【音频分离】demucs V3的环境搭建及训练(window)
文章目录
- 一、环境搭建
-
- (1)新建虚拟环境,并进入
- (2)安装pyTorch
- (3)进入代码文件夹,批量安装包
- (4)安装其他需要的包
- 二、数据集准备
-
- (1)下载数据集
- (2)修改配置参数
- (3)创建微调数据集
- (4)解压outputs.tar.gz
- 三、训练
-
- (1)默认,cpu
- (2)默认,gpu
- (3)修改参数,gpu
- 四、推理
-
- (1)模型导出
- (2)模型评估
- (3)推理
- 报错
-
- (1)soundfile.LibsndfileError: Error opening 'C:\\Users\\Lenovo\\AppData\\Local\\Temp\\tmps0ogpyqy.wav': System error.
- (2)FileNotFoundError: [WinError 2] 系统找不到指定的文件。
- (3)TypeError: beat_track() takes 0 positional arguments but 1 positional argument (and 2 keyword-only arguments) were given
- (4)TypeError: chroma_cqt() takes 0 positional arguments but 1 positional argument (and 1 keyword-only argument) were given
- (5)numpy.core._exceptions._ArrayMemoryError: Unable to allocate 1.11 GiB for an array with shape (54134, 1377) and data type complex128
- (6)UserWarning:The version_base parameter is not specified.
- (7)FileNotFoundError: Caught FileNotFoundError in DataLoader worker process 0.
- (8)torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 562.00 MiB (GPU 0; 15.99 GiB total capacity; 14.06 GiB already allocated; 0 bytes free; 14.72 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
- (9)WARNING:__main__:Model 81de367c has less epoch than expected (8 / 360)
- 写在最后
代码下载
这是一个音频提取、分离的项目
一、环境搭建
(1)新建虚拟环境,并进入
conda create -n demucs python=3.8
activate demucs

(2)安装pyTorch
到pyTorch官网选择对应配置
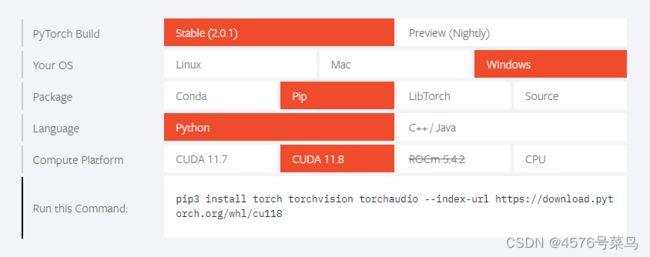
这个是我的配置
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118

(3)进入代码文件夹,批量安装包

d:
cd D:\data\cqZhang\demucs-3
pip install -r requirements.txt
(4)安装其他需要的包
pip install librosa
二、数据集准备
(1)下载数据集
使用Musdb HQ 数据集
获取路径有:
https://zenodo.org/record/3338373
https://www.kaggle.com/datasets/ayu055/musdb18hq
数据集可以放在“\checkpoint\defossez\datasets\musdbhq”路径下,
这与代码原来的位置应该是一致的
(2)修改配置参数
- The
dset.musdbkey insideconf/config.yaml. - The variable
MUSDB_PATHinsidetools/automix.py.

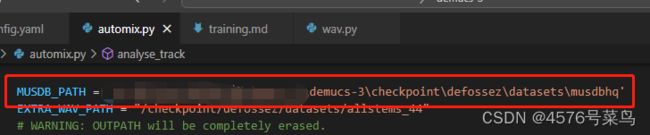
我本来使用的是相对路径,但是他貌似找不到,后来改成绝对路径
其他的路径也一样,如果找不到,就要改成绝对路径
(3)创建微调数据集
原来的命令是export NUMBA_NUM_THREADS=1; python3 -m tools.automix,但它是linux上的命令,
将其改为set NUMBA_NUM_THREADS=1 && python -m tools.automix
运行结束会在项目目录下产生tmp文件夹,里面有新的数据集
修改 conf/config.yaml.中的 dset.musdb
修改 conf/dset/auto_mus.yaml 中的 dset.wav ( OUTPATH)
(4)解压outputs.tar.gz
tar xvf outputs.tar.gz
三、训练
训练有三种命令
我只尝试了第二种
(1)默认,cpu
dora info -f 81de367c
this will show the hyper-parameter used by a specific XP.
Be careful some overrides might present twice, and the right most one will give you the right value for it.
这将显示特定XP使用的超参数。
请注意,有些覆盖可能会出现两次,最正确的一次将为您提供正确的值。
(2)默认,gpu
dora run -d -f 81de367c

