ClickHouse入门实战
ClickHouse入门实战到进阶
- 一、ClickHouse简介
- 二、ClickHouse单机版安装
-
- 2.1、安装准备环境
- 2.2、单机安装
- 2.3、ClickHouse一些默认路径
- 2.4、ClickHouse端口说明
- 三、数据类型
- 四、表引擎
-
- 4.1 MergeTree
-
- 4.1.1 partition by 分区
- 4.1.2 primary key 主键
- 4.1.3 order by 排序
- 4.1.4 二级索引(跳数索引)
- 4.1.5 数据TTL(过期时间)
- 4.2 ReplacingMergeTree
- 4.3 SummingMergeTree
- 五、sql增删改查
-
- 5.1 insert
- 5.2 Update 和 Delete
- 5.3 SELECT
- 5.3 alter操作
- 六、一些sql优化点
- 七、ClickHouse遇到的一些奇葩问题
-
- 1、ClickHouse服务起不来
一、ClickHouse简介
对于其他乱起八糟的简介,我就不写了,只写干货.ClickHouse总结一个字:快
1、ClickHouse是列式数据库,特别适合大数据量对列的聚合,计数,求和等统计操作原因优于行式存储, 数据量可以大到10亿到百亿级别。
2、真正的列式数据库管理系统,ClickHouse不单单是一个数据库, 它是一个数据库管理系统。因为它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务。
3、常见列式数据库HBase,BigTable,Cassandra,HyperTable。在这些列式数据库中,你可以得到每秒数十万的吞吐能力,但是无法得到每秒几亿行的吞吐能力。
4、数据压缩,由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重,由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间。
5、ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。高性能自然需要高配服务器。
点击进入: ClickHouse官网文档
二、ClickHouse单机版安装
2.1、安装准备环境
2.1.1、Centos 取消打开文件数限制
vim /etc/security/limits.conf
vim /etc/security/limits.d/20-nproc.conf
##编辑上面两个文件,添加下面内容,记得两个文件都添加,在文件末尾添加
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
2.1.2、安装ClickHouse依赖环境
yum install -y libtool
yum install -y *unixODBC*
2.1.3、CentOS 取消 SELINUX
#修改/etc/selinux/config 中的 SELINUX=disabled
vim /etc/selinux/config
2.2、单机安装
2.2.1、安装包准备
可自行去官网把下图中的四个安装包下载下来, 下载地址:http://repo.red-soft.biz/repos/clickhouse/stable/el7/
2.2.2、安装
上传到centos中的某一目录中,在目录中执行如下命令。rpm -ivh *.rpm

查看安装情况
sudo rpm -qa|grep clickhouse
2.2.3、修改配置文件
把
vim /etc/clickhouse-server/config.xml
2.2.4、启动clickhouse
注意,启动clickhouse是开机自启的。
#查看clickhouse状态
systemctl status clickhouse-server
#启动clickhouse
systemctl start clickhouse-server
#重启clickhouse
systemctl restart clickhouse-server
#查看防火墙状态
systemctl status firewalld.service
#暂时关闭防火墙
systemctl stop firewalld.service
#永久关闭防火墙
systemctl disable firewalld.service
#使用该命令,是禁制clickhouse开机自启,不过一般我们都是需要开机自启,
#所以不执行下面这条命令了
systemctl disable clickhouse-server
2.2.5、终端链接clickhouse,终端进入数据库命令
#如果在上面没设置默认密码,执行clickhouse-client -m即可
clickhouse-client -m
#如果在上面设置了默认密码,执行clickhouse-client --password,然后按回车输入密码,就可以进入了
clickhouse-client --password
#查看数据库
show databases;
#进入指定数据库
use defalut;
#查询库里面的所有表
show tables;
2.3、ClickHouse一些默认路径
bin/ ====> /usr/bin/ #可执行文件路径
conf/ ====> /etc/clickhouse-server #配置文件路径
lib/ ====> /var/lib/clickhouse #数据存放路径
log/ ====> /var/log/clickhouse #日志路径
2.4、ClickHouse端口说明
1、9000是clickhouse-client使用的端口,一般咱们通过命令行链接,使用9000端口。2、8123是HTTP连接clickhouse使用的端口,一般用第三方工具,比如java客户端,或者DBever客户端连接,都用8123端口。
3、记得一定要关闭centos防火墙哦。
三、数据类型
和其他语言的数据类型都相似,我就不一一说了,官方文档上写的很好,参考下官网: https://clickhouse.com/docs/zh/sql-reference/data-types四、表引擎
4.1 MergeTree
MergeTree 引擎是ClickHouse中最常用的,地位相当于mysql的innodb,下面介绍下MergeTree引擎的一些特性
建表语句
create table t_student_mg(
id UInt32,
stu_id String,
total_score Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,stu_id);
插入数据
insert into t_student_mg values
(101,'stu_001',500,'2023-06-01 12:00:00') ,
(102,'stu_002',520,'2023-06-01 11:00:00'),
(102,'stu_004',666,'2023-06-01 12:00:00'),
