python爬虫 京东关键词搜索商品及具体参数和评论
文章目录
-
- 爬取京东关键词搜索商品及具体参数和评论
-
-
- 查看京东关键词搜索,分析其网址各部分代表的意义,选取特定分类和时间区间进行爬取
- 解析网页内容,查看商品参数的位置;
- 筛选所需数据,输出并保存,尝试输出对齐
-
爬取京东关键词搜索商品及具体参数和评论
一个课堂作业,用requests,BeautifulSoup等模板爬取京东关键词搜索商品及具体参数和评论,完整代码在结尾。
查看京东关键词搜索,分析其网址各部分代表的意义,选取特定分类和时间区间进行爬取
分析url结构,可以发现京东搜索给定笔记本电脑时,url结构为https://search.jd.com/Search?keyword=笔记本电脑,同时需要把关键词进行编码,因此使用urllib.parse.quote_plus()进行编码加入,具体实现如下:
keyword = "笔记本电脑"
start_url = "https://search.jd.com/Search?keyword="+urllib.parse.quote_plus(keyword) + "&"+keyword
同时page的值为每一页的值*2+1,因此我们使用一个for循环来爬取我们所需要足够多的数据
for i in range(4):
url = start_url + "page=" + str(2*i+1)
#print(url)
html = getHTMLText(url)
找到网站后就使用我们的通用爬虫框架,进行网页数据爬取
def getHTMLText(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
try:
r = requests.get(url,headers = headers)
r.encoding = r.apparent_encoding
return r.text
except:
return ""
解析网页内容,查看商品参数的位置;
分析网页内容后,我们只可以在网页上找到商品对应的url,价格和商品名称,因此我们打开商品对应的url进行进一步的查找
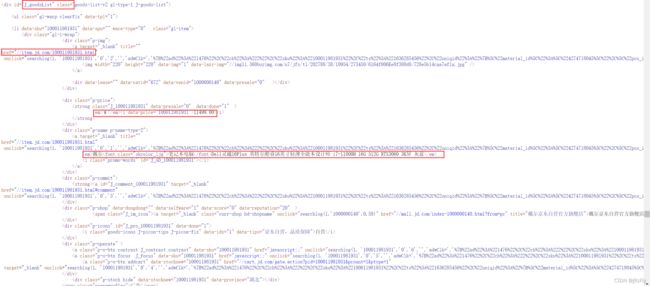
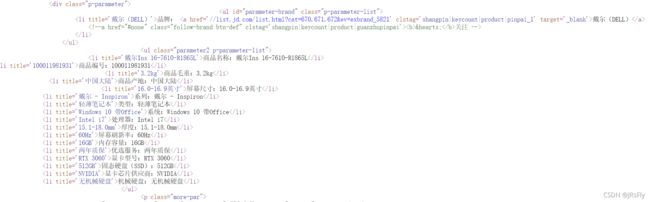
查看对应商品的源代码,找到我们想要的商品具体参数
现在寻找商品网站的评论,可以发现每次在我们点击商品评论后,对应网站都会对一个网站进行get请求,因此我们查看这个网站可以发现我们所需要的评论,至此爬虫所需信息的网页框架和信息都已经找到,接着就是用代码进行实现了
筛选所需数据,输出并保存,尝试输出对齐
import requests
from bs4 import BeautifulSoup
import bs4
import re
import urllib.parse
from pandas.core.frame import DataFrame
import json
import time
import random
def getHTMLText(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
try:
r = requests.get(url,headers = headers)
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(price_set,name_set,product_ID_set,html):
soup = BeautifulSoup(html, "html.parser")
prices = soup.find_all('div',class_ = 'p-price')
names = soup.find_all('div',class_ = 'p-name p-name-type-2')
product_IDs = soup.find_all('li',class_ = 'gl-item')
for price in prices:
price = price.text.split()
price_set.append(price[0])
for name in names:
name = name.find_all('em')[0]
name = name.text
name_set.append(name)
for product_ID in product_IDs:
product_ID_set.append(product_ID['data-sku'])
return ""
def intro_product(intro_product_id_set,intro_product_key_set,product_id):
url = "https://item.jd.com/"+str(product_id)+".html"
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
li = soup.find_all('ul',class_ = 'parameter2 p-parameter-list')
for tr in li:
tr = tr.text.strip('\n')
print(tr)
tr =re.split(r'[:\n]',tr)
#print(tr)
'''for i in range(len(tr)):
if i % 2 == 0:
intro_product_id_set.append(tr[i])
else:
intro_product_key_set.append(tr[i])'''
#获取商品的价格,名称和编号
price_set = []
name_set = []
product_ID_set = []