注意:如果修改了数据集,要在目录下删除metadata文件夹,否则会出错。
run an XP with the hyper-parameters from XP 81de367c.
-dis for distributed, it will use all available GPUs.
使用XP 81de367c中的超参数运行XP。
-d是分布式的,它将使用所有可用的GPU。
(3)修改参数,gpu
dora run -d -f 81de367c hdemucs.channels=32
start from the config of XP 81de367c but change some hyper-params.
This will give you a new XP with a new signature (here 3fe9c332).
从XP 81de367c的配置开始,但更改了一些超参数。
这将为您提供一个带有新签名的新XP(此处为3fe9c332)。
四、推理
(1)模型导出
python -m tools.export 81de367c

(2)模型评估
python -m tools.test_pretrained --repo ./release_models -n 81de367c

(3)推理
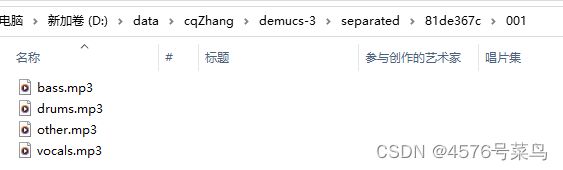
python -m demucs --repo ./release_models -n 81de367c --mp3 D:\data\cqZhang\001.mp3

保存位置./separated
报错
(1)soundfile.LibsndfileError: Error opening ‘C:\Users\Lenovo\AppData\Local\Temp\tmps0ogpyqy.wav’: System error.

在linux上运行会创建一个临时文件,且程序退出后该临时文件会自动删除,
但是在windows上运行时,不能打开创建的临时文件,
Whether the name can be used to open the file a second time, while the named temporary file is still open, varies across platforms (it can be so used on Unix; it cannot on Windows NT or later).
在命名的临时文件仍然打开的情况下,该名称是否可以用于第二次打开文件,因平台而异(它可以在Unix上使用;不能在Windows NT或更高版本上使用)。
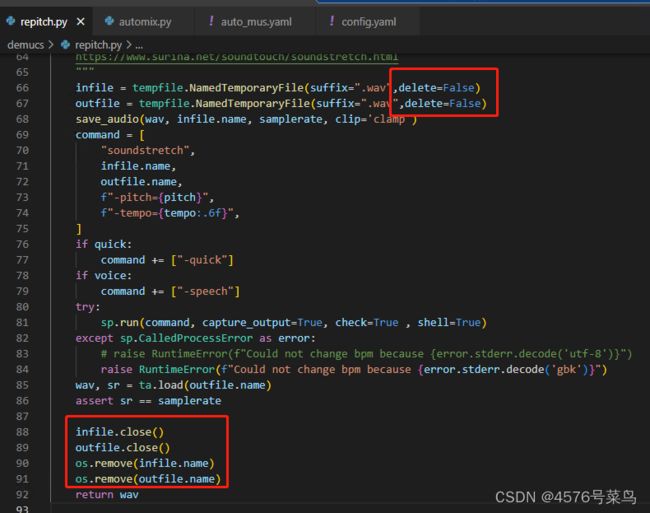
处理:
方法1. 更改临时文件保存方式(不保存到系统的临时文件夹里)
方法2. 增加参数:delete=False,手动删除
我采用方法2
执行后会报其他错误,这是另一个问题了

