高级 IO
目录
前言
什么是IO?
有哪些IO的的方式呢?
五种IO模型
这五种模型在特性有什么差别呢?
其他高级IO
非阻塞IO
fcntl
实现函数SetNonBlock
I/O多路转接之select
初识select
select函数
参数说明:
关于timeval结构
函数返回值:
关于fd_set结构
理解select执行过程
select的特点
I/O多路转接之poll
poll函数接口
参数说明:
events和revents的取值:编辑
返回结果:
poll的优点
poll的缺点
I/O多路转接之epoll
epoll初识
epoll的相关系统调用
epoll_create
epoll_ctl
epoll_wait
epoll工作原理
epoll工作方式
对比LT和ET
理解ET模式和非阻塞文件描述符
epoll的使用场景
简洁版的Reactor

前言
什么是IO?
Input,Output,不就是IO嘛,站在体系结构的角度,把数据从外设搬到内存就是Input,把数据从内存拷贝到外设就是Output。你说的没错,但是理解的还不够深刻,只有理解了什么是IO,才有可能理解什么是高效的IO?
当我们在网络中发送数据时,用write来发送,用read来读取。但是有没有发现一个问题,之前说过在应用层调用 write,并不是直接将数据发送到网络中,而是将数据从应用层拷贝到传输层中的发送缓冲区中,所以write的本质是拷贝;当然调用 read 也并不是直接从网络中读取数据,而是将数据从传输层的接收缓冲区中拷贝到应用层,所以read也是拷贝函数。
那么问题来了,你想拷贝就拷贝吗?这句话什么意思呢?比如说调用read,你就一定能读取到数据吗?
答案是不一定,比如接收缓冲区里并没有数据,那么read 去读取时并不能读到数据,并且read还会被阻塞住。我们知道读取和发送的本质是拷贝,但是拷贝是有条件的,以读取为例,接收缓冲区中要有数据,read才能把数据从内核空间拷贝到用户空间并返回。
那什么是阻塞呢? 阻塞的核心本质就是在等待资源就绪。
那么等待什么资源就绪呢? 以read为例,就是等待接收缓冲区中有资源。
这里我们不能简简单单的认为读取就是拷贝,因为还需要等待资源就绪,而发送/写入也一样。
那么可以得出一个结论:IO的本质就是 等 + 数据拷贝 。
什么是高效IO呢?
因为数据拷贝是操作系统做的事,没有特殊情况的话数据拷贝的时间一般都是固定的。所以高效IO的本质就是 减少等的比重 。
有哪些IO的的方式呢?
举例子:
知道钓鱼吧,我们先去除钓鱼的一些准备工作和繁琐事项,认为钓鱼只有两个动作:等 + 把鱼从河里拉上来放到自己的鱼篓里。这里有个前提:鱼咬钩了之后就不会在跑了。
在一个很大的河边,有这么几个人在钓鱼,每个人都有自己的钓鱼方式:
- 1. 张三,他专心致志的盯着自己的鱼漂,等鱼上钩立马就把鱼拉上来放到鱼篓里,然后再次下钩,盯着鱼漂。
- 2. 李四,他下了钩之后,稍微等了一下,看鱼没上钩,他就一会玩游戏,一会刷视频,一会看新闻,一会四处转转,一会再看看鱼上钩了没,总之一直在干不同的事;干了一会别的事,再次看鱼漂的时候发现鱼上钩了,就把鱼拉上来放到鱼篓里,然后下钩,继续干着他的事。
- 3. 王五,他下了钩之后,也是稍微等了一下,看鱼没上钩,他就干别的事去了(比如肝游戏的每日任务),但是王五的鱼漂很特殊,它上面有一个铃铛,有鱼上钩时铃铛就会响;过了一会铃铛响了,王五看了一眼,把手上的事放下,然后把鱼拉上来放到鱼篓里,继续下钩,下完钩后,再继续干他自己刚才的事。
- 4. 赵六,他在河边放了一排鱼竿,然后全部下钩,他就在这一排鱼竿里来回走动,检查鱼有没有上钩;过了一会,他检查某个鱼竿时,发现鱼上钩了,就把鱼拉上来放到鱼篓里,然后下钩,继续检查下一个鱼竿;
- 5. 田七,他自己因为有点事,不能钓鱼了,就雇佣了小齐帮他钓鱼,小齐的钓鱼方式跟张三差不多;田七去忙自己的事了,小齐就在那里钓鱼。过了一上午,小齐钓了好多鱼,就给田七打电话说,老板我钓好多鱼了,你有时间把鱼拿走处理了吧。田七说好,过了一段时间田七把鱼拿走了,就把鱼分给七大姑八大姨了吃了。
那么有个问题,你认为谁的效率高呢?
这里我们认为一段时间内谁钓的鱼多,谁的效率就高,那么无论是张三、李四、王五、还是田七,他都只有一个鱼竿,而赵六有很多个鱼竿,那么赵六的效率就一定比其他人要高很多。为什么?前面说过我们认为钓鱼就两个动作:等 + 上鱼;因为赵六等的时间比重比较低,所以他的效率就高。
这几个人分别对应的IO模型是:
张三 :阻塞式IO
李四 :非阻塞式IO
王五 : 信号驱动IO
赵六 :IO多路转接
田七 :异步IO
五种IO模型
- 阻塞IO: 在内核将数据准备好之前,系统调用会一直等待。所有的套接字,默认都是阻塞方式。阻塞IO是最常见的IO模型。

