基于WebAssembly的前端视频编辑器设计与实现(个人毕设论文删改)
前言: 本来想通过一篇更精简通俗易懂的博文讲述的,但是写到一半发现要讲的东西太多,于是太监了,因此我把个人毕设做了一些删改,把工程源码放在了末尾,发出来供各位参考。
(2021年10月8日更新了图片,此前未将图片复制上网。)
基于WebAssembly的前端视频编辑器设计与实现
摘 要
JavaScript灵活而强大,而且足以应对大部分应用开发,但随着web应用发展,JavaScript面临性能瓶颈。近几年,主流浏览器各自进行提高浏览器应用性能的尝试并推出解决方案,他们最终达成一致,webassembly因此诞生了。它的诞生使得浏览器运行密集计算型应用有了新的途径。
当前,人们可能为了使用一些简单功能而下载安装软件,然而使用这些功能的频率低,当不需要使用这些功能时,还需要手动卸载这些应用。如果,浏览器能运行这些功能,人们只需打开应用网页,即可使用所需功能,当关闭网页则清空占用的内存,无需安装软件。这类似微信小程序,这将极大减少为下载、安装、卸载软件而产生的使用成本。
本次研究主要是在学习webassembly的基础上,尝试使用webassembly实现完全在前端运行的简单视频编辑应用。
本次应用的实现,主要通过Emscript工具编译FFmpeg开源视频编辑库,并且编写相应的接口调用代码,实现相应的视频编辑功能,最终在浏览器上测试运行。
关键词 webassembly FFmpeg Emscripten 浏览器 视频编辑
目 录
第一章 绪论 5
1.1、选题背景 5
1.2、需求分析与研究意义: 5
1.3、研究内容 6
1.4、结构安排 6
第二章 技术背景 6
2.1、WebAssembly 原理: 6
2.2、Webassembly的定位与优缺点 7
2.2.1、 WebAssembly的目标 8
2.2.2 、WebAssembly具备以下优势 8
2.2.3 WebAssembly的局限性: 8
2.3、webassembly的发展与现状 9
2.3.1 、发展 9
2.3.2、现状: 10
2.4、WebAssembly 相关文本格式 10
2.5、Js中调用wasm中函数的方式 13
2.5.1、获取并实例化wasm 13
2.5.2 向wasm导入js函数并调用wasm中的函数 13
2.5.3 Memory 15
2.6、Emscripten: 15
2.6.1、什么是Emscripten 16
2.6.2 、C与Javascript的互操作方法 16
2.6.3、Emscript文件系统 18
2.6.4 、Js胶水代码简要说明 19
2.7、WebAssembly JS API: 20
2.7.1、项目中加载wasm的方式 20
2.7.2、项目中调用wasm中的函数的方式 20
2.7、FFmpeg基本知识 22
2.8.1、FFmpeg基本概念 22
2.8.2、FFmpeg常规处理流程 23
第三章 程序概要设计 24
3.1确定功能要素以及开发途径: 24
3.2完整应用草图 25
3.3、总体数据流向: 26
3.4、出逻辑与数据流向: 26
3.4.1、Js内的数据流向与逻辑: 26
3.4.2、Wasm中的数据流向与逻辑 28
3.5、模块调用逻辑 29
3.6、功能模块概述 30
3.6.1、Js中的模块: 30
3.6.2、wasm中的模块: 30
第四章 程序详细设计 31
4.1、模块包含的对象方法与参数类型 31
4.1.1、Js中的模块: 31
4.1.2、wasm中的模块: 33
4.2、分割,合并,截图实现方法: 34
4.2.1、ffmpeg处理视音频文件的一般流程: 34
4.2.2、简单的ffmpeg播放功能流程 35
4.2.3、数据预处理模块 36
4.2.4、“分割”功能模块 38
4.2.5、“合并”功能模块: 40
4.2.6、“截图”功能模块: 41
4.3、其他模块具体实现方法 43
4.4、一些关键代码分析 45
4.4.1、时间戳处理 45
4.4.2、JS读取wasm返回值方法 47
4.5、环境配置信息 49
4.6、编译C与FFmpeg为wasm 49
4.6.1、编译FFmpeg步骤 49
4.6.2、C与FFmpeg编译成wasm 50
4.7、简单前端页面设计 50
第五章 调试与运行 52
5.1、同源策略问题 52
5.2、内存问题 52
5.3、功能问题 55
5.3.1、视频分割花屏问题 55
5.3.2、不同视频合并异常问题 56
第六章 总结 57
参考文献 58
致 谢 58
第一章 绪论
1.1、选题背景
JavaScript基本上已经成为了Web平台的标准开发语言,但不能满足一些新功能应用的性能需求。已经出现试图将其他语言代码转化为Javascript,以此克服Javascript自身短板的项目,例如微软的TypeScript、Google的Dart与PNaCl、Mozilla的asm.js项目。但并非所有浏览器都兼容以上项目。2017年初,WebAssembly 的核心被宣布完成。
WebAssembly是一种新的字节码格式(简称“wasm”)是一种新的底层安全的二进制语言。它将能支持各类高级语言在浏览器上以与原生应用相当的效率执行,开发者可以选择使用以往浏览器不能支持的语言进行web应用开发,浏览器可以高效运行由这些高级语言编译而成的wasm二进制码,实现更多性能需求高的web应用。目前,已经出现wasm的一些应用。例如:游戏引擎Egret Engine、多媒体影音处理函数库Web-DSP。
来自MDN的定义:WebAssembly是一种新的编码方式,可以在浏览器中运行 ——它是一种低级的类汇编语言,具有紧凑的二进制格式,可以接近原生的性能运行,并可以作为诸如C / C ++等语言的编译目标,以便它们可以在Web上运行。这意味着一些优质的C/C++程序可以借此移植到前端运行,从开发角度看,原生应用的跨平台多了一种途径,减少了不同平台实现同样功能的开发周期或着难度,另一方面,拓宽了前端应用的实现方式,为前端运行计算密集型应用提供了一个解决方案。
1.2、需求分析与研究意义:
1、对于网页应用提供商,单纯的前端处理数据可以减少带宽的使用。传统网页的文件处理交由后台服务器进行,来回数据传递产生带宽成本与时间成本,特别是视音频这类数据的处理成本更大。传统文件处理交由后台服务器,也提高了服务器的运行成本。
2、对于非视频处理行业人士,浏览器运行视频编辑应用,用户不必再为偶然的文件处理需求而下载以及安装对应程序到本地。
3、Js的性能瓶颈决定不适合计算密集型程序运行,虽然配合JIT可以优化部分程序。
4、FFmpeg库使用Js编写,成本巨大。不适宜将大型、计算密集的程序改写成Js,这使得一些优质c/c++程序难以通过改写成Js而在浏览器上运行。
5、wasm被主流浏览器所支持,将ffmpeg编译成wasm进而在前端运行视音频处理程序是值得尝试的途径。
1.3、研究内容
1、学习webassembly基础知识内容。
2、学习FFmpeg开源库的使用。
3、基于web assembly的、移植FFmpeg以实现完全前端视音频处理方案设计。
4、学习以web assembly为基础的前端移植方案。
1.4、结构安排
本文一共分为六章,具体安排如下:
第一章:绪论,主要介绍本文选题背景与研究意义
第二章:介绍webassembly的技术基础知识,webassembly简要原理与定位,该技术的优缺点,发展与现状。
第三章:介绍程序概要设计,讲解总体程序模块划分与布局,简要说明项目的运行逻辑。
第四章:按照模块划分讲解各个模块功能的具体实现方法与流程,介绍各个模块的输入输出与具体功能处理方法。
第五章:介绍运行所遇到的问题与解决思路,并说明当前项目存在的问题。
第六章:总结开发内容与成果,以及在开发过程中的心得体会
第二章 技术背景
2.1、WebAssembly 原理:
众所周知,计算机直接运行的是以0、1构成的机器码。但机器码可读性极差,因此人们通过高级语言 C、C++、Rust、Go 等编写再编译成机器码。但
由于不同的计算机 CPU 架构不同,机器码标准也有所差别,其中 x86、AMD64、ARM是常见的 CPU 架构, 在由高级编程语言编译成可自行代码时需要指定目标架构。
每个高级语言都去实现源码到不同平台的机器码的转换工作是重复的,高级语言只需要生成底层虚拟机(LLVM)认识的中间语言(LLVM IR),LLVM 能实现:
1、LLVM IR 到不同 CPU 架构机器码的生成;
2、机器码编译时性能和大小优化
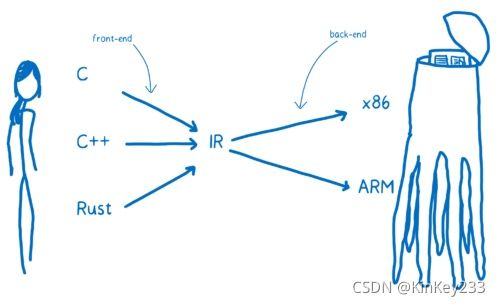
图 一-高级语言编译[1]
由图一可见,高级语言转为IR代码后,针对不同CPU框架,进行一次编译。而WebAssembly 字节码是一种抹平了不同 CPU 架构的机器码,WebAssembly 字节码不能直接在任何一种 CPU 架构上运行, 但由于非常接近机器码,可以非常快的被翻译为对应架构的机器码,因此 WebAssembly 运行速度和机器码接近,非常像 Java 字节码。抽象理解为概念机器的机器语言,而不是实际的物理机器的机器语言。

图 二-高级语言编译2 [1]
如图二可见,将IR编译为wasm后,wasm在x86、ARM框架下都能运行,因此编译成wasm不必关心最终代码运行的CPU框架。
总而言之:WebAssembly 字节码经过翻译后能够在不同CPU架构上运行,
目前能编译成 WebAssembly 字节码的高级语言有:c\c++、Rust、Kotlin。
2.2、Webassembly的定位与优缺点
javaScript足够强大到够解决人们在当今网络上遇到的绝大部分问题。但是尽管如此,当试图把JavaScript应用到诸如图像/视频编辑、增强现实、计算机视觉、3D游戏、虚拟现实以及大量的要求原生性能的其他领域的时候,JS遇到了性能问题。下载、解析以及编译巨大的JavaScript应用程序的成本是过高的。移动平台和其他资源受限平台进一步放大了这些性能瓶颈。
webassembly设计的目的不是为了手写代码而是为诸如C、C++和Rust等低级源语言提供一个高效的编译目标。它被设计为和JavaScript一起协同工作,从而使得网络开发者能够利用两种语言的优势。
当然根据现有的一些针对JS、webassembly运行性能的测评,JS配合JIT有时是能比webassemly更接近原生应用运行速度
2.2.1、 WebAssembly的目标
作为W3C WebAssembly Community Group中的一项开放标准,WebAssembly是为下列目标而生的:
1.快速、高效、可移植——未来WebAssembly代码能不同平台上能够以接近原生应用速度运行。
2.可读、可调试——WebAssembly是一门低级语言,但是它有确实有一种人类可读的文本格式wat,这允许开发者手工来写代码,以及调试代码。
3.保持安全——WebAssembly被限制运行在一个安全的执行环境中,像其他网络代码一样,它遵循浏览器的同源策略和授权策略。
WebAssembly不是用来取代JavaScript的,相反,设计之初就是为了让webassembly辅助JS,两者协作,发挥优势。
2.2.2 、WebAssembly具备以下优势
文件加载 - WebAssembly 文件体积小,下载速度快。
解析 - 解码 WebAssembly 比解析 JavaScript 要快。
编译和优化 - 编译和优化所需的时间较少,因为在编译成wasm的环节已经进行了优化,JavaScript 需要为动态类型多次编译代码。
重新优化 - WebAssembly 代码不需要重新优化,因为编译器有足够的信息可以在第一次运行时获得正确的代码。
执行 - 执行可以更快,WebAssembly 指令更接近机器码。
垃圾回收 - 目前 WebAssembly 不支持垃圾自动回收,垃圾回收都是手动控制的,因此开发者可以自定义垃圾回收时机,以避免程序需要高速运行时,收到垃圾自动回收的影响。
2.2.3 WebAssembly的局限性:
根据参考文献[4]得出:
Webassembly 的局限性
1、WebAssembly 没有任何方式能够操作 DOM,必须通过 JavaScript 才能改变 DOM 节点。因此,与标签相关的操作,会相比js慢。
一些资料显示,wasm是计算密集型应用的途径,但不是一定是最优秀的。
2、WASM 运行时性能在原理上就是受限的,运行速度达不到真正的汇编级别。Rust 编译到 WASM 后有不小的性能损失,极致优化后的 JS 不会输它多少
· WASM 不是计算密集型应用的唯一解决方案。对于精度要求不高并且高度并行的算法,用 WebGL 做 GPU 加速往往更快,其次是 WASM 这种 CPU 上运行的字节码。
3、JS上调用wasm模块,未必能提高性能。JIT 为JS 内置了机器码级的优化,手动把算法重写成 C,未必比 Happy Path 上的 JIT 更快。
4、WASM 生态跟前端工具链基本无关,它的 Emscripten 工具链搞的完全就是 C++ 系语言交叉编译,从编译器到依赖库都完全跟 JS 这一套无关。
当前webassembly尚未真正支持多线程。WebAssembly 的性能优于js,但是低于nodejs的原生模块或者是c的原生模块。
但正是因为wasm和js基本无关,原生应用生产者可以将优质的c/c++应用移植到前端。对于一些改写成js 成本巨大的原生应用,wasm是非常好的移植途径。
2.3、webassembly的发展与现状
2.3.1、发展
自从 JavaScript 诞生起到现在已经变成最流行的编程语言,这背后正是 Web 的发展所推动的。Web 应用更多更复杂,这也暴露出了 JavaScript 的一些问题:
语法太灵活,开发大型 Web 项目困难,性能不能满足一些场景的需要。
针对以上两点,近些年来出现了一些 JS 的代替语言,
例如:
微软的 TypeScript 通过为 JS 加入静态类型检查来改进 JS 松散的语法,提升代码健壮性;
谷歌的 Dart 为浏览器引入新的虚拟机去直接运行 Dart 程序以提升性能;
火狐的 asm.js 则是取 JS 的子集,JS 引擎针对 asm.js 做性能优化。asm.js 由 Mozilla 提出,属于 Java 的一个子集,主要是为了解决 Java 的执行效率问题,可以更大程度的优化以提高执行速度。
以上尝试各有优缺点,其中:
TypeScript 解决了 JS 语法松散的问题,但是还需要编译成 JS 去运行,对性能没有提升。
Dart 只能在 Chrome 预览版中运行,无主流浏览器支持。
asm.js 语法过于简易、有很大限制,开发效率不高。
三大主流浏览器分别提出了自己的解决方案,互不兼容,这违背了 Web 的宗旨; 技术的规范统一使得 Web 得以快速发展,因此需要形成一套新的规范去解决 JS 所面临的问题。