(2)FileNotFoundError: [WinError 2] 系统找不到指定的文件。

出现这个错误,原因大概有三种:
1、先查看路径是否正确
2、再查看该文件是否存在
3、如果还没解决问题,最后很可能就是该命令在dos环境内无法使用
处理:
根据实际情况,我判断是第三种问题
到这里下载一个程序,
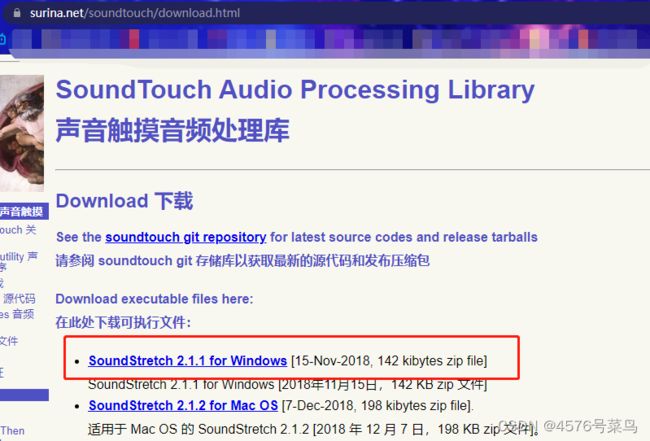
解压后放在项目目录下

已经成功执行了
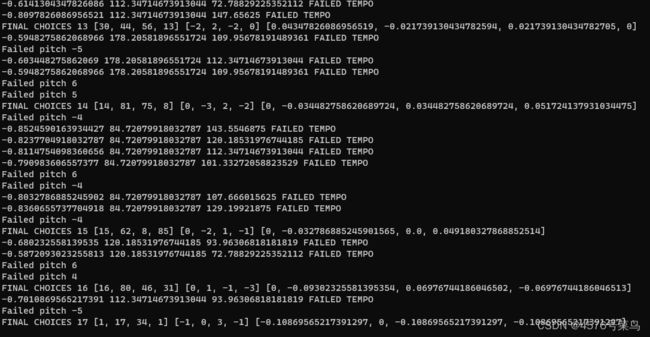
(3)TypeError: beat_track() takes 0 positional arguments but 1 positional argument (and 2 keyword-only arguments) were given
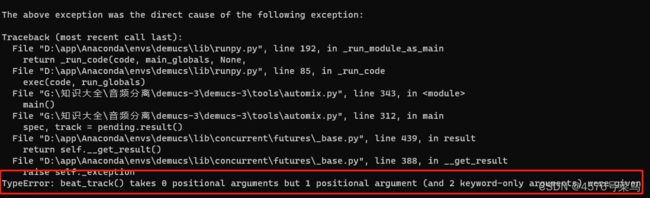
说是参数个数不匹配的问题,其实并不是
处理:
# 将下列代码
tempo, events = beat_track(drums.numpy(), units='time', sr=SR)
# 改为
tempo, events = beat_track(y=drums.numpy(), units='time', sr=SR)

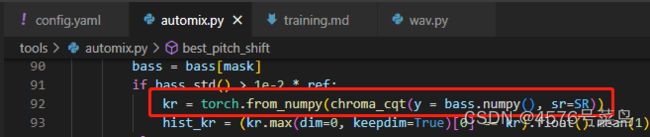
(4)TypeError: chroma_cqt() takes 0 positional arguments but 1 positional argument (and 1 keyword-only argument) were given

这个问题与上面那个问题一样
说是参数个数不匹配的问题,其实并不是
处理:
# 将下列代码
kr = torch.from_numpy(chroma_cqt(bass.numpy(), sr=SR))
# 改为
kr = torch.from_numpy(chroma_cqt(y = bass.numpy(), sr=SR))
(5)numpy.core._exceptions._ArrayMemoryError: Unable to allocate 1.11 GiB for an array with shape (54134, 1377) and data type complex128
内存不足
这个我没有去思考如何减少内存的使用
也许减小数据集有效
我的处理方式是:换一台大内存的机器
它的内存需求不超过40g
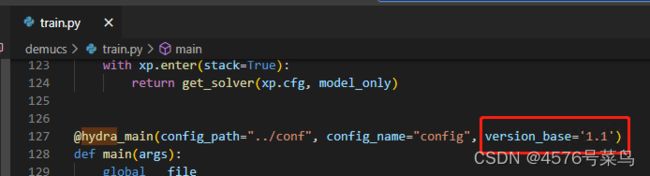
(6)UserWarning:The version_base parameter is not specified.