- 非阻塞IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回,并且返回EWOULDBLOCK错误码。非阻塞IO往往需要程序员循环的方式反复尝试读写文件描述符, 这个过程称为轮询。 这对CPU来说是较大的浪费, 一般只有特定场景下才使用。

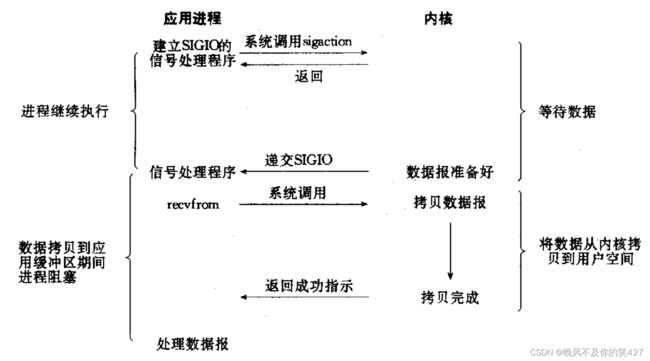
信号驱动IO:内核将数据准备好的时候,使用SIGIO信号通知应用程序进行IO操作 。
- IO多路转接:虽然从流程图上看起来和阻塞IO类似, 实际上最核心在于IO多路转接能够同时等待多个文件描述符的就绪状态。