(102,'stu_002',720,'2023-06-01 13:00:00'),
(102,'stu_002',222,'2023-06-01 13:00:00'),
(102,'stu_002',555,'2023-06-02 12:00:00');
4.1.1 partition by 分区
分区非必选的属性。
1、分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理, 即一个线程处理一个分区内的数据,单条查询就能利用整机所有 CPU。极致的并行处理能力,极大的降低了查询延时。说明ClickHouse在高性能的同时,是需要高服务器的。2、分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区,也可以指定为Tuple(),以单表一亿数据为例,分区大小控制在10-30个为最佳。
3、那些有相同分区表达式值的数据片段才会合并。这意味着 你不应该用太精细的分区方案(超过一千个分区)。否则,会因为文件系统中的文件数量过多和需要打开的文件描述符过多,导致 SELECT 查询效率不佳。
4、还有就是一般我们都是使用的是日期作为分区键,同一分区内有序,不同分区不能保证有序。
5、分区数据合并,任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作。 ClickHouse 也可以手动合并分区,手动把临时分区合并到已有分区中
#手动合并分区命令
optimize table 表名称 final;
4.1.2 primary key 主键
主键是非必选的属性。
1、ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引(稀疏索引),但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。2、index granularity指的是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
3、稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描。实际稀疏索引就是某种形式的二分查找,能够定位到对应的 index granularity,避免了全表扫描
4.1.3 order by 排序
排序是必选的属性。
1、order by 排序,是对分区内的排序
2、主键必须是 order by 字段的前缀字段,比如 order by 字段是 (id,stu_id) 那么主键必须是 id 或者(id,stu_id)。
4.1.4 二级索引(跳数索引)
二级索引是非必选的属性。
后面讲哈,基本很少用到,即使用到,不会也没关系4.1.5 数据TTL(过期时间)
数据TTL是非必选的属性。
1、ClickHouse中分为表级TTL和列级TTL, 表级TTL就是表中的某些行数据到期了,会自动删除;列级TTL则是对表中的某些字段设置过期时间,一旦过期,表中的该字段则会变成0。2、只谈表级TTL,因为列级TTL基本很少用,用的时候百度下就可以了。
3、涉及判断的字段,下面语句的create_time, 必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
4、建表时,指定表级TTL, 下面语句中,说明只保留create_time值是1月内的数据。
5、使用过期时间的单位:SECOND、MINUTE、MINUTE、DAY、WEEK、MONTH、QUARTER YEAR
6、下面语句中,最后写的DELETE,可以不写,因为默认就是DELETE。 DELETE表示到期了自动删除。 还可以写成TO VOLUME 'a' 或TO DISK 'a' 都表示将数据移动到磁盘 a上; 写成GROUP BY 表示聚合过期行。
create table t_student_mg2(
id UInt32,
stu_id String,
total_score Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,stu_id)
TTL create_time + INTERVAL 1 MONTH DELETE
4.2 ReplacingMergeTree
1、ReplacingMergeTree是基于MergeTree 延申出的一个表引擎,它存储特性完全继承 MergeTree,只是多了一个去重的功能。 虽然 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree。去重按照order by的字段去重
2、数据的去重只会在合并的过程中出现;去重只会在分区内部进行去重,不能执行跨分区的去重。3、eplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的。下面sql中数据如果去重,保留create_time最大的数据。如果create_time相同则按插入顺序保留最后一笔。 如果不填版本字段,默认按照插入顺序保留最后一条。
#表创建
create table t_student_mg3(
id UInt32,
sku_id String,
total_score Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
4.3 SummingMergeTree
1、 对于不查询明细,只关心以维度进行汇总聚合结果的场景。如果只使用普通的MergeTree的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。ClickHouse 为了这种场景,提供了一种能够“预聚合”的引擎 SummingMergeTree。该引擎聚合的依据依然是 order by 的字段,相当于按照 order by 的字段做了一次 Group By
2、以 SummingMergeTree()中指定的列作为汇总数据列,可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列。
以order by 的列为准,作为维度列。
不在一个分区的数据不会被聚合。
只有在同一批次插入(第一次插入)或分片合并时才会进行聚合
create table t_student_mg4(
id UInt32,
sku_id String,
total_score Decimal(16,2) ,
create_time Datetime
) engine =SummingMergeTree(total_score)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id );
4、查sql时有可能还没得到汇总值,因为可能包含一些还没来得及聚合数据。
如果要是获取汇总值,还是需要使用 sum 进行聚合,这样效率会有一定的提高,但本身 ClickHouse 是列式存储的,效率提升不是很高。
五、sql增删改查
5.1 insert
1、和Mysql语法一致#标准sql插入语句
insert into [table_name] values(…),(….)
#从表到表的插入
insert into [table_name] select a,b,c from [table_name_2]
5.2 Update 和 Delete
1、ClickHouse 支持 Delete 和 Update ,但是删除和更新是一种很重的操作,且不支持事务。 之所以说重,是因为每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。#删除语句
alter table t_student_mg delete where stu_id ='stu_001';
#更新语句
alter table t_student_mg update total_score=toDecimal32(2000,2) where id = 102;
5.3 SELECT
1、 ClickHouse 基本上与MySQL 差别不大,可以按照Mysql语句写。2、支持子查询
3、支持各种 JOIN,但是 JOIN 操作无法使用缓存, 尽量避免使用 JOIN,所以即使是两次相同的 JOIN 语句,ClickHouse 也会视为两条新 SQL
4、GROUP BY 操作增加了 with rollup \ with cube \ with total 用来计算小计和总计。
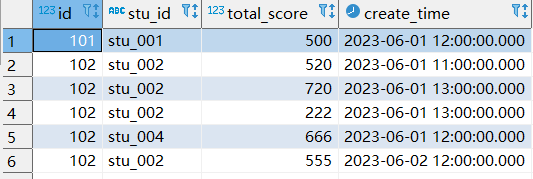
#该sql查询如下图所示
SELECT * from t_student_mg;
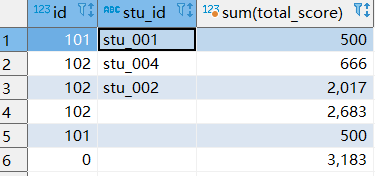
下面查询是从右至左去掉维度,前三条是正常分组查的,第四第五条是去掉stu_id维度统计的,也就是以Id为维度统计的。第六条是去掉stu_id,id统计的,也就是所有数据在一个组内统计的。
select id , stu_id,sum(total_score) from t_student_mg group by id,stu_id with rollup;
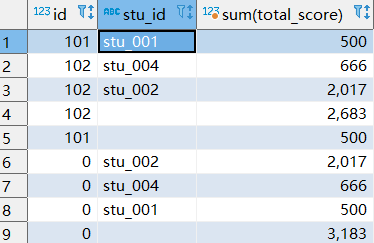
select id , stu_id,sum(total_score) from t_student_mg group by
id,stu_id with cube;
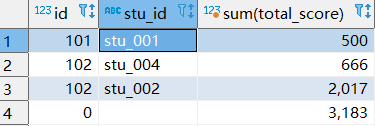
select id , stu_id,sum(total_score) from t_student_mg group by
id,stu_id with totals;
5.3 alter操作
1、alert操作指的是通过sql,修改、新增、删除表的字段。#新增字段,after col1指的是新增的字段在col1字段后面
alter table tableName add column newcolname String after col1;
#修改字段类型
alter table tableName modify column 字段名称 String;
#删除字段
alter table tableName drop column 字段名称;
六、一些sql优化点
七、ClickHouse遇到的一些奇葩问题
1、ClickHouse服务起不来
开机后发现clickHouse服务起不来,具体查看了下日志信息,如下图所示:

日志说是/var/lib/clickhouse/store/f66/f66f1f2e-cc4d-47ea-b33d-f0cabf63aa63/202304_93_93_0目录损坏了
处理方法:
进入到损坏的目录 cd /var/lib/clickhouse/store 执行mv f66/ f66_bak命令,不用担心/f66目录下的文件,clickhouse会重新生成个f66目录的,然后clickhouse就正常启动了