这是一个版本警告,其实无关紧要
完整的警告如下:
D:\app\anaconda\envs\demucs\lib\site-packages\dora\hydra.py:279: UserWarning:
The version_base parameter is not specified.
Please specify a compatability version level, or None.
Will assume defaults for version 1.1
with initialize_config_dir(str(self.full_config_path), job_name=self._job_name,
处理:
加上参数version_base='1.1'
(7)FileNotFoundError: Caught FileNotFoundError in DataLoader worker process 0.
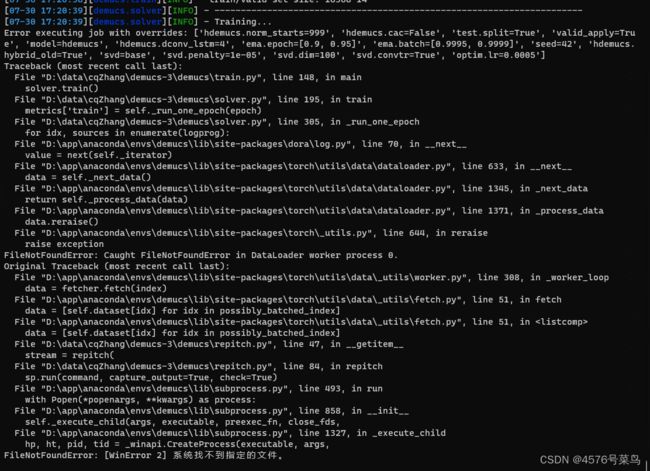
处理:
首先我在demucs/repitch的sp.run()中加入参数shell=True

再次运行dora run -d -f 81de367c,报错信息出现变化
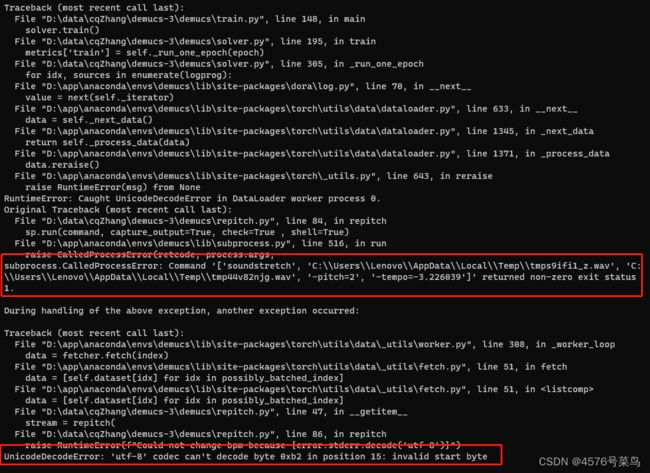
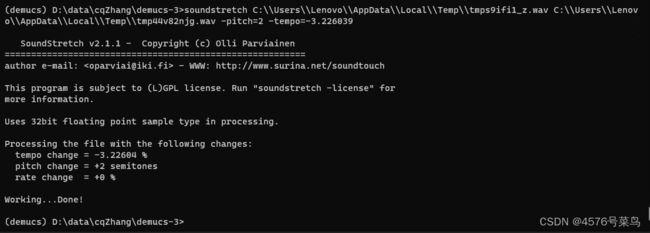
我运行命令soundstretch C:\\Users\\Lenovo\\AppData\\Local\\Temp\\tmps9ifi1_z.wav C:\\Users\\Lenovo\\AppData\\Local\\Temp\\tmp44v82njg.wav -pitch=2 -tempo=-3.226039,执行成功
说明文件其实是存在的,但是不知道为啥不能执行成功
第二处应该是编码格式的问题,我将raise RuntimeError(f"Could not change bpm because {error.stderr.decode('utf-8')}")修改为raise RuntimeError(f"Could not change bpm because {error.stderr.decode('gbk')}")解决