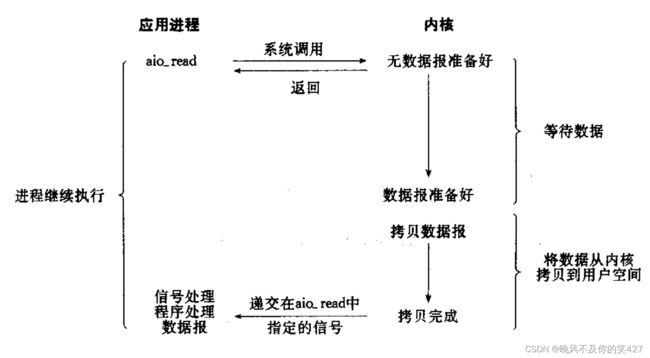
- 异步IO:由内核在数据拷贝完成时,通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据)。
别看有这么多的模型,常用的还是阻塞式IO。
这五种模型在特性有什么差别呢?
- 阻塞IO、非阻塞IO、信号驱动IO,这三个在效率上没有差别,为什么这么说,因为在某种事件就绪前,它们三个都在等;而事件就绪之后,它们都做出了相应的动作;那么它们三个在其他方面有差别吗?当然有,从整体来看 非阻塞IO 和 信号驱动IO 它们两在等的时候可以做其他事情。
- 阻塞IO、非阻塞IO、信号驱动IO、IO多路转接,这四个它们都参与了IO的过程,也就是等 + 数据拷贝(它们是切身实地的在河边),所以这几个统称同步IO。
- 异步IO并没有参与 IO 两个阶段中的任意一个阶段;它只是发起事件,并没有参与事件,所以他被叫做异步IO。
阻塞IO、非阻塞IO有什么差别呢?
- 共同点:都进行了数据拷贝
- 不同点:等待的方式不同
这里的同步IO和多进程/多线程的同步有什么关系吗?
没有任何关系,所以以后看到同步时要看前提条件是什么,线程同步:让多线程执行具有一定的顺序性;IO同步:是否参与IO的过程。
其他高级IO
非阻塞IO,纪录锁,系统V流机制, I/O多路转接(也叫I/O多路复用),readv和writev函数以及存储映射IO(mmap),这些统称为高级IO。
本篇文章重点说明IO多路转接
非阻塞IO
fcntl
操作文件描述符,默认方式是阻塞IO。
传入的cmd的值不同,后面追加的参数也不相同。
fcntl函数有5种功能:
- 复制一个现有的描述符(cmd = F_DUPFD)。
- 获得/设置文件描述符标记(cmd = F_GETFD 或 F_SETFD)。
- 获得/设置文件状态标记(cmd = F_GETFL 或 F_SETFL)。
- 获得/设置异步I/O所有权(cmd = F_GETOWN 或 F_SETOWN)。
- 获得/设置记录锁(cmd = F_GETLK,F_SETLK 或 F_SETLKW)。
我们这里只用第三种功能,获取/设置文件状态标记,就可以将一个文件描述符设置为非阻塞。
用read读取数据时,默认是阻塞式,所以内核的接收缓冲区中没有数据,read会被阻塞。

实现函数SetNonBlock
基于fcntl,我们实现一个SetNoBlock函数, 将文件描述符设置为非阻塞。
使用F_GETFL将当前的文件描述符的属性取出来(这是一个位图),然后再使用F_SETFL将文件描述符设置回去,设置回去的同时,加上一个O_NONBLOCK参数。
#include
#include
#include
#include
#include
#include
#include
using namespace std;
void SetNoBlock(int fd)
{
int fl = fcntl(fd, F_GETFL);//获取文件描述符属性
if(fl < 0)
{
std::cerr << "fcntl: " << strerror(errno) << std::endl;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK); //将该文件描述符fd,设置为非阻塞
}
int main()
{
SetNoBlock(0);
while (true)
{
printf(">>> ");
fflush(stdout);
char buffer[1024];
int n = read(0, buffer, sizeof(buffer) - 1);
if (n > 0)
{
buffer[n] = 0;
cout << "echo#" << buffer << endl;
}
else if (n == 0)
{
cout << "read end" << endl;
break;
}
else
{
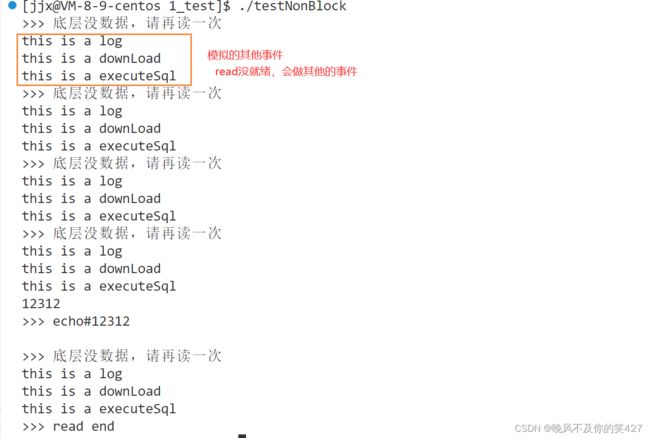
// 1.当我不输入时,底层没有数据算错误吗? 不算,只是以错误的形式返回
// 2.我又如何区分是真的错了还是底层没数据? 单靠返回值无法区分,
if(errno == EAGAIN)
{
cout << "底层没数据,请再读一次 " << endl;
}
else if(errno == EINTR) //因为某些原因,中断读取,所以重新读取
{
continue;
}
else
{
cout << "result:" << n << "errno:" << strerror(errno) << endl;
break;
}
}
sleep(1);
}
return 0;
} 
I/O多路转接之select
初识select
系统提供select函数来实现多路复用输入/输出模型。select系统调用是用来让我们的程序监视多个文件描述符的状态变化的,程序会停在select这里等待,直到被监视的文件描述符有一个或多个发生了状态改变。
select函数

