PySpark和RDD对象详解
目录
一.了解Spark、PySpark
Spark是什么
Python on Spark
Pyspark
小结
二.构建PySpark执行环境入口对象
PySpark的编程模型
小结
三.RDD对象
python数据容器转RDD对象
注意
演示
读取文件转RDD对象
演示

一.了解Spark、PySpark
Spark是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。

简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据
Python on Spark
Spark作为全球顶级的分布式计算框架,支持众多的编程语言进行开发。而Python语言,则是Spark重点支持的方向。
Pyspark
Spark对Python语言的支持,重点体现在,Python第三方库: PySpark之上。
PySpark是由Spark官方开发的Python语言第三方库。
Python开发者可以使用pip程序快速的安装PySpark并像其它三方库那样直接使用。
小结
1.什么是Spark、什么是PySpark
- Spark是Apache基金会旗下的顶级开源项目,用于对海量数据进行大规模分布式计算。
- PySpark是Spark的Python实现,是Spark为Python开发者提供的编程入口,用于以Python代码完成Spark任务的开发
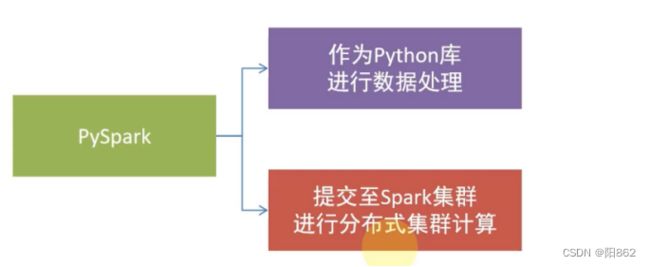
- PySpark不仅可以作为Python第三方库使用,也可以将程序提交的Spark集群环境中,调度大规模集群进行执行。
2.为什么要学习PySpark?
大数据开发是Python众多就业方向中的明星赛道,薪资高岗位多,Spark ( PySpark)又是大数据开发中的核心技术
二.构建PySpark执行环境入口对象
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。PySpark的执行环境入口对象是:类SparkContext的类对象
注意: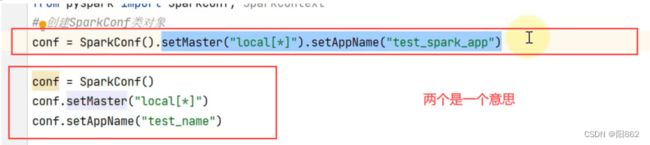
红框里面的两个都是一个意思,上面的方法叫做链式调用
#导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark_app")
#基于SparkConf类对象创建SparkContext对象
sc=SparkContext(conf=conf)
#打印Pyspark版本
print(sc.version)
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()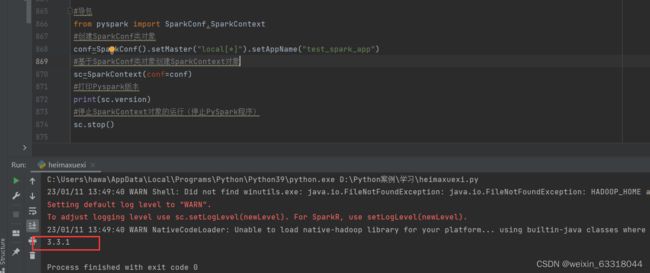
注意:要想运行成功需要下载JDK并配置好环境变量
PySpark的编程模型
SparkContext类对象,是PySpark编程中一切功能的入口。PySpark的编程,主要分为如下三大步骤:

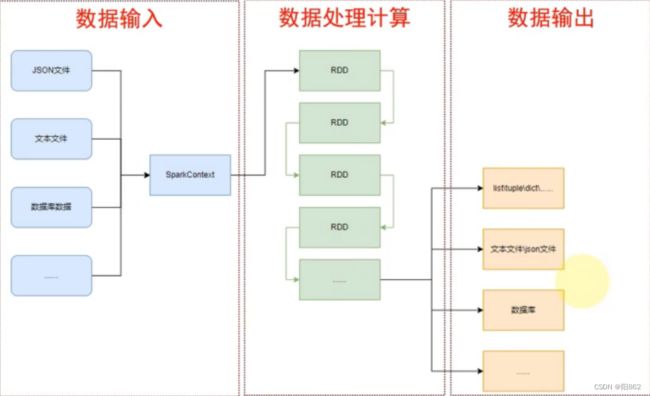
- 通过SparkContext对象,完成数据输入
- 输入数据后得到RDD对象,对RDD对象进行迭代计算
- 最终通过RDD对象的成员方法,完成数据输出工作
小结
1.如何安装PySpark库
pip install pyspark
2.为什么要构建SparkContext对象作为执行入口
PySpark的功能都是从SparkContext对象作为开始
3.PySpark的编程模型是?
- 数据输入:通过SparkContext完成数据读取
- 数据计算:读取到的数据转换为RDD对象,调用RDD的成员方法完成计算
- 数据输出:调用RDD的数据输出相关成员方法,将结果输出到list、元组、字典、文本文件、数据库等
三.RDD对象
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集( Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
python数据容器转RDD对象
PySpark支持通过Sparkcontext对象的parallelize成员方法,将:
- list
- tuple
- set
- dict
- str
转为PySpark的RDD对象
代码:

注意
- 字符串会被拆分出1个个的字符
- 存入RDD对象字典仅有key会被存入RDD对象
- 如果要查看RDD里面有什么内容,需要用collect()方法
演示
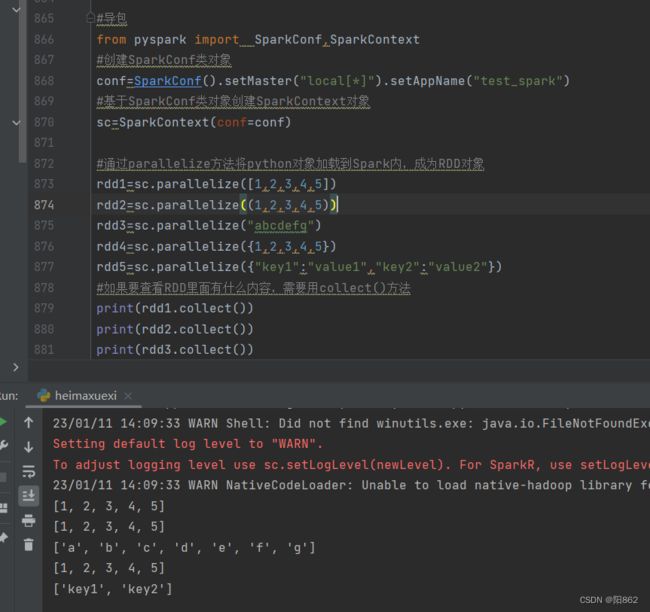
#导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#基于SparkConf类对象创建SparkContext对象
sc=SparkContext(conf=conf)
#通过parallelize方法将python对象加载到Spark内,成为RDD对象
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize((1,2,3,4,5))
rdd3=sc.parallelize("abcdefg")
rdd4=sc.parallelize({1,2,3,4,5})
rdd5=sc.parallelize({"key1":"value1","key2":"value2"})
#如果要查看RDD里面有什么内容,需要用collect()方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()结果是
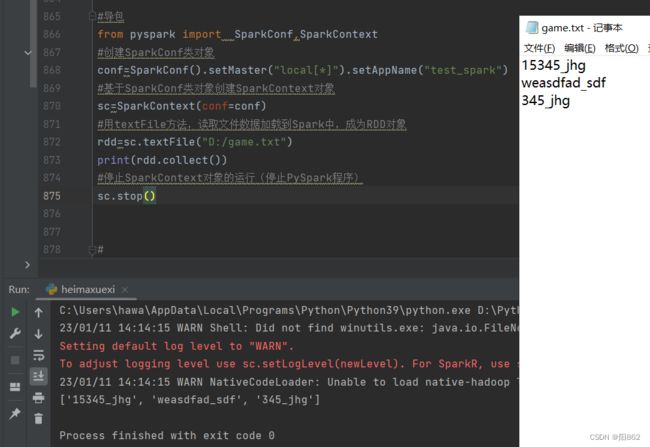
读取文件转RDD对象
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。

演示
#导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#基于SparkConf类对象创建SparkContext对象
sc=SparkContext(conf=conf)
#用textFile方法,读取文件数据加载到Spark中,成为RDD对象
rdd=sc.textFile("D:/game.txt")
print(rdd.collect())
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()结果是