《Opencv入门到项目实战》(一):Opencv安装及图像基本操作
文章目录
- 0.Opencv介绍及环境配置
- 1.图像读取
-
- 1.1 彩色图像读取
- 1.2 灰色图像读取
- 2.视频读取
- 3.ROI读取
-
- 3.1 图形切片处理
- 3.2 提取颜色通道
- 4.图像填充
- 5.数值运算与图像融合
-
- 5.1 加法运算
- 5.2 图像融合
- 6. 总结
0.Opencv介绍及环境配置
OpenCV是一个强大的计算机视觉库,它提供了丰富的函数和工具,可用于图像处理、特征提取、目标检测、机器学习等各种计算机视觉任务。接下来我们主要介绍使用Opencv进行图形处理,首先我们要配置好对应的环境。大家在网上可以搜到各种各样的教程,这里我的环境如下
python3.6, opencv-contrib-python3.4.1.15,opencv-python3.4.1.15
大家可以根据自己的python环境自习安装对应的版本。
以我的环境为例,安装命令如下
pip install opencv-python==3.4.1.15
pip install opencv-contrib-python==3.4.1.15
1.图像读取
接下来我们来看在opencv当中,图像最基本的操作。
首先,我们得先知道计算机是如何看一张图像的
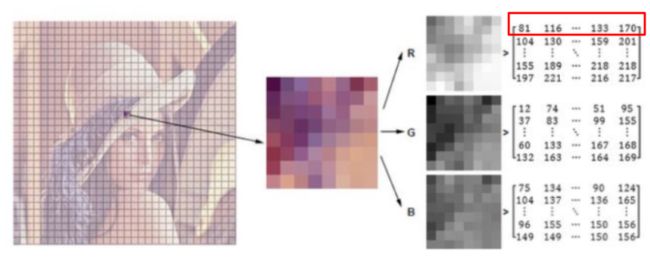
我们来观察这个图,我们把它叫做丽娜,我们把图片分成了很多很多小方格,然后我们拿出其中的一个方格观察一下。在这个方格当中,我们的每一个就是一个大区域,它是有很多个小块儿所组成的,其中的每一个小格,它叫做一个像素点,计算机当就是由这些像素点来构成一张图像的,那像素点又是什么呢?
其实,它就是一个值,我们来看最右边,每一个矩阵里边儿的组成,各种值,例如81,116,…,133,170。它们就是构成像素点的每一个值了,而这个数值大小意味着什么呢?
在计算机当中,每一个像素点的值是在0-255之间进行浮动的,表示该点亮度,0表示很亮,255表示很暗
然后我们再来看R、G、B三个通道,每一个彩色图都是由RGB三颜色通道组成的,然后每一个矩阵分别对应每一个通道的亮度。对于灰度图而言,就只有一个通道来表示亮度。
这些像素点组成了一个矩阵,这个矩阵就表示图像的大小,例如我们假设矩阵是300×300,那相应的rgb三个通道都是300×300,因此整个图形的维度就是(300,300,3)
1.1 彩色图像读取
当我们要分析一张图片时,首先就是读取它转换成一个矩阵的格式,下面我们正式看一下如何读取图片
import cv2 #opencv读取的格式是BGR
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
img=cv2.imread('yangqi.jpg')
在这里我们先导入cv2,然后找到你要读取的图片地址,我这里用的是我们家小狗的图片,他的名字叫洋气,‘yangqi.jpg’,使用cv.imread()函数就会把这张图像读进来。
我们来看一下它的结果是什么
img
array([[[ 99, 141, 148],
[ 95, 137, 144],
[ 78, 120, 127],
...,
[ 69, 88, 103],
[ 81, 100, 113],
[ 88, 107, 120]],
[[ 93, 137, 144],
[ 49, 93, 100],
[ 86, 130, 137],
...,
[175, 197, 209],
[195, 217, 229],
[200, 222, 234]],
[[ 30, 76, 84],
[ 23, 66, 75],
[ 72, 115, 124],
...,
[ 43, 65, 77],
[ 42, 64, 76],
[ 43, 65, 77]],
...,
[[178, 209, 232],
[158, 189, 212],
[154, 185, 206],
...,
[ 68, 78, 85],
[ 54, 64, 71],
[ 83, 93, 100]],
[[164, 195, 216],
[138, 169, 190],
[168, 197, 218],
...,
[ 84, 94, 101],
[ 92, 102, 109],
[ 87, 97, 104]],
[[167, 196, 217],
[129, 158, 179],
[102, 131, 152],
...,
[101, 111, 118],
[124, 134, 141],
[ 96, 106, 113]]], dtype=uint8)
img.shape
(238, 218, 3)
可以看到,它返回的是一个ndarray的结构,纬度为(238, 218, 3),因为我们这里是一张彩色图片,所以有三个通道。
现在我们已经把图像数据给读进来了,有些时候就是随着我们对图像进行处理,例如边缘检测,或者是一些更复杂的操作。在做操作过程当中,我们想观察一下,这个图像它变换成什么样子了,因此我们需要展示图像,我们可以用matplotlib或者cv2,但是需要注意的是openCV默认读取是BGR的格式,所以在读取的时候,如果我们要用matplotlib的话需要进行相应的转变。我们这里全部都用openCV自带的函数来展示。这里我们利用cv.imshow()函数,传入两个参数,第一个参数表示窗口的名称,第二个函数就是我们要读取的图像数据,也就是我们刚刚得到的那个矩阵
#图像展示
cv2.imshow('cat',img)
cv2.waitKey(0) # 等待时间,0表示按任意键结束
cv2.destroyAllWindows()