参数说明:
- 参数nfds是需要监视的最大的文件描述符值+1;
- rdset、wrset、exset分别对应于需要检测的可读文件描述符的集合,可写文件描述符的集合及异常文件描述符的集合;
- 参数timeout为结构timeval,用来设置select()的等待时间;
参数timeout取值:
- NULL:则表示select()没有timeout, select将一直被阻塞,直到某个文件描述符上发生了事件;(阻塞)
- 0:仅检测描述符集合的状态,然后立即返回,并不等待外部事件的发生;(非阻塞)
- 特定的时间值:如果在指定的时间段里没有事件发生, select将超时返回。(特定时间内阻塞,每隔一个时间段返回一次)
关于timeval结构
timeval结构用于描述一段时间长度,如果在这个时间内,需要监视的描述符没有事件发生则函数返回,返回值为0。
函数返回值:
- 执行成功则返回文件描述符状态已改变的个数,也就是说有几个描述符就绪了,就返回几;
- 如果返回0代表在描述符状态改变前已超过timeout时间,没有返回,表示超时返回了;
- 当有错误发生时则返回-1,错误原因存于errno,此时参数readfds, writefds, exceptfds和timeout的值变成不可预测,代表可能函数调用失败了。
错误值可能为:
- EBADF 文件描述词为无效的或该文件已关闭;
- EINTR 此调用被信号所中断;
- EINVAL 参数n 为负值;
- ENOMEM 核心内存不足。
那么select未来要关心的事件只有三类:1.读 2.写 3.异常 ,对于任何一个fd都是这三种。
关于fd_set结构
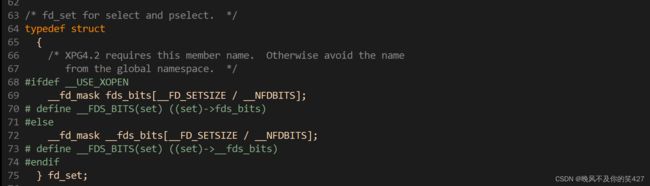
![]() 其实这个结构就是一个整数数组,更严格的说,是一个 "位图"。 使用位图中对应的位来表示要监视的文件描述符。
其实这个结构就是一个整数数组,更严格的说,是一个 "位图"。 使用位图中对应的位来表示要监视的文件描述符。
因为参数是输入输出型,所以输入代表的是用户告诉内核,这个集合上的设置文件描述符事件你要关心;输出代表内核告诉用户,你让我关心的多个文件描述符中哪个就绪了。这个输入输出型参数是为了让用户和内核之间的相互沟通,互相知晓对方要的或关心的。
操作系统也提供了一组操作fd_set的接口,来比较方便的操作位图。
- void FD_CLR(int fd, fd_set *set); // 用来清除描述词组set中相关fd 的位
- int FD_ISSET(int fd, fd_set *set); // 用来测试描述词组set中相关fd 的位是否为真
- void FD_SET(int fd, fd_set *set); // 用来设置描述词组set中相关fd的位
- void FD_ZERO(fd_set *set); // 用来清除描述词组set的全部位
理解select执行过程
理解select模型的关键在于理解fd_set,为说明方便,取fd_set长度为1字节, fd_set中的每一bit可以对应一个文件描述符fd,则1字节长的fd_set最大可以对应8个fd。
- 执行fd_set set, FD_ZERO(&set),则set用位表示是0000,0000;
- 若fd= 5,执行FD_SET(fd,&set),后set变为0001,0000(第5位置为1);
- 若再加入fd= 2, fd=1,则set变为0001,0011;
- 执行select(6,&set,0,0,0)阻塞等待;
- 若fd=1,fd=2上都发生可读事件,则select返回,此时set变为0000,0011。
注意:没有事件发生的fd=5被清空。
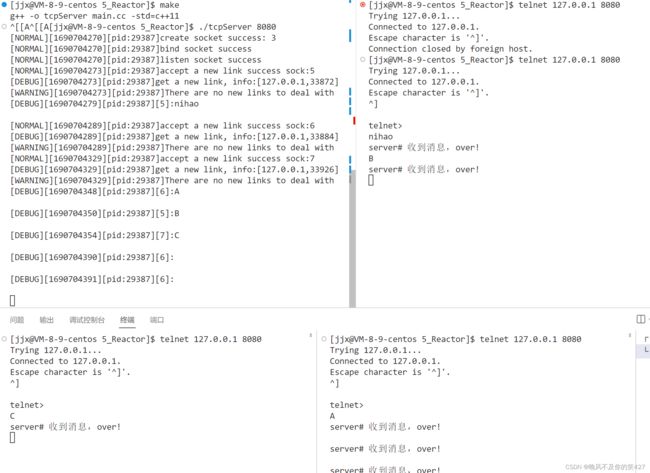
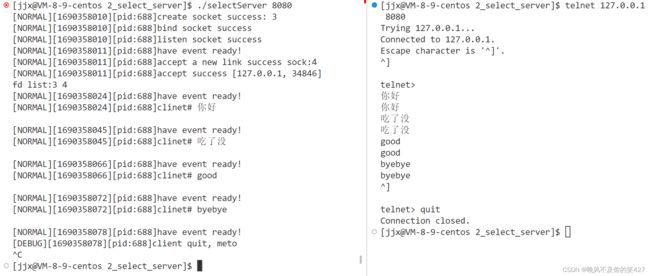
基于select实现一个从网络中读取数据并反显的服务器(只关心读取):因为代码分了几个文件不好直接体现,所以有兴趣的自己去Gitee上看吧。
lesson15/2_select_server · 晚风不及你的笑/MyCodeStorehouse - 码云 - 开源中国 (gitee.com)
这里用telnet充当客户端。
select的特点
- 能同时等待的文件描述符是有上限的,取决与sizeof(fd_set)的值,服务器上sizeof(fd_set)= 128,每bit表示一个文件描述符,则我服务器上支持的最大文件描述符是128*8=1024。
- 将fd加入select监控集的同时,还要再使用一个数据结构array保存放到select监控集中的fd。
- select的大部分参数是输入输出型的,,调用select之前,要重新设置所有的fd,调用之后还要检查更新所有fd,在用户层来看,这么多个循环遍历,这都是成本。
- select为什么第一个参数是最大的fd+1呢? select怎么知道事件就绪了呢,当然是通过遍历去确定,因为select是系统调用,所以这个参数在内核层面上来看是确定遍历范围。
- select采用位图的方式,用户到内核,内核到用户就要来回的进行数据拷贝,拷贝成本的问题在fd很多时会很大。
- 每次调用select,都需要手动设置fd集合, 从接口使用角度来说也非常不便。
I/O多路转接之poll
poll也是一种Linux中多路转接的方案。poll 的作用和select的作用也是一样的:等待。
但是poll解决了一些问题:
1. poll解决了select的fd有上限的问题;
2.poll解决了select每次调用都要重新设置关心的fd的问题。
poll函数接口