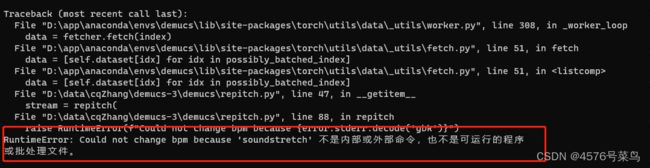
这可能就是报错的主要原因了
将soundstretch放到下面目录
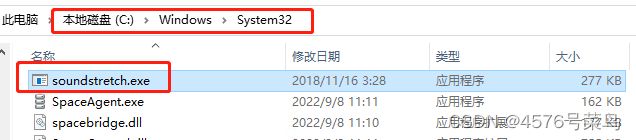
运行出现一下结果,应该是没问题了。(内存不足修改batch_size)

(8)torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 562.00 MiB (GPU 0; 15.99 GiB total capacity; 14.06 GiB already allocated; 0 bytes free; 14.72 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
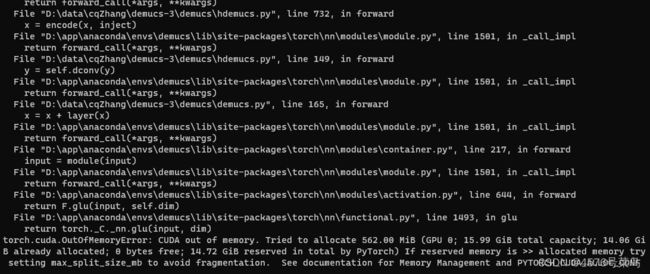
处理:
修改conf/config.yaml里的batch_size
默认64,但是我只有16G的显存,设置成4,目前恰好运行,不知道能不能运行到结束。

##(9)FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。
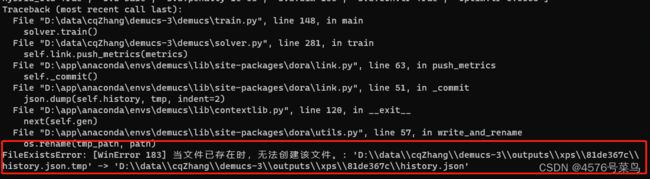
处理:
方法1:修改重命名方式,改成强制覆盖
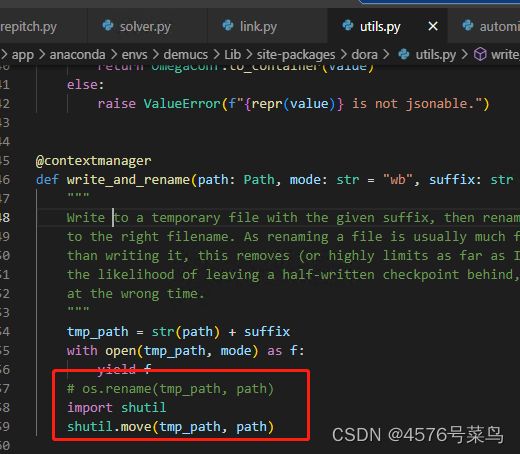
方法2:在重命名前删除已有文件
方法3:修改命名方式,比如加上日期时间
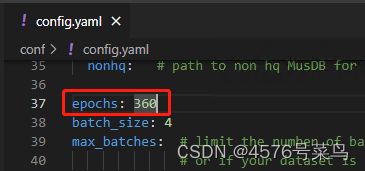
(9)WARNING:main:Model 81de367c has less epoch than expected (8 / 360)

模型没有训练够就想导出。
处理:
只是一个警告,不理会也没关系。
介意的话,把这里改小即可。
写在最后
写一半的时候有其他的事,停了大半个月
现在又有事了,匆匆忙忙把推理部分写上
后面有机会再补充
有机会尝试自己构造数据集训练