为了方便使用,我们定义函数cv_show(),以后就直接调用这个函数来进行图像读取
def cv_show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
1.2 灰色图像读取
在opencv中,默认都是进行彩色图像读取,有的时候我们想要读取灰度图,在这里我们指定cv2.IMREAD_GRAYSCALE
img=cv2.imread('yangqi.jpg',cv2.IMREAD_GRAYSCALE)
img
array([[138, 134, 117, ..., 90, 102, 109],
[134, 90, 127, ..., 198, 218, 223],
[ 73, 64, 113, ..., 66, 65, 66],
...,
[212, 192, 188, ..., 79, 65, 94],
[198, 172, 200, ..., 95, 103, 98],
[199, 161, 134, ..., 112, 135, 107]], dtype=uint8)
img.shape
(238, 218)
可以看到现在的数据变成了一个二维矩阵了,此时是一个单通道,我们再次读取
cv2.imshow('cat2',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

可以看出现在这个图片就变成灰白了
2.视频读取
视频读取其实和我们图像读取类似,我们先把视频进行拆分,拆分成其中的每一帧,然后基于每一帧图像去做。下面我们具体来看一下如何使用opencv读取视频,首先找到你要读取的视频路径,然后调用cv2.VideoCapture()函数得到视频流,然后我们使用isOpened()来判断是否能打开,如果能打开,使用vc.read()一帧一帧的读取视频信息,然后返回两个值,open为布尔值,frame为读取的每一帧的图像数据
vc = cv2.VideoCapture('test.mp4')
# 检查是否打开正确
if vc.isOpened():
oepn, frame = vc.read()
else:
open = False
while open:
ret, frame = vc.read()
if frame is None:
break
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #转换成黑白图
cv2.imshow('result', gray)#显示每一帧图像
if cv2.waitKey(100) & 0xFF == 27:#等待时间
break
vc.release()
cv2.destroyAllWindows()
3.ROI读取
3.1 图形切片处理
接下来我们来看,当我拿到一张图像时,有的时候我只对某一个区域感兴趣,例如我们刚刚小狗yangqi图片,我可能想要观察的是中间的某一个特定区域,这就是region of interest(ROI)读取,如下所示,我们对图形进行切片处理,得到它的左上部分结果。
img=cv2.imread('yangqi.jpg')
dog=img[0:50,0:200]
cv_show('yangqi',dog)

3.2 提取颜色通道
有的时候我们需要对图像进行一些特殊的分析,假设一个彩色图像,它是由三个颜色通道组成,BGR(Opencv默认顺序)。在openCV当中,我们可以使用cv2.split()把三个通道分别提取出来看一下
b,g,r=cv2.split(img)
这样我们得到了每一个通道的数据
r.shape,b.shape,g.shape
((238, 218), (238, 218), (238, 218))
可以看到每一个通道都是一个二维矩阵。在我们切片完处理之后,我们希望再将其组合在一起,我们可以直接调用cv2.merge(),注意我们的顺序是BGR
img=cv2.merge((b,g,r))#顺序为bgr
img.shape
我们前面一直说彩色图片有三个通道,那么每个通道的图像是怎样的呢?我们接下来分别来看看。首先,我们只看R通道的图像,那么我们设置B,G通道对于的像素点值全为0
tmp_img = img.copy()
tmp_img[:,:,0] = 0#第一个通道B全部设为0
tmp_img[:,:,1] = 0#第二个通道G全部设为0
cv_show('Red',tmp_img)

可以看到得到了一张红色图片,下面类似的操作可以分别得到蓝色和绿色的结果
tmp_img = img.copy()
tmp_img[:,:,0] = 0
tmp_img[:,:,2] = 0
cv_show('Green',tmp_img)

tmp_img = img.copy()
tmp_img[:,:,1] = 0
tmp_img[:,:,2] = 0
cv_show('Blue',tmp_img)