参数说明:
- fds是一个poll函数监听的结构列表,每一个元素中,包含了三部分内容:文件描述符、监听的事件集合(输入)、 返回的事件集合(输出)。
- nfds表示fds数组的长度;
- timeout表示poll函数的超时返回的时间, 单位是毫秒(ms);timeout > 0:在timeout内阻塞,超出timeout返回一次,timeout == 0:非阻塞等待,timeout < 0:阻塞等待。
从第一个参数的结构可以看到输入输出是分离的,代表poll不需要对参数重新设定了。
为什么说它解决了select的fd有上限的问题呢?因为这里传的是数组的长度,也就是说只要你想,数组有多大,这个fd就可以有多少。那么有人说了这不还是有上限嘛,这个上限属于是你系统的上限而不是像select那样的上限。
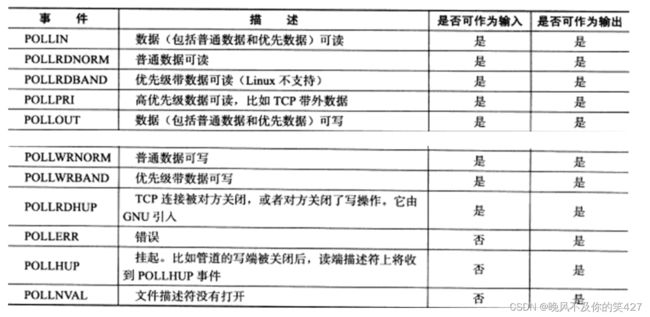
events和revents的取值:
返回结果:
返回值小于0, 表示出错;
返回值等于0, 表示poll函数等待超时;
返回值大于0, 表示poll由于监听的文件描述符就绪而返回。
在之前select的服务器基础上进行修改:
lesson15/3_poll_server · 晚风不及你的笑/MyCodeStorehouse - 码云 - 开源中国 (gitee.com)