WebAssembly 起源于 Mozilla 的一个项目:ASM.js,简单的说就是 JS 的一个轻简版子集,去除了动态类型、对象、垃圾回收等损耗性能的部件。它的作用是成为 C/C++ 的编译目标,从而能将大中型游戏引入浏览器,取得很好的效果。然而 ASM.js 毕竟仍然是 JS,它不具备原生代码的一些功能,如 SIMD、线程、共享内存等,因此 ASM.js 进一步发展,于是 WebAssembly 诞生了,WebAssembly 作为一种新的字节码格式,主流浏览器都已经支持 WebAssembly。 和 JS 需要解释执行不同,WebAssembly 字节码和底层机器码很相似,可快速解析,因此性能相对于 JS 边解释边执行有更大提升。 WebAssembly 并不是一门编程语言,而是一份字节码标准,需要用高级编程语言编译出字节码放到 WebAssembly 虚拟机中才能运行, 浏览器厂商需要做的就是根据 WebAssembly 规范实现虚拟机。
2.3.2、现状
webassembly当前应用举例:
1、Google Earth — 支持各大浏览器的 3D 地图,而且运行流畅
2017年10月底,谷歌开始支持让 Google Earth 在 Firefox 上运行,其中的关键就是使用了 WebAssembly。
2、Magnum — 跨平台的 OpenGL 图形引擎
Magnum 是一款轻量级和模块化的游戏、数据可视化 OpenGL 图形处理引擎,支持 C++11/C++14。桌面环境一共支持 Linux、Windows 及 Mac,移动环境也支持了 iOS 和 Android,并且整合了嵌入式 Linux,而在网页环境则必须通过编译器 Emen 将代码编译成 Asm.js、WebAssembly 格式。该工具所支持的图片 API,包含了 OpenGL、OpenGL ES 及 WebGL。
2.4、WebAssembly 相关文本格式
Webassembly二进制文件格式不适合阅读,因此为了阅读webassembly的逻辑,创建了一种表达式(S-expression-based textual representation),该文本的格式为.wat。
观察来自MDN社区的例子:
(module
(func $i (import “imports” “imported_func”) (param i32))
(func (export “exported_func”)
i32.const 42
call $i
)
)
该模块定义了两个函数,一个是需要从外界导入函数体的函数(可以理解为c语言中,先声明函数名称和参数)。第二个是可以被wasm以外的环境调用的函数。
Import :该关键词将当前函数定义为“输入函数”,即需要从外界导入函数体的函数,而且在wat编译成wasm后,初始化wasm模块时,必须要通过对应的“命名空间”,将函数实现导入。
“命名空间”即 {imports :imported+func { 函数实现 } }
在js中,应先定义对象如下:
var importObject = {
Imports: {
imported_func: 函数实现
}
};
其中函数实现的参数必须和模块中定义的参数个数一致。
调用WebAssembly.instantiate() 实例化wasm时,将该对象作为参数导入。
一种标准的定义式如下:
(module
(son_1)
(son_2)(…)
(export “Out_name” (func $func_name) )(…)
)
一个模块中可以有多个函数,函数可以先声明,在最后使用export对个别函数定义一个对外调用的接口名称。经过总结后,可以使用图三表达:
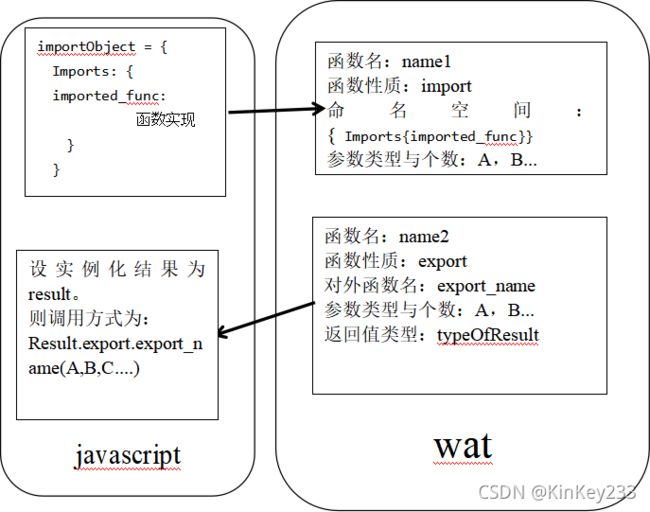
图 三-wat文本解读
图三可以看做是wasm与js之间导入导出函数的示意,体现了js和wasm之间进行函数调用和函数导入的方式方法。
当然,wat需要先编译成wasm文件,才能被js使用。
从该wat例子中,我们可以发现S-表达式和汇编语言非常像。
(func $i (import “imports” “imported_func”) (param i32))
(func(export “exported_func”)
i32.const 42
call $i
)
Param i32表明该函数有一个输入参数,输入参数的数据类型是i32(32位整型)
这个函数中 i32.const 42 ,定义了一个内容为42的32位整数,并将此数据放在堆栈的最上方。
Call $i 语句则调用了第一个函数 $i,并将堆栈最上方的数据作为参数导入函数中。这和汇编语言极其相似。
为了把二进制文件格式 wasm 转换成人眼可见的 wast 文本,需要安装 WebAssembly 二进制工具箱WABT,wasm2wast f.wasm 获得 wast;除此之外还可以通过 wast2wasm f.wast -o f.wasm 逆向转换回去。
2.5、Js中调用wasm中函数的方式
2.5.1、获取并实例化wasm
目前 WebAssembly 只能通过 JS 去加载和执行,但未来在浏览器中可以通过像加载 JS 那样 去加载和执行 WebAssembly,下面来详细介绍如何用 JS 调 WebAssembly。
JS 调 WebAssembly 分为 3 大步:加载字节码 > 编译字节码 > 实例化,获取到 WebAssembly 实例后就可以通过 JS 去调用了,以上 3 步具体的操作是:
在获取到字节码后都需要转换成 ArrayBuffer 后才能被编译,通过 WebAssembly 通过的 JS API WebAssembly.compile 编译后会通过 Promise resolve 一个 WebAssembly.Module,这个 module 是不能直接被调用的需要
在获取到 module 后需要通过 WebAssembly.Instance API 实例化 module,获取到 Instance 后就可以像使用 JS 模块一个调用了。
其中的第 2、3 步可以合并一步完成,前面提到的 WebAssembly.instantiate 就做了这两个事情。
Js加载执行wasm的例子:
function fetchAndInstantiate(url, importObject) {
return fetch(url).then(response =>
response.arrayBuffer()
).then(bytes =>
WebAssembly.instantiate(bytes, importObject)
).then(results =>
results.instance.exports.exported_func()
);
}
其中url为wasm文件路径,importObject为需要导入的对象(其中可以包含需要导入的内存和输入函数的实现)
在获取instance后,通过类似访问属性的方式,使用暴露的函数名exported_func()来调用wasm中的函数。
2.5.2 向wasm导入js函数并调用wasm中的函数
依旧以下面的wat文本编译的wasm为例子:
(module
(func $i (import “imports” “imported_func”) (param i32))
(func (export “exported_func”)
i32.const 42
Call $i
)
)
首先将该文本通过wabt工具集合中的”wat2wasm.cc”工具编译成wasm。
在js中编写如下:
1、定义一个对象:
var importObject = {
imports: {
imported_func: function(arg) {
console.log(arg);
}
}
};
该对象包含的子对象,结构上需要对应wat文本中定义的输入函数命名空间
Import “imports” “imported_func”
保持一致,而且imported_func :对应的js函数参数个数必须与wat中定义的输入函数参数一致。
使用fetch()获取wasm文件,并将其读成arraybuffer,对该结果使用WebAssembly.instantiate实例化。
fetch(url).then(response =>
response.arrayBuffer()
).then(bytes =>
WebAssembly.instantiate(bytes, importObject)
其中url是wasm资源路径,importObject则是之前定义好的,需要传递给wasm的对象。
2、调用wasm中的函数
3、完整的获取并实例化wasm代码如下:
function fetchAndInstantiate(url, importObject) {
return fetch(url).then(response =>
response.arrayBuffer()
).then(bytes =>
WebAssembly.instantiate(bytes, importObject)
).then(results =>
results.instance.exports.exported_func()
//上面这语句调用了wasm中声明为exports的exported_func()
);
}
var res = fetchAndInstantiate(‘simple.wasm’,importObject);
fetchAndInstantiate是自定义的函数,以方便对获取并实例化wasm。
以上例子实现了从js 向wasm导入js函数,实现了调用wasm中定义为export的函数。现在MDN社区推荐实用instantiateStreaming进行初始化wasm。
WebAssembly.instantiateStreaming(fetch(‘simple.wasm’), importObject)
2.5.3 Memory
Memory是 WebAssembly 一种构件,一般是表示编译的 C/C++ 应用程序的整个堆。Memories 可被 JavaScript 创建,需要提供参数,如初始大小和最大值。
WebAssembly.Memory() 构造函数创建一个新 Memory 对象。该对象的 buffer 属性是一个可调整大小的 ArrayBuffer ,其内存储的是 WebAssembly 实例 所访问内存的原始字节码。
var memory = new WebAssembly.Memory({initial:10, maximum:100});
这行代码表示创建一个起始大小为10个单位,最大为100单位的Memory。一个单位大小为固定值64KB。
在js调用webassembly.Memory创建好Memory后,采取2.5.2节同样的方式,将Memory导入到wasm。
示例如下:
Var object = {js: {mem:memory} };
Webassembly.instantiateStreaming(fetch(‘memory.wasm’),object)
创建一个对象Object ,包含结构同样要对应wasm中定义Memory时的命名空间。调用instantiateStreaming完成实例化并导入object。
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_objects/WebAssembly/Memory
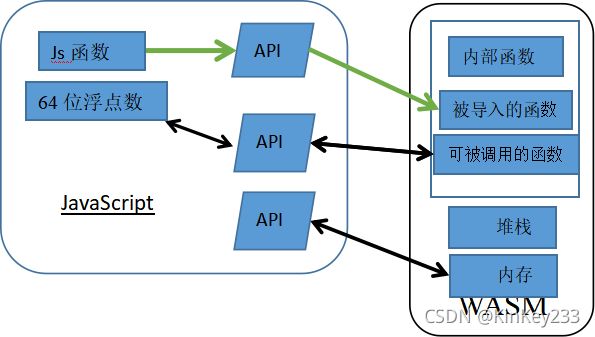
总结2.5节可以的出图四:

图 四-wasm与JavaScript调用关系图
解释:
这图表示只含有一个module的wasm模块与js之间的互动。
JavaScript调用webassembly API向wasm中导入内存、函数或者进行修改、调用
2.6、Emscripten:
2.6.1、什么是Emscripten
Emscripten是,Mozilla 的工程师 Alon Zakai 在研究 LLVM 编译器时,为了能将 C / C++ 语言编译成 JavaScript 代码,以此将C/C++程序在浏览器上运行,专门做的一个编译器项目。
Emscripten 的底层是 LLVM 编译器,理论上任何可以生成 LLVM IR(Intermediate Representation)的语言,都可以编译生成 asm.js。 但是实际上,当时Emscripten 几乎只用于将 C / C++ 代码编译生成 asm.js。起初,Emscripten只能将C/C++编译为asm.js文本–一种JavaScript的变体。
如今,Emscripten工具可以支持将C/C++编译为wasm二进制文件。使用Emscripten编译C/C++为wasm后,会产生Js胶水代码,在这个胶水代码的封装下,Js可以像调用自身函数那样调用wasm中包含的C/C++函数,不必依照上节Js调用wasm中的函数方式进行调用。
一个简单的C程序,编译成wasm后,再将该wasm文件通过使用wabt工具集合中的”wasm2wat.cc“工具,转换成wat文本进行阅读,一般情况情况下,C程序功能在wasm中的实现,可能需要多个Module联合实现,而js胶水代码的作用,就是将这些module封装成一个方法,供js调用。在Js胶水代码的封装下,我们无需考虑wasm内部module的逻辑。因此我们只需要学习C与Javascript的互操作方法。
2.6节主要参考文献[5]。
2.6.2 、C与Javascript的互操作方法
2.6.2.1、JavaScript 调用 C/C++
实际上是JavaScript调用wasm中的函数,但经过js胶水代码的封装后,可以等同于JavaScript调用C/C++的函数。
1、 函数导出宏:
为了方便函数导出,我们需要添加一个函数导出宏,该宏需要完成以下功能:避免函数因为缺乏引用而导致在编译时被优化器删除。如果某个导出函数仅供JavaScript调用,而在C/C++环境中从未被使用,开启某些优化选项(比如-O2以上)时,函数有可能被编译器优化删除,因此需要提前告知编译器:该函数必须保留,不能删除,不能改名。
main()作为C/C程序的主入口,欺负好修饰策略是特殊的,因此即使在C中不作特殊约束,其最终的符号仍然是_main(),无需按上述第1点进行处理。
为了满足上述要求,需要在C程序中添加EM_PORT_API宏定义(详情见附录)
使用该宏定义的方式为:
EM_PORT_API(返回值类型) function_name() {}
然而在本项目中,编译时并没有添加-o2优化选项,可以无需为了避免main函数以外的函数被优化而添加导出宏;
但,为了告诉Emscripten编译某C函数时,为该c函数封装一个被外界调用的方法,需要在C函数前添加”EMSCRIPTEN_KEEPALIVE “,表示这个函数可被Js调用。