4.图像填充
接下来我们讨论一下图像填充,这个也比较常见,我们之间在介绍卷积的时候说了padding,它就是在图像在边界进行填充。下面我们就介绍一下使用Opencv来填充图像的一些方法
top_size,bottom_size,left_size,right_size = (100,100,100,100)#要填充的大小
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE) #复制法
reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_REFLECT) #反射法
reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101) #反射法101
wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP) #外包装法
constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_CONSTANT, value=0) #常数填充,0表示黑色
BORDER_REPLICATE:复制法,直接复制最边缘的像素BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制,例如,原始为1234,那么我们复制的方法为321|1234|432BORDER_REFLECT_101:反射法101,以最边缘像素为轴进行对称复制,例如,原始为1234,那么我们复制的方法为432|1234|321BORDER_WRAP:外包装法,例如原始为1234,复制为234|1234|123BORDER_CONSTANT:常量法,常数值填充。
查看结果
import matplotlib.pyplot as plt
plt.subplot(231), plt.imshow(img, 'gray'), plt.title('ORIGINAL')
plt.subplot(232), plt.imshow(replicate, 'gray'), plt.title('REPLICATE')
plt.subplot(233), plt.imshow(reflect, 'gray'), plt.title('REFLECT')
plt.subplot(234), plt.imshow(reflect101, 'gray'), plt.title('REFLECT_101')
plt.subplot(235), plt.imshow(wrap, 'gray'), plt.title('WRAP')
plt.subplot(236), plt.imshow(constant, 'gray'), plt.title('CONSTANT')
plt.show()

5.数值运算与图像融合
接下来我们来看一下在Opencv中的基本数值运算,我们先读取两张图像,yangqi和另一只猫的图片cat
img_dog=cv2.imread('yangqi.jpg')
img_cat=cv2.imread('cat.jpg')
5.1 加法运算
img_cat2= img_cat +10
img_cat[:5,:,0]
array([[142, 146, 151, ..., 156, 155, 154],
[107, 112, 117, ..., 155, 154, 153],
[108, 112, 118, ..., 154, 153, 152],
[139, 143, 148, ..., 156, 155, 154],
[153, 158, 163, ..., 160, 159, 158]], dtype=uint8)
然后我们对cat加10,这相当于在每个像素点都加10.
img_cat2[:5,:,0]
array([[152, 156, 161, ..., 166, 165, 164],
[117, 122, 127, ..., 165, 164, 163],
[118, 122, 128, ..., 164, 163, 162],
[149, 153, 158, ..., 166, 165, 164],
[163, 168, 173, ..., 170, 169, 168]], dtype=uint8)
在opencv中,我们有两种方法实现两个矩阵相加
# 方法一
(img_cat + img_cat2)[:5,:,0]
array([[ 38, 46, 56, ..., 66, 64, 62],
[224, 234, 244, ..., 64, 62, 60],
[226, 234, 246, ..., 62, 60, 58],
[ 32, 40, 50, ..., 66, 64, 62],
[ 60, 70, 80, ..., 74, 72, 70]], dtype=uint8)
# 方法二
cv2.add(img_cat,img_cat2)[:5,:,0]
array([[255, 255, 255, ..., 255, 255, 255],
[224, 234, 244, ..., 255, 255, 255],
[226, 234, 246, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]], dtype=uint8)
-
方法一:直接如上所示,用
a+b,这样得出来的结果大家可以看第一个为38,我们知道刚刚两个矩阵的第一个元素相加为142+152=294,之前我们说每一个像素的范围为0-255,在这里超过了255,因此我们这里实际上是294%256=38,进行了一个取余数的操作 -
方法二:
cv2.add(),这种方法会将超过255的值定义为255
5.2 图像融合
首先我们来看一下两张图片的维度
img_cat.shape,img_dog.shape
((414, 500, 3), (238, 218, 3))
由于维度不同,不能直接相加,这里我们需要使用cv.resize将dog的图片维度转换,这在我们之前CNN中也用过类似的操作。
img_dog = cv2.resize(img_dog, (500, 414))
img_dog.shape
(414, 500, 3)
现在两张图片的纬度一样了,我们可以调用cv2.addWeighted()将两张图片融合。
这里有5个参数,分别是图片1数据、图片1权重、图片2数据、图片2权重、常数项。
具体操作就是0.4*cat+0.6*dog+0
res = cv2.addWeighted(img_cat, 0.4, img_dog, 0.6, 0)
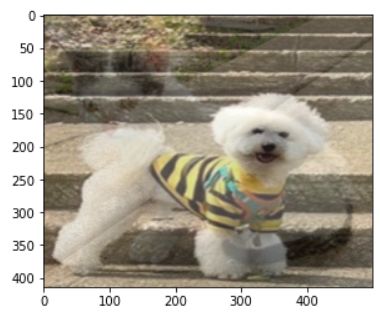
可以看到这个结果当中,左边像猫,右边像狗,这样就好像两张图像就融合在一起了。
6. 总结
我们介绍了Opencv环境配置、基本的图像和视频读取、读取感兴趣的部分图像、图像填充、以及在Opencv中的基本数值计算和图像融合。