poll的优点
- 不同与select使用三个位图来表示三个fdset的方式, poll使用一个pollfd的指针实现;
- pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式,接口使用比select更方便。
- poll并没有最大数量限制 (但是数量过大后性能也是会下降)
poll的缺点
poll中监听的文件描述符数目增多时
- 和select函数一样, poll返回后,需要轮询pollfd来获取就绪的描述符;
- 每次调用poll都需要把大量的pollfd结构从用户态拷贝到内核中;
- 同时连接的大量客户端在一时刻可能只有很少的处于就绪状态, 因此随着监视的描述符数量的增长,其效率也会线性下降。
I/O多路转接之epoll
epoll初识
按照man手册的说法: 是为处理大批量句柄而作了改进的poll。
它是在2.5.44内核中被引进的(epoll(4) is a new API introduced in Linux kernel 2.5.44) 它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
epoll的相关系统调用
epoll 有3个相关的系统调用
头文件: #include
epoll_create
int epoll_create(int size);
说明:
- 创建一个epoll的句柄,成功返回一个文件描述符,失败返回-1,错误码被设置。
- 自从linux2.6.8之后, size参数是被忽略的,只要 > 0 即可。
- 用完之后,必须调用close()关闭.
epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll的事件注册函数,它不同于select,select是在监听事件时告诉内核要监听什么类型的事件, 而是在这里先注册要监听的事件类型。
参数说明:
- 第一个参数是epoll_create()的返回值(epoll的句柄);
- 第二个参数表示动作,用三个宏来表示。
EPOLL_CTL_ADD :注册新的fd到epfd中;
EPOLL_CTL_MOD :修改已经注册的fd的监听事件;
EPOLL_CTL_DEL : 从epfd中删除一个fd;
- 第三个参数是需要监听的fd;
- 第四个参数是告诉内核需要监听什么事。
struct epoll_event结构如下:

events可以是以下几个宏的集合:
- EPOLLIN : 表示对应的文件描述符可以读 (包括对端SOCKET正常关闭);
- EPOLLOUT : 表示对应的文件描述符可以写;
- EPOLLPRI : 表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
- EPOLLERR : 表示对应的文件描述符发生错误;
- EPOLLHUP : 表示对应的文件描述符被挂断;
- EPOLLET : 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的;
- EPOLLONESHOT:只监听一次事件, 当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里。
返回值: 成功返回0,失败返回-1,错误码被设置。
epoll_wait
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
收集在epoll监控的事件中已经就绪的事件。
参数说明:
- 第一个参数是epoll_create()的返回值;
- 第二个参数events是分配好的epoll_event结构体数组,是一个输出型参数。epoll将会把就绪的事件赋值到events数组中 (events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)。
- 第三个参数 maxevents告诉内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size。
- 第四个参数timeout是超时时间 (单位毫秒, 0是非阻塞, -1是阻塞式,>0是时间内阻塞,超时返回一次)。
函数返回值:
和select、poll函数的返回值一样,如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时, 返回小于0表示函数调用失败。
epoll工作原理