keyword = input("爬取词汇:")
start_url = "https://search.jd.com/Search?keyword="+urllib.parse.quote_plus(keyword) + "&"
#print(start_url)
for i in range(4):
url = start_url + "page=" + str(2*i+1)
#print(url)
html = getHTMLText(url)
fillUnivList(price_set,name_set,product_ID_set,html)
# printUnivList(uinfo,20)
data = {"价格(¥)":price_set,"名称":name_set}
data = DataFrame(data)
data.to_csv('爬取关键词:'+keyword+'结果'+'.csv')
#输出每一件商品的评论
#url = url1 + product_ID + url2 + page + url3
url1 = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId="
url2 = "&score=0&sortType=5&page="
url3 = "&pageSize=10&isShadowSku=0&rid=0&fold=1"
product_num = len(name_set) #商品数目
pinglun_page_num = 1 #输出评论页数
content_set1 = []
for product in range(product_num):
print("商品名称")
print(name_set[product])
print('-'*59)
intro_product_id_set = []
intro_product_key_set = []
print("商品参数")
intro_product(intro_product_id_set,intro_product_key_set,product_ID_set[product])
for i in range(pinglun_page_num):
url = url1 + product_ID_set[product] + url2 + str(i) + url3
#print(intro_product_set)
print('-'*59)
print(url)
callback='fetchJSON_comment98'
html = getHTMLText(url)
#print(html)
data = html.replace(callback,'') # 发现多出来的字符串是url中的callback参数,
data = data.replace('(','')
data = data.replace(')','')
data = data.replace(';','')
data = json.loads(data) #将处理的数据进行解析
#print(data) # 打印下来
user_id_set = []
content_set = []
creationTime_set = []
for user in data['comments']:
print('评论者:'+str(user['id']))
print('发表时间:'+str(user['creationTime']))
print()
print(user['content'])
print('-'*59)
user_id_set.append(str(user['id']))
content_set.append(user['content'])
creationTime_set.append(user['creationTime'])
content_set1.append(content_set)
print('*'*59)
time.sleep(random.randint(0,9))
#print(intro_product_id_set)
#print(intro_product_key_set)
#print(len(intro_product_id_set),len(intro_product_key_set))
'''data = {"商品参数名":intro_product_id_set,"商品参数值":intro_product_key_set}
data = DataFrame(data)
data.to_csv('爬取'+name_set[product]+'参数结果'+'.csv')
data = {"user_id":user_id_set,"发表时间":creationTime_set,"评论":content_set}
data = DataFrame(data)
data.to_csv('爬取'+name_set[product]+'评论结果'+'.csv')'''
#json_data = json.loads(html.text)
# print(html['content'])
# printUnivList(uinfo,20)
#data = {"商品名":name_set[0:product_num],"商品参数":name_set,"评论":}
#data = DataFrame(data)
print(len(content_set1))
data = {"价格(¥)":price_set[0:product_num],"名称":name_set[0:product_num],"评价":content_set1}
data = DataFrame(data)
data.to_csv('爬取关键词:'+keyword+'.csv')
最终可以发现,我们的保存结果如下图所示