染)
通俗点理解就是,vuex 弱化 dispatch,通过commit进行 store状态的一次更变;取消了action概念,不必传入特定的 action形式进行指定变更;弱化reducer,基于commit参数直接对数据进行转变,使得框架更加简易;
(2)共同思想
- 单—的数据源
- 变化可以预测
本质上:redux与vuex都是对mvvm思想的服务,将数据从视图中抽离的一种方案;
形式上:vuex借鉴了redux,将store作为全局的数据中心,进行mode管理;
十八、Vue3 有什么更新
(1)监测机制的改变
- 3.0 将带来基于代理 Proxy的 observer 实现,提供全语言覆盖的反应性跟踪。
- 消除了 Vue 2 当中基于 Object.defineProperty 的实现所存在的很多限制:
(2)只能监测属性,不能监测对象
- 检测属性的添加和删除;
- 检测数组索引和长度的变更;
- 支持 Map、Set、WeakMap 和 WeakSet。
(3)模板
- 作用域插槽,2.x 的机制导致作用域插槽变了,父组件会重新渲染,而 3.0 把作用域插槽改成了函数的方式,这样只会影响子组件的重新渲染,提升了渲染的性能。
- 同时,对于 render 函数的方面,vue3.0 也会进行一系列更改来方便习惯直接使用 api 来生成 vdom 。
(4)对象式的组件声明方式
- vue2.x 中的组件是通过声明的方式传入一系列 option,和 TypeScript 的结合需要通过一些装饰器的方式来做,虽然能实现功能,但是比较麻烦。
- 3.0 修改了组件的声明方式,改成了类式的写法,这样使得和 TypeScript 的结合变得很容易
(5)其它方面的更改
- 支持自定义渲染器,从而使得 weex 可以通过自定义渲染器的方式来扩展,而不是直接 fork 源码来改的方式。
- 支持 Fragment(多个根节点)和 Protal(在 dom 其他部分渲染组建内容)组件,针对一些特殊的场景做了处理。
- 基于 tree shaking 优化,提供了更多的内置功能。
十九、defineProperty和proxy的区别
Vue 在实例初始化时遍历 data 中的所有属性,并使用 Object.defineProperty 把这些属性全部转为 getter/setter。这样当追踪数据发生变化时,setter 会被自动调用。
Object.defineProperty 是 ES5 中一个无法 shim 的特性,这也就是 Vue 不支持 IE8 以及更低版本浏览器的原因。
但是这样做有以下问题:
- 添加或删除对象的属性时,Vue 检测不到。因为添加或删除的对象没有在初始化进行响应式处理,只能通过 $set 来调用 Object.defineProperty() 处理。
- 无法监控到数组下标和长度的变化。
Vue3 使用 Proxy 来监控数据的变化。Proxy 是 ES6 中提供的功能,其作用为:用于定义基本操作的自定义行为(如属性查找,赋值,枚举,函数调用等)。相对于 Object.defineProperty(),其有以下特点:
- Proxy 直接代理整个对象而非对象属性,这样只需做一层代理就可以监听同级结构下的所有属性变化,包括新增属性和删除属性。
- Proxy 可以监听数组的变化。
二十、对虚拟DOM的理解
从本质上来说,Virtual Dom是一个JavaScript对象,通过对象的方式来表示DOM结构。将页面的状态抽象为JS对象的形式,配合不同的渲染工具,使跨平台渲染成为可能。通过事务处理机制,将多次DOM修改的结果一次性的更新到页面上,从而有效的减少页面渲染的次数,减少修改DOM的重绘重排次数,提高渲染性能。
虚拟DOM是对DOM的抽象,这个对象是更加轻量级的对 DOM的描述。它设计的最初目的,就是更好的跨平台,比如Node.js就没有DOM,如果想实现SSR,那么一个方式就是借助虚拟DOM,因为虚拟DOM本身是js对象。 在代码渲染到页面之前,vue会把代码转换成一个对象(虚拟 DOM)。以对象的形式来描述真实DOM结构,最终渲染到页面。在每次数据发生变化前,虚拟DOM都会缓存一份,变化之时,现在的虚拟DOM会与缓存的虚拟DOM进行比较。在vue内部封装了diff算法,通过这个算法来进行比较,渲染时修改改变的变化,原先没有发生改变的通过原先的数据进行渲染。
另外现代前端框架的一个基本要求就是无须手动操作DOM,一方面是因为手动操作DOM无法保证程序性能,多人协作的项目中如果review不严格,可能会有开发者写出性能较低的代码,另一方面更重要的是省略手动DOM操作可以大大提高开发效率。
二十一、DIFF算法的原理
在新老虚拟DOM对比时:
- 首先,对比节点本身,判断是否为同一节点,如果不为相同节点,则删除该节点重新创建节点进行替换
- 如果为相同节点,进行patchVnode,判断如何对该节点的子节点进行处理,先判断一方有子节点一方没有子节点的情况(如果新的children没有子节点,将旧的子节点移除)
- 比较如果都有子节点,则进行updateChildren,判断如何对这些新老节点的子节点进行操作(diff核心)
- 匹配时,找到相同的子节点,递归比较子节点
在diff中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从O(n3)降低值O(n),也就是说,只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
二十二、Vue的优点
- 轻量级框架:只关注视图层,是一个构建数据的视图集合,大小只有几十 kb 。
- 简单易学:国人开发,中文文档,不存在语言障碍 ,易于理解和学习。
- 双向数据绑定:保留了 angular 的特点,在数据操作方面更为简单。
- 组件化:保留了 react 的优点,实现了 html 的封装和重用,在构建单页面应用方面有着独特的优势。
- 视图,数据,结构分离:使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作。
- 虚拟DOM:dom 操作是非常耗费性能的,不再使用原生的 dom 操作节点,极大解放 dom 操作,但具体操作的还是 dom 不过是换了另一种方式。
- 运行速度更快:相比较于 react 而言,同样是操作虚拟 dom,就性能而言, vue 存在很大的优势。