当某一进程调用epoll_create方法时, Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关:
struct eventpoll{
....
/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
struct rb_root rbr;
/*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
struct list_head rdlist;
....
}; 每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件;这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当响应的事件发生时会调用这个回调方法。
这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表(就绪队列)中。在epoll中,对于每一个事件,都会建立一个epitem结构体。
struct epitem{
struct rb_node rbn;//红黑树节点
struct list_head rdllink;//双向链表节点
struct epoll_filefd ffd; //事件句柄信息
struct eventpoll *ep; //指向其所属的eventpoll对象
struct epoll_event event; //期待发生的事件类型
}当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表(就绪队列)中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户,这个操作的时间复杂度是O(1)。
细节:
- epoll_wait将所有就绪的事件,按照顺序放到用户传入的数组中;比如有5个文件描述符的事件就绪,那么数组的前5个就是按照就绪的先后顺序存放的。
- 如果就绪队列中有很多数据节点,一次拿不完怎么办? 因为是就绪队列,先进先出嘛,拿不完也没事,下次再继续拿就好了。
- 为什么说epoll高效呢,是因为他把这些操作主体都交给了操作系统去做,而select和poll主要工作是程序员自己做。
在前面代码的基础上进行修改,也只支持连接和读取,LT模式:
lesson15/4_epoll_server · 晚风不及你的笑/MyCodeStorehouse - 码云 - 开源中国 (gitee.com)

什么叫做事件就绪?
底层IO条件满足了,可以进行某种IO行为了,就叫做事件就绪。
那么select、poll、epoll的这些多路转接的方式都叫做IO就绪事件的通知机制,那么这个通知机制有没有策略呢?有,下面接着看。
epoll工作方式
epoll有2种工作方式-水平触发(LT)和边缘触发(ET)。epoll默认状态下就是LT工作模式。
举个例子:有个快递员叫张三,今天给你送快递,你的快递很多,他给你打电话叫你下楼取快递,你满口答应,但是手头上的事还没做完,想等做完再下去;过了一小会,张三见你没下来,又给你打电话叫你赶紧下来取快递,你答应着,但是继续忙着自己的事,张三就一直给你打电话,直到你下楼取快递,但是快递很多,一次取不完;你刚到家,老板打来电话,叫你改东西,要的很急;你只好赶紧改东西,过了一小会,张三电话打来了,你快递没取完呢,赶紧下来取,你又继续答应着,然后忙自己的事,张三就跟之前一样过一会给你打一个电话,直到你把快递取完才不给你打电话了。这个张三就是水平触发,用代码演示一下,比如我们监听listen套接字,但是有连接到来时,并不对这个连接 accept ,此时就会一直报有事件就绪了(如下图),直至你把你把就绪事件捞走。

又有一个快递员叫李四,也同样给你送快递,到了你楼下,给你打了一个电话,说你这次不下来,我就不给你打电话了,你后面要是再想取快递就等下一次或者别人给你送了;然后你忙着呢,哪有空管快递,然后李四等了一会你没下来,他就走了,给别人送快递去了;然后今天你又有新快递到驿站了,李四送完一车,回到站点取下一车快递发现有你的,就会又给你送一次,依旧是同样的话,你不下来我就走了;这次你知道你不下来的话,这快递你就只能等明天送或者有新快递了才送,然后你赶紧下来把快递去了。李四就叫做边缘触发。也就是说有事件就绪只会通知一次,倒逼着你赶紧把所有的就绪事件捞走,这次不拿只能等下一次有新事件就绪了才会在通知你。
就这么来看的话ET的效率要比LT效率高,因为它只通知一次,倒逼着你必须把数据一次性读完。