2、调用C/C++函数:
使用script标签加载js胶水代码后,等待wasm模块加载完毕,再进行调用函数的操作:
Module = {};
Module._func_name( )
参数写在括号内,如需获取返回值,在Module前添加js变量承接返回值即可。
2.6.2.2、C/C++ 与 JavaScript 的通信
1、Number型数据的传递
根据上一小节的内容,我们可以通过调用C/C++函数时传递参数/获取返回值进行通信。
但通过上一节的方法传递的参数是有限制的。
Js环境中只有一种数值类型:Number,64为浮点数(IEEE 754标准)。
Js与C/C++ 有完全不同的数据体系,Number是两者之间的唯一的共同点。
因此,两者相互调用时,是在交换Number。
Number从JavaScript传入C/C++有两种途径:
JavaScript调用了带参数的C导出函数,Number通过参数传入;
C调用了由JavaScript实现的函数(见2.2),Number通过注入函数的返回值传入。
本项目只涉及第一种方式,第二种方式不做介绍。
本项目需要向C函数传递视频数据,属于非Number数据,因此,不宜采取以上方式直接传递视频数据。需要通过共享内存进行。
2、非Number数据传递:
Js向C传递非Number数据基本步骤:
① Js中,将数据保存到Array数组中。
② 调用Module._malloc()函数,以数据的字节长度为参数,申请一片共享内存,并获得该内存的起始位置offset。数据字节长度是Number型,而内存起始位置是uint8_t型。
③ 使用Module.HEAP8.set(Array, offset);语句,将Array数组中的数据拷贝到以offset为起始位置的内存中。
图 五-内存示意图
如图 六所示,完成以上步骤后,将offset与数据字节长度传递到C中,C中的函数可以依据offset与数据字节长度length读取数据。以此完成通过内存的数据交换。
Module._malloc(length):是Emscripten导出的C的malloc()函数
这使得Js可以调用该函数在C中申请一片内存并获得该内存的起始指针。
3、C向Js传递非Number数据基本步骤:
a.在c中使用malloc()函数依据数据字节长度申请内存空间,获得内存的起始指针offset。
b.将数据字节长度length 和 offset 作为一个结构体指针的值。将该结构体指针作为C函数的返回值,传递回Js。
c.Js依据结构体指针,按字节读取length信息后,读取对应长度上的内存的数据,保存到js对象中,以此完成以此C向Js传递数据操作。
2.6.3、Emscripten文件系统
2.6.3.1、为什么要设置Emscripent文件系统
通常的JavaScript程序与C/C++本地程序有巨大的差异,主要体现在:
运行在浏览器中的JavaScript程序无法访问本地文件系统;
在JavaScript中,无论AJAX还是fetch(),都是异步操作。
Emscripten提供了一套虚拟文件系统,以兼容libc/libcxx的同步文件访问函数。
而这是本项目的重要支撑。
在FFmpeg中,个别函数需要一个模拟文件系统的路径作为参数。因此需要设置开启Emscripten文件系统。
Emscripten文件系统可以供fopen()/fread()/fwrite()等libc/libcxx文件访问函数调用。
2.6.3.2、文件系统类型与选择
Emscripten提供了三种文件系统,分别为
· MEMFS:内存文件系统。该系统的数据完全存储于内存中,程序运行时写入的数据在页面刷新或程序重载后将丢失;
· NODEFS:Node.js文件系统。该系统可以访问本地文件系统,可以持久化存储,但只能用于Node.js环境;
· IDBFS:IndexedDB文件系统。该系统基于浏览器的IndexedDB对象,可以持久化存储,但只能用于浏览器环境
本项目在浏览器js环境中运行,而且不需要在浏览器中
持久化储存输出视频,故选择MEMFS 内存文件系统。
2.6.3.3、Emscripten文件系统的创建
本项目中,wasm创建MEMFS并添加文件到该文件系统供访问时,需要在编译时添加 --preload-file file 命令。
其中filename 是希望添加到Emscripten文件系统的文件或者文件夹。
编译之后,会在原来生成js胶水代码和wasm文件的基础上,多生成一个.data文件。本项目详细编译指令与Emscripten文件系统的使用将在第四章程序详细设计中介绍。
设置开启文件系统后,C/C++的代码中可以像访问读写本地文件一样访问Emscripten文件系统。
2.6.4 、Js胶水代码简要说明
JS胶水代码是使用Emscripten编译C/C++代码时产生的文件。使用
2.7、WebAssembly JS API:
2.7.1、项目中加载wasm的方式
使用emcc命令编译时会产生index.js胶水代码,在script标签中加载js 胶水代码就能自动完成wasm的实例化。
2.7.2、项目中调用wasm中的函数的方式
本项目中使用的wasm是ffmpeg的开源库通过Emscripten工具编译而成。依照第二章关于Emscripten的介绍,可以使用以下方式对wasm中的函数进行封装,方便在Js中调用。
本项目中实例化wasm并调用wasm中的函数(可视为C中的函数)的方式为:
第一步:
Script标签加载编译时产生的胶水代码index.js
第二步:
Js_func_name=Module.cwrap(‘c_name’,返回值类型, 输入参数类型);
Js_func_name 是给Js调用的函数名,可以自定义。
Module 是加载index.js后,实例化wasm的结果。
Cwrap是wasm和js间的API。用于在js中声明wasm中的函数。
c_name是wasm中,被设置为“export”的函数。
返回值类型和输入参数类型:
32位以及以下整数、32位浮点数、64位浮点数。
(js中只有一种数字类型:64位浮点数-IEEE 754标准)
经过此步骤后,在js中可以如同调用js函数一般调用该wasm函数。
通过Cwrap直接传递参数并获得返回值是C/C++与JS交换数据的主要方式,
适用于传递少量的数字类型的数据。
图 四-wasm与JavaScript调用关系图
如图四所示:
一个稍微复杂的C代码,编译成的wasm中会有许多module,每个module包含多个函数,它们相互配合之下,才能实现C代码的功能。人为调用各种API去操作wasm是不现实的的,需要js胶水代码完成方法封装。
总结上述资料,并结合2.5节图 四-wasm与JavaScript调用关系图,可以画出js、wasm经过js胶水代码封装后的调用关系图。
经过封装后的关系如图六所示。
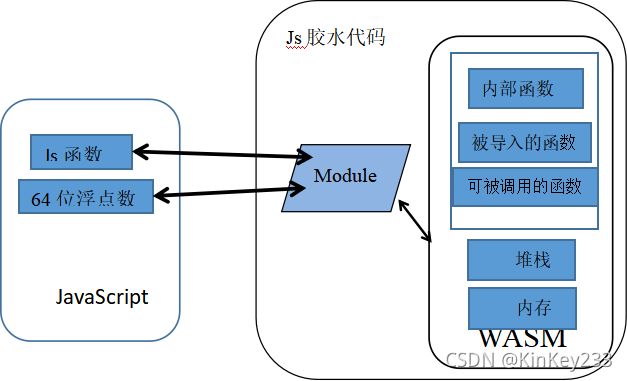
图 六-封装后的js、wasm关系图
2.7、FFmpeg基本知识
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。
采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库libavcodec,为了保证高可移植性和编解码质量,libavcodec里很多code都是从头开发的。
2.8.1、FFmpeg基本概念
1.容器/文件(Container/File):某一格式的多媒体文件,比如flv、MP4,mov等。
2. 媒体流(Stream):时间轴上一段连续数据,比如一段视音频数据。
3. 数据帧/数据包(Frame/Packet):数据帧是未经编码的原始数据,数据包是经过编码的数据帧。数据帧是编码器的输入,数据包是编码器的输出。分属于不同媒体流的数据帧交错存储与容器之中。通常情况下一个数据包包含一帧视频图像信息或者多帧音频信息。
4. 编解码器:编解码器是以帧为单位实现压缩数据和原始数据之间的相互转换的。
FFmpeg中抽象的概念:
- AVFormatContext:是对容器或者文件层次的抽象,可以认为是一个承载文件信息的容器。
- AVStream:容器里面包含了多路流,例如MP4文件中可能包含视频流、音频流、字幕流,AVStream 就是对流的抽象。
3.AVCodecContext 与 AVCodec:用于描述该流的编码格式,比如视频流和音频流的编解码格式是不同的。对编解码器格式以及编解码器的抽象就是AVCodecContext 与 AVCodec。
AVPacket 与 AVFrame:他们分别对应于解码器或者编码器的输入输出部分,也就是压缩数据以及原始数据的抽象就是AVPacket与AVFrame。
2.8.2、FFmpeg常规处理流程
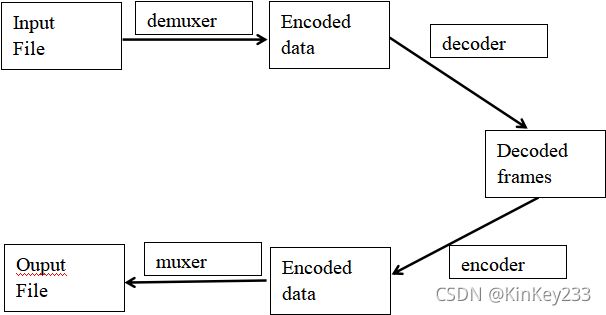
图 七-FFmpeg处理基本流程
流程如图七所示:
输入视频文件,经过解复用器,对视频文件进行解封装。获得编码数据包,编码数据包经过解码器,获得原始数据帧。原始数据帧经过编码器产生编码数据包,这些数据包再经过复用器,最终生成输出视频文件。
解封装(或称解复用):
输入文件为我们常见的MP4、flv、mov等格式的文件,这些文件称为具有一定封装格式的媒体文件。编码压缩号的视音频数据,字幕数据按照一定的格式放在一个文件中。Demuxer(解复用)将媒体文件中存放的压缩视音频数据、字幕数据分离开来。
解码和加工:
解封装后的数据是压缩编码后的数据,因此需要经过解码,获得原始数据。加工操作是对原始数据进行例如视频像素修改、裁剪等行为。
编码:
原始数据经过编码器,重新编码成编码数据。
重新封装:
将编码后的数据按照一定格式的要求,进行复用。
第三章 程序概要设计
3.1确定功能要素以及开发途径:
功能要素:
合并:前端页面输入两个本地视频文件,程序将两者进行时间轴上的合并,并返回合并后的视频。
分割:前端页面输入一个本地视频以及剪切起始和结束时间,程序按时间参数将视频分割,返回对应时间片段的视频。
截取视频帧:前端页面输入一个本地视频文件以及视频帧的显示时间,程序将截取对应的视频帧返回到前端页面显示,并可以选择是否保存到本地
下载:将处理后的视频文件,保存到本地。
开发途径如图八所示:
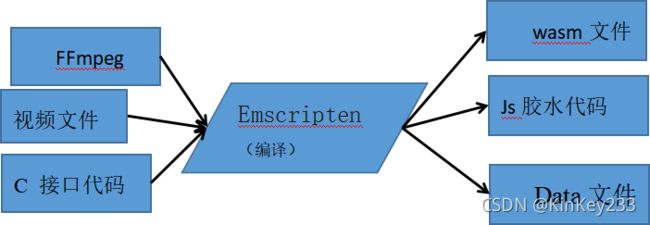
图 八-开发途径
依照第二章节,Webassembly应用开发有两条途径,一是直接使用S-表达式编写wat文件,再将wat转换成wasm。但实际上中类似FFmpeg这样的大型开源代码不可能直接由wat改写完成。
经过调查,选择FFmpeg作为移植对象,编译成为wasm是最佳途径。
3.2完整应用草图
图 九-完整应用草图

如图九所示:
在完整的方案中:
后台:
将wasm、Date、Js、html等保存在服务器上,设想中Web服务器端软件为Tornado
前端:
1、浏览器请求wasm、Date、Js、html等文件。
2、能实现将wasm、date缓存到localStorage,下次进入页面可无需从服务器再获取源文件。需手动清除localStorage才能清除wasm模块。
3.3、总体数据流向:
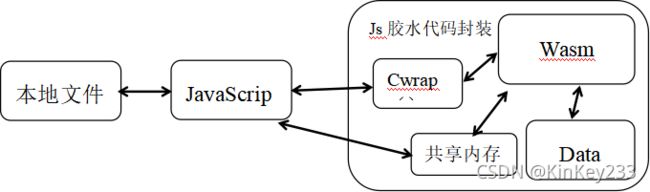
图 十-总体数据流向
如图十所示:
1、本地视频数据保存到Js数组中,Js再将数组保存到共享内存中。完成视频数据的导入。
2、Js通过Cwrap向wasm告知视频数据所在内存位置,wasm读取并处理视频数据。
3、wasm将处理完毕的数据保存到Data文件中保存。
4、wasm通过Cwrap()向js传递输出视频数据在内存的位置。
5、Js读取输出视频数据,并保存到本地。
其中Data对应于Emscripten文件系统:
将功能模块处理完毕的视频保存到Emscripten文件系统的原因:
经过有限调查,FFmepg需要创建一个用于输出的AVformatContext上下文,并打开一个输出文件URL,对输出上下文的写入数据操作,最终会写到输出文件中。
根据查找的资料:
Ffmpeg能从内存中读取媒体文件数据。
FFmpeg能读取媒体文件到内存。
但在不赋予URL的情况下初始化输出AVformatContext后,在进行avformat_write_header写文件头时报错,该错误暂时无法解决,因此暂时将输出文件保存到Emscripten文件系统,避开该错误,继续实现项目。
3.4、出逻辑与数据流向:
以Cwrap()函数为界,可画出以下两个数据流向与逻辑图:
3.4.1、Js内的数据流向与逻辑:
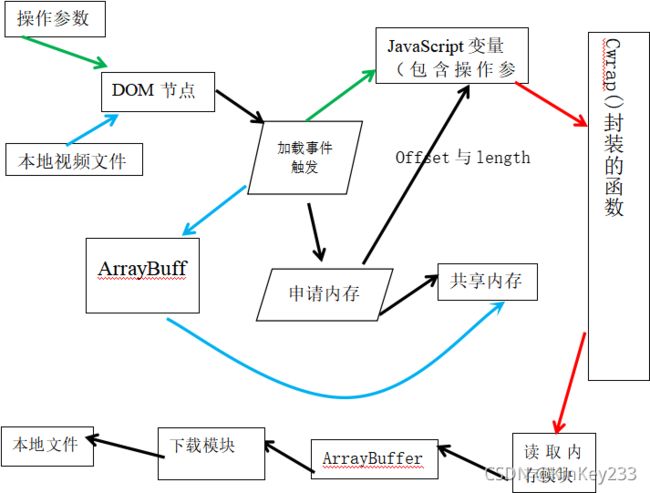
图 十一-Js脚本中的行为
如图十一所示,在Cwrap()左侧全部发生在js内:
1、操作参数(例如视频分割时间点)由用户填写在网页面上,由用户通过输入框选择本地视频文件,两者都会暂时保存在页面节点(标签)上。
2、用户点击按钮,触发加载事件,将会把操作参数从DOM节点中读取到JavaScript中的变量。同时,将视频保存到Arraybuffer中,依照Array buffer的长度申请内存空间,并调用相应的函数将ArrayBuffer 中的视频数据拷贝到共享内存中。以上完成了js中视频处理的前期准备工作。
3、Cwrap函数封装好了wasm中对应的功能调用函数,调用Cwrap封装的函数传递包含操作参数和视频在内存中的位置offset和长度length。
4、接收的返回值(保存处理后视频数据的内存offset和length),根据返回的offset和length,从内存中读取数据保存到ArrayBuffer中。
5、调用“下载模块”下载ArrayBuffer中的视频数据到本地。
3.4.2、Wasm中的数据流向与逻辑
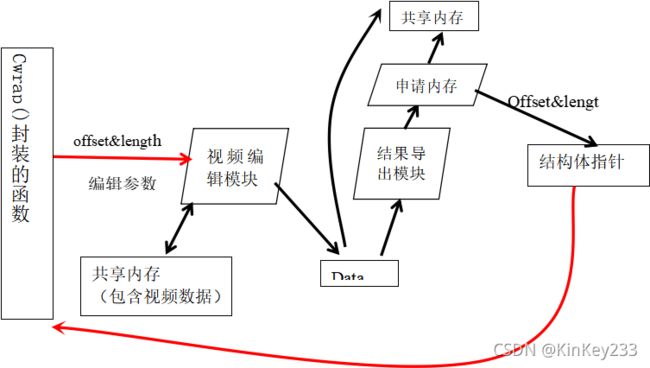
图 十二-wasm中的行为
如图十二所示,Cwrap()封装的方法进行了如下步骤:
1、获取操作参数与offset、length,传递给对应的视频编辑函数。
2、视频编辑模块根据offset、length从共享内存中读取输入视频数据。
3、将处理好的视频保存到模拟文件系统内
4、调用“结果导出模块”,读取模拟文件系统内的输出视频文件,保存到共享内存,并将该片内存的offset 和length保存到结构体指针中。
5、通过封装的方法返回该结构体指针。
3.5、模块调用逻辑
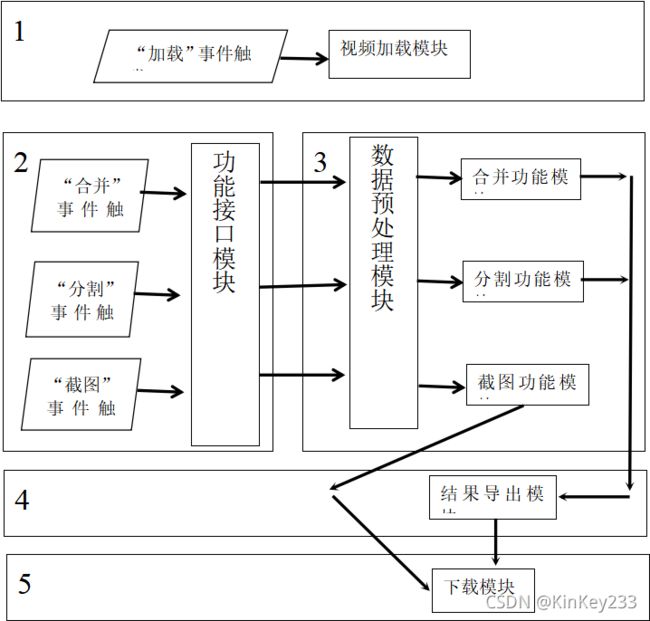
图 十三-模块调用逻辑
图十三中,每一方框左上角的数字为时间序号。
1、用户选择本地视频后,触发“加载事件”,调用“视频加载模块”,将视频导入到内存中,并获得相关参数。
2、用户点击功能按钮,触发功能事件,调用“数据预处理模块”,根据导入的参数中获取“功能模块”所需数据。