看下图,设置了ET模式后,连接到来只通知一次。

select和poll其实也是工作在LT模式下, epoll既可以支持LT, 也可以支持ET。
对比LT和ET
ET模式下底层只有在数据从无到有或从有到多的情况下才会通知上层,而且只会通知一次,所以这就到逼着程序员将本轮就绪的数据全部读取到上层,那么你怎么知道你本次就绪的数据全部读取完了呢?
循环读取,直到读不出数据了,那这里有个问题,一般的文件描述符都是阻塞式的,也就是说你读取到最后一次时会被阻塞住,这种情况是不符合要求的呀,所以就要求ET模式对应的文件描述符必须是非阻塞式的。
那么LT模式下文件描述符可以是阻塞式也可以是非阻塞式,那么LT模式可不可以模仿ET的工作方式呢?当然可以啦,那有人会问了,那既然LT可以模仿ET,还要ET有什么用呢?直接一个LT不就得了?
我们要知道这两个模式并不是说谁更好,而是看使用场景,有些场景LT模式更好,有些场景ET更好。
ET模式的高效不仅仅体现在通知机制上,而是倒逼着让上层尽快的把数据取走,数据取走后,TCP就可以给发送端提供更大的窗口大小,从而让对方更新出更大的滑动窗口,这个滑动窗口大了,数据发送的吞吐量就大了,也就提高了底层的数据发送效率,更好的利用诸如TCP延迟应答等策略。
TCP报头8个标记位中psh标记位的作用是什么?让底层的数据事件就绪,再让上层知道。
理解ET模式和非阻塞文件描述符
使用 ET 模式的 epoll, 需要将文件描述设置为非阻塞。这个不是接口上的要求, 而是 "工程实践" 上的要求。
假设这样的场景:服务器接受到一个10k的请求,会向客户端返回一个应答数据,如果客户端收不到应答, 不会发送第二个10k请求。

如果服务端写的代码是阻塞式的read, 并且一次只 read 1k 数据的话(read不能保证一次就把所有的数据都读出来,参考 man 手册的说明, 可能被信号打断), 剩下的9k数据就会待在缓冲区中。
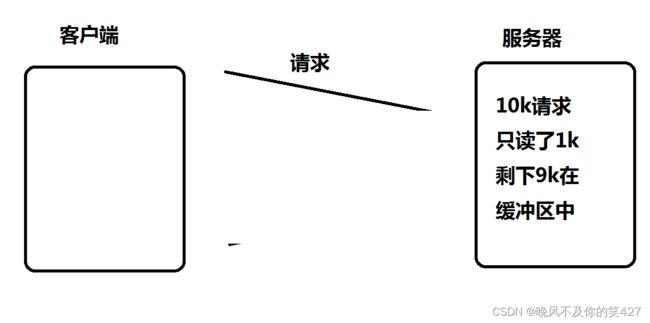
此时由于服务器的 epoll 是ET模式, 并不会认为文件描述符读就绪, epoll_wait 就不会再次返回, 剩下的 9k 数据会一直在缓冲区中, 直到下一次客户端再给服务器写数据, epoll_wait 才能返回。
但是问题来了:
服务器只读到1k个数据,要10k读完才会给客户端返回响应数据;
客户端要读到服务器的响应,才会发送下一个请求;
客户端发送了下一个请求, epoll_wait 才会返回,才能去读缓冲区中剩余的数据;
所以,为了解决上述问题(阻塞read不一定能一下把完整的请求读完), 于是就可以使用非阻塞轮训的方式来读缓冲区,保证一定能把完整的请求都读出来;而如果是LT没这个问题, 只要缓冲区中的数据没读完, 就能够让 epoll_wait 返回文件描述符读就绪。
epoll的使用场景
epoll的高性能, 是有一定的特定场景的。 如果场景选择的不适宜, epoll的性能可能适得其反。对于多连接,且多连接中只有一部分连接比较活跃时,比较适合使用epoll。
例如:典型的一个需要处理上万个客户端的服务器, 例如各种互联网APP的入口服务器, 这样的服务器就很适合epoll。如果只是系统内部, 服务器和服务器之间进行通信, 只有少数的几个连接, 这种情况下用epoll就并不合适。具体要根据需求和场景特点来决定使用哪种IO模型。
简洁版的Reactor
是一个半同步半异步的模式,只是负责通知就绪事件和IO,不做业务处理;业务处理可以自己实现。
lesson15/5_Reactor · 晚风不及你的笑/MyCodeStorehouse - 码云 - 开源中国 (gitee.com)