3、“数据预处理模块”处理完毕参数后,将处理好的数据传递给“功能模块”,功能模块开始工作并处理结果。
4、“结果导出模块”,将暂时保存到Emscripten文件系统中的处理结果读取到内存。
5、“视频下载模块”将内存中的视频文件,下载到本地。
3.6、功能模块概述
3.6.1、Js中的模块:
视频加载模块:
由于不能通过Cwrap()函数直接传递视频数据,依照第二章Emscripten的资料,通过共享内存传递视频数据,视频加载模块的功能应如下:
1.使用Module._malloc()在Module堆中分配内存,获取地址buffer;
2.将视频数据保存到Arraybuffer(js的数组)中,并获得视频字节长度length。
3.使用Module.HEAP8.set()将Arraybuffer中的数据拷入内存的buffer处。
功能接口模块:
该模块实质上就是使用Cwrap()函数对wasm中函数进行封装,方便传递向wasm传递操作参数,选择调用的处理模块(如合并、分割)。
该模块将视频在内存的地址buffer与视频字节长度,传递到“数据预处理模块”。
下载模块:
根据内存地址buffer以及length,读取数据到Arraybuffer中,将Arraybuffer转为Blob对象,以Blob创建URL,以供下载。
3.6.2、wasm中的模块:
数据预处理模块:
该模块将依据收到的内存地址buffer、视频字节长度length,读取视频数据,并将视频数据使用FFmpeg的库函数读取,构建好视频处理相关的结构体,以供“合并”“分割”等功能模块使用。这是三个功能模块工作的共同前提。
功能模块:
合并:将两个视频的合并成为一个新视频,并保存到Emscripten文件系统中(Data文件中)。
分割:将起始结束时间区间内的视频分割出来,并保存到文件系统中(Data文件中)。
截图:将时间点对应的视频帧截取出来,对视频帧转化成RGB格式并保存到内存中。
结果导出模块:
将暂时保存在Emscripten文件系统中的视频文件读取到内存中,返回内存位置buffer以及文件字节大小length,以供视频下载模块使用。
第四章 程序详细设计
4.1、模块包含的对象方法与参数类型
项目中常用的Js数据类型、对象以及可能承载的数据内容:
Number:64位浮点数 内存地址、文件大小、时间
Arraybuffer:数组对象 视频数据、RGB视频帧数据
项目中wasm模块中自定义的重要数据结构以及承载的数据内容:
typedef struct{
uint32_t buffLength;
uint8_t *buff;
}Video_Buffer;
typedef struct {
uint32_t width;
uint32_t height;
uint8_t *data;
} ImageData;
Video_Buffer是“合并”“分割”功能模块的返回值。
Video_Buffer结构中,buffLength表示应读取的内存长度(数据字节长度)。
buff表示内存指针。
该结构用于向js提供输出视频的内存位置。
ImageData是“截图”功能模块的返回值。
ImageData结构中 width和height分别表示截图的像素宽高,data表示保存图片数据的内存指针。
Js可以根据结构中的宽高获得图片字节大小,以便知晓读取内存片段的长度。
4.1.1、Js中的模块:
视频加载模块:
模块输入参数:File文件;
模块返回值:[Number,Number],分别代表内存地址和文件字节长度。
包含的对象或方法函数接口:
readAsArrayBuffer(file);
buffer = New Uint8Array(ArrayBuffer);
Module._malloc(length);
Module.HEAP8.set(buffer, offset);
readAsArrayBuffer(file):该方法的参数为FILE对象,该方法属于js 的FileReader对象。该方法将会把作为参数的文件对象以数组形式读取,结果是包含文件数据的Arraybuffer对象,并可触发onload事件,可实现异步读取文件内容。
buffer = New Uint8Array(ArrayBuffer):该语句将对ArrayBuffer转化为8位无符号整数值的类型化数组。
Module._malloc(buffer.length):该函数参数为Number,创建字节长度为length的内存空间,并返回起始位置offset,类型也是Number。
Module.HEAP8.set(buffer, offset):该方法将buffer数组中的数据按照字节读取并写到内存地址为offset 的内存上。完成数据拷贝。
功能接口模块:
模块输入参数:无;
模块返回值:无。
包含的对象或方法函数接口:Module.cwrap();
示例:
split_video =Module.cwrap(‘split’,‘number’, [‘number’, ‘number’, ‘number’, ‘number’]);
调用Module.cwrap(),对C中名为的“split”的函数封装。
第二个参数number,定义了返回值类型。
第三个参数为[‘number’, ‘number’, ‘number’, ‘number’],定义了传入参数的类型,这意味着需要向split()传递四个number型参数。
该模块将在浏览器加载wasm完毕后自动运行。
Js中想要调用C中的split函数,只需要调用split_video()。
下载模块:
模块输入参数:Arraybuffer;
模块返回值:无;
包含的对象或方法函数接口:
Blob;
window.URL.createObjectURL(object);
window.URL.createObjectURL():将会为object创建一个资源链接URL,以便读取或下载。本项目中,将为window.URL.createObjectURL()传递一个Blob对象。
Blob对象:在本项目中,会使用Blob对象的创建方法,将Arraybuffer转化为Blob对象,以便能够下载Arraybuffer中的视频数据。例如new Blob([Arraybuffer]);
4.1.2、wasm中的模块:
数据预处理模块:
对于不同功能模块,数据预处理模块有所差别,以“分割”功能模块的数据预处理模块为例:
模块输入参数:uint8_t *buff、int buffLength、double time_star,double time_end;
模块返回值:无;
包含的对象或方法函数接口:
(uint8_t *)av_malloc(size);
split_process(pFormatCtx, time_star, time_end);
(其它重要函数以及结构在4.2.1中讲解)
av_malloc(size):FFmpeg将malloc()函数封装为av_malloc();该函数的作用是申请size字节大小的空间。
split_process():将调用“分割”功能模块。以预处理模块的结果pFormatCtx(AVFormatContext)和时间起始结束点time_star, time_end为参数。
功能模块:
① “分割”功能模块:
模块输入参数:AVFormatContext *inputContext;double time_star,double time_end;
模块返回值:无;
包含的对象或方法函数接口: 4.2.4中讲解
② “合并”功能模块:
模块输入参数:AVFormatContext *inputContext1;AVFormatContext *inputContext2;
模块返回值:无;
包含的对象或方法函数接口: 4.2.5中讲解
③ “截图”功能模块:
模块输入参数:AVFormatContext *inputContext,double time;
模块返回值:ImageData结构体;
包含的对象或方法函数接口: 4.2.6中讲解
④ 结果导出模块:
模块输入参数:无;
模块返回值:Video_Buffer结构体;
包含的对象或方法接口:
fopen();fclose()
fseek();
ftell();
malloc();
fread();
fopen()用于打开文件,本项目中是打开暂时保存在Emscripten文件系统中的输出视频文件。fclose()关闭文件。参数为:文件路径;访问方式。
fseek()用于 移动文件指针。参数为:已打开的文件流FILE *stream;指针偏移量 long offset;偏移起始位置 int fromwhere;
ftell();计算文件指针距离文件开始的字节数。一般用于计算文件大小。参数为:文件流FILE *stream。
fread()用于将文件流中的数据保存到内存指针指向的内存片段。
4.2、分割,合并,截图实现方法:
4.2.1、ffmpeg处理视音频文件的一般流程:
在2.8.2节,已经介绍了关于FFmpeg的一般处理流程。
分为:
解复用、解码、编码、复用
四个步骤对应的FFmpeg 关键API函数如图十四:

图 十四-FFmpeg处理流程与API
解复用:这一步是通过avformat_open_input()这个API实现的。该API读出文件的头部信息,并做解复用,在此之后我们可以读出视音频流,对二者分别进行处理。
获取packet:通过av_read_frame()从AVformatContext上下文中获取packet,即经过编码的数据包。
解码:avcodec_decode_video2()以及avcodec_decode_audio4(),对包(packet)进行解码,得到帧(frame),恢复出视音频原始数据。
本项目中不涉及编码,因此不在此介绍。
复用:通过av_interleaved_write_frame()将packet写入文件。
4.2.2、简单的ffmpeg播放功能流程
由4.2.1可得出一个播放功能的实现流程:
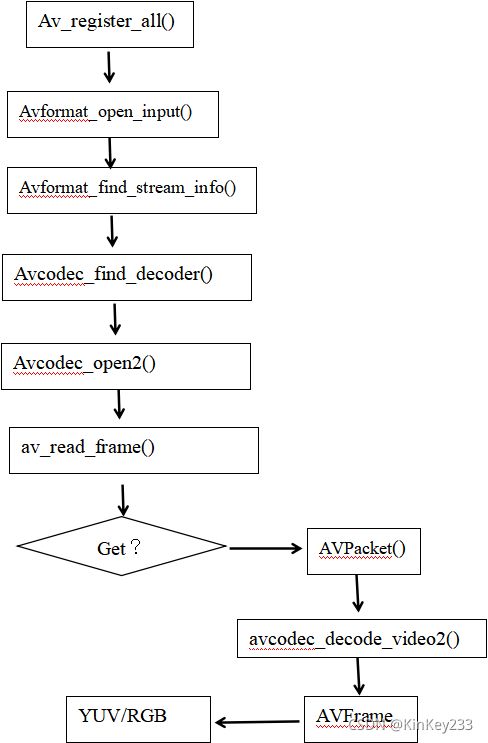
图 十五-FFmpeg解码流程图
如图十五所示:
1、Av_register_all()
该函数将会注册所有的格式。包括解封装格式和加封装格式,初始化所有组件,只有调用了该函数,才能使用复用器和编解码器。
2、Avformat_open_input(AVFormatContext **ps, char *filename, AVInputFormat *fmt,AVDictionary **option s)
第一个参数为AVFormatContext上下文,必填;
第二个参数为需要打开的媒体文件URL,必填;
第三个参数为指定的媒体格式,选填,当为空时,将会自动检测媒体文件的封装格式;
第四个参数一般不用;
该函数将会对媒体文件进行解封装和解析,结果保存在AVFormatContext上下文中。
3、Avformat_find_stream_info()
参数为载有经过解析媒体文件信息的AVFormatContext上下文。
该函数可以读取一部分视音频数据并且获得一些相关的信息,查找格式和索引。有些早期格式它的索引并没有放到头当中,需要你到后面探测,就会用到此函数。作用是为pFormatCtx->streams填充上正确的信息。
4、Avcodec_find_decoder()
参数为AVCodecContext *pCodecCtx;AVCodecContext上下文是从pFormatCtx->streams[id]->Codec属性下获取的关于流的编码信息codec_id,例如某个视频的编码信息为AV_CODEC_ID_H264,函数依据这个信息,适配解码器。
5、Avcodec_open2()
打开解码器。
6、av_read_frame()
参数为AVFormatContext上下文,该函数将读取一个packet(包)的数据,保存在AVPacket *packet中。
7、avcodec_decode_video2()
该函数将会依据先前打开的解码器对输入的属于视频流的packet解码。输出结果为frame(帧)。将frame作为sws_scale()的参数之一,设定其他配置信息,可将帧转化为RGB图片数据。
4.2.3、数据预处理模块
之前所描述的简单的ffmpeg播放功能流程,无法直接应用到项目中,原因如下:
该播放流程中,使用Avformat_open_input()解析URL所指向的媒体文件,但本项目中,媒体文件已经存在内存中,因此,在需要在调用Avformat_open_input()之前进行一些操作,以使得Avformat_open_input()能解析内存中的媒体文件数据。
对于“合并”“分割”功能,可以无需进行解码、编码。直接以packet为单位进行“合并”“分割”,而不是以frame为单位。
而数据预处理模块就是实现从内存中读取媒体文件数据,并解析、初始化AvformatContext上下文。
对于不同功能模块,数据预处理模块可能略有差别,“分割”与“截图”功能的数据预处理模块完全一致,因为两者只有一个输入视频,只需要初始化一个AvformatContext上下文,而对于“合并”功能,需要对两个输入视频分别初始化一个AvformatContext上下文。
因此,需要在avformat_open_input()前添加如下图方框内的步骤(参考文献[7])
对于分割模块的数据预处理模块:
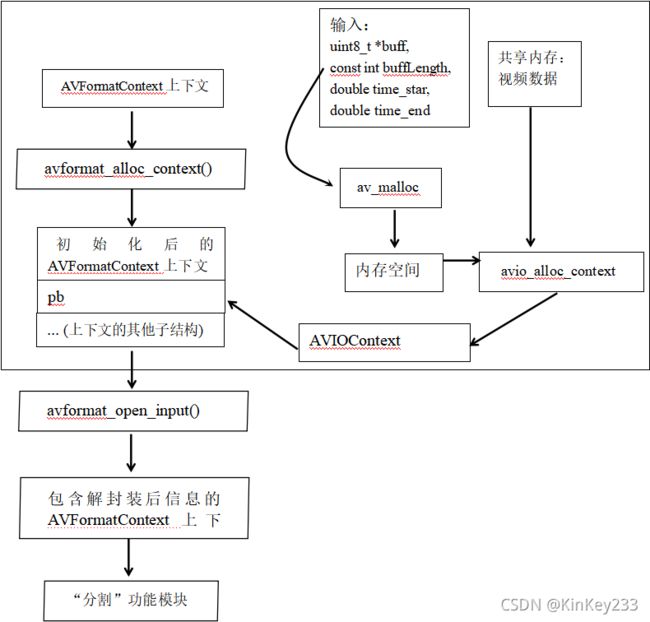
图 十六-分割模块的数据预处理模块流程
如图十六所示,步骤如下:
1、使用av_malloc()为AVIOContext 分配一段字节长度为 buffLength的内存空间。
2、使用avio_alloc_context(), 为I/0缓存申请并初始化一个AVIOContext结构。按内存指针buff和buffLength,将指定内存中的视频数据拷贝到新申请的内存中。新申请的内存指针和字节长度将会保存在AVIOContext结构中。
3、将AVFormatContext上下文中的pb指向AVIOContext上下文;至此,AVFormatContext上下文将可获得媒体文件的所有数据。
4、以AVFormatContext上下文为参数,调用avformat_open_input(),此时不必为该函数填写真实存在的URL,因为AVFormatContext上下文已经包含媒体信息。这一步完成了对媒体文件的解析(解封装)。
5、以AVFormatContext上下文和分割时间段time_star、time_end 为参数调用“分割模块”。
同理,调用“合并”功能时,必定传入两个视频,因此传递给“合并”功能模块的参数是对应两个视频的两个AVFormatContext上下文。
因此“合并”功能的数据预处理模块,只需要以上的流程基础上,重复构建另一个AVFormatContext上下文,不再赘述。
4.2.4、“分割”功能模块
如2.8节关于ffmpeg的基础知识,一个packet包含一帧图像,或者几帧音频。packet关于分割功能涉及的两个属性:,解码时间戳(dts)、显示时间戳(pts)。
包的显示时间戳,标志着packet包含的视频图像在ffmpeg时间刻度上的位置。
包的解码时间戳,标志着packet应当在ffmpeg时间刻度上何时被解码。
Pts时间戳与视频时间的换算关系:
视频时间(秒)=pts*av_q2d(time_base)
其中time_base是时间基,保存在AVFormatContext下的stream中,可以表示一秒相当于多少ffmpeg时间刻度。例如有的MP4文件的time_base如下。
名称 值 类型
◢ time_base {num=1 den=24000 } AVRational
这意味着一秒相当于ffmpeg中24000刻度。
经过av_q2d()将time_base换算成double型数值,单位为 刻度/秒。
Pts*av_q2d(time_base)结果就是pts在视频中的时间位置。
分割方式:
按包(packet)的pts(显示时间)或dts(解码时间)进行分割。
结合4.2.2节关于简单的ffmpeg播放功能流程的资料,可以改写成以下流程图。
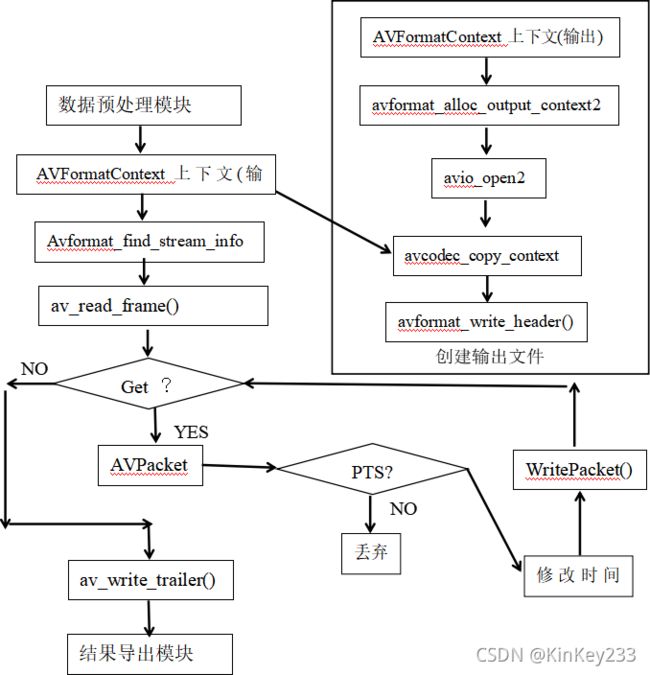
图 十七-“分割”流程图
如图十七所示:
1、从“数据预处理模块”获得装载视频信息的 AVFormatContext上下文(输入)。
对 AVFormatContext上下文(输入)使用Avformat_find_stream_info(),获取并更新关于stream的一些信息。
2、创建输出文件。如流程图右上角方框内的流程所示,使用一些列ffmpeg函数创建一个新的 AVFormatContext上下文(输出)。其中,
3、avio_open2()将打开一个用于保存输出视频数据的文件。
avcodec_copy_context()用于拷贝AVFormatContext上下文(输入)中的流的信息(例如编码信息)。
4、avformat_write_header()用于写文件头,否则视频可能无法正常播放。
5、av_read_frame(),从AVFormatContext上下文(输入)中获取一个packet。如果无法获得packet,则直接进行av_write_trailer()写文件尾,并调用结果导出模块进入下一个步骤。
6、正常获取一个packet后,按照pts计算该packet在视频时间轴上的位置,并判断是否在分割的时间区间内。如果属于该时间区间,先对该packet进行时间戳处理。时间戳处理方法将在4.2.7节具体说明。
则调用WritePacket()将packet写入文件,否则丢弃。
4.2.5、“合并”功能模块:
“合并”功能模块实现两个相同格式的视频进行时间轴上的合并。
因此,无需涉及到编解码,但需要进行packet的时间戳修改。
根据“分割”功能模块流程图改写得到以下流程图。
图 十八-合并功能流程图

如图十八所示,合并功能的实现分一下主要步骤:
1、数据预处理模块将传递两个AVformatContext给“合并模块”。
2、首先依据输入AVformatContext创建一个输出AVformatContext,并创建输出文件。
3、对第一个输入AVformatContext进行av_read_frame(),循环读取packet,直接写入输出文件。
4、写完第一个输入AVformatContext后,对第二个AVformatContext读取packet,
但需要读出来的packet进行时间戳修改。修改时间戳后再写入输出文件。
5、av_write_trailer()写文件尾,并调用结果导出模块。
处理时间戳的大体思想:
1、在第一个视频的packet全部写入输出文件后,记录最后一个packet的pts或者dts时间戳。
2、第二个视频每个packet的时间戳数值都加上第一个视频最后一个packet的时间戳。
3、实际操作上,这个方案是存在很大缺陷的。4.2.7节关键代码分析将具体说明。
4.2.6、“截图”功能模块:
简要分析:“截图”功能,意味着需要进行解码,可以直接参考4.2.2简单ffmpeg播放器的流程图。唯一不同是,如果依次遍历packet的时间戳,寻找最接近截图时间点的packet,会出现以下两个问题:
1、如果截图时间点靠后,视频较长,将会导致效率低下。
2、如果截图时间点对应的packet包含的帧不是视频关键帧,会在导致截图失败。
因此需要使用av_seek_frame对视频进行跳转。
av_read_frame()读取packet时,会有一个读标,每一次读取packet,读标后移,进而实现不重复读取同一个packet。
而av_seek_frame的作用可以理解为将读标移动到指定位置,在使用av_read_frame()读取packet。
因此设计“截图”功能流程图如下:
图 十九-截图功能流程图

如图十九所示,截图功能的实现有以下主要步骤:
1、在Avformat_find_stream_info()更新好关于stream的信息后,寻找一个视频流,并获得该视频流的编码信息codec_id。(如果是多视频流以及各个视频流编码信息不同的情况需要添加遍历所有视频流的过程)
2、以codec_id为参数,调用Avcodec_find_decoder(),寻找解码器。
3、Avcodec_open2()打开解码器
4、Av_seek_frame(),将读标跳转到指定时间节点,配置属性,可以选择跳转到时间点附近的关键帧。
5、av_read_frame(),读取一个packet。并判断该packet是否属于视频流,如果不是,则再次读取新的packet。
6、读取到指定时间点附近的视频packet后,调用avcodec_decode_video2()进行解码,获得frame(原始图像信息,帧)。
将frame作为参数调用sws_scale(),可调整输出图像格式、大小。本项目中将frame转化成前端可显示的RBG格式。
4.3、其他模块具体实现方法
视频加载模块:
图 二十-视频加载模块流程图
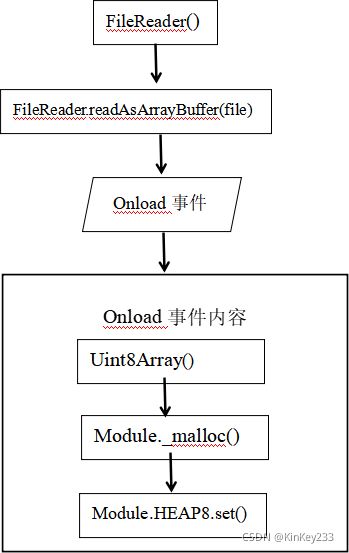
如图二十所示,步骤如下:
1、FileReader()创建一个FileReader对象。
2、readAsArrayBuffer(file);将文件按ArrayBuffer数组读取,结果为包含文件数据的ArrayBuffer。
读取完毕后触发onload事件。
3、 New Uint8Array(ArrayBuffer);
该语句将对ArrayBuffer转化为8位无符号整数值的类型化数组。
1、Module._malloc();分配内存空间用于保存ArrayBuffer中的数据。
5、Module.HEAP8.set();
该方法将数组中的数据按照字节读取并写到内存中。完成数据拷贝。
下载模块:
3.6.1节中描述了下载模块的功能——读取内存中的数据并下载。
图二十一为模块的具体实现流程:

图 二十一-下载模块流程图
1、根据功能模块返回的包含输出视频数据的内存位置和文件字节大小,调用Module.HEAPU8.subarray(),以Arraybuffer的方式读取内存片段中的数据。
2、调用window.URL.createObjectURL(),为Arraybuffer创建一个URL
3、隐式创建标签,将URL赋值给标签的href属性,执行click(),触发点击事件,实现下载。
结果导出模块:
“分割”与“合并”模块的处理结果都暂时保存在Emscripten文件系统中。
需要调用结果导出模块将Emscripten文件系统中的输出视频写到内存中,并将内存地址与文件字节长度返回前端。
流程如下:
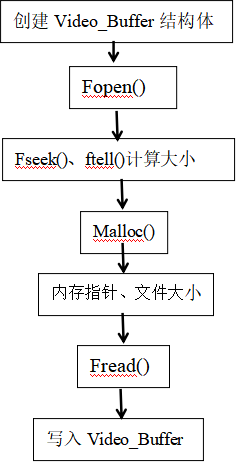
图 二十二-写入内存
这是非常典型的将文件读取到内存的流程,不再赘述。
4.4、一些关键代码分析
4.4.1、时间戳处理
对于“分割”模块:
视频文件的图像packet的显示、解码时间戳一般都是0开始。
为何要进行时间戳处理:
依照4.2.4节分割功能实现的流程图,基本思想是遍历所有packet的显示时间戳,将显示时间戳在指定范围内的packet写入到输出文件中,但此时packet需要进行时间戳修改,否则将会导致——输出视频播放总时长与输入视频一样,但只有分割时间段内存在视频画面和声音,其余时间段都是“无声黑屏”。
如何进行时间戳处理:
1、记录符合指定范围的第一个packet的显示时间戳。
2、执行av_interleaved_write_frame()写packet入文件前,对每一个packet的pts和dts减去第一个packet的显示时间戳数值。
packet->pts -= firstpts;//firstpts是指符合条件的第一个packet的显示时间戳
packet->dts -= firstpts;
…//省略部分为packet的时间基转换。
av_interleaved_write_frame(outputContext, packet);
对于“合并”模块:
如果直接套用“分割”模块的时间戳处理,即记录第一个视频文件的最后一个packet的pts或者dts,在第二个视频文件的所有packet写入前,都加上先前记录的数值。
将会导致以下问题:
[mp4 @ 0000017d646f51a0] Application provided invalid, non monotonically increasing dts to muxer in stream 0: 3685888 >= 3685421
错误分析:该错误原因是视频时间戳出问题,ffmpeg需要视音频的时间戳递增,如果该packet的时间戳比先前写入的packet的时间戳小,则该packet会被丢弃。最终输出视频异常如下:
1、第一段视频结尾异常,两段视频交界处的时间段花屏,第二段视频开头缺失。
2、结尾出现最后一帧的静止画面。
依照函数执行的先后顺序不同,错误结果:
1、
packet->pts += firstpts;
packet->dts += firstpts;
. …//省略部分为packet的时间基处理
av_interleaved_write_frame(outputContext, packet);
错误结果同上
2、
…//省略部分为packet的时间基处理
packet->pts += firstpts;
packet->dts += firstpts;
av_interleaved_write_frame(outputContext, packet);
此时输出视频异常情况:
处理过程未报时间戳错误,但输出视频时间轴错乱——正常播放时,第一段视频的内容完整,第二段视频开头数秒片段缺失,但通过拖动进度条回放,可以完整播放第二段视频。这意味着和两段视频有一部分存在时间戳重叠。
通过遍历一个MP4样片的packet,观察时间戳变化以及所属流的变化:
图 二十三-某视频packet时间戳变化

如图二十三所示:
其中pts0表示该packet属于视频流,pts1表示该packet属于音频流;
可见:视音频流的增长关系不一致;属于视频流的若干个packet连续被读取。
因此,在合并时,记录第一段视频的最后一个packet的时间戳是无意义的。
正确的“合并”时间戳处理:
分别记录视频流、音频流的最后一个packet的时间戳
第二段视频的packet写入文件前,按照所属流,减去记录中对应的时间戳,例如视频流的packet时间戳减去第一段视频最后一个属于视频流的packet的时间戳。
对于第二段视频的所有属于视频流的packet作以下处理。
packet->pts += lastpts_video + 1;
//lastpts_video 为第一段视频最后一个视频流packet的时间戳。
//+1是为了避免第二段视频的第一个packet时间戳与第一段视频的最后一个 //packet时间戳相等的//情况而报错
packet->dts += lastpts_video+ 1;
…//省略部分为对packet的时间基转换
av_interleaved_write_frame(outputContext, packet);
4.4.2、JS读取wasm返回值方法
在4.1节说明了两个用于返回前端的结构体,在此将介绍如何在前端利用这这两个结构体。
对于typedef struct{
uint32_t buffLength;
uint8_t *buff;
}Video_Buffer;
Wasm返回JS的实际上是Video_Buffer结构体指针,设为ptr。
先读取输出视频文件的字节大小buffLength,buffLength是32位无符号整型,因此,
bufferlength = Module.HEAPU32[ptr / 4];
Module.HEAPU32可以理解为使用一个32位的“视窗”读取ptr。一次读取32位数据,恰好对应buffLength所占位数。

图 二十四-内存读取示意图
ptr / 4是因为Module.HEAPU32一个单位32位,而ptr一个单位8位,因此需要将ptr/4,获得Module.HEAPU32“视窗”下的正确索引。
获取buffLength后,将“视窗”向后移动一单位,并读取buff指针。
BufferPtr = Module.HEAPU32[ptr / 4 + 1]
当然也可以改成
Buff = Module.HEAPU8[ptr+4+1]
获取buff指针后,使用
Module.HEAPU8.subarray(Buff, Buffer+ bufferlength+1);
以8位“视窗”读取Buff到Buffer+ bufferlength+1之间的数据,并保存为Arraybuffer。
之后调用下载模块,最终将Video_Buffer指示的内存数据下载。
typedef struct {
uint32_t width;
uint32_t height;
uint8_t *data;
} ImageData;
ImageData同理,不再赘述。
4.5、环境配置信息
系统:Ubuntu 18.04.4 LTS
虚拟系统软件:VMware
环境项目 版本
Node 12.9.1-64bit
python 2.7
Emscripten 1.39.12
clang 11.0.0
Cmake 3.17.1
Python-2.7 2.7.17
表 1-环境信息表
4.6、编译C与FFmpeg为wasm
4.6.1、编译FFmpeg步骤
参照文献[2][3]得出以下步骤与命令:
1、下载FFmpeg3.3.3版本的源文件
2、解压到ffmpeg3.3文件夹中
3、打开终端并进入ffmpeg3.3中执行以下命令:
CPPFLAGS="-D_POSIX_C_SOURCE=200112 -D_XOPEN_SOURCE=600" emconfigure ./configure --cc=“emcc” --cxx=“em++” --ar=“emar” --prefix=$(pwd)/dist --enable-cross-compile --target-os=none --arch=x86_64 --cpu=generic --enable-gpl --enable-version3 --disable-postproc --disable-parsers --disable-ffplay --disable-ffprobe --disable-asm --disable-doc --disable-devices --disable-hwaccels --disable-bsfs --disable-debug --disable-indevs --disable-outdevs --disable-network --disable-w32threads --disable-pthreads --enable-ffmpeg --enable-static --disable-shared --enable-lto --enable-decoder=pcm_mulaw --enable-decoder=pcm_alaw --enable-decoder=adpcm_ima_smjpeg --enable-decoder=aac --enable-decoder=hevc --enable-decoder=h264 --enable-protocol=file --disable-stripping
这条命令用来生成Makefile,确认一些编译的环境和参数,关闭不需要的或者不支持wasm的特性
4、在管理员模式下执行make
5、sudo make install
执行完以上步骤,可以在ffmpeg3.3文件夹下找到一个dist文件夹。
该文件夹包含bin、include、lib、share四个文件夹,同时FFmepg3.3文件夹下将出现名为FFmpeg(没有后缀)的文件,表示编译make成功。
手动将Include 文件夹下含有的.a 后缀文件全部改为.bc。
4.6.2、C与FFmpeg编译成wasm
步骤:
1、检查终端窗口中emcc命令的可用性。
2、编写好调用ffmpeg API 实现所需功能的C程序。
3、将C程序以及所需要的非ffmpeg头部依赖,放在dist文件夹内,执行以下命令:
emcc -I/home/kinkey/ffmpeg3.3/dist/include web.c process.c ./lib/libavformat.bc ./lib/libavcodec.bc ./lib/libswscale.bc ./lib/libswresample.bc ./lib/libavutil.bc -Os -s WASM=1 -o index.html --preload-file out.mp4 -s EXTRA_EXPORTED_RUNTIME_METHODS=’[“ccall”, “cwrap”]’ -s ALLOW_MEMORY_GROWTH=1 -s TOTAL_MEMORY=16777216
其中:-I/home/kinkey/ffmpeg3.3/dist/include的作用是为emcc指定寻找头文件的路径,如果不设置该路径,将会出现寻找ffmpeg头文件失败的情况。
web.c 、process.c包含功能函数的实现。
libavformat.bc\libavcodec.bc\libswscale.bc 等文件是编译ffmpeg时产生的。
–preload-file 是启用Emscripten文件系统,out.mp4是希望预先保存到Emscripten文件系统的文件,此举将会产生一个data文件。这个文件包含out.mp4的信息。
EXTRA_EXPORTED_RUNTIME_METHODS=’[“ccall”, “cwrap”]’ 表示要导出ccall和cwrap两个函数,这两个函数能够调用C里写的函数(如果该函数不在main中,需要在函数前添加EMSCRIPTEN_KEEPALIVE宏)。
4.7、简单前端页面设计
由第三章程序概要设计进行前端页面功能设计。
1、三个文件输入框:
第一个用于输入将要执行“分割”操作的视频文件。
三个用于输入用于执行“合并”操作的视频文件。
2、时间输入框:用于手动设置“分割”“截图”操作的起始结束时间。
3、视频播放窗口:用于页面上播放需要进行“分割”的视频。
4、对视频播放操作的功能按键:播放/暂停、减速/加速播放、正常播放。
5、视频处理功能按键:“分割”、“合并”、“截图”。
6、获取视频当前播放时间的功能按钮:用于自动获取播放器当前进度的时间点,自动设置原本需要手动设置的时间。
具体页面展示如图二十五:
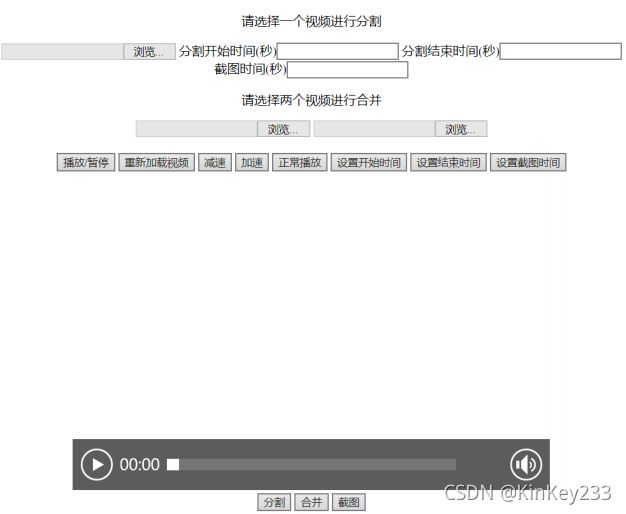
图 二十五-html页面图
操作流程:
1、进行视频分割:
① 在第一个文件输入框选择要分割的视频。该视频会在页面上播放。
② 选择截取的时间区间:可以手动在相应输入框内填写分割时间或者通过使用 “设置开始时间”“设置结束时间”从视频播放窗口的进度条上自动获取。
③ 点击“分割”按钮。
④ 下载文件
2、进行视频合并:
① 在第三、第四个输入框选择要合并的视频。
② 点击“合并”按钮。
③ 下载文件
3、截取视频图片:
① 在第一个输入框选择视频文件。
② 在对应输入框填写截图时间。
③ 点击“截图”。
④ 下载文件
第五章 调试与运行
5.1、同源策略问题
编写好html并将wasm模块、data文件、js胶水代码保存到同一文件夹下,进行本地运行。
分别使用Edge、Firefox、QQ浏览器、Chrome打开html页面。
未对浏览器进行额外设置,以File协议打开html情况如下:
Edge运行正常,Firefox、QQ浏览器、Chrome均报关于“CORS policy”的错误。
错误内容:已拦截跨源请求,同源策略禁止读取位于****的远程资源。
分析原因:
根据查找“CORS policy”相关文献[6],CORS(跨域资源共享)请求只能使用HTTPS URL方案,
而使用File协议打开页面时,依照最新的同源策略,同一目录或其子目录中的其他资源不再满足 CORS 同源规则,被阻止获取本地文件wasm。
两个解决方案:
1、修改浏览器设置,例如对Firefox设置,寻找privacy.file_unique_origin,关闭该功能。
2、使用xampp等软件,创建一个本地服务器,以http协议打开html。
5.2、内存问题
在浏览器上运行时,观察内存大小变化情况。
1、对489MB 的MP4视频进行两次“分割”操作,内存变化情况如下:

图 二十六-总内存监视图1
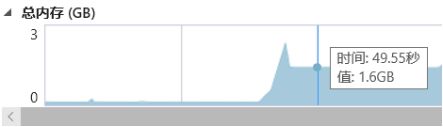
图 二十七-总内存监视图2
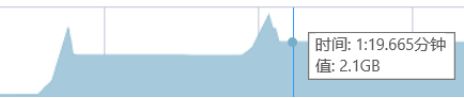
图 二十八-总内存监视图3
由图二十六、图二十七可见:
489MB的视频执行“分割”操作时,总内存峰值大约2.5GB,大约是视频的5倍,执行完毕后,总内存下降到1.6GB,大约是视频的3倍。
原因分析:
我在使用FFmpeg API 编写功能模块时,不可避免得创建结构体并申请内存存放视频数据,例如,js脚本创建Arraybuffer存放视频数据,其次再调用Module的方法在wasm模块中申请内存,用于拷贝Arraybuffer中的数据,这两步执行时占用了两倍视频大小的内存,而且加上在编辑视频功能执行时创建的各种内存,总量达到2.5GB,属于正常情况。
其次,最后总内存保持在了1.6GB,查看堆快照,Arraybuffer类型占了1.45GB,原因是wasm申请的空间不会被自动释放。
但通过图二十八可见,重复执行分割操作,实行结束后总内存变成2.1GB,相比之前大了0.5GB,相当于该视频文件的大小。这意味着wasm中存在可被释放的内存,但没有被释放。
解决思路:
需要对C代码进行优化,排查,释放内存。
通过新窗口下载输出文件,同时重新加载页面,则无需考虑释放内存问题。
以下尝试通过第一条思路解决内存增长问题:
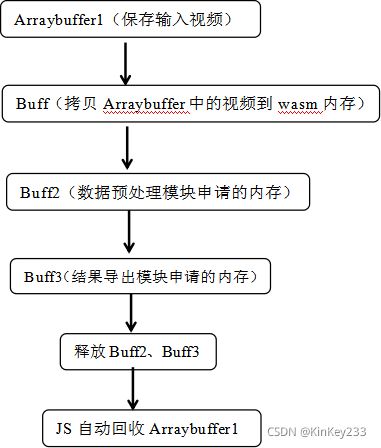
图 二十九-改进前内存申请释放图
经整理,如图二十九所示,旧版本没有释放在js中调用Module._malloc()申请的Buff所占用的内存,而重复实行“分割”功能时,会导致Buff指向新申请的内存,而旧内存没有释放,因此会导致重复执行功能,总内存占用上升一个视频的大小。
改进处理:在数据预处理模块拷贝Buff中的数据后,释放Buff。在结果导出模块申请Buff3前,释放Buff2。
改进结果如图三十所示:
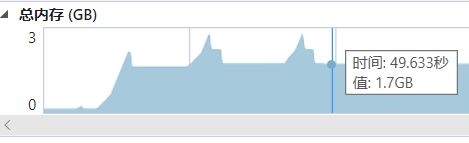
图 三十-改进后的总内存变化图
经过改进后,对489MB的视频重复执行“分割”功能后,总内存保持在1.7GB,不再递增。
2、对573MB大小的视频进行“分割”操作,内存变化情况如下:

图 三十一-总内存监视4
无返回输出视频,并且控制台报错如下:
SCRIPT7017: SCRIPT7017: Memory index is out of range
原因分析:
Wasm模块运行时峰值内存超出了限制,只能通过改良wasm模块的代码。但从现实角度看,对一个大于500MB的视频进行编辑时,wasm模块相比本地视频编辑软件,可能没有优势。
5.3、功能问题
5.3.1、视频分割花屏问题
问题描述:
对视频分割后,视频开头部分播放出现花屏或者黑屏,一段时间后播放正常。
分析原因:
视频帧分为I|、P、B三种类型,其中I是关键帧,包含一张图像所有像素信息,P帧为单向预测帧,需要根据前一帧图像的信息才能正确显示,B帧为双向预测帧,根据前后两帧画面的信息才能正确显示。
目前,分割功能的实现只是循环读取packet并判断packet时间戳对应的视频时间是否在截取时间区间内,是,则写入,否则丢弃,因此存在输出视频的前几秒因为丢失关键帧而花屏的情况。
解决思路:
1、使用av_seek_frame函数,将av_read_frame函数的读针跳转到分割视频起始时间对应的前一个关键帧,从此帧开始写入文件。
但是该思路存在一个问题,当某一特殊视频关键帧间隔时长较大时,截取出来的视频长度可能会很长。其次,av_seek_frame对于一些视频格式,存在定位不准的问题。
3、采取类似“播放器”的流程,将时间区间前后的视频包全部解码成frame,转换成视频图像,再编码回packet,以此解决开头缺失关键帧的问题。
5.3.2、不同视频合并异常问题
问题描述:
对不同格式的媒体文件合并可能会出现关于时间戳的错误,例如:
Application provided invalid, non monotonically increasing dts to muxer in stream 0: 66404352 >= 55332097
或者
[mp4 @ 0000021b1e353c80] Application provided invalid, non monotonically increasing dts to muxer in stream 0: 66404352 >= 55332097
分析原因:
在合并功能模块处理时间戳的环节,存在一个调整时间戳的代码,如下:
av_packet_rescale_ts1(packet, inputStream->time_base, outputStream->time_base);
函数将packet的pts和dts按照来源视频时间基和输出视频时间基的值进行转换。
例如:A视频的时间基为{1,90000},B视频的时间基为{1,24000},那么某一个A视频的packet解码时间戳是90000,那么当该packet存放到B视频中,解码时间戳需要按照两者时间基比例进行转换,Dts =90000在A视频对应1秒,当存放到B视频时,dts应转换为 24000。
合并功能需要处理第二段视频的起始时间戳,当前,未考虑视频不同时间基的问题。
当前合并功能调整时间戳的方法如4.4.1节所示:将第二段视频packet的时间戳分别加上第一段视频最后一个相同流的packet的时间戳,再进行时间基转换,写入输出文件。
但这个做法在时间基不同的视频合并时,将出现异常。
尝试过的解决思路:
1、设置输出视频的时间基与第一段视的一致。
2、分别记录第一段视频不同流的最后一个packet的dts、pts。
3、在处理第二段视频的packet的pts、dts时,先将之前记录的时间戳,依照两者时间基的不同,转换成第二段视频时间基下的时间戳。再将第二段视频的packet时间戳加上转化后的时间戳,然后进行一次packet时间基转换,转换成输出视频的时间基,最后写入到输出文件。
该思路存在的问题:输出视频包含并能正常播放第一段视频,视频总时长等于两段视频之和,但当轮到第二段视频播放时,声音正常,但画面静止在第一段视频的最后一帧。尚未解决该问题。
参考文献
[1]Lin Clark.WebAssembly Interface Types: Interoperate with All the Things![EB/OL].https://hacks.mozilla.org/2019/08/webassembly-interface-types/,2019-8-21.
[2]李银城.wasm + ffmpeg实现前端截取视频帧功能[EB/OL].https://zhuanlan.zhihu.com/p/40786748,2018-7-29.
[3]hang8756.使用en编译ffmpeg库[EB/OL].https://blog.csdn.net/congbai1203/article/details/87003100,2019-7-21.
[4]Yifeng Wang一个白学家眼里的 WebAssembly[EB/OL].https://zhuanlan.zhihu.com/p/102692865,2020-1-14.
[5]丁尔男,柴树杉.WebAssembly标准入门[M].人民邮电出版社:北京市,2018-11-01:129.
[6]Mozilla contributors.CORS 请求不是 HTTP[EB/OL].https://developer.mozilla.org/zh-CN/docs/Web/HTTP/CORS/Errors/CORSRequestNotHttp,2019-7-15.
[7]雷霄骅.ffmpeg 从内存中读取数据(或将数据输出到内存)[EB/OL].https://blog.csdn.net/leixiaohua1020/article/details/12980423,2014-7-24.
附录
1、web.h 代码
#include
#include “libavcodec/avcodec.h”
#include “libavformat/avformat.h”
#include “libswscale/swscale.h”
#include “process2.h”
#include
#include
int read_packet(void *opaque, uint8_t *buf, int buf_size);
int read_packet2(void *opaque, uint8_t *buf, int buf_size);
Video_Buffer *result1;
typedef struct {
uint8_t *ptr;
size_t size;
} buffer_data;
buffer_data bufferData;
buffer_data bufferData2;
EMSCRIPTEN_KEEPALIVE
void free_video_buffer(){
if ((result1->buff)!=NULL){
free(result1->buff);
result1->buff = NULL;
fprintf(stdout, “===已释放Video_buffer=\n”);
}
}
void clean_data(){
FILE* file = fopen(“out.mp4”, “w+”);
fclose(file);
fprintf(stdout, “===已释放data=\n”);
}
int read_packet(void *opaque, uint8_t *buf, int buf_size) {
buf_size = FFMIN(buf_size, bufferData.size);
if (!buf_size)
return AVERROR_EOF;
// printf("ptr:%p size:%zu bz%zu\n", bufferData.ptr, bufferData.size, buf_size);
/* copy internal buffer data to buf */
memcpy(buf, bufferData.ptr, buf_size);
bufferData.ptr += buf_size;
bufferData.size -= buf_size;
return buf_size;
}
int read_packet2(void *opaque, uint8_t *buf, int buf_size) {
buf_size = FFMIN(buf_size, bufferData2.size);
if (!buf_size)
return AVERROR_EOF;
// printf("ptr:%p size:%zu bz%zu\n", bufferData.ptr, bufferData.size, buf_size);
/* copy internal buffer data to buf */
memcpy(buf, bufferData2.ptr, buf_size);
bufferData2.ptr += buf_size;
bufferData2.size -= buf_size;
return buf_size;
}
int main () {
av_register_all();
fprintf(stdout, “ffmpeg init done\n”);
return 0;
}
//split 函数是从指针buff处,读取长度为buffLength的视频数据,从中截取time_star到
//time_end(单位秒)之间的视频并返回Video_Buffer结构体
//Video_Buffer结构体定义在process.h
EMSCRIPTEN_KEEPALIVE //这个宏表示这个函数要作为导出的函数
Video_Buffer *split(uint8_t *buff, const int buffLength, double time_star,double time_end) {
size_t avio_ctx_buffer_size = buffLength;
bufferData.ptr = buff; /* will be grown as needed by the realloc above */
bufferData.size = buffLength; /* no data at this point */
AVFormatContext *pFormatCtx = avformat_alloc_context();
uint8_t *avioCtxBuffer = (uint8_t *)av_malloc(avio_ctx_buffer_size);
/* 读内存数据 */
AVIOContext *avioCtx = avio_alloc_context(avioCtxBuffer, avio_ctx_buffer_size, 0, NULL, read_packet, NULL, NULL);
pFormatCtx->pb = avioCtx;
pFormatCtx->flags = AVFMT_FLAG_CUSTOM_IO;
if (avformat_open_input(&pFormatCtx, "whatever", NULL, NULL) < 0) {
fprintf(stderr, "Could not open input\n");
fprintf(stdout, "wu_fa_avformat_open_input\n");
return NULL;
}
av_dump_format(pFormatCtx, 0, "", 0);
//这里调用截取视频的函数
free(buff);
buff = NULL;
split_process(pFormatCtx, time_star, time_end);
// 清掉在js申请的内存,在js使用module释放buff失败。
//printf("已释放buff");
//CloseInput();
//CloseOutput();
//释放顺序不能变
avformat_close_input(&pFormatCtx);
av_free(avioCtx->buffer);
av_free(avioCtx);
av_free(avioCtxBuffer);
result1=get_outfile_buffer();
clean_data();
return result1;
}
EMSCRIPTEN_KEEPALIVE //这个宏表示这个函数要作为导出的函数
Video_Buffer *combin_api(uint8_t *buff,uint8_t *buff2, const int buffLength,const int buffLength2) {
size_t avio_ctx_buffer_size = buffLength;
bufferData.ptr = buff; /* will be grown as needed by the realloc above */
bufferData.size = buffLength; /* no data at this point */
AVFormatContext *pFormatCtx_combin1 = avformat_alloc_context();
uint8_t *avioCtxBuffer_combin1 = (uint8_t *)av_malloc(avio_ctx_buffer_size);
/* 读内存数据 */
AVIOContext *avioCtx_combin1 = avio_alloc_context(avioCtxBuffer_combin1, avio_ctx_buffer_size, 0, NULL, read_packet, NULL, NULL);
pFormatCtx_combin1->pb = avioCtx_combin1;
pFormatCtx_combin1->flags = AVFMT_FLAG_CUSTOM_IO;
if (avformat_open_input(&pFormatCtx_combin1, "whatever", NULL, NULL) < 0) {
fprintf(stderr, "Could not open input\n");
fprintf(stdout, "wu_fa_avformat_open_input\n");
return NULL;
}
av_dump_format(pFormatCtx_combin1, 0, "", 0);
size_t avio_ctx_buffer_size2 = buffLength2;
bufferData2.ptr = buff2; /* will be grown as needed by the realloc above */
bufferData2.size = buffLength2; /* no data at this point */
AVFormatContext *pFormatCtx_combin2 = avformat_alloc_context();
uint8_t *avioCtxBuffer_combin2 = (uint8_t *)av_malloc(avio_ctx_buffer_size2);
/* 读内存数据 */
AVIOContext *avioCtx_combin2 = avio_alloc_context(avioCtxBuffer_combin2, avio_ctx_buffer_size2, 0, NULL, read_packet2, NULL, NULL);
pFormatCtx_combin2->pb = avioCtx_combin2;
pFormatCtx_combin2->flags = AVFMT_FLAG_CUSTOM_IO;
if (avformat_open_input(&pFormatCtx_combin2, "whatever", NULL, NULL) < 0) {
fprintf(stderr, "Could not open input\n");
fprintf(stdout, "wu_fa_avformat_open_input\n");
return NULL;
}
av_dump_format(pFormatCtx_combin2, 0, "", 0);
free(buff2);
buff2 = NULL;
free(buff);
buff = NULL;
//释放js传递进来的内存
//这里调用截取视频的函数
//combin_process(pFormatCtx_combin1,pFormatCtx_combin2,avioCtx_combin1,avioCtxBuffer_combin1,avioCtx_combin2,avioCtxBuffer_combin2);
combin_process(pFormatCtx_combin1,pFormatCtx_combin2);
// 清掉内存
/*free(buff2);
//buff2 = NULL;
//free(buff);
//buff = NULL;
//CloseInput();
//CloseOutput();
//
*/
avformat_close_input(&pFormatCtx_combin1);
av_free(avioCtx_combin1->buffer);
av_free(avioCtx_combin1);
av_free(avioCtxBuffer_combin1);
avformat_close_input(&pFormatCtx_combin2);
av_free(avioCtx_combin2->buffer);
av_free(avioCtx_combin2);
av_free(avioCtxBuffer_combin2);
result1=get_outfile_buffer();
//fprintf(stdout, “===合并,完成内存释放=\n”);
clean_data();
return result1;
}
EMSCRIPTEN_KEEPALIVE //这个宏表示这个函数要作为导出的函数
ImageData *getimage(uint8_t *buff, const int buffLength, double timeStamp) {
unsigned char *avio_ctx_buffer = NULL;
// 对于普通的mp4文件,这个size只要1MB就够了,但是对于mov/m4v需要和buff一样大
size_t avio_ctx_buffer_size = buffLength;
// AVInputFormat* in_fmt = av_find_input_format("h265");
bufferData.ptr = buff; /* will be grown as needed by the realloc above */
bufferData.size = buffLength; /* no data at this point */
AVFormatContext *pFormatCtx = avformat_alloc_context();
uint8_t *avioCtxBuffer = (uint8_t *)av_malloc(avio_ctx_buffer_size);
/* 读内存数据 */
AVIOContext *avioCtx = avio_alloc_context(avioCtxBuffer, avio_ctx_buffer_size, 0, NULL, read_packet, NULL, NULL);
pFormatCtx->pb = avioCtx;
pFormatCtx->flags = AVFMT_FLAG_CUSTOM_IO;
/* 打开内存缓存文件, and allocate format context */
// pFormatCtx->probesize = 10000 * 1024;
// pFormatCtx->max_analyze_duration = 100 * AV_TIME_BASE;
if (avformat_open_input(&pFormatCtx, "", NULL, NULL) < 0) {
fprintf(stderr, "Could not open input\n");
return NULL;
}
av_dump_format(pFormatCtx, 0, "", 0);
ImageData *result_image = image_process(pFormatCtx, timeStamp);
// 清掉内存
avformat_close_input(&pFormatCtx);
av_free(avioCtx->buffer);
av_free(avioCtx);
av_free(avioCtxBuffer);
return result_image;
}
2、process.h 代码
#include “libavcodec/avcodec.h”
#include “libavformat/avformat.h”
#include “libswscale/swscale.h”
typedef struct{
uint32_t buffLength;
uint8_t *buff;
}Video_Buffer;
typedef struct {
uint32_t width;
uint32_t height;
uint8_t *data;
} ImageData;
//第一个参数请看web.c 里split函数中 第70行
//第二个参数为截取的视频片段开始时间、第三参数为该片段的结束时间
//返回值存在 Video_Buffer
//*buff 储存提取出来的视频的内存的指针。
//buffLength 为提取出来的视频文件的比特长度。
//需要为截取的视频写好文件头、文件尾,存入buff指针对应内存中。
void split_process (AVFormatContext *inputContext,double time_star,double time_end);
Video_Buffer *get_outfile_buffer();
void av_packet_rescale_ts1(AVPacket *pkt, AVRational src_tb, AVRational dst_tb) ;
Video_Buffer *combin_process(AVFormatContext *inputContext1, AVFormatContext *inputContext2) ;
ImageData *image_process (AVFormatContext *pFormatCtx, double timeStamp);
int findVideoStream (AVFormatContext *pFormatCtx);
AVCodecContext *openCodec (AVCodecContext *pCodecCtx);
AVFrame *initAVFrame (AVCodecContext *pCodecCtx, uint8_t **frameBuffer);
AVFrame *readAVFrame (AVCodecContext *pCodecCtx, AVFormatContext *pFormatCtx,
AVFrame *pFrameRGB, int videoStream, double timeStamp);
uint8_t *getFrameBuffer(AVFrame *pFrame, AVCodecContext *pCodecCtx);
3、process.c 代码
#include “process2.h”
#include
#include
FILE *fp_write;
AVFormatContext *outputContext= NULL;
//int64_t lastReadPacktTime;
ImageData *imageData = NULL;
int write_buffer(void *opaque, uint8_t *buf, int buf_size) {
if (!feof(fp_write)) {
int true_size = fwrite(buf, 1, buf_size, fp_write);
return true_size;
}
else {
return -1;
}
}
int WritePacket(AVPacket *packet, int64_t firstpts,AVFormatContext *inputContext)
{
AVStream *inputStream = inputContext->streams[packet->stream_index];
AVStream *outputStream = outputContext->streams[packet->stream_index];
packet->pts -= firstpts;
packet->dts -= firstpts;
av_packet_rescale_ts1(packet, inputStream->time_base, outputStream->time_base);
int ret99 = av_interleaved_write_frame(outputContext, packet);
av_packet_unref(packet);
return ret99;
}
int WritePacket_combin(AVPacket *packet, int64_t firstpts,AVFormatContext *inputContext11)
{
AVStream *inputStream = inputContext11->streams[packet->stream_index];
AVStream *outputStream = outputContext->streams[packet->stream_index];
//packet->pts -= firstpts;
//packet->dts -= firstpts;
//int64_t first = -1;
//first =( firstpts * av_q2d(outputStream->time_base))/ av_q2d(inputStream->time_base);
packet->pts += firstpts+1 ;
packet->dts += firstpts+1;
av_packet_rescale_ts1(packet, inputStream->time_base, outputStream->time_base);
//packet->pts += firstpts;
//packet->dts += firstpts;
int ret99 = av_interleaved_write_frame(outputContext, packet);
av_packet_unref(packet);
return ret99;
}
void av_packet_rescale_ts1(AVPacket *pkt, AVRational src_tb, AVRational dst_tb) {
if (pkt->pts != AV_NOPTS_VALUE)
pkt->pts = av_rescale_q(pkt->pts, src_tb, dst_tb);
if (pkt->dts != AV_NOPTS_VALUE)
pkt->dts = av_rescale_q(pkt->dts, src_tb, dst_tb);
if (pkt->duration > 0)
pkt->duration = av_rescale_q(pkt->duration, src_tb, dst_tb);
}
AVPacket *ReadPacketFromSource(AVFormatContext *inputContext)
{
AVPacket *packet = av_packet_alloc();
if (av_read_frame(inputContext, packet) >= 0)
{
return packet;
}
else
{
av_packet_free(&packet);
return NULL;
}
}
void CloseOutput()
{
if (outputContext != NULL)
{
av_write_trailer(outputContext);
avformat_close_input(&outputContext);
}
//AVFormatContext *outputContext= NULL;
}
int OpenOutput(AVFormatContext *inputContext, char *outUrl)
{
if (avformat_alloc_output_context2(&outputContext, NULL, NULL, outUrl)<0)
{
fprintf(NULL, AV_LOG_ERROR, "open output context failed\n");
}
if (avio_open2(&outputContext->pb, outUrl, AVIO_FLAG_WRITE, NULL, NULL)<0)
{
fprintf(NULL, AV_LOG_ERROR, "open avio failed");
}
for (int i = 0; i < inputContext->nb_streams; i++)
{
AVStream * stream = avformat_new_stream(outputContext, inputContext->streams[i]->codec->codec);
if (avcodec_copy_context(stream->codec, inputContext->streams[i]->codec)< 0)
{
fprintf(NULL, AV_LOG_ERROR, "copy coddec context failed");
}
outputContext->streams[i]->time_base = inputContext->streams[i]->time_base;
stream->codec->codec_tag = 0;
}
if (avformat_write_header(outputContext, NULL) < 0)
{
fprintf(NULL, AV_LOG_ERROR, "format write header failed");
}
fprintf(NULL, AV_LOG_FATAL, " Open output file success %s\n", outUrl);
return NULL;
}
void split_process (AVFormatContext *inputContext,double time_star,double time_end){
//Video_Buffer *result2 = NULL;
if (avformat_find_stream_info(inputContext, NULL) < 0) {
fprintf(stderr, "Could not find_stream_info\n");
//return NULL;
}
OpenOutput(inputContext,"out.mp4");
int64_t firstpts = -1;
int64_t firstpts_video = -1;
int64_t firstpts_audio= -1;
int key_video = 1;
int key_audio = 1;
double pts2time = av_q2d(inputContext->streams[0]->time_base);
double packet_time = -1;
double packet_start = 0;
double packet_end = 0;
packet_start = time_star/pts2time;
packet_end = time_end/pts2time;
int key=1;
while (1)
{
AVPacket *packet = av_packet_alloc();
packet = ReadPacketFromSource(inputContext);
if (packet)
{
/*if ((packet)->pts <= packet_end) {
if ((packet)->pts >= packet_start) {
if (packet->stream_index ==0){
if (key_video){
key_video = 0;
firstpts_video = packet->pts;
}
WritePacket(packet, firstpts_video,inputContext);
}
if (packet->stream_index ==1){
if (key_audio){
key_audio = 0;
firstpts_audio = packet->pts;
}
WritePacket(packet, firstpts_audio,inputContext);
}
}
}*/
packet_time = ((packet)->pts)*pts2time;
if (firstpts >= 0) {
if (packet_time > time_end) {
break;
}
}
if (packet_time == 0&&time_star>0) {
WritePacket(packet,0 ,inputContext);
}
if (packet_time >= time_star) {
if (firstpts < 0 && key == 1) {
firstpts =( packet)->pts;
key = 0;
}
//printf("%lf\n",packet_time);
WritePacket(packet, firstpts,inputContext);
}
}
else
{
break;
}
}
CloseOutput();
//Close_in_process(inputContext);
//result2=get_outfile_buffer();
//return result2;
//
}
Video_Buffer *combin_process(AVFormatContext *inputContext1, AVFormatContext *inputContext2) {
Video_Buffer *result_combin = NULL;
if (avformat_find_stream_info(inputContext1, NULL) < 0) {
fprintf(stderr, "Could not find_stream1_info\n");
//return NULL;
}
if (avformat_find_stream_info(inputContext2, NULL) < 0) {
fprintf(stderr, "Could not find_stream2_info\n");
//return NULL;
}
OpenOutput(inputContext1, "out.mp4");
int64_t lastpts0 = -1;
int64_t lastpts1 = -1;
int64_t lastpts = -1;
//int key = 1;
//double pts2time = av_q2d(inputContext1->streams[0]->time_base);
//double packet_time = -1;
while (1)
{
AVPacket *packet = av_packet_alloc();
packet = ReadPacketFromSource(inputContext1);
if (packet)
{
if (packet->stream_index == 0) {
lastpts0 = packet->pts;
}
if (packet->stream_index == 1){
lastpts1 = packet->pts;
}
//lastpts = packet->pts;
WritePacket(packet, 0, inputContext1);
}
else
{
break;
}
}
while (1)
{
AVPacket *packet2 = av_packet_alloc();
packet2 = ReadPacketFromSource(inputContext2);
if (packet2)
{
/*if (packet2->stream_index == 0) {
WritePacket_combin(packet2, lastpts0, inputContext2);
}
if (packet2->stream_index == 1) {
WritePacket_combin(packet2, lastpts1, inputContext2);
}
else{
WritePacket_combin(packet2, lastpts1, inputContext2);
}*/
switch(packet2->stream_index) {
case 0 :
WritePacket_combin(packet2, lastpts0, inputContext2);
break;
case 1 :
WritePacket_combin(packet2, lastpts1, inputContext2);
break;
default :
break;
}
//WritePacket_combin(packet2, lastpts, inputContext2);
}
else
{
break;
}
}
//
CloseOutput();
//result_combin=get_outfile_buffer();
return result_combin;
}
Video_Buffer *get_outfile_buffer() {
printf(“打开data\n”);
Video_Buffer *result=(Video_Buffer *)malloc(sizeof(Video_Buffer));
if (!result){printf("申请输出内存失败\n");}
FILE* file = fopen("out.mp4", "rb");
if (!file) {
printf("打开文件失败\n");
//return NULL;
}
//将文件指针移动到文件末尾
if (fseek(file, 0, SEEK_END) != 0) {
printf("fseek error\n");
//return NULL;
}
//求出当前文件指针距离文件开始的字节数
uint32_t size = ftell(file);
if (size == -1) {
printf("获取文件大小失败\n");
//return NULL;
}
//将文件指针返回到文件开始处
if (fseek(file, 0, SEEK_SET) != 0) {
printf("fseek error\n");
//return NULL;
}
//分配内存
uint8_t* file_buffer = (uint8_t*)malloc(size + 1);
if (file_buffer == NULL) {
printf("内存分配失败\n");
//return NULL;
}
if (fread(file_buffer, size, 1, file) == 0) {
printf("读取文件错误\n");
//return NULL;
}
file_buffer[size] = '\0';//为了更加的安全
fclose(file);
result->buffLength = size+1;
result->buff = file_buffer;
return result;
}
ImageData *image_process (AVFormatContext *pFormatCtx, double timeStamp) {
if (avformat_find_stream_info(pFormatCtx, NULL) < 0) {
return NULL;
}
// 找到视频流
int videoStream = findVideoStream(pFormatCtx);
AVCodecContext *pCodecCtx = pFormatCtx->streams[videoStream]->codec;
// 打开相应的解码器
AVCodecContext *pNewCodecCtx = openCodec(pCodecCtx);
if (!pNewCodecCtx) {
fprintf(stderr, "openCodec failed, pNewCodecCtx is NULL\n");
return NULL;
}
uint8_t *frameBuffer;
AVFrame *pFrameRGB = initAVFrame(pNewCodecCtx, &frameBuffer);
pFrameRGB = readAVFrame(pNewCodecCtx, pFormatCtx, pFrameRGB, videoStream, timeStamp);
if (pFrameRGB == NULL) {
fprintf(stderr, "%s", "read AV frame failed");
return NULL;
}
imageData = (ImageData *)malloc(sizeof(ImageData));
imageData->width = (uint32_t)pNewCodecCtx->width;
imageData->height = (uint32_t)pNewCodecCtx->height;
// imageData->data = pFrameRGB->data;
imageData->data = getFrameBuffer(pFrameRGB, pNewCodecCtx);
// 释放内存
avcodec_close(pCodecCtx);
av_free(frameBuffer);
return imageData;
// free();
}
uint8_t *getFrameBuffer(AVFrame *pFrame, AVCodecContext *pCodecCtx) {
int width = pCodecCtx->width;
int height = pCodecCtx->height;
// Write pixel data
uint8_t *buffer = (uint8_t *)malloc(height * width * 3);
for (int y = 0; y < height; y++) {
memcpy(buffer + y * pFrame->linesize[0], pFrame->data[0] + y * pFrame->linesize[0], width * 3);
}
return buffer;
}
AVFrame *readAVFrame (AVCodecContext *pCodecCtx, AVFormatContext *pFormatCtx,
AVFrame *pFrameRGB, int videoStream, double timeStamp) {
double pts2time = av_q2d(pFormatCtx->streams[0]->time_base);
int64_t seekpts = timeStamp/pts2time;
struct SwsContext *sws_ctx = NULL;
int frameFinished;
AVPacket packet;
AVFrame *pFrame = NULL;
// Allocate video frame
pFrame = av_frame_alloc();
// initialize SWS context for software scaling
sws_ctx = sws_getContext(pCodecCtx->width,
pCodecCtx->height,
pCodecCtx->pix_fmt,
pCodecCtx->width,
pCodecCtx->height,
AV_PIX_FMT_RGB24,
SWS_BILINEAR,
NULL,
NULL,
NULL
);
int i = 0;
//1、视音频流 2、第一个视频流序号 3、时间戳
// int ret = av_seek_frame(pFormatCtx, videoStream, ((double)timeStamp/(double)33492.5)*AV_TIME_BASE
// + (double)pFormatCtx->start_time, AVSEEK_FLAG_BACKWARD);
int ret = av_seek_frame(pFormatCtx, videoStream,
seekpts , AVSEEK_FLAG_BACKWARD);
if (ret < 0) {
fprintf(stderr, "av_seek_frame failed");
return NULL;
}
while (av_read_frame(pFormatCtx, &packet) >= 0) {
// Is this a packet from the video stream?
if (packet.stream_index == videoStream) {
// Decode video frame
avcodec_decode_video2(pCodecCtx, pFrame, &frameFinished, &packet);
// Did we get a video frame?
if(frameFinished) {
// Convert the image from its native format to RGB
sws_scale(sws_ctx, (uint8_t const * const *)pFrame->data,
pFrame->linesize, 0, pCodecCtx->height,
pFrameRGB->data, pFrameRGB->linesize);
return pFrameRGB;
}
}
// Free the packet that was allocated by av_read_frame
av_free_packet(&packet);
}
return NULL;
}
AVFrame *initAVFrame (AVCodecContext *pCodecCtx, uint8_t **frameBuffer) {
// Allocate an AVFrame structure
AVFrame *pFrameRGB = av_frame_alloc();
if (pFrameRGB == NULL) {
return NULL;
}
int numBytes;
// Determine required buffer size and allocate buffer
numBytes = avpicture_get_size(AV_PIX_FMT_RGB24, pCodecCtx->width,
pCodecCtx->height);
*frameBuffer = (uint8_t *)av_malloc(numBytes * sizeof(uint8_t));
// Assign appropriate parts of buffer to image planes in pFrameRGB
// Note that pFrameRGB is an AVFrame, but AVFrame is a superset
// of AVPicture
avpicture_fill((AVPicture *)pFrameRGB, *frameBuffer, AV_PIX_FMT_RGB24,
pCodecCtx->width, pCodecCtx->height);
return pFrameRGB;
}
int findVideoStream (AVFormatContext *pFormatCtx) {
// Find the first video stream
int videoStream = -1;
for (int i = 0; i < pFormatCtx -> nb_streams; i++) {
if (pFormatCtx->streams[i]->codec->codec_type == AVMEDIA_TYPE_VIDEO) {
videoStream = i;
break;
}
}
return videoStream;
}
AVCodecContext *openCodec (AVCodecContext *pCodecCtx) {
AVCodec *pCodec = NULL;
// Find the decoder for the video stream
pCodec = avcodec_find_decoder(pCodecCtx->codec_id);
if (pCodec == NULL) {
fprintf(stderr, “%s”, “Unsupported codec!\n”);
return NULL; // Codec not found
}
// Copy context
AVCodecContext *pNewCodecCtx = avcodec_alloc_context3(pCodec);
if (avcodec_copy_context(pNewCodecCtx, pCodecCtx) != 0) {
fprintf(stderr, “Couldn’t copy codec context”);
return NULL; // Error copying codec context
}
// Open codec
if (avcodec_open2(pNewCodecCtx, pCodec, NULL) < 0) {
return NULL; // Could not open codec
}
return pNewCodecCtx;
}
4、HTML关键代码
下载:
function download(buff){
let url = window.URL.createObjectURL(new Blob([buff], {type: “arraybuffer”}))
const link = document.createElement(‘a’);
link.style.display = ‘none’;
link.href = url;
link.setAttribute(‘download’, ‘out.mp4’);
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
}
分割:
function run_split(){
let fileReader = new FileReader();
let file = form.file_split.files[0];
if(!file){
console.log("未检测到输入视频");
return 0;
}
fileReader.readAsArrayBuffer(file);
fileReader.onload = function () {
let buffer233 = new Uint8Array(this.result);
console.log("buffer233.length:",buffer233.length);
let offset = Module._malloc(buffer233.length);
console.log("offset",offset);
Module.HEAP8.set(buffer233, offset);
ptr = 0;
ptr = split_video(offset, buffer233.length, +form.time.value,+form.time1.value
);
console.log("传入的时间数据");
console.log(+form.time.value);
console.log(+form.time1.value);
let bufferlength = Module.HEAPU32[ptr / 4],
BufferPtr = Module.HEAPU32[ptr / 4 + 1],
returnBuffer = Module.HEAPU8.subarray(BufferPtr, BufferPtr + bufferlength+1);
if (!bufferlength) {
console.log("获取shibai");
return;
}
console.log(returnBuffer.length);
console.log(typeof(returnBuffer));
console.log(Object.prototype.toString.call(returnBuffer));
download(returnBuffer);
returnBuffer=0;
//Module._free_video_buffer();
//Module._free(buffer);
//Module._free(offset);
buffer233=0;
}
}
合并:
function run_combin(){
let buffer1=0;
let offset1=0;
let buffer2=0;
let offset2=0;
let fileReader1 = new FileReader();
let fileReader2 = new FileReader();
let file1 = form.file_combin1.files[0];
let file2 = form.file_combin2.files[0];
if(!file1){
console.log("未检测到合并视频1");
return 0;
}
if(!file2){
console.log("未检测到合并视频2");
return 0;
}
fileReader1.onload = function () {
buffer1 = new Uint8Array(this.result);
offset1 = Module._malloc(buffer1.length);
Module.HEAP8.set(buffer1, offset1);
fileReader2.readAsArrayBuffer(file2);
}
fileReader2.onload = function () {
buffer2 = new Uint8Array(this.result);
offset2 = Module._malloc(buffer2.length);
Module.HEAP8.set(buffer2, offset2);
console.log("buffer2.length",buffer2.length);
console.log("buffer1.length_read2",buffer1.length);
console.log("offset1_read2",offset1);
console.log("offset2_read2",offset2);
ptr=0;
ptr = combin_video(offset1,offset2, buffer1.length , buffer2.length);
let bufferlength = Module.HEAPU32[ptr / 4],
BufferPtr = Module.HEAPU32[ptr / 4 + 1],
returnBuffer = Module.HEAPU8.subarray(BufferPtr, BufferPtr + bufferlength+1);
//console.log("returnBuffer------",returnBuffer);
if (!bufferlength) {
console.log("获取合并文件失败");
return;
}
download(returnBuffer);
//returnBuffer=0;
Module._free_video_buffer();
//Module._free(offset1);
//Module._free(buffer);
//buffer2=0;
//buffer1=0;
}
fileReader1.readAsArrayBuffer(file1);
fileReader=null;
}
截图:
function run_cut(){
let fileReader = new FileReader();
let file = form.file_split.files[0];
if(!file){
console.log("未检测到输入视频");
return 0;
}
fileReader.readAsArrayBuffer(file);
fileReader.onload = function () {
let buffer233 = new Uint8Array(this.result);
console.log("buffer233.length:",buffer233.length);
let offset = Module._malloc(buffer233.length);
console.log("offset",offset);
Module.HEAP8.set(buffer233, offset);
ptr = 0;
ptr = getimage(offset, buffer233.length,+form.time2.value
);
console.log("传入的时间数据");
console.log(+form.time2.value);
let width = Module.HEAPU32[ptr / 4]
height = Module.HEAPU32[ptr / 4 + 1],
imgBufferPtr = Module.HEAPU32[ptr / 4 + 2],
imageBuffer = Module.HEAPU8.subarray(imgBufferPtr, imgBufferPtr + width * height * 3);
if (!width || !height) {
$errorTip.textContent = '获取图片帧失败,图片宽高为0,时间可能超限';
return;
}
drawImage(width, height, imageBuffer);
//Module._free(offset);
//Module._free(ptr);
//Module._free(imgBufferPtr);
fileReader
}
fileReader=null;
}
显示截图:
function drawImage(width, height, buffer) {
// 内存画布
memCanvas = document.createElement(‘canvas’),
memContext = memCanvas.getContext(‘2d’);
ctx = canvas.getContext('2d');
canvas.width = Math.max(600, window.innerWidth - 40);
let imageData = ctx.createImageData(width, height);
let k = 0;
for (let i = 0; i < buffer.length; i++) {
if (i && i % 3 === 0) {
imageData.data[k++] = 255;
}
imageData.data[k++] = buffer[i];
}
imageData.data[k] = 255;
memCanvas.width = width;
memCanvas.height = height;
canvas.height = canvas.width * height / width;
memContext.putImageData(imageData, 0, 0, 0, 0, width, height);
ctx.drawImage(memCanvas, 0, 0, width, height, 0, 0, canvas.width, canvas